- The paper presents Learning While Deploying (LWD), a framework that integrates offline pretraining with continual online learning for generalist robot policies.
- It introduces two novel techniques, DIVL for robust distributional value learning and QAM for stable policy extraction, achieving a 95% success rate across diverse tasks.
- The approach demonstrates scalable, real-world adaptation on eight complex manipulation tasks through a closed-loop fleet deployment and continual policy improvement.
Fleet-Scale Offline-to-Online RL for Generalist Robot Policies
Motivation and Problem Statement
The paper addresses the challenge of deploying generalist robot policies trained via Vision-Language-Action (VLA) models in real-world environments where distributional shifts, long-tail failures, and task variations prevail. Offline pretraining is insufficient for adaptation to unpredictable conditions arising during deployment. The central problem is closing the loop between fleet-scale real-world deployment, policy improvement, and subsequent redeployment, using both autonomous rollouts and human intervention data. The authors propose Learning While Deploying (LWD)—a continual, fleet-scale RL framework to enable post-training of generalist policies with both offline and online buffers, supporting robust adaptation in heterogeneous, operational environments.
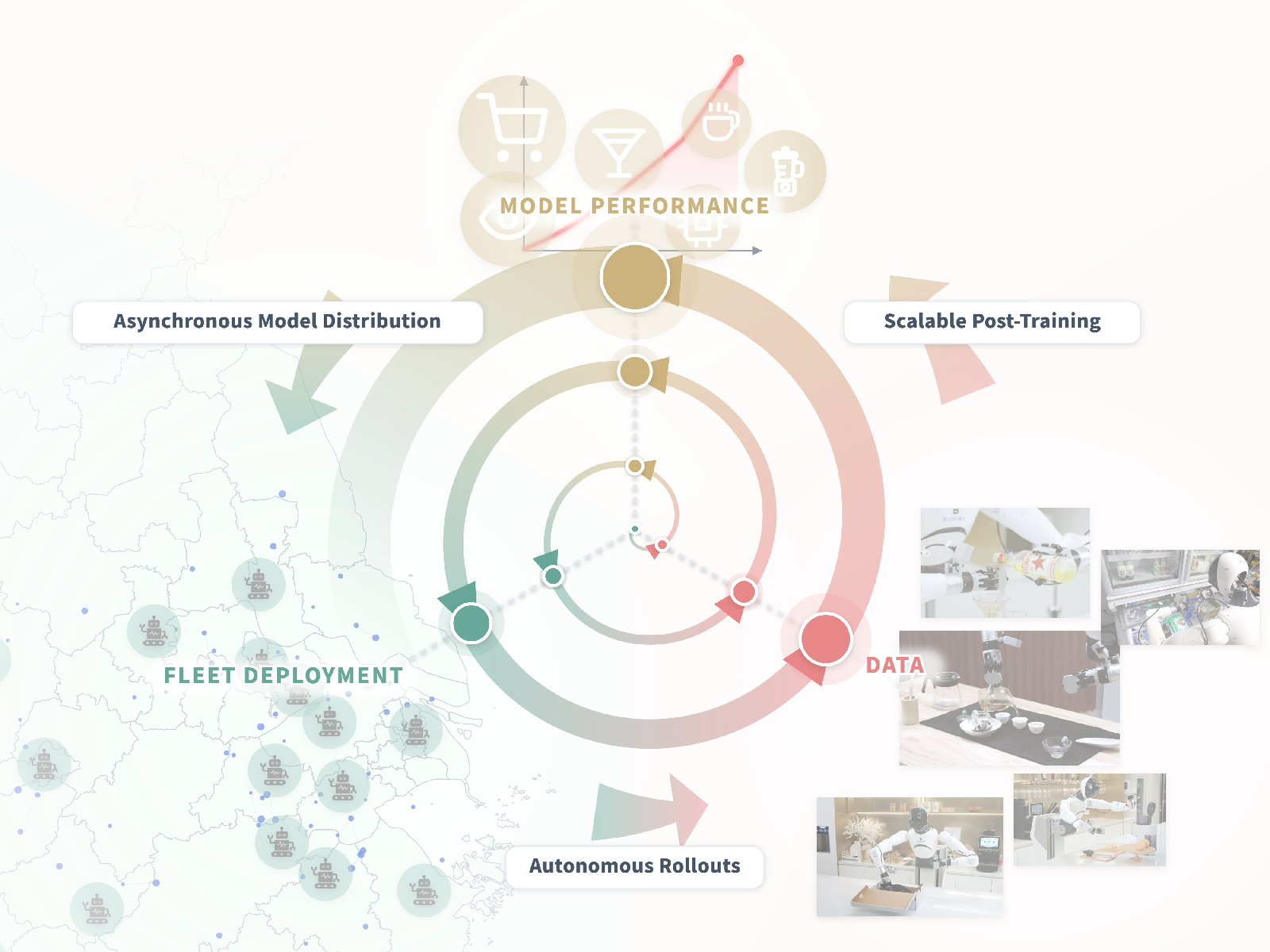
Figure 1: The LWD data flywheel: after offline pretraining, deployed robots collect online interaction data which is used to update the policy for further deployment, establishing a closed, continual improvement loop.
Methodological Framework
LWD combines offline RL pretraining with continuous online post-training, exploiting mixed replay from static and online buffers. The offline phase leverages demonstration, historical rollouts, and play data covering both success and failure modalities. The online phase uses a fleet (16 robots) to collect interactive experience, asynchronously mixing autonomous executions and human corrections.
The algorithmic pipeline consists of two principal components:
- Distributional Implicit Value Learning (DIVL): Extends Implicit Q-Learning by modeling the value function as a categorical distribution over dataset action-values. Quantile-based bootstrapping replaces expectile regression, preserving multimodal return distributions and supporting robust value estimation on heterogeneous, off-policy, and sparse-reward data. Adaptive optimism is achieved by conditioning the quantile parameter τ on entropy, ensuring conservative estimation under uncertainty.
- Q-learning via Adjoint Matching (QAM): Facilitates stable policy extraction in flow-based VLA generators by locally regressing the action vector field towards reward-informed gradients supplied by the DIVL critic. QAM mitigates instability and computational burden arising from direct backpropagation through multi-step generative flows.
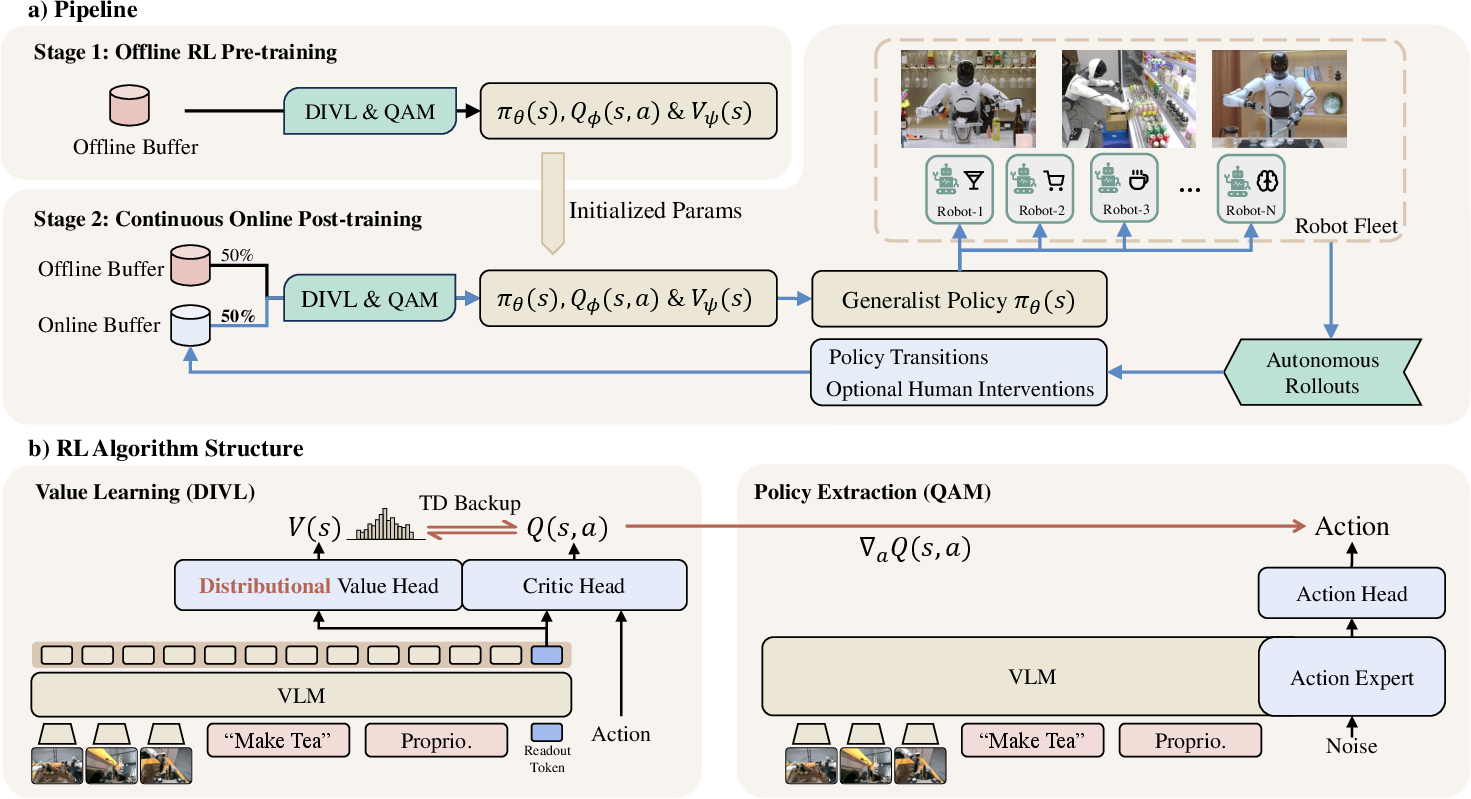
Figure 2: LWD pipeline: Stage 1 is offline RL pre-training; Stage 2 is continual online training, feeding data collected by a distributed robot fleet into a central learner.
Experimental Evaluation
LWD is validated on eight manipulation tasks, encompassing both short-horizon semantic restocking tasks and long-horizon precision tasks (3–5 minutes per episode) such as "Make Cocktail", "Brew Gongfu Tea", "Make Fruit Juice", and "Pack Shoes". Tasks require semantic grounding, contact-rich operations, long-horizon dependencies, and recovery from error. The evaluation setup spans variable instructions, clutter, object poses, and configuration diversity, pushing the generalization capabilities of the policy.

Figure 3: Task suite visualizations showing complex manipulation sequences and long-horizon challenges with semantic variation and error recovery demands.
The robot fleet architecture ensures concurrent data collection and rapid deployment cycles; each robot acts as an asynchronous actor, streaming data to the learner, which periodically synchronizes updated policies to all actors.

Figure 4: Illustration of the 16-robot fleet, collectively generating heterogeneous real-world data to drive continual policy improvement.
Quantitative Results and Analysis
LWD (Online) achieves an average success rate of 95% across tasks, with pronounced advantages on long-horizon tasks (average score: 0.91). Compared to baselines (SFT, RECAP, HG-DAgger), LWD consistently outperforms, especially in scenarios where imitation strategies suffer from compounding errors and limited reward signal propagation. RL-driven policy updates harness both autonomous and failed trajectories, enabling effective reward-based optimization for recovery and progress tracking.
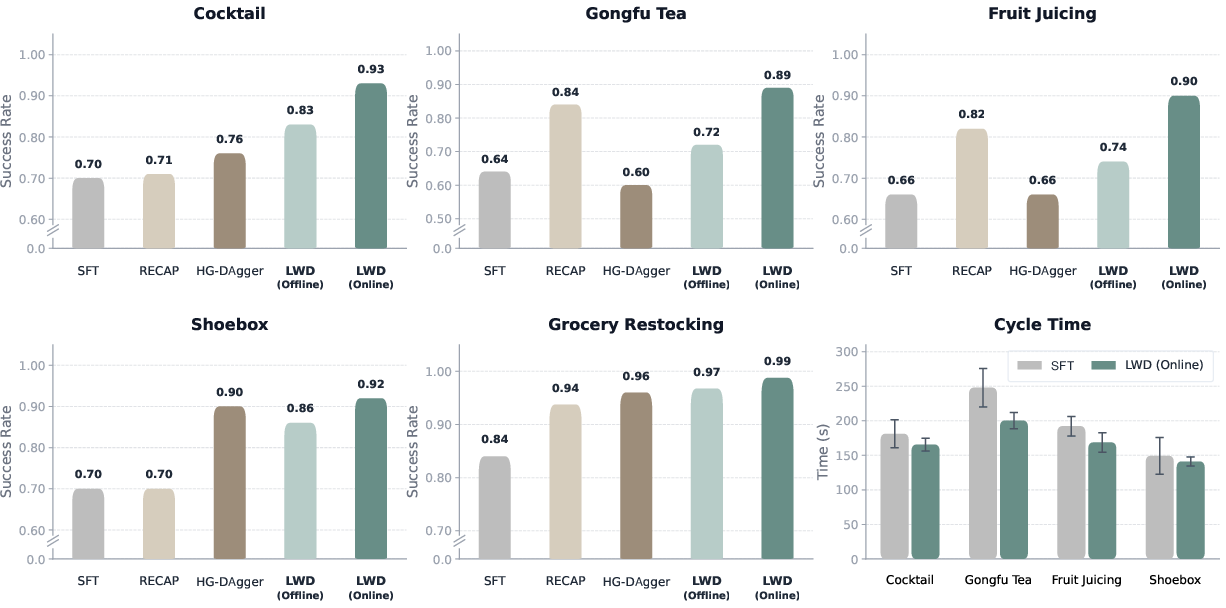
Figure 5: Comparison of success scores and cycle times—LWD yields improved success and reduced execution latency relative to SFT and other baselines.
Value function diagnostics indicate that DIVL provides reliable progress signals: successful trajectories exhibit increasing value estimates nearing task completion, while failed trajectories plateau at lower values, reflecting degraded policy progress.
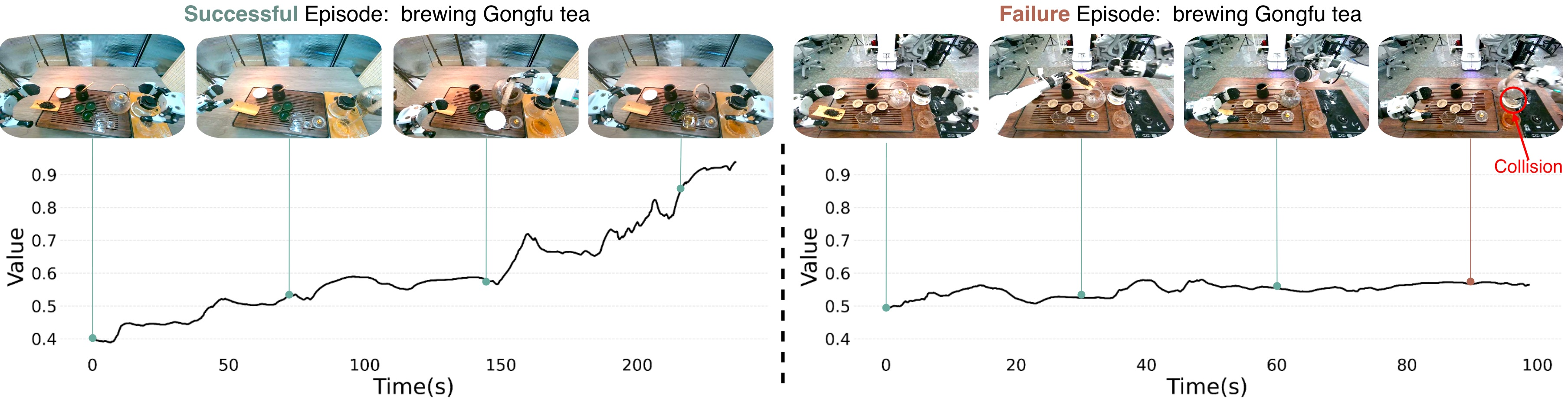
Figure 6: Quantile value learning plots for Gongfu Tea episodes, demonstrating effective progress tracking and differentiation between successful and failed executions.
Ablative Insights
Ablations highlight the superiority of DIVL over scalar expectile regression, with gains of up to 16.7% in online long-horizon settings. The adaptive τ schedule further enhances performance, providing 4% improvement over constant τ by dynamically calibrating optimism via entropy-based uncertainty.
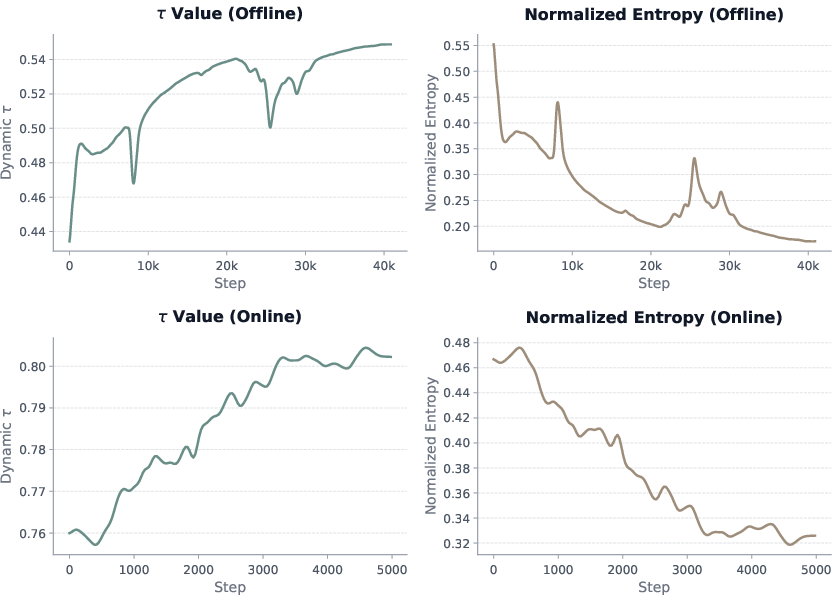
Figure 7: Dynamics of τ and normalized entropy during training; decreasing entropy leads to increased confidence and more optimistic policy improvement.
Predicted value distributions reflect the ability to distinguish between execution outcomes, supporting fine-grained policy updates rooted in reward-sensitive statistics.
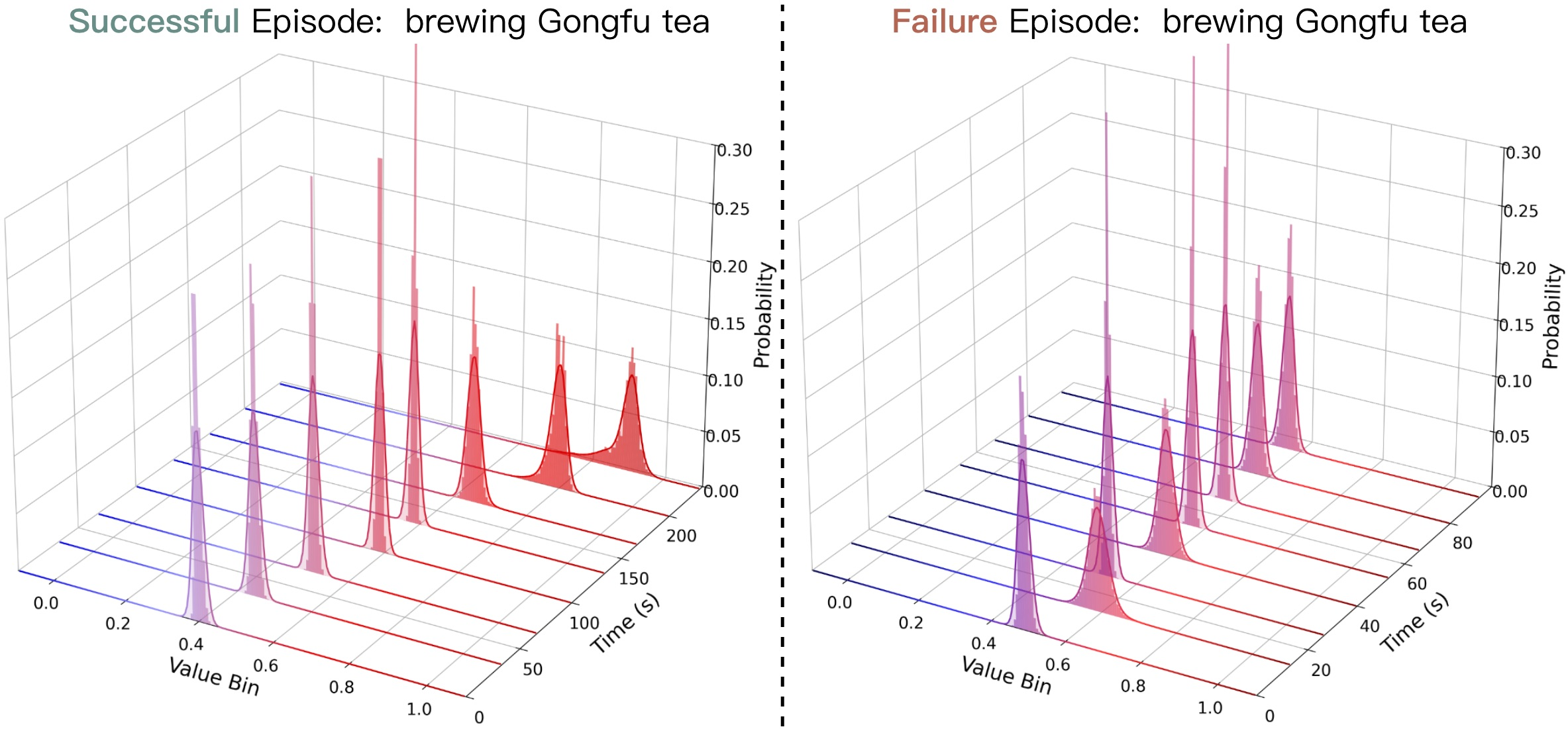
Figure 8: Value distribution evolution in successful versus failed Gongfu Tea episodes; unimodal progression in successes contrasts with stagnation in failures.
Implications and Future Directions
The LWD framework operationalizes the concept that fleet deployment is not merely an endpoint but a primary source of continual learning, effectively transforming robot fleets into distributed data generation substrates. Practically, LWD enables robust, scalable adaptation for generalist VLA models, leveraging a closed-loop flywheel between deployment and policy improvement. Theoretically, DIVL’s distributional perspective aligns with recent advances in distributional RL, offering better handling of multimodal and heavy-tailed returns. QAM introduces a tractable, stable route for gradient-based fine-tuning in generative policies.
Potential future directions include optimizing the online update schedule for larger-scale deployments, more advanced vision-language reasoning for complex task decomposition, and incorporating explicit safety-aware learning and control mechanisms for real-world robustness. The integration of world models as simulators for post-training and further scaling via distributed learning systems (as explored in SOP (Pan et al., 6 Jan 2026)) are likely avenues to amplify the impact of LWD.
Conclusion
LWD demonstrates that continual improvement of a single generalist robot policy is possible and highly effective when leveraging fleet-scale offline-to-online RL with mixed replay, distributional value learning, and gradient-based policy extraction. The framework sets a practical foundation for large-scale, robust, and adaptive deployment of vision-language-action robotic systems in varied, real-world environments.