- The paper introduces Philautia-Eval, a normalization framework that isolates self-preference bias in multimodal evaluations.
- It reveals significant self- and family-level biases with philautia scores often exceeding two standard deviations above the mean.
- By applying the Pomms ensemble method, the study achieves substantial bias reduction while maintaining strong correlation with human judgment.
Model-Specific Preference Bias in MLLM-as-a-Judge
Introduction and Motivation
The automatic evaluation of outputs produced by multimodal LLMs (MLLMs) is a critical component of current vision-language research. The prevailing paradigm—MLLM-as-a-Judge—delegates to MLLMs not only the generative image captioning task but also the evaluation of generated captions, enabling large-scale, cost-efficient benchmarking. This paradigm, however, is susceptible to model-specific preference bias: the tendency of an MLLM to systematically favor, or disfavor, outputs originating from itself or from closely related models. Such biases undermine the reliability and scientific utility of empirical benchmarking, especially in settings characterized by opaque architectures and overlapping pretraining resources. The investigation presented in "MLLM-as-a-Judge Exhibits Model Preference Bias" (2604.11589) systematically quantifies and disentangles these biases, providing new tools and data to properly interrogate and mitigate their effect.
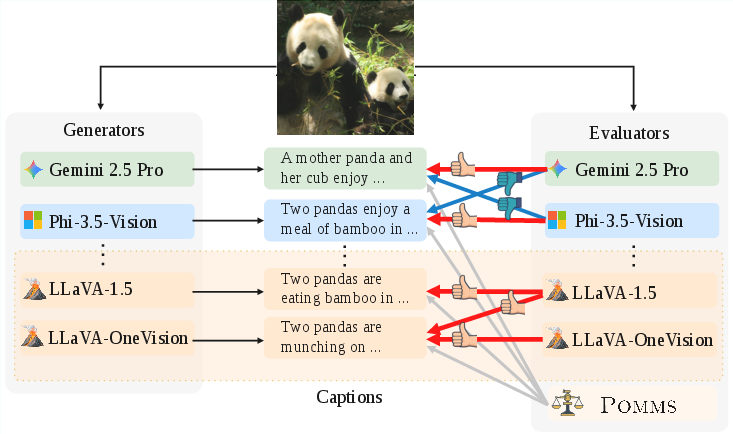
Figure 1: Schematic showing the evaluation pipeline and model preference biases in MLLM-as-a-Judge.
Methodology: Philautia-Eval
A fundamental methodological challenge is decoupling preference bias from differences in inherent sample quality. Prior approaches fail to disentangle these confounds, leading to ambiguous conclusions regarding source and magnitude of bias. The paper introduces Philautia-Eval, leveraging cross-model scoring to produce a matrix Φ across all Generator-Evaluator pairs, followed by sequential column-wise and row-wise standardization, resulting in Φ~. This normalization equalizes both score distribution per Evaluator (column) and Generator (row), isolating actual preferential relationships from raw model quality disparities.
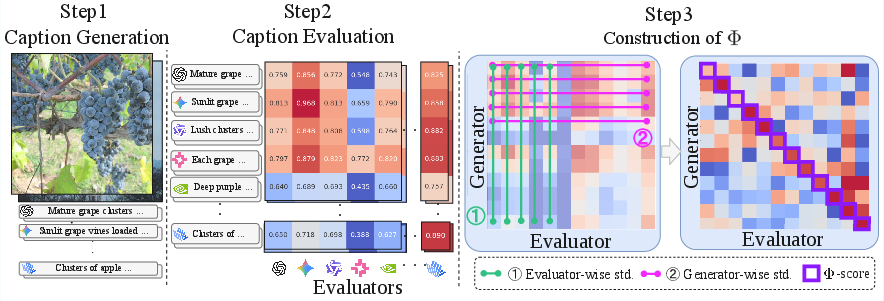
Figure 2: Philautia-Eval pipeline—generation, evaluation, and matrix standardization isolate true model-specific preferences.
The diagonal elements of Φ~ (the "philautia score") quantify self-preference bias: the extent to which models favor their own generations after controlling for confounds. Off-diagonal patterns reveal cross-model preference structure.
Dataset: SelfEval-Cap
Existing datasets are poorly matched to systemic preference analysis, lacking either sufficiently diverse candidate MLLMs or associated multi-model evaluation scores. The authors curate the SelfEval-Cap dataset: 54k captions generated by 12 diverse MLLMs over 4,500 images, each caption scored by all 12 Evaluators in both reference-based and reference-free conditions. The selected models span proprietary and academic open weights, various vision encoders (ViT, CLIP, SigLIP), and multiple language backbones (Qwen2.5, Vicuna, InternLM2.5), ensuring substantial architectural and pretraining diversity.
Empirical Results: Self- and Cross-Preference Bias
Self-Preference Bias
Applying Philautia-Eval, the analysis reveals strong and consistent self-preference bias for all evaluated MLLMs across both reference-based and reference-free settings. All models' philautia scores (diagonal entries of Φ~) are significantly greater than zero, typically exceeding 1.0 in standardized units, indicating a robust intrinsic preference for self-generated outputs.
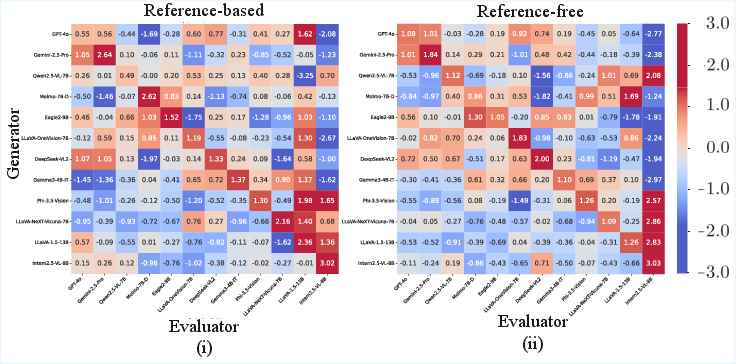
Figure 3: Visualizations of standardized preference matrices show all models favor their own outputs (positive diagonal).
Cases such as InternVL2.5-8B (philautia score ≈ 3.0) and Gemini-2.5-Pro (2.64) exemplify severe bias magnitude, frequently exceeding two standard deviations from the overall mean. This phenomenon is further evidenced by qualitative examples: MLLMs overrate their own captions, even in the presence of hallucinations or content errors.
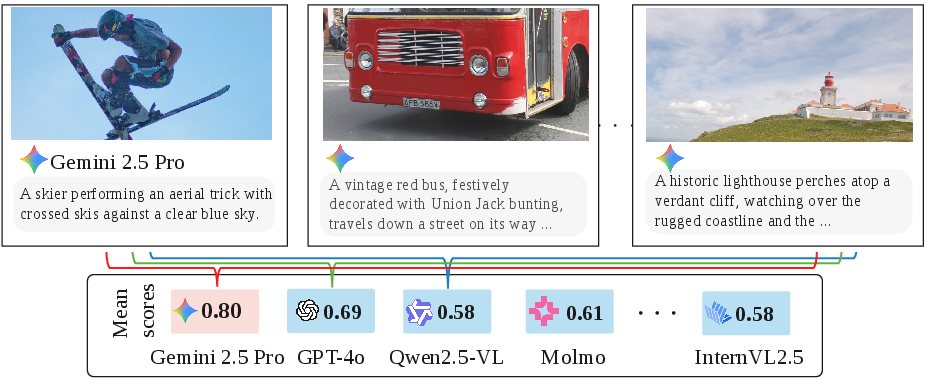
Figure 4: Gemini 2.5 Pro rates its own hallucinated caption far above all other evaluators, illustrating self-preference bias.
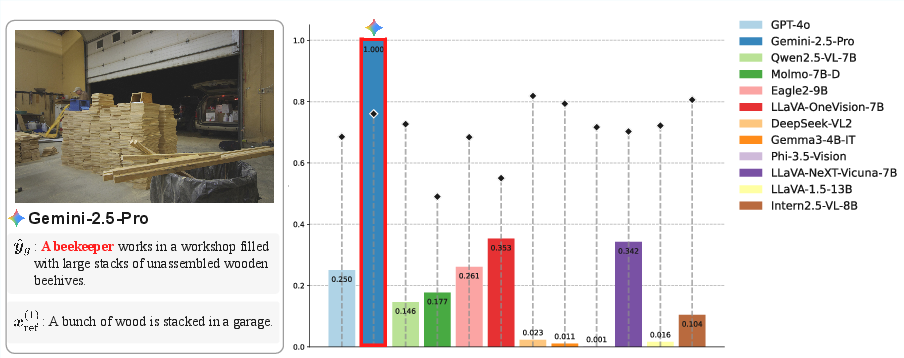
Figure 5: Bar chart showing Gemini-2.5-Pro's high self-evaluation relative to all other models on a flawed caption.
Additional examples involving DeepSeek-VL2 and LLaVA-1.5 demonstrate that this effect is widespread and not confined to a single model family.
Cross-Model Preference and Family Bias
Submatrix analysis on Φ~ exposes structured cross-model biases. Qwen-based MLLMs exhibit mutual favoritism, with 9 of 12 off-diagonal scores positive, which is statistically anomalous relative to random allocation. The LLaVA family displays a pattern where LLaVA-1.5-13B preferentially rates outputs from its own architectural descendants higher, likely reflecting shared connectors and instruction-tuning data.
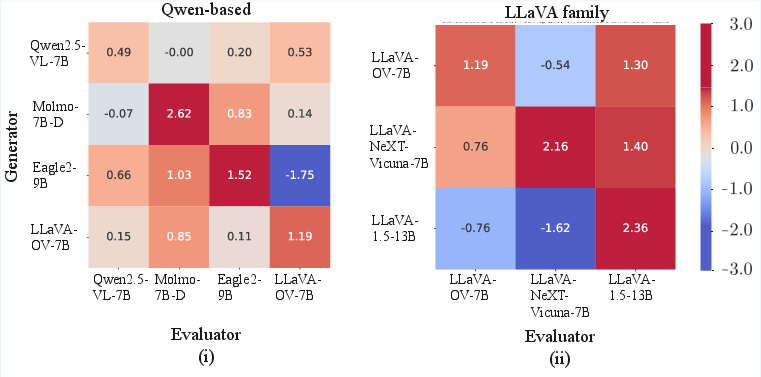
Figure 6: Within-family preference bias in Qwen- and LLaVA-based MLLMs, highlighting training pipeline entanglement.
Reference Effects
The reference-based vs. reference-free analysis shows that the availability of references modulates the bias landscape—to both amplify and suppress philautia scores in specific models, exposing the dependency of these metrics on evaluation prompt configuration.
Outlier Behavior
GPT-4o and Qwen2.5-VL-7B are notable for relatively lower philautia scores, but deeper analysis reveals these values often arise from unique cross-model antagonistic interactions rather than genuinely fair assessment.
Mitigating Bias: Ensemble Methods (Pomms)
The paper proposes the Pomms ensemble framework, in which multiple MLLM Evaluators are aggregated via lightweight meta-learning (e.g., elastic net regression with feature selection on individual model evaluations). The central hypothesis is that averaging over diverse biases dilutes individual preference idiosyncrasies.
Experimental results on SelfEval-Cap and standard reference datasets (Flickr8k-Expert, Nebula) confirm that Pomms ensembles—optimally selected—achieve significantly reduced philautia scores (as low as 0.15, compared to >1.0 for leading single models), while maintaining or marginally improving correlation with human annotations (Kendall's τ up to 57.0).
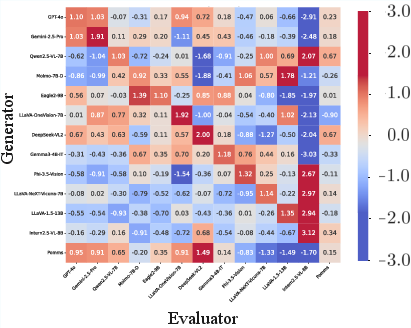
Figure 7: Ensemble-based scoring matrix demonstrating Pomms' substantial mitigation of bias across all Generator-Evaluator pairs.
Pomms not only suppresses extremes of self-preference but does so without substantive loss in overall evaluative alignment with human ground truth.
Discussion and Implications
This work validates and characterizes the model preference bias intrinsic to MLLM-as-a-Judge, exposing the risks of naive single-model evaluation normalization and the dangers of relying on cross-model benchmarks to reflect human-meaningful improvements. The demonstrated within-family biases imply that benchmark rankings are vulnerable to shifting as a function of model proliferation and pretraining entanglement. Furthermore, the finding that ensemble-based evaluation robustly mitigates these effects indicates an actionable protocol for the community to improve metric reliability, pending broader adoption.
Two critical practical considerations arise: (1) Model transparency remains limited, especially for proprietary MLLMs, complicating further causal disambiguation of observed behaviors; (2) Ensemble-based solutions, though powerful, incur increased computational cost at inference. The authors propose future work on distilling consensus preferences into lightweight scoring students, an important direction for scalable real-world deployment.
On the theoretical front, the field must define socially and scientifically acceptable bias thresholds for model-based evaluation, especially as MLLMs are increasingly interdependent in the broader language and vision pipeline ecosystem.
Conclusion
"MLLM-as-a-Judge Exhibits Model Preference Bias" provides a rigorous dissection of model-specific preference behaviors in vision-LLM evaluation, introduces the Philautia-Eval methodology for principled bias quantification, and demonstrates both the pervasiveness of self- and family-level preference and an effective, empirically validated mitigation strategy via ensembling (2604.11589). These findings have immediate consequences for the design and interpretation of MLLM benchmarks, the construction of fairer evaluation protocols, and the future development of trustworthy multimodal AI assessment.