- The paper introduces MMed-RAG, a novel retrieval-augmented generation system that reduces factual hallucination in medical vision-language models.
- The methodology integrates domain-aware retrieval, adaptive context selection, and RAG-based preference fine-tuning to improve cross-modality and overall alignment.
- Experimental results demonstrate up to 69.1% improvement in report generation and enhanced performance across radiology, ophthalmology, and pathology datasets.
MMed-RAG: Enhancing Factuality in Medical Vision LLMs through Versatile RAG
The paper "MMed-RAG: Versatile Multimodal RAG System for Medical Vision LLMs" (2410.13085) introduces MMed-RAG, a retrieval-augmented generation (RAG) system designed to improve the factual accuracy of Medical Large Vision-LLMs (Med-LVLMs). MMed-RAG addresses limitations in existing Med-LVLMs, such as factual hallucination and insufficient generalizability across medical domains, through a combination of domain-aware retrieval, adaptive context selection, and RAG-based preference fine-tuning. The experimental results demonstrate significant improvements in factual accuracy on medical VQA and report generation tasks across radiology, ophthalmology, and pathology datasets.
Problem Statement and Proposed Solution
Current Med-LVLMs often struggle with factual hallucination, distribution shifts between training and deployment data, and misalignment issues that affect cross-modality alignment and overall alignment with ground truth. To mitigate these issues, MMed-RAG incorporates three key modules:
- A domain-aware retrieval mechanism that selects appropriate retrieval models based on input medical images.
- An adaptive context selection method to determine the optimal number of retrieved contexts.
- A RAG-based preference fine-tuning strategy that enhances both cross-modality alignment and overall alignment with ground truth.
The rationale behind MMed-RAG is to provide a versatile and reliable RAG process that improves the factuality and alignment of Med-LVLMs.
Technical Approach
MMed-RAG operates through three complementary modules: domain-aware retrieval, adaptive context selection, and RAG-based preference fine-tuning.
Domain-Aware Retrieval
The domain-aware retrieval mechanism effectively handles medical images from various sources by employing a domain identification module. This module, fine-tuned on a small dataset of medical images and their corresponding domain labels, assigns a domain label d=F(xv) to each input image xv using the BiomedCLIP model. Based on this label, the image is then fed into the corresponding multimodal retriever Rd(⋅) for knowledge retrieval.
Each multimodal retriever Rd(⋅) is trained using contrastive learning, where visual and textual information Ximg,Xtxt are encoded into embeddings Vimg=Eimg(Ximg),Vtxt=Etxt(Xtxt) using respective encoders. The contrastive learning loss is applied to maximize the similarity between embeddings of the same example and minimize the similarity between embeddings of different examples:
$\mathcal{L} = \frac{\mathcal{L}_{img}+\mathcal{L}_{txt}{2}, \text{where}\;\;
\mathcal{L}_{img}=-\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(S_{i, i})}{\sum_{j=1}^{N} \exp(S_{i, j})}, \mathcal{L}_{txt}=-\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(S_{i, i})}{\sum_{j=1}^{N} \exp(S_{j, i})},$
where S∈RN×N is the similarity matrix between image and text modalities.
Finally, the top-k most similar reports xr=Rd(xv) are retrieved and provided to the Med-LVLM M(⋅) as references.
Adaptive Retrieved Context Selection
To determine the optimal amount of context, MMed-RAG employs an adaptive method based on the similarity scores of the retrieved contexts. This approach addresses the limitations of fixed-k methods, which can include lower-quality information and introduce noise. The method analyzes similarity ratios between consecutive retrievals ui=log(Si/Si+1), where Si is the similarity score of the i-th retrieved context. If ui exceeds a predefined threshold γ, the method truncates k at that point i, discarding less relevant retrievals. This adaptive truncation mitigates the risk of hallucination and improves factual accuracy.
RAG-Based Preference Fine-Tuning
MMed-RAG incorporates RAG-based preference fine-tuning (RAG-PT) to address cross-modality misalignment and overall misalignment with the ground truth. RAG-PT constructs two types of preference pairs:
- Preference pairs for cross-modality alignment, which are designed to ensure the model prioritizes the input medical image when generating responses. This is achieved by selecting a preferred response yw,o1←y and a dispreferred response yl,o1←M(xv∗,(xt,xr)), where xv∗ is a noisy image associated with a different ground truth.
- Preference pairs for overall alignment, which are designed to enhance the model's ability to leverage retrieved knowledge effectively while mitigating interference from irrelevant information. Preferred responses are selected where the model correctly answers based on both the original image and the retrieved information, while dispreferred responses represent cases where the model answers incorrectly based on the image without retrieval.
The preference dataset Dpt=Dcm∪Doa={x(i),yw,o(i),yl,o(i)}i=1N is then used to fine-tune the Med-LVLM using direct preference optimization with the following loss:
$\mathcal{L}_{pt} = -\mathbb{E}_{(x,y_{w,o},y_{l,o}) \sim \mathcal{D}
\left[ \log \sigma
\left(
\alpha \log \frac{\pi_\theta(y_{w,o} | x)}{\pi_{o}(y_{w,o} | x)}
- \alpha \log \frac{\pi_\theta(y_{l,o} | x)}{\pi_{o}(y_{l,o} | x)}
\right) \right].$
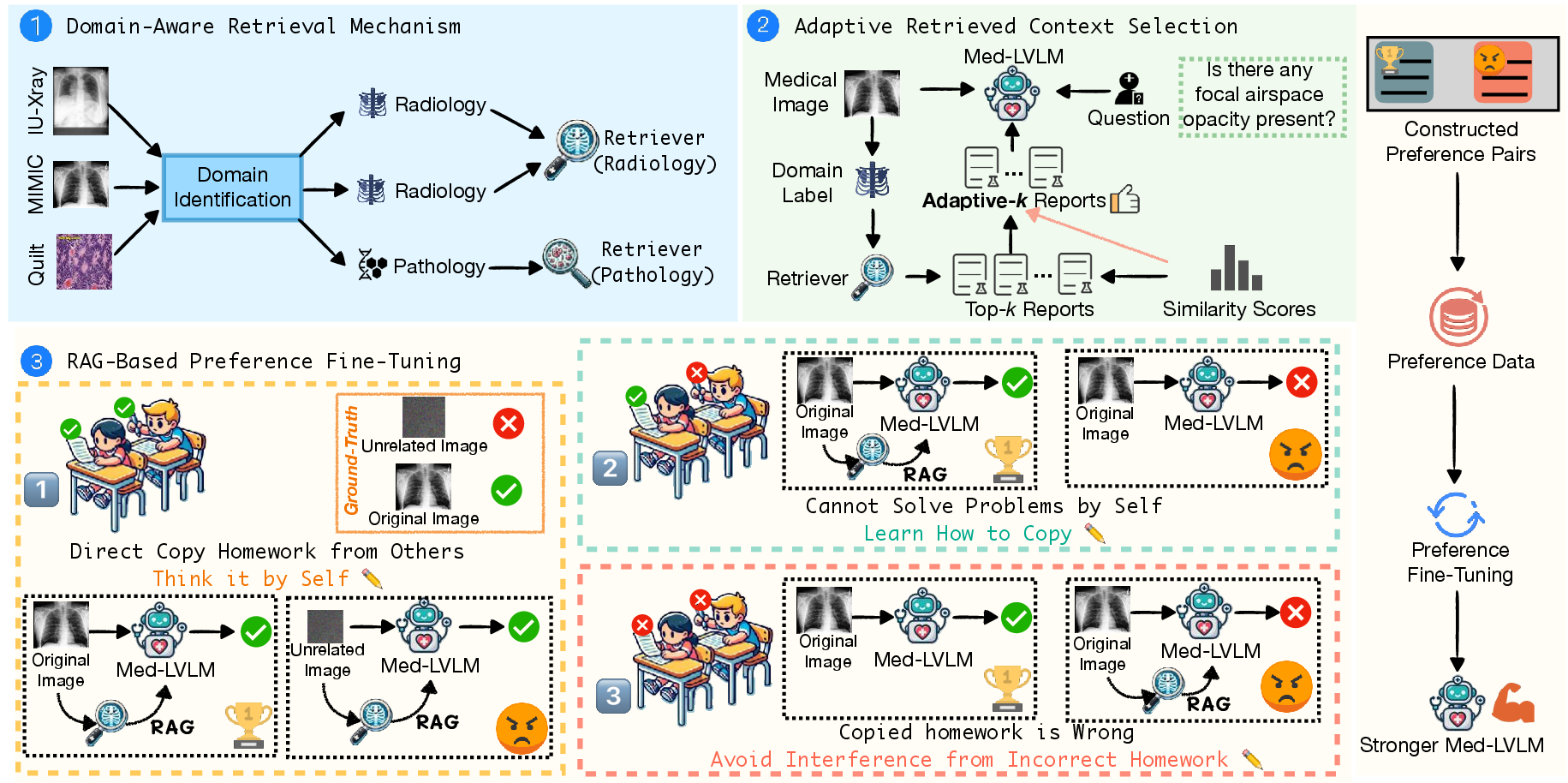
Figure 1: Overview of MMed-RAG, a versatile factual multimodal RAG system designed to enhance the reliability of Med-LVLMs.
Theoretical Analysis
The paper provides a theoretical analysis to demonstrate how MMed-RAG mitigates misalignment issues. It demonstrates that the RAG-PT approach, under certain assumptions, increases the weight of relevant images and retrieved information while reducing the weight of irrelevant information.
Cross-Modality Alignment
The cross-modality loss function adjusts the model to place greater emphasis on images, informed by the retrieved data.
Overall Alignment
By leveraging appropriate retrieved knowledge and reducing reliance on irrelevant information, the model improves overall alignment, enhancing its use of relevant information while reducing the reliance on non-helpful retrieved data.
Experimental Results and Analysis
MMed-RAG is evaluated on five medical vision-language datasets covering radiology, ophthalmology, and pathology. Compared to baseline methods, MMed-RAG achieves an average improvement of 43.8\% in the factual accuracy of Med-LVLMs. Specifically, it improves by 18.5\% and 69.1% over the original Med-LVLM in medical VQA and report generation tasks, respectively. Ablation studies confirm the contribution of each module, demonstrating that domain-aware retrieval, adaptive context selection, and RAG-based preference fine-tuning all contribute to the overall performance gains.
The paper includes visualizations of attention maps showing that, after RAG-PT, the model significantly increases its attention to visual information and reduces the interference of RAG, better aligning the model's knowledge with the fundamental facts.
Conclusion
The authors present MMed-RAG as a method to enhance the factuality of Med-LVLMs by addressing limitations related to hallucination, domain specificity, and misalignment. By integrating domain-aware retrieval, adaptive context selection, and RAG-based preference fine-tuning, MMed-RAG achieves substantial improvements in factual accuracy across various medical imaging domains. The study underscores the importance of robust multimodal RAG mechanisms for ensuring the reliability and trustworthiness of Med-LVLMs in clinical applications.
The results of the study suggest the potential for future research in several areas. Further work could investigate the development of more sophisticated preference fine-tuning techniques, the incorporation of additional modalities such as patient history and lab results, and the extension of MMed-RAG to other medical applications such as treatment planning and disease monitoring.