- The paper introduces a surrogate for group-wise DPO that decouples sample activations while preserving first-order gradient equivalence.
- It demonstrates that group-wise training yields substantial performance gains over pairwise approaches in tasks like math, reasoning, coding, and instruction-following.
- The method achieves flat GPU memory usage and enhanced stability using positive-response NLL regularization, making large group training practically scalable.
GroupDPO: Memory-Efficient Group-Wise Direct Preference Optimization
Motivation and Context
Direct Preference Optimization (DPO) has become a standard technique for aligning LLMs with preference data, but conventional approaches are limited to pairwise comparisons—single positive/negative response pairs per prompt—despite modern preference datasets often containing multiple candidate responses per prompt. This restriction squanders valuable inter-response supervision inherent in the data. Recent developments have extended DPO to group-wise or listwise objectives, but computational bottlenecks, particularly GPU memory constraints resulting from cross-sample coupling in the loss, have hindered both empirical study and practical scalability.
Surrogate Objective for Group-Wise Preference Learning
The core methodological contribution is a memory-efficient surrogate for group-wise DPO that decouples activations across samples while preserving first-order gradient equivalence to the coupled groupwise objective. Standard group-wise loss computation requires activation retention for all candidate responses in a group until the backward pass, resulting in high memory overhead as group sizes increase, which severely limits practical group size and thereby the benefit of richer supervision.
The surrogate approach first performs a parameter-free, no-gradient forward pass to acquire the current implicit preference scores for all candidate responses. It then computes constant per-sample coefficients via the derivatives of the group loss evaluated at these no-grad scores. The backward pass then optimizes the sum of per-sample (coefficient × preference score), ensuring the parameter gradients match the true group objective at the current iterate but without inter-sample dependency in the backward graph. This makes GPU memory usage essentially invariant to group size.
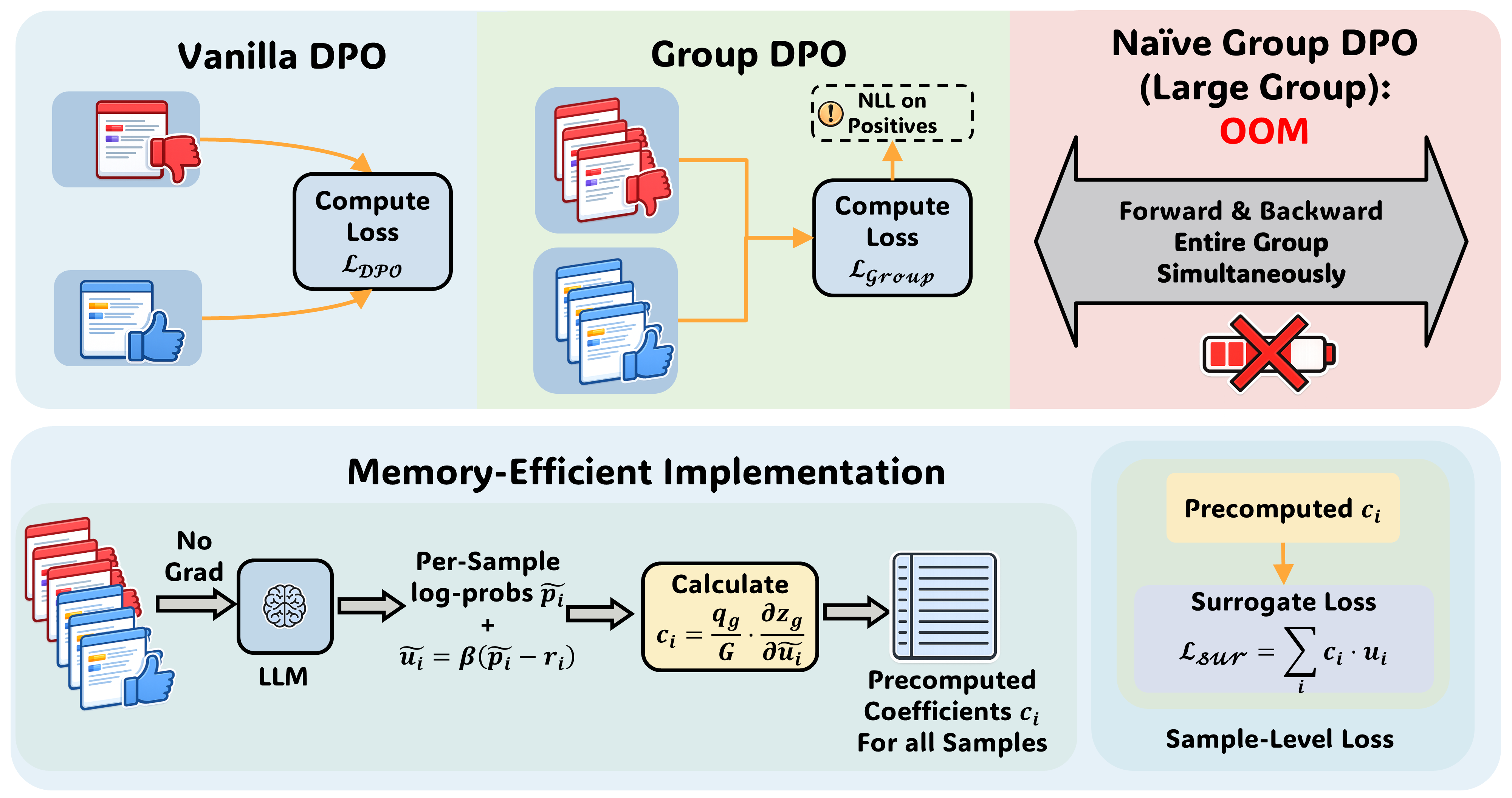
Figure 1: Standard DPO is contrasted with group-wise objectives, where the surrogate implementation avoids joint backpropagation, enabling large group training without OOM.
Empirical Evaluation
Across both offline and online alignment scenarios, with a systematic comparison over multiple DPO variants (Margin, MPO, All-Pairs, Softmax), the study demonstrates that group-wise training leveraging multiple responses per prompt strictly dominates the pairwise baseline in terms of generalization across math, reasoning, coding, and instruction-following tasks. Notably, the performance gain is robust to the particular group-wise formulation used; all tested variants offer similar improvements relative to single-pair DPO.
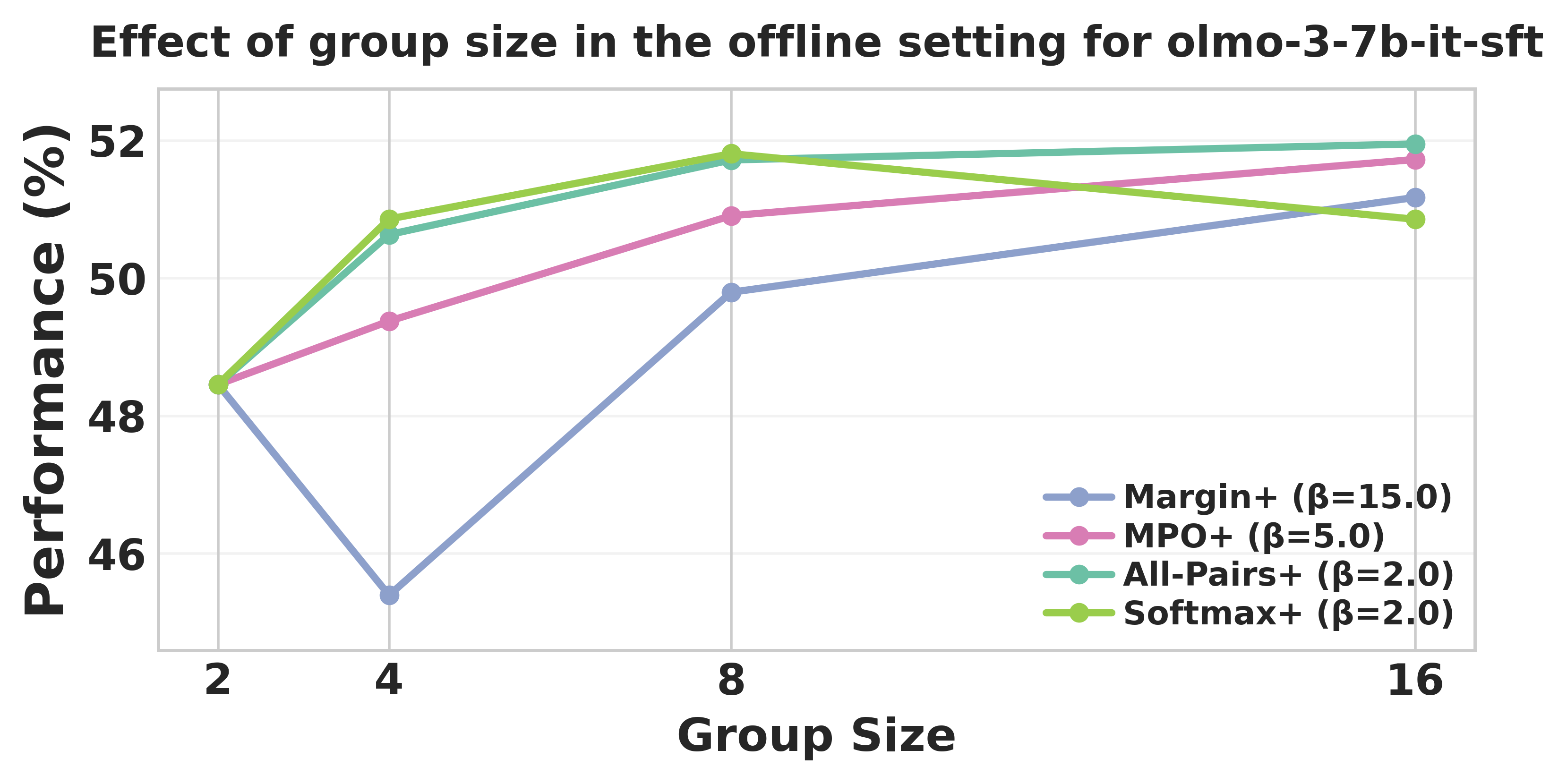
Figure 2: Increasing group size in olmo-3-7b-it-sft yields monotonic performance improvement up to moderate group sizes.
Strong numerical improvements are observed across all model families, including olmo-3-7b and olmo-3.1-32b checkpoints, as well as in the qwen3-4b-base online alignment regime.
Sample Size Scaling and Signal Saturation
Analysis of group size shows that increasing the number of candidate responses per prompt improves downstream performance up to a moderate threshold (≈8 candidates), beyond which saturation or signal-to-noise trade offs emerge. Thus, the benefit of large groups can be realized in practice, provided memory constraints are resolved—a critical motivator for the surrogate implementation.
Positive-Response NLL Regularization Is Critical
An important empirical result is the necessity of a negative log-likelihood (NLL) regularization term on positive responses. Inclusion of the positive-sample NLL acts as a stabilizer, preventing collapse and degradation of the model’s likelihood over positive responses during group-wise alignment. Omitting this regularizer frequently yields unstable optimization and lower final task accuracy across all tested settings.
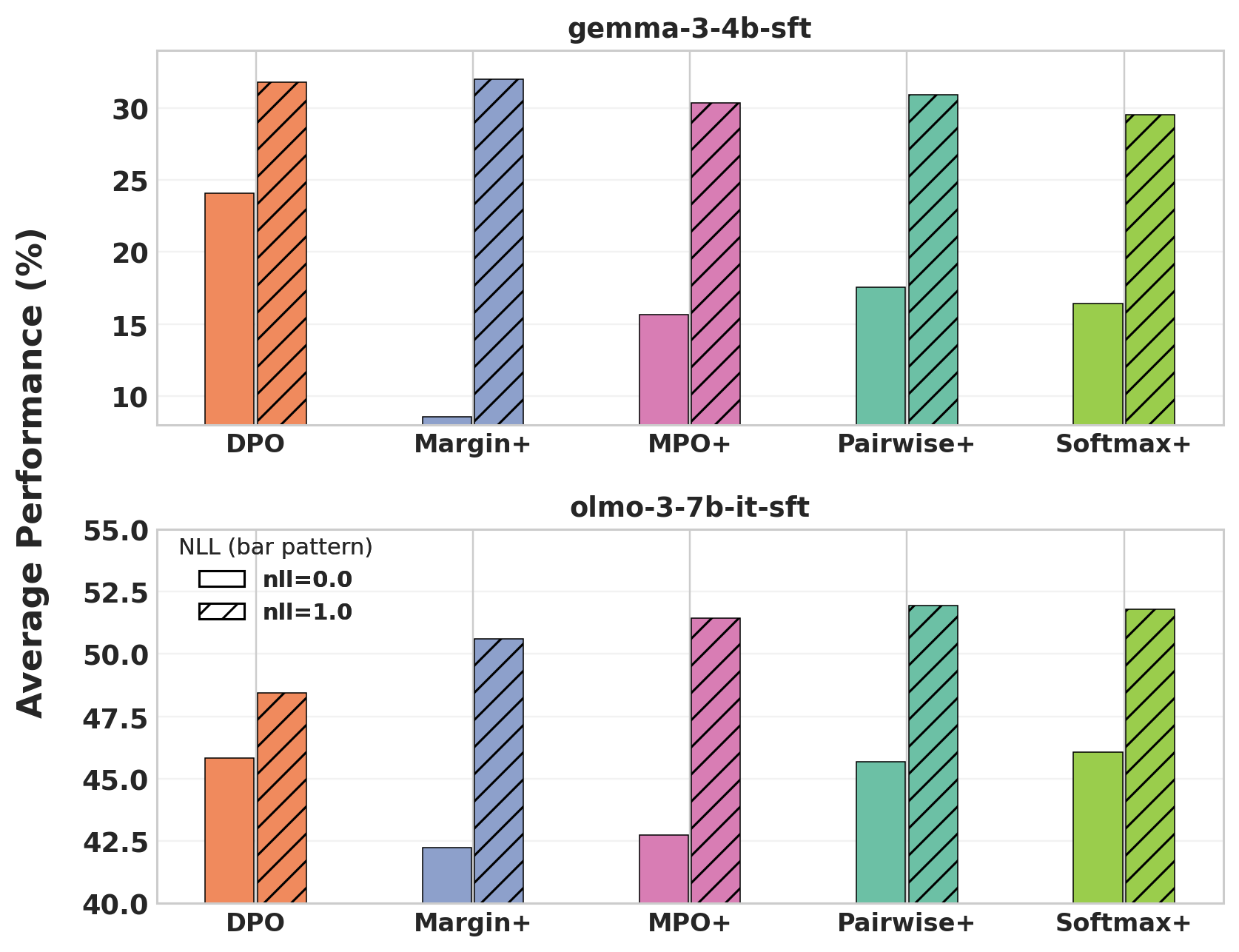
Figure 3: Inclusion of the NLL term (α=1) consistently yields higher average performance than omitting it (α=0) across both models and objectives.
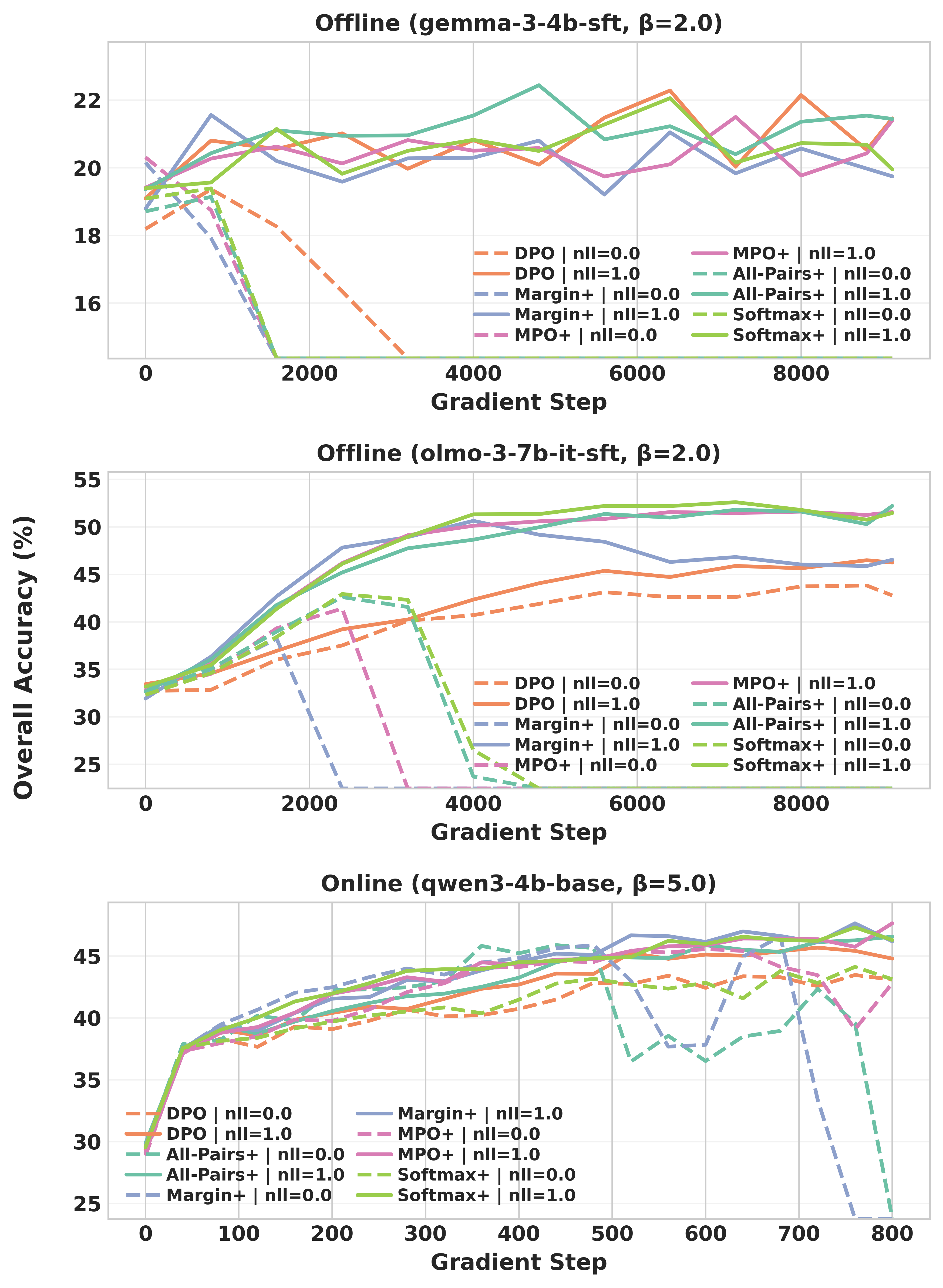
Figure 4: Training curves reveal that NLL-free group-wise training often collapses, while NLL-regularized runs are stable and performant.
Memory and Latency Analysis
The surrogate implementation delivers radical memory savings compared to the vanilla (fully coupled) group DPO or naïve flattening approaches. Whereas vanilla implementations quickly exhaust GPU memory with increasing group size or sequence length, the surrogate maintains flat, low memory requirements with only a modest latency overhead, thus enabling batch and sequence scaling on standard hardware.
Figure 5: Surrogate implementation achieves low, group-size-invariant memory overhead and modest extra latency in olmo-3-7b-it-sft.
Figure 6: A similar pattern of memory savings is confirmed in gemma-3-4b-sft with the surrogate extending viability into substantially larger group/batch regimes.
Practical and Theoretical Implications
From an applied perspective, the surrogate group-wise DPO method renders previously impractical groupwise or listwise preference training feasible for current and future LLM post-training pipelines. This unlocks richer supervision curves without requiring reward model training, RL-based optimization, or bespoke hardware arrangements. The approach is compatible with standard first-order optimizers, though as the surrogate is only first-order gradient exact, second-order methods or hyperparameter schedules that depend on Hessian structure may not be guaranteed equivalent.
Theoretically, these findings reinforce the hypothesis that information contained in the relative ranking among multiple samples per prompt contains signal lost in pairwise binarization, and that unlocking this signal is not merely a function of objective sophistication but, crucially, of computational feasibility.
Future Directions
Several open questions emerge:
- Extended Listwise Objectives: The methodology is easily extended to more complex listwise objectives or to structured target sets such as partial orders; this may further close the gap between LLM training and classical learning-to-rank.
- Second-Order Optimization: While the surrogate is first-order equivalent, the impact of second-order misspecification for adaptive training warrants further formal and empirical study.
- Generalization to Multi-Task or Multi-Modal Preference Data: The surrogate decoupling principle may be further leveraged for joint training on complex, multi-task datasets or in multi-modal RLHF settings.
Conclusion
GroupDPO introduces a practical, scalable approach to group-wise preference optimization, delivering consistent, architecture- and task-agnostic gains over pairwise DPO while also decisively resolving the computational barriers that have previously stymied its adoption. Empirical results affirm the necessity of positive-sample NLL regularization in stabilizing alignment and maximizing benefit from rich candidate response sets. The method's favorable memory/latency tradeoff makes it a robust choice for both research and production settings and positions group-wise preference learning as a future default for LLM post-training (2604.15602).