- The paper demonstrates that increasing negative samples can cause performance collapse due to the imbalance between trivial and boundary-critical negatives.
- DynamicPO employs adaptive boundary negative selection and dual-margin dynamic β adjustment to sharpen decision boundaries and improve HitRatio by up to 8%.
- Empirical results on LastFM, Steam, and Goodreads show that DynamicPO outperforms baseline methods with a nearly 28% improvement in reward win rate.
DynamicPO: Dynamic Preference Optimization for Recommendation
Introduction and Context
The integration of LLMs into sequential recommendation has significantly advanced the field, particularly through the deployment of preference optimization techniques capable of explicit user alignment. However, Direct Preference Optimization (DPO) and its multi-negative variants, while designed to leverage abundant implicit-feedback negatives, are subject to a critical pathology: as the number of negative samples increases, the HitRatio on held-out recommendation tasks first improves and then unexpectedly collapses—even as the training loss continues to decrease. This “preference optimization collapse” invalidates standard assumptions about the monotonic benefits of negative scaling in multi-sample preference optimization frameworks and exposes a central weakness in high-capacity model alignment for recommender systems.

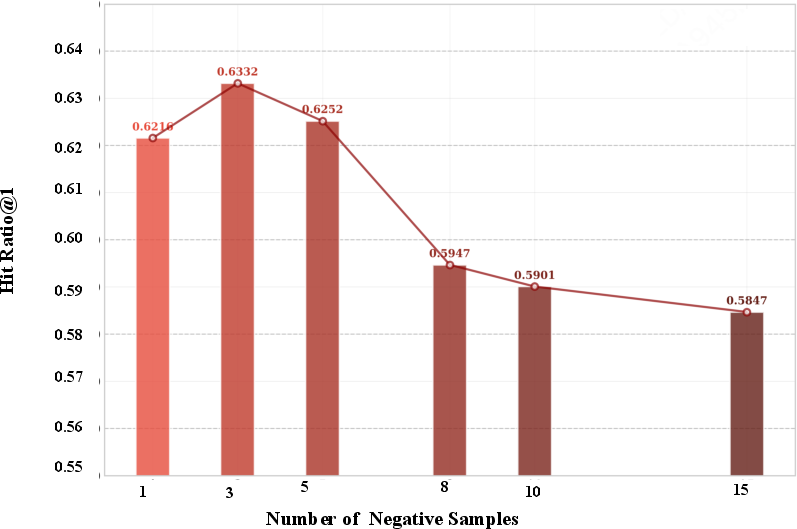
Figure 1: Demonstration of preference optimization and collapse phenomenon in LLM-based recommenders.
Empirical and theoretical analyses show that this collapse is not a simple consequence of overfitting or optimization pathology, but rather results from the imbalance between trivial, model-discriminative negatives and the rare but information-rich boundary-critical negatives that govern preference resolution. The gradient budget in naïve multi-negative DPO becomes dominated by unimportant samples, starving the pivotal decision boundary of optimization signal and leading to boundary deterioration.
Core Methodology: DynamicPO
DynamicPO addresses this collapse through two adaptive mechanisms: Dynamic Boundary Negative Selection and Dual-Margin Dynamic β Adjustment, integrated as a computationally efficient, preprocessing-free, plug-and-play layer atop any multi-negative DPO recommender.
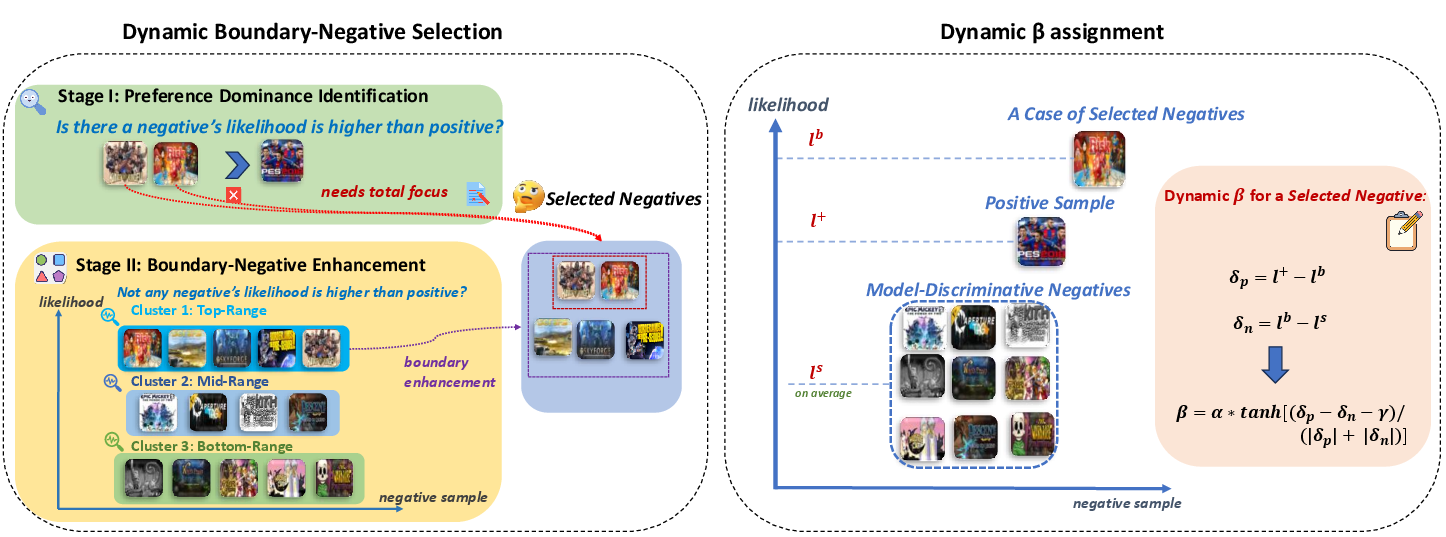
Figure 2: Overview of DynamicPO: dynamic boundary negative selection and dynamic beta-adjustment.
Dynamic Boundary Negative Selection
The first mechanism adaptively identifies and prioritizes negatives that reside near the current model’s preference boundary. It operates in two online stages:
- Preference Dominance Identification: Hard negatives violating the preferred ordering (model scores them above the positive) are targeted.
- Likelihood Clustering: Absent strict violations, boundary-near negatives are identified via K-means clustering of negative likelihoods, automatically focusing on ambiguous, high-likelihood negatives.
The selection frequency and coverage of boundary-critical negatives are tracked and shown to increase in later training stages, evidencing successful focusing of optimization on hard cases.
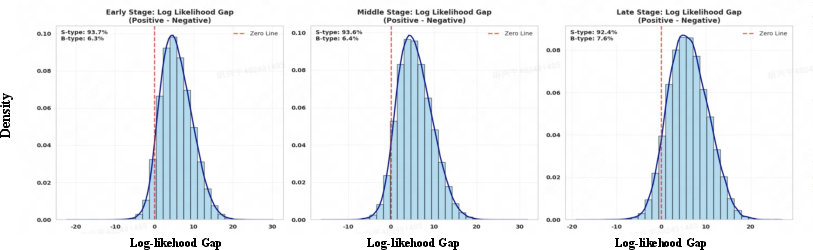
Figure 3: Proportions of S (trivial negatives) and B (boundary-critical negatives) over three training stages in DMPO.
Dual-Margin Dynamic β Adjustment
The second mechanism applies a dual-margin scheme: β for each boundary negative is dynamically adjusted based on two distances—(1) ambiguity between the positive and boundary negative, (2) informativeness contrast between boundary negative and trivial negatives. The formula ensures fine-grained plasticity: ambiguous, informative negatives induce lower β for aggressive adaptation, while trivial cases receive higher β for stability. The result is fine-specific gradient modulation, enabling sharper and more reliable preference boundaries.
Empirical Evaluation
DynamicPO is evaluated on three public sequential recommendation datasets (LastFM, Steam, Goodreads), employing Llama2-7B, Llama3-8B, and Qwen2.5-7B as LLM backbones. Performance is reported primarily via HitRatio@1 under large-scale candidate sets.
DynamicPO outperforms both traditional neural recommenders (GRU4Rec, Caser, SASRec) and recent LLM-based SFT/fine-tuning methods (MoRec, TALLRec, LLaRA). Most notably, when compared to preference optimization baselines (DMPO, MPPO, S-DPO), DynamicPO shows consistent and substantial improvement, especially in high negative-sample regimes where base methods fail due to collapse.
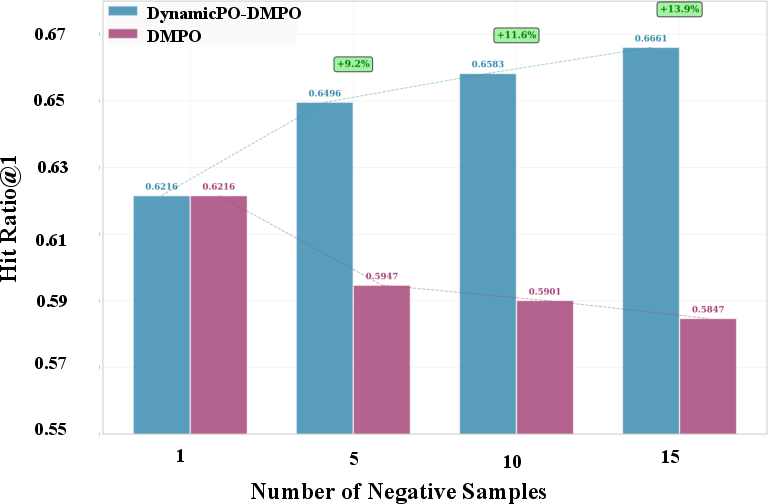
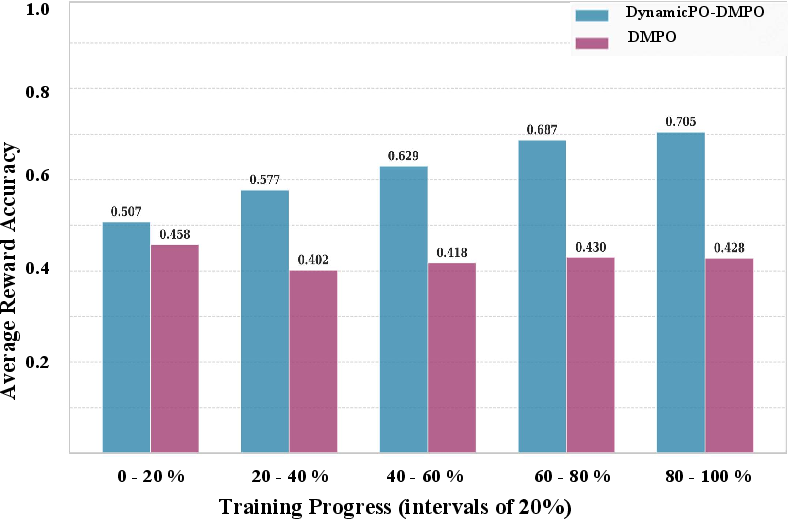
Figure 4: Effect of negative sample scaling and reward evolution on model performance in DMPO and DynamicPO.
DynamicPO consistently prevents performance collapse as negatives increase, in contrast to DMPO’s sharp decline. HitRatio@1 increments of up to 8% (e.g., +8.1% absolute on Llama2-7B for LastFM at 15 negatives) are observed, and the “reward win rate”—a proxy for boundary sharpness—improves by nearly 28% in later training compared to DMPO.
Furthermore, DynamicPO’s improvements generalize across multi-negative DPO variants and LLM architectures without additional computational overhead (<1% time increase), demonstrating its architectural agnosticism and scalability.
Analysis and Ablation
Detailed ablations verify that both stages of negative selection and the dynamic β adjustment contribute non-trivially to observed gains. Removing either boundary selection substage or substituting rigid Top-K truncation for adaptive clustering results in notable performance drops. Hyperparameter sweeps on K0 (preference margin) and K1 (intensity) show robustness—DynamicPO remains stable and performant across a broad hyperparameter range.
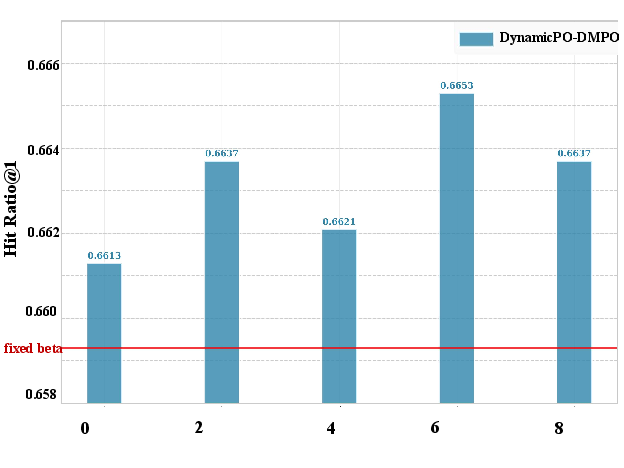
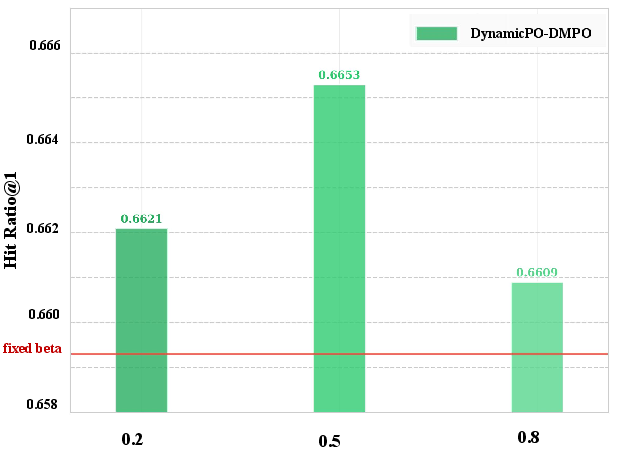
Figure 5: Study of K2 and K3 of DynamicPO on LastFM.
The analysis of negative sample proportions reveals that, without DynamicPO, the fraction of unresolved, boundary-critical negatives perversely increases during training, in line with theoretical predictions about gradient suppression. DynamicPO reverses this trend and maintains focus on hard cases throughout learning.
Implications and Future Directions
DynamicPO introduces algorithmic mechanisms for robust decision boundary sharpening in LLM-based recommendation. Its core methodological contributions—adaptive, online focusing of optimizer gradient budget on boundary-critical negatives and sample-specifically dynamic regularization—have wider implications for other implicit-feedback and preference-optimization domains where negative class imbalance and spurious optimization are problematic.
Practically, this method enables the safe scaling of negative samples, removing a key empirical barrier for data-rich, high-capacity recommenders. The plug-and-play nature means DynamicPO can be deployed in production pipelines without altering data preprocessing or introducing significant compute overhead.
Theoretically, the identification and formalization of preference optimization collapse provides a new lens for analyzing optimization dynamics in multi-sample, high-capacity alignment settings. Future work could extend DynamicPO-style boundary-aware methods to integrate structural constraints, leverage user-user relations, or support explainability and counterfactual robustness in recommendation.
Conclusion
DynamicPO provides a principled, effective, and robust solution to the collapse phenomenon plaguing multi-negative preference optimization in LLM-based recommenders. Through real-time, distribution-aware selection of informative negatives and dual-margin-based adjustment of optimization strength, the method advances both practical performance and theoretical understanding of LLM alignment in structured recommendation settings. Its zero-cost integration into existing frameworks and strong empirical demonstrating across a range of datasets and models position DynamicPO as a foundation for future advances in preference modeling and adaptive optimization for LLM-driven recommendation systems (2605.00327).