- The paper presents an iterative multimodal retrieval-augmented framework for medical QA that leverages page-image embeddings to capture complex visual and textual cues.
- It integrates vision-language models with memory-augmented iterative reasoning to improve accuracy by 5.8 percentage points over text-only baselines.
- The system demonstrates robust multi-hop evidence aggregation, addressing retrieval challenges in biomedical literature with scalable, interpretable architecture.
Iterative Multimodal Retrieval-Augmented Generation for Medical Question Answering
Introduction and Motivation
Medical domain question answering (QA) presents unique challenges due to heterogeneous evidence forms, often originating from complex page layouts comprising mixed text, tables, and figures in primary biomedical literature. Existing RAG frameworks in medical QA predominantly rely on retrieval from linearized, OCR-parsed text, systematically neglecting structural and visual cues that are critical for precise knowledge extraction. Furthermore, single-pass retrieval pipelines are suboptimal for multi-hop questions that necessitate the aggregation of evidence spanning multiple documents.
This work introduces an iterative multimodal RAG framework explicitly tailored for medical QA, operating over page-level document images rather than isolated textual chunks. By leveraging vision-LLMs (VLMs) capable of processing both visual and textual modalities, and by adopting an iterative, memory-augmented reasoning procedure, the system aims to improve both the robustness and interpretability of medical answer generation.
Figure 1: The system architecture integrates ColQwen2.5 for page-image embedding, fast FAISS-based retrieval, an LLM-based candidate filter, and iterative VLM-based reasoning with memory across up to three rounds.
System Architecture
The pipeline involves four principal stages. First, each page of the ~350K PubMed Central (PMC) OA document corpus is rendered at native resolution and encoded using ColQwen2.5 (a ColPali variant with Qwen2.5-VL backbone) to obtain multi-vector, patch-level page embeddings, PCA-reduced for scalability. These embeddings populate a FAISS-based index with a two-tiered retrieval scheme: ANN over per-page centroids followed by exact fine-grained vector-wise scoring.
Given a medical question, the system retrieves the top-2,000 candidate pages by embedding similarity (Stage 1). These candidates, represented by brief, LLM-generated summaries, are then filtered by a sharded MapReduce LLM (Qwen3-30B-A3B), narrowing the set to the top-100 (Stage 2). The highest-ranked 10 page images, alongside 20 top summaries and a structured memory bank, are then presented to a VLM (Qwen2.5-VL-32B-Instruct) that executes iterative reasoning: it may output an answer or emit a refined query for further retrieval, looping for up to three rounds. The memory bank accumulates key findings and reasoning history, enabling both information retention and auditability across iterations.
Experimental Evaluation
The framework is evaluated on four prominent medical QA benchmarks: MedQA, MedMCQA, PubMedQA, and MMLU-Med. All evaluations are zero-shot with no context leakage, using identical backbones and decoding settings for controlled ablation. The full system achieves an average accuracy of 78.6% across these datasets, surpassing the no-retrieval baseline (Qwen2.5-VL-32B) by +5.8 percentage points. This includes:
- +1.0 from employing page-image versus text-chunk retrieval;
- +1.5 from iterative (multi-round) reasoning;
- +1.0 from the inclusion of a memory bank.
Notably, comparison with previous best-performing open-source, text-only RAG frameworks—such as MedRAG with GPT-4—shows a +1.8 point edge (albeit with the caveat of cross-paper methodology differences).
Iteration analysis shows that a majority of questions (mean 61.4%) are resolved after a single VLM reasoning round, 24.8% require two rounds, and only 13.8% necessitate all three rounds.
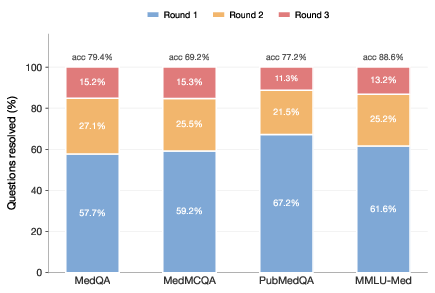
Figure 2: Iteration count distribution indicates most queries are resolved in the first round, with three-round paths serving only the most complex questions.
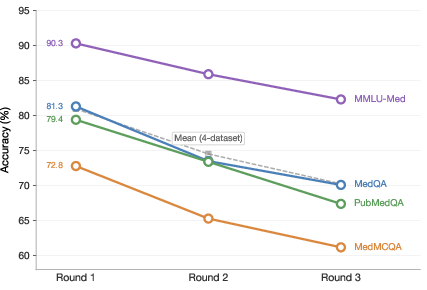
Figure 3: Accuracy as a function of iteration count; multi-iteration questions yield weighted average accuracy of 72.9% in later rounds, indicating successful recovery on challenging cases.
Latency per 3-round pipeline is 47.8 seconds on 4 × NVIDIA A100 GPUs, with retrieval consistently under 30 ms and iterative VLM inference dominating computational cost.
Empirical Analysis, Ablation, and Error Taxonomy
Ablation experiments effectively isolate each major system component's impact. Direct comparison to a text-only RAG baseline using BGE-large embeddings confirms the necessity of visual modality: medical evidence commonly relies on tabular data, diagnostic flowcharts, and spatial context inaccessible to purely textual models. Manual error classification of failure cases on MedQA reveals that 35.9% are due to retrieval miss, 19.7% to LLM filter miss, 29.5% to VLM misinterpretation, and 14.9% to iteration drift.
A major finding is the resilience of the image-based system to contextual noise, an issue frequently observed in text-only RAG. Unlike prior systems that occasionally exhibit performance regressions under conflicting chunk contexts, the proposed system avoids these degradations even on benchmarks known to be sensitive to irrelevant context injection.
Detailed inspection of the memory bank—serving as both information persistence and a per-round audit trail—demonstrates its role in preventing reasoning drift and enabling systematic coverage of multi-hop queries. Accuracy gains from iterativity are shown to be largest on problems requiring synthesis of scattered evidence, mirroring real-world clinical information-seeking processes.
Implications and Future Directions
This research demonstrates that page-level multimodal retrieval, iterative VLM-based reasoning, and architectural memory contribute additive, though modest, improvements to the state-of-the-art in medical QA. Maintaining evidence in its original, visually rich format supports better alignment with human interpretability and downstream clinical validation. The iterative architecture also mirrors actual clinician search strategies, providing a foundation for future systems requiring transparent evidence chains.
Potential avenues for extension include integrating guideline repositories and clinical textbooks into the retrieval corpus, optimizing latency through confidence-calibrated early stopping, and moving beyond multiple-choice benchmarks to free-form or open-ended clinical QA. More robust statistical comparisons, stronger text baseline retrievers, and clinician-in-the-loop deployments represent important milestones toward trustworthy, real-world AI clinical decision support.
Conclusion
The iterative multimodal RAG framework for medical QA, built on ColQwen2.5-based image retrieval, LLM filtering, and memory-augmented VLM reasoning, attains 78.6% average accuracy over four rigorous medical QA datasets—a +5.8 point gain over its no-retrieval counterpart. Each innovation—modality shift to page images, iterativity, and use of accumulated memory—contributes distinct accuracy improvements. While the numerical margins are narrow, the architecture sets a new empirical and methodological standard for knowledge-intensive multimodal reasoning under compute and interpretability constraints, warranting systematic future study and extension.