- The paper demonstrates that Nvidia’s GPUs deliver high throughput for sub-30B models, while Apple’s SoCs enable efficient inference for ultra-large models.
- The study employs rigorous benchmarking to reveal how quantization strategies and memory bottlenecks impact inference performance and ecosystem compatibility.
- The research highlights the need for multi-objective system design, balancing compute density, energy efficiency, and precision for local LLM deployment.
Silicon Showdown: Empirical Dissection of GPU and SoC Architectures for Consumer-Grade LLM Inference
Introduction
The proliferation of large, open-weight LLMs has necessitated highly efficient local inference capabilities on consumer hardware. This work provides a rigorous, systems-level comparison between the Nvidia Blackwell GPU architecture and Apple's M-series SoC Unified Memory Architecture (UMA), with a focus on datacenter-scale LLMs (up to 80B parameters). The analysis moves beyond conventional throughput metrics, addressing quantization strategies, memory bottlenecks, software ecosystem maturity, and power efficiency, offering nuanced insights for researchers and system designers tailoring LLM deployment to local, power-constrained, or bandwidth-limited settings.
Architectural Divergence and Ecosystem Friction
Nvidia's traditional discrete GPU approach leverages high-bandwidth VRAM and tensor acceleration to maximize compute density. However, this is physically constrained by fixed VRAM capacity, sharply limiting the practical deployment of 70B+ parameter models and necessitating either aggressive quantization—potentially degrading model intelligence—or PCIe offloading, which catastrophically reduces throughput due to bandwidth and latency limitations. Conversely, Apple's UMA design eliminates the PCIe bottleneck, enabling direct SoC access to large, unified memory pools for both dense and quantized 70B+ models, accommodating larger models without traditional offloading penalties.
Software stack maturity and proprietary quantization formats introduce significant "ecosystem friction." On Nvidia, NVFP4 offers substantial theoretical speed and efficiency gains but is shackled by frequent incompatibilities in the inference toolchain. The "Backend Dichotomy" is evident: only the PyTorch backend for TensorRT-LLM fully exploits NVFP4's performance, while the C++ backend, though superior in latency, operates near BF16 speeds, largely negating NVFP4's throughput advantage.
The study benchmarks flagship consumer platforms—Nvidia RTX 5090 and Apple M3 Ultra—across efficient 1.5B models and state-of-the-art 70B–80B models using harmonized prompt and decoding settings. Throughput (tokens/sec), Time-To-First-Token (TTFT), and energy efficiency (tokens/joule) are reported.
For small models running at precision levels that avoid VRAM bottlenecks, the RTX 5090 exhibits a 70% throughput advantage relative to the M3 Ultra. However, this comes at an extreme energy deficit—the Apple M3 Ultra delivers up to a 23x improvement in energy efficiency. This efficiency arises from reduced inter-chip data movement and power-optimized SoC design in Apple hardware.
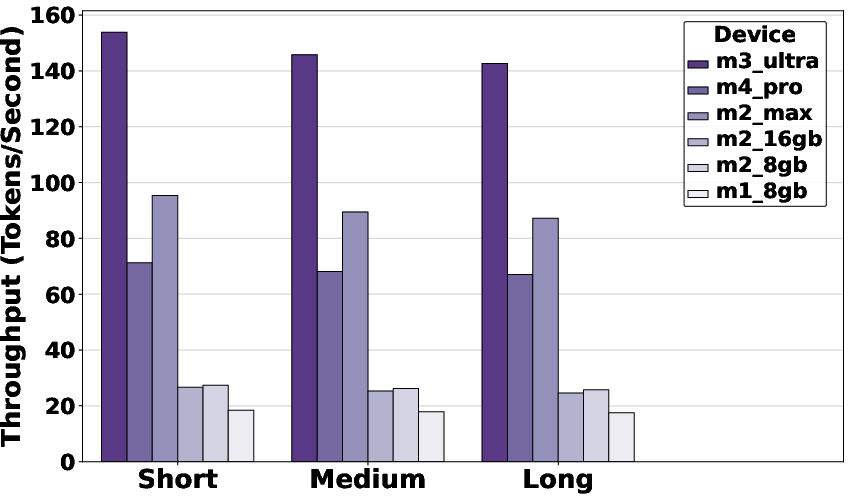
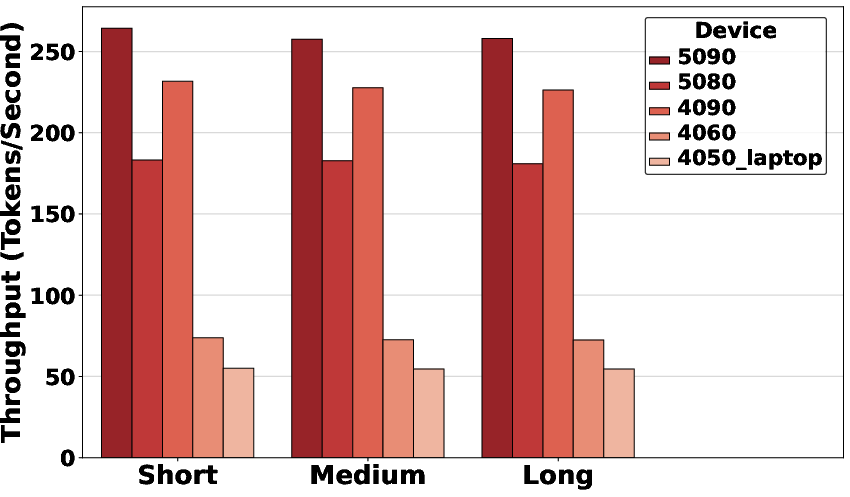
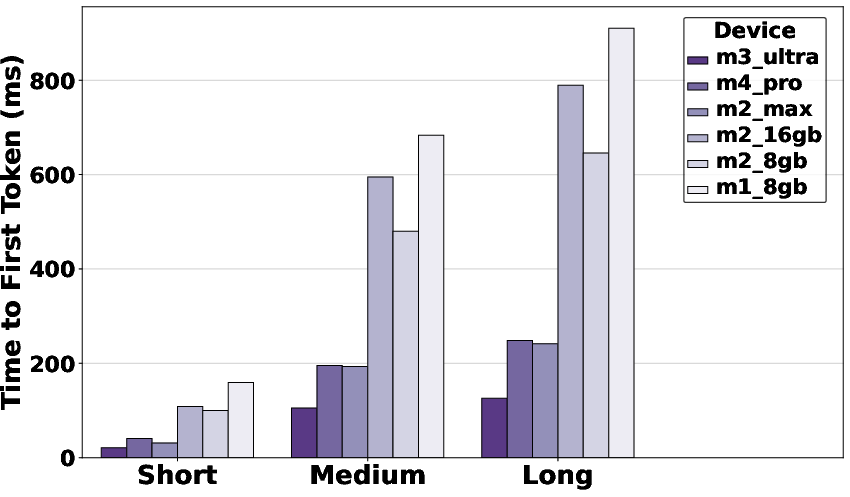
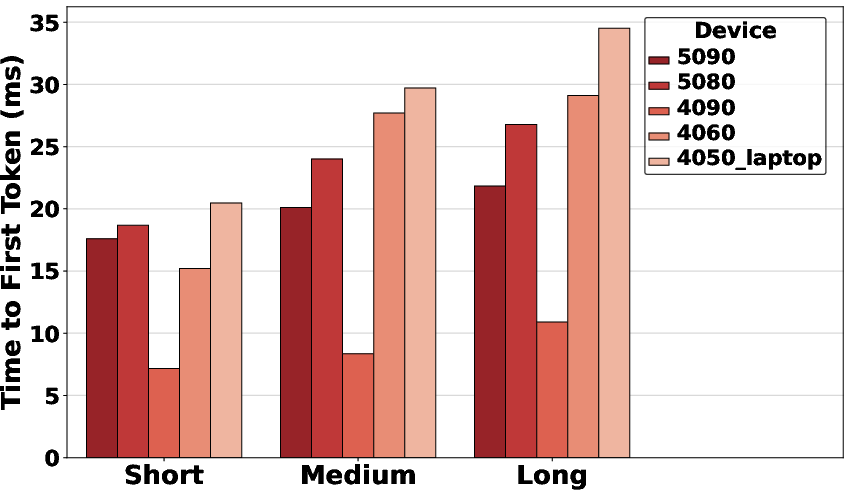
Figure 1: Throughput of Apple Silicon hardware using MLX, demonstrating performance scaling and operational tiers across model sizes.
A critical anomaly appears in latency: the previous-generation RTX 4090 outperforms the 5090 by over 2.2x in TTFT. The discrepancy is attributed to software immaturity on Blackwell, with drivers and acceleration libraries lagging hardware capability.
Quantization, VRAM Walls, and Offloading Penalties
NVFP4 on Blackwell, when invoked via the PyTorch backend, yields a 1.6x throughput advantage over BF16 with negligible accuracy loss on moderate model sizes (up to 8B parameters). However, the VRAM requirement for quantizing large models (e.g., 70B parameters) in NVFP4 surpasses the physical memory limit of modern discrete GPUs, necessitating reliance on pre-quantized weights (often unavailable or limited) or slow CPU-based quantization processes. Once model size exceeds available VRAM, practitioners must choose between aggressive quantization (e.g., IQ3, Q2) and offloading. The former reduces effective model intelligence, the latter incurs a 90% reduction in inference speed, dropping generational throughput from 76 tokens/sec (VRAM fit) to under 5 tokens/sec (25-28% offload to CPU) on the RTX 5090.
Apple Silicon’s UMA, leveraging MLX-native 4-bit quantization, accommodates 70B–80B models within 96GB of system memory with practical performance, bypassing the trade-offs forced by discrete VRAM ceilings. For dense models, like Llama-3.3-70B, throughput scales linearly with memory bandwidth; for MoE models, the scaling shifts towards latency sensitivity, with monolithic die architectures (M4 Pro) sometimes outperforming multi-die (M3 Ultra) systems due to lower cross-die latency and superior single-core routing efficiency.
Implications for Local AI Deployment
Findings underscore the non-trivial challenge of deploying modern LLMs on consumer hardware. For model sizes under 30B parameters, Nvidia’s discrete GPUs remain unmatched in raw throughput, albeit at high power cost and with backend constraints. For state-of-the-art, ultra-large models, Apple’s UMA is the only architecture capable of supporting high-precision inference without resorting to destructive trade-offs.
The proliferation of proprietary quantization and backend-specific optimizations fragments deployment workflows, raising the bar for reproducible, efficient inference. Backend choice directly determines attainable speed; NVFP4’s full performance is accessible only through the PyTorch runner, while the C++ backend and traditional toolchains lag or lack support entirely. Furthermore, hardware-limited software maturity on new GPU architectures creates an optimization gap, highlighting the need for further software and systems research.
Theoretical and Practical Outlook
The dichotomy between throughput and memory capacity elevates system design from simple benchmarking to a problem of multi-objective optimization involving precision, intelligence retention, throughput, startup latency, and energy efficiency. The results compel the field towards better unified memory strategies on discrete GPU platforms, improved quantization workflows with lower ecosystem friction, and the convergence of high-throughput, energy-efficient on-device LLM inference.
On the theoretical side, the findings challenge the assumption that more cores and bandwidth alone suffice for MoE scaling: memory topology and architectural optimizations around latency-sensitive routing are increasingly critical for next-generation inference workloads.
Conclusion
This work presents a comprehensive, empirical exploration of consumer-grade Nvidia and Apple Silicon hardware for LLM inference. Nvidia Blackwell GPUs, with NVFP4, lead in compute density and throughput for sub-30B models—if and only if ecosystem friction can be navigated. For 70B+ models, Apple’s unified memory enables practical inference with higher precision at competitive throughputs and vastly superior energy efficiency. Power-optimized SoC designs, next-generation monolithic dies, and streamlined software stacks define the future for accessible, sustainable, and high-capacity local AI inference. The study signals a paradigm shift: optimal local LLM deployment is now a function of complex hardware-software codesign, workload-specific constraints, and a rapidly evolving quantization ecosystem.

