- The paper introduces RoDPO, enhancing direct preference optimization for multimodal sequential recommendation with a novel stochastic Top-K negative sampling strategy.
- It integrates a sparse Mixture-of-Experts encoder to achieve scalable and efficient multimodal fusion of text and image features.
- Experimental results show significant ranking improvements (up to +5.25% NDCG@5 and +7.67% MRR@5) across diverse e-commerce benchmarks.
Robust Preference Alignment for Multimodal Sequential Recommendation with RoDPO
Introduction
The paper "Aligning Multimodal Sequential Recommendations via Robust Direct Preference Optimization with Sparse MoE" (2603.29259) presents RoDPO, a framework for aligning Multimodal Sequential Recommendation (MSR) models with user preferences under implicit feedback. This work addresses the systemic brittleness observed with Direct Preference Optimization (DPO) when naively adapted to recommendation, due to the prevalence of false negatives among unobserved items. The authors’ primary contribution is a negative sampling strategy—Stochastic Top-K Negative Sampling—that stabilizes DPO training and substantially improves ranking accuracy. The framework integrates a sparse Mixture-of-Experts (MoE) encoder for scalable multimodal fusion and maintains competitive inference efficiency.
Problem Setting and Challenges
MSR leverages sequential user–item interactions augmented with heterogeneous modalities (text, image) to model dynamic preferences. Traditional training regimes utilize pointwise objectives (e.g., Cross-Entropy), which fail to encode relative preference rankings. Recent advances in LLM alignment—especially RLHF and DPO—motivate the adoption of pairwise preference optimization, but there are domain-specific obstacles when ported to RecSys.
Naive application of DPO in RecSys suffers due to the ill-posed assumption that all non-interacted items are strictly negative. However, in real-world implicit feedback, many items are simply unexposed. Hard negative mining thus frequently selects false negatives for penalization, yielding corrupted gradients that degrade ranking boundaries and model generalization.
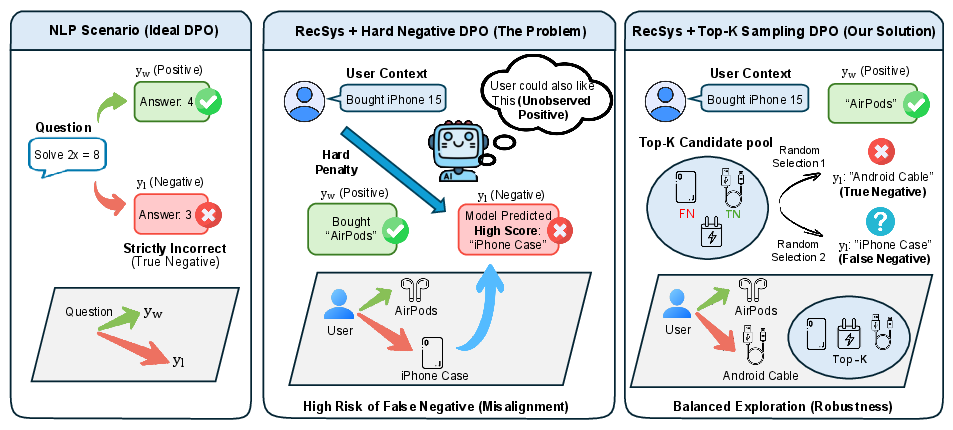
Figure 1: Schematic of the "False Negative" dilemma—NLP negatives are reliable, RecSys hard negatives often include unobserved positives, and Top-K sampling mitigates mis-penalization.
RoDPO Framework
RoDPO comprises two central innovations: (1) robust preference construction via stochastic Top-K negative sampling and (2) a scalable multimodal encoder architecture augmented with Sparse MoE.
Multimodal Sequential Encoder
The model is agnostic to architectural backbone but employs modality-specific Transformer encoders to process item IDs and pre-extracted multimodal features, further refined via a temporal module and an optional Sparse MoE layer for parameter-efficient scaling. The fusion weights among modalities are learned, enabling adaptive integration of complementary signals while preserving sequential and temporal dynamics.
Stochastic Top-K Negative Sampling
Rather than deterministically choosing the hardest negative, RoDPO defines a dynamic candidate pool consisting of the top K scoring non-target items at each iteration, from which one is sampled uniformly as the negative. This procedure maintains the advantages of hard negatives (strong gradients) while introducing stochasticity to amortize the risk of repeatedly misclassifying unobserved positives as negatives.
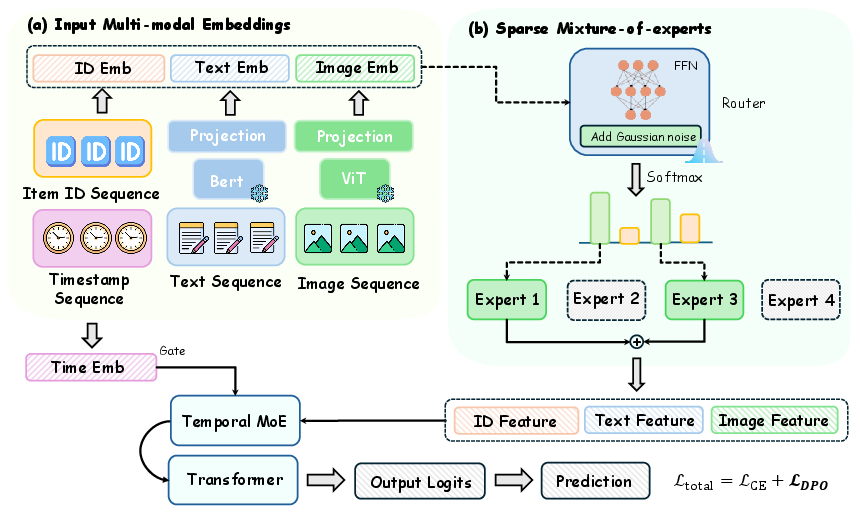
Figure 2: RoDPO high-level architecture—multimodal encoding (left) and stochastic preference pair sampling with DPO training (right).
Direct Preference Optimization Objective
RoDPO leverages DPO to align the current model πθ with a reference policy πref derived by supervised pretraining. For each preference pair (yw,yl), the DPO loss is computed as:
LDPO(x,yw,yl)=−logσ(β[Δsθ(x,yw,yl)−Δsref(x,yw,yl)])
where Δsθ(x,yw,yl)=sθ(x,yw)−sθ(x,yl), and β controls the strength of preference enforcement. Training proceeds in two stages: warm-up via standard likelihood, followed by RoDPO fine-tuning with a frozen reference model.
Empirical Evaluation
Comprehensive experiments were conducted on Amazon-Toys, Beauty, and Home & Kitchen benchmarks. RoDPO demonstrates robust and significant improvements across all evaluation metrics (NDCG@5, MRR@5) relative to diverse time-aware, multimodal, and state-of-the-art baselines.
Strong Numerical Results:
- RoDPO yields up to +5.25% NDCG@5 and +7.67% MRR@5 improvement over HM4SR and other leading baselines.
- Performance gains remain consistent across cutoffs and are observed in all tested domains.
Key ablations isolating negative sampling strategies confirm that hard negative mining is only marginally beneficial over random sampling—a direct consequence of false negative risk. Stochastic Top-K0 sampling robustly outperforms both.
Analysis and Ablations
- Negative Sampling Size (K1): Small K2 degenerates to hard mining and is sensitive to noise; large K3 resembles random sampling and attenuates gradients. Optimal performance is realized at K4, balancing hardness and stochastic smoothing.
- DPO Coefficient (K5): Best results at K6; higher than typical NLP settings, reflecting the higher false-negative risk in RecSys and the need for steadfast alignment.
- Sparse MoE: When enabled, this module yields further (albeit incremental) improvements in fine-grained preference discrimination without inflating inference cost.
- Efficiency: RoDPO matches the inference and training efficiency of competitive methods due to sharing frozen reference weights and partial expert activation in MoE layers.
Preference distribution visualizations exhibit that RoDPO effectively suppresses the model’s overconfidence in hard negatives, redistributing the logit density and yielding a more robust preference margin.
Case Study
A representative user preference trace demonstrates that RoDPO avoids the semantic similarity trap inherent to strong baselines, surfacing relevant but semantically diverse items (matching latent intent present in historical behavior), attributable to robust preference optimization and effective negative candidate balancing.
Theoretical and Practical Implications
This work underscores the necessity of domain-aware adaptation of preference optimization: DPO’s efficacy in LLMs does not directly translate to RecSys due to divergent negative set semantics. Correctly resolving false-negative sensitivity is critical for practical deployment, especially as RecSys models scale to multimodal and foundation architectures.
The light-touch nature of Top-K7 sampling, which requires only modifications to the negative selection procedure, makes RoDPO applicable as a plug-in to a wide spectrum of backbone architectures and market domains.
Limitations and Future Work
While empirical gains are decisive on e-commerce datasets, generalization to other domains (e.g., short-video, news, or personalized content streams) merits further validation. Scaling training to extremely large item catalogs and multimodal feature sets may incur heightened cost, motivating further research in efficient candidate selection and reference model distillation.
Conclusion
RoDPO demonstrates that robust stochastic negative sampling is a crucial enabler for effective DPO-based alignment in sequential recommendation with implicit feedback. By harmonizing model capacity, optimization stability, and sensitivity to the structural properties of RecSys data, RoDPO closes a critical gap in preference alignment methodologies. The framework paves the way for principled large-scale preference-driven alignment under weak signals and offers immediate applicability to multimodal, sequential recommendation foundations.