- The paper demonstrates that thermal and power constraints, rather than peak compute, primarily govern sustained LLM inference performance.
- It evaluates four platforms using a unified 258-token prompt, measuring throughput, latency, energy, and temperature to reveal distinct hardware bottlenecks.
- The study highlights that edge NPUs offer stable, energy-efficient inference for background tasks, while mobile devices suffer from rapid thermal throttling in always-on scenarios.
Overview
The paper "LLM Inference at the Edge: Mobile, NPU, and GPU Performance Efficiency Trade-offs Under Sustained Load" (2603.23640) systematically benchmarks sustained autoregressive inference for a quantized 1.5B-parameter LLM (Qwen 2.5 1.5B, 4-bit) across four edge-representative platforms: Raspberry Pi 5 equipped with Hailo-10H NPU, Samsung Galaxy S24 Ultra, iPhone 16 Pro, and NVIDIA RTX 4050 laptop GPU. The study targets always-on agent deployment scenarios in which inference must be sustained under continuous load, revealing how power, thermal envelopes, and memory bandwidth serve as primary constraints, superseding peak compute specifications. The evaluation exposes distinct platform bottlenecks, quantifies throughput, power, and thermal stability, and characterizes the real-world feasibility of LLM deployment at the edge.
Methodology and Benchmarking Design
The authors select Qwen 2.5 1.5B with 4-bit quantization due to its sub-1GB memory footprint and wide framework support, enabling controlled comparisons. Each platform receives a unified 258-token prompt eliciting extended, structured output to stress sustained decode throughput and thermal management. Benchmarks are executed under warm conditions (model pre-loaded, 20 back-to-back iterations per device), with metrics including sustained throughput (tok/s), latency, power consumption, and temperature. Measurement instrumentation is platform-specific: direct current sensing for Hailo-10H, GPU-level power via nvidia-smi for RTX 4050, battery proxy for iPhone, and temperature logs for all platforms. Iteration-level results are validated for anomalies, and cold-start overhead is measured but excluded from final statistics.
RTX 4050 Laptop GPU
The battery-powered RTX 4050 achieves the highest sustained throughput at 131.7 tok/s (CV = 2.2%), operating at a stable average power of 34.1 W. GPU temperature increases gradually (55°C → 70°C), but no throttling is observed. Energy per token stabilizes at 297 mJ.
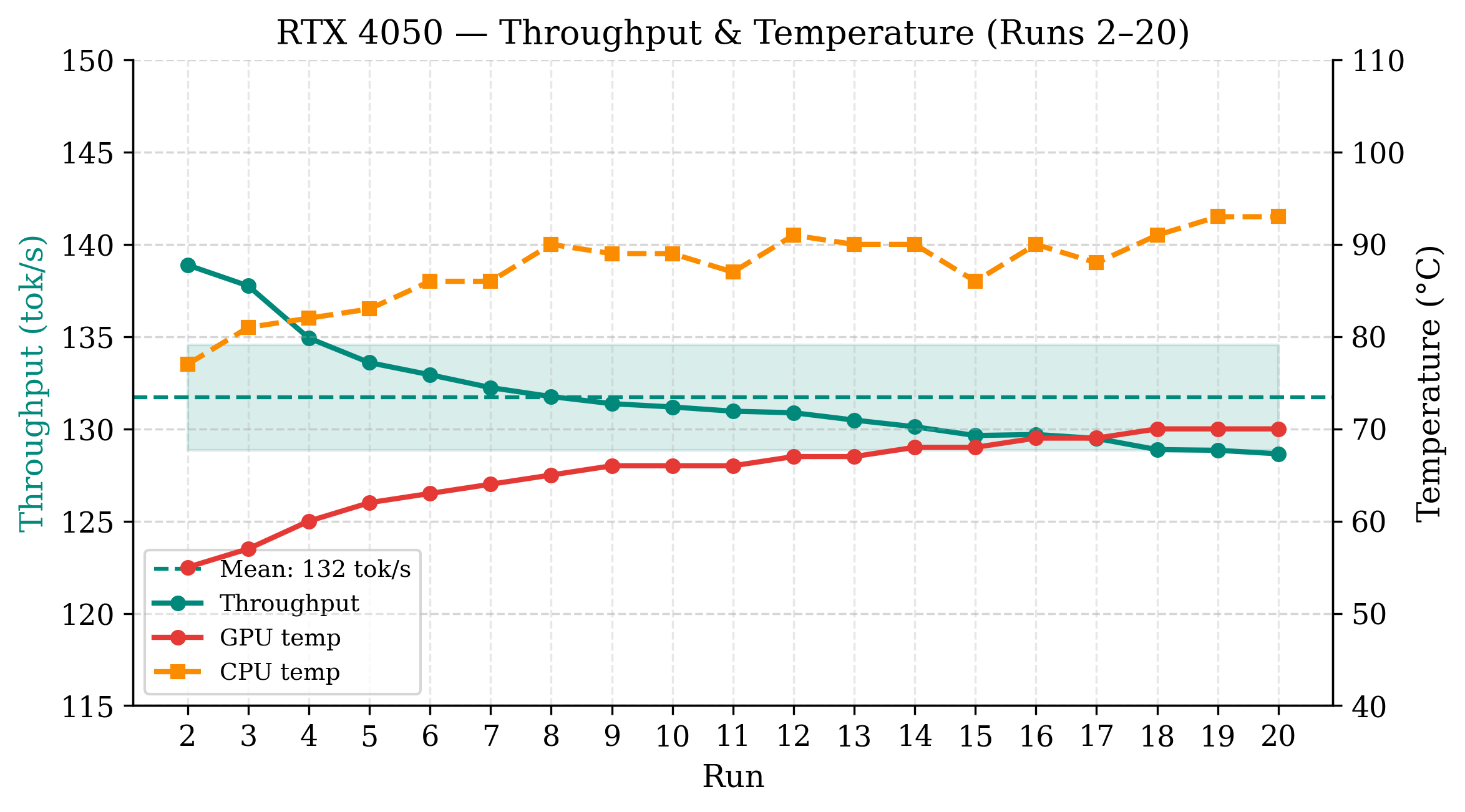
Figure 1: RTX 4050 per-run throughput and temperature across 20 sustained inference runs; stable performance and no thermal throttling.
Raspberry Pi 5 + Hailo-10H NPU
Hailo-10H delivers 6.9 tok/s at 1.87 W, exhibiting near-zero throughput variance (CV = 0.04%) and thermally stable operation (CPU/NPU 52.7/58.5°C). The result matches vendor reference figures, confirming memory-bandwidth-bound deployment as the primary limiter. Energy per token is lowest among platforms at 271 mJ, comparable to RTX 4050 on a per-joule basis.
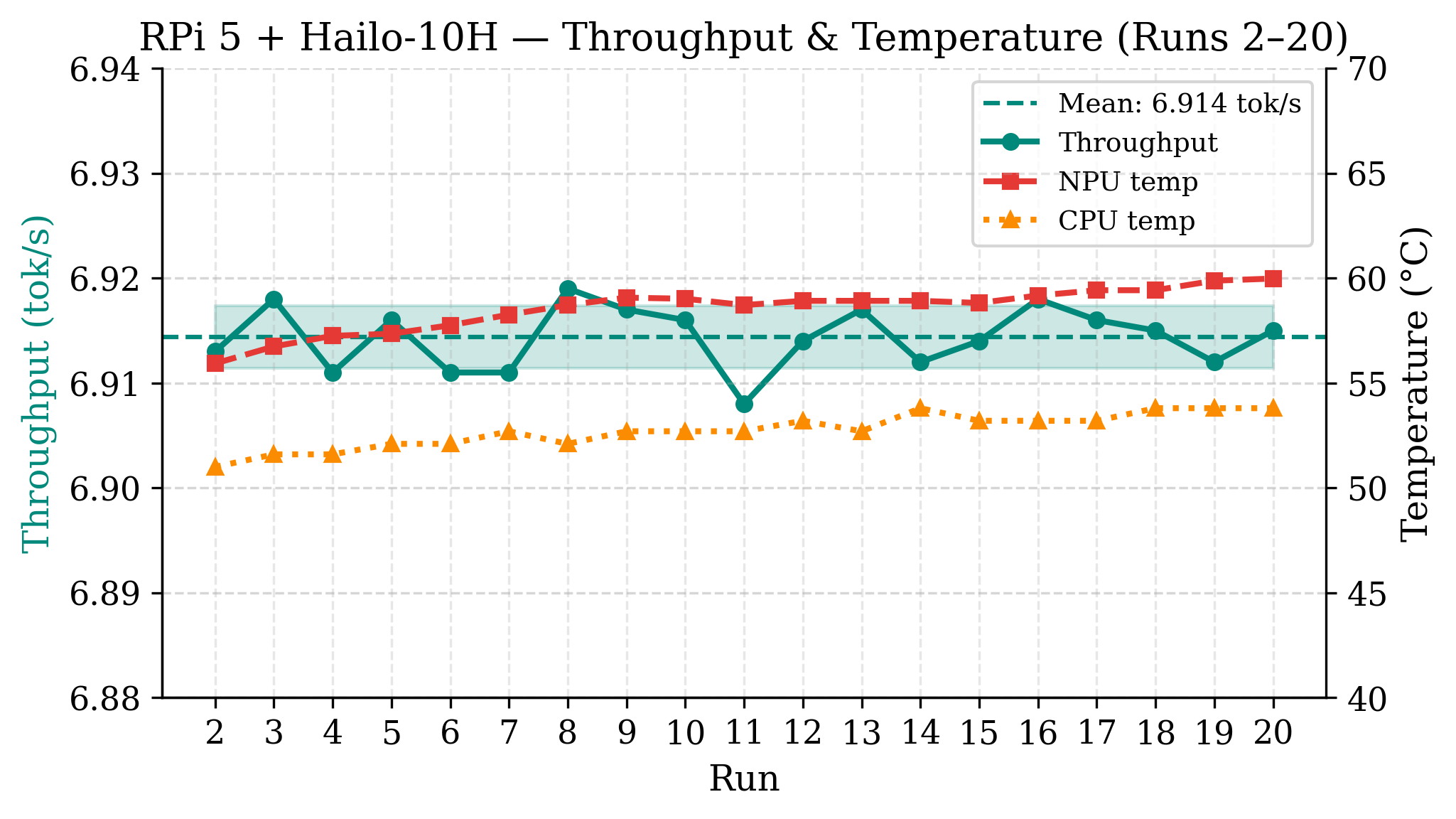
Figure 2: Hailo-10H NPU throughput and temperature over 20 iterations; deterministic and thermally stable inference.
iPhone 16 Pro
Peak throughput reaches 40.35 tok/s but degrades to a sustained 22.56 tok/s (Hot thermal state, –44% from peak) after only two iterations, with 65% of runs executed in a throttled state. Battery drain is 10% over 20 iterations; power per inference cannot be directly measured.
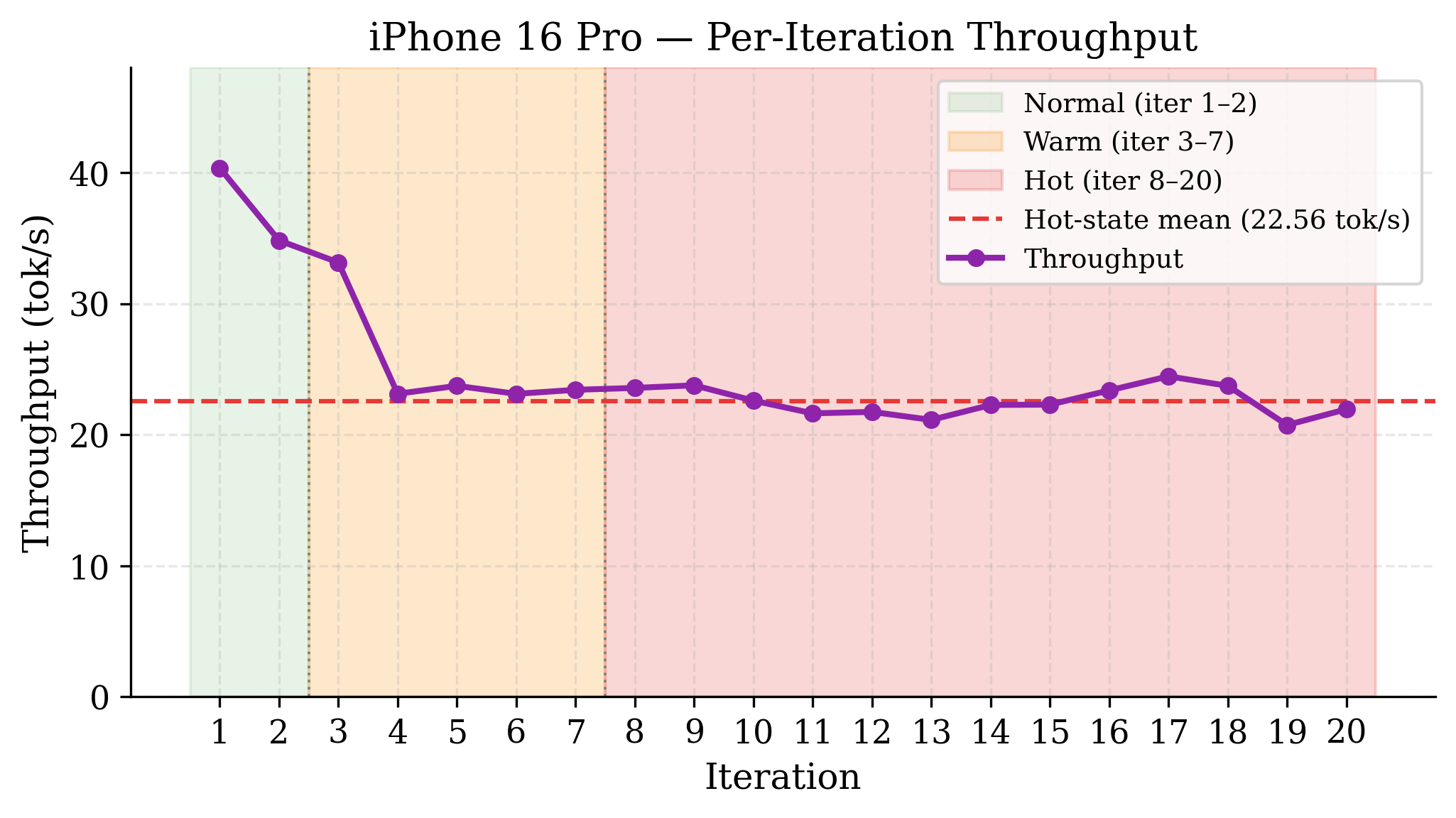
Figure 3: iPhone 16 Pro per-iteration throughput, with rapid thermal state transitions and sustained Hot-state degradation.
Samsung Galaxy S24 Ultra
S24 Ultra sustains 9.9 tok/s across only five valid iterations before Android's thermal governor enforces a hard GPU frequency floor, terminating inference (GPU temperature 78.3°C). Pre-fill time is anomalously high (25.1 s), likely due to software stack overhead. The device is unsuited for sustained agent operation.
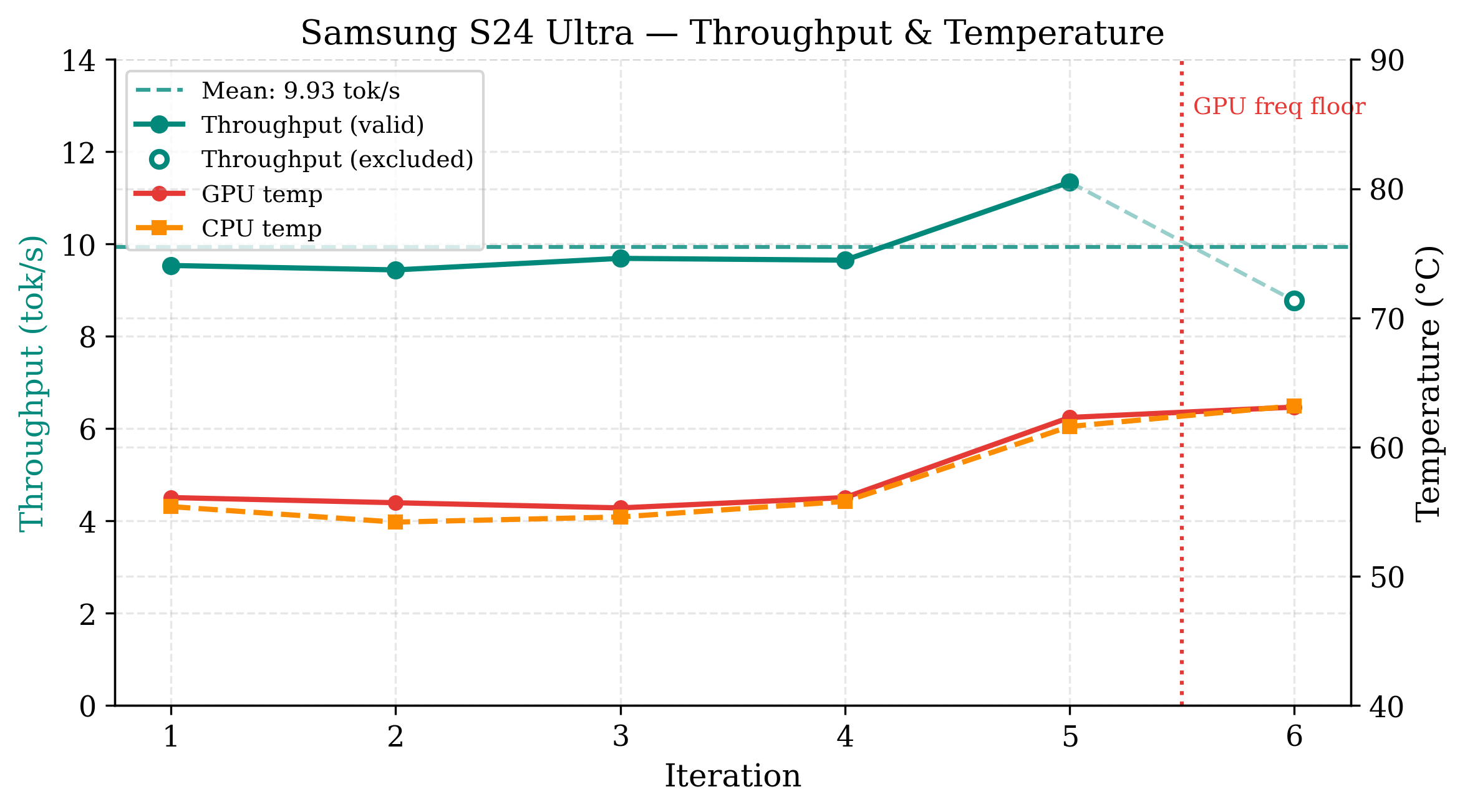
Figure 4: S24 Ultra per-iteration throughput; hard OS-enforced frequency floor and benchmark termination due to severe thermal event.
Among all platforms, the RTX 4050 delivers 19× higher throughput than Hailo-10H and 5.8× that of iPhone 16 Pro (sustained). Both RTX 4050 and Hailo-10H demonstrate comparable energy proportionality (∼0.26 W/tok/s), confirming high efficiency at vastly different power envelopes. Mobile platforms (iPhone, S24 Ultra) are notably constrained by rapid thermal throttling, precluding always-on deployment even at modest query rates. Hailo-10H is unique in its ability to deliver deterministic, thermally stable inference suitable for asynchronous or background workloads, albeit with a significant latency limitation (∼72 s for 500 tokens).
Implications for Deployment
Thermal Constraints Dominate Mobile Edge
Empirical evidence confirms that sustained LLM inference on mobile SoCs is primarily limited by thermal management rather than peak compute. Rapid throughput degradation (iPhone Hot state), abrupt throttling (S24 Ultra), and lack of thermal recovery within short cooldown intervals pose significant barriers for always-on, high-frequency agent deployments. Interactive scenarios require either significant duty-cycling or external cooling strategies to avoid reliability degradation.
Dedicated Edge NPUs as Viable Alternative
Edge NPUs like Hailo-10H offer unmatched stability and efficiency for sustained workloads, supporting indefinite operation within tight power/thermal envelopes. However, throughput remains substantially lower than other platforms, restricting their applicability to non-interactive or background tasks unless deployment optimizations (batched decoding, host-NPU integration) improve per-token latency.
GPU Edge Viability and Battery Constraints
Laptop-grade GPUs (RTX 4050) are optimal for high-throughput, thermally stable inference given sufficient power sources. Battery-powered sustained agent operation is infeasible due to drain rates (∼12% per 20 runs), limiting practical deployment to AC-powered or episodic scenarios.
Framework and Measurement Limitations
Performance differences reflect combined hardware-software effects. Contrasts in quantization formats, inference stacks, and measurement methodologies constrain generalizability. Android/iOS do not expose reliable per-component power metrics, precluding cross-platform energy analysis. Only a single model and prompt were evaluated; results may not extrapolate to shorter outputs or smaller models.
Future Research Directions
The study calls for extended-duration thermal profiling (100+ iterations), standardized power instrumentation (hardware-level sensors across platforms), exploration of batching/speculative decoding on edge NPUs, quantization format unification, and coverage of diverse models and prompt types. Investigating software stack optimizations and hybrid agent architectures combining mobile SoCs with lightweight NPUs will further delineate the practical landscape for edge LLM inference.
Conclusion
Sustained autoregressive LLM inference at the edge is fundamentally governed by thermal and power constraints, not nominal compute capacity. Dedicated edge NPUs (Hailo-10H) exhibit unparalleled stability and efficiency at low throughput, while mobile flagships (iPhone, S24 Ultra) fail to sustain inference due to rapid or abrupt thermal throttling. GPU-edge devices (RTX 4050) lead in throughput but impose battery limitations. These findings underscore the necessity for platform-aware deployment strategies, including agent duty-cycling, hardware integration, and careful workload engineering for edge LLMs. Robust benchmarking standards and instrumentation are essential for future comparative studies.

