- The paper applies Shannon’s character-guessing experiment with 184 participants to derive human-based entropy bounds for Ukrainian text.
- It computes lower and upper bounds of 0.599 and 1.201 bits per character using rigorously preprocessed news articles and a controlled experimental setup.
- It benchmarks transformer-based language models against human performance, revealing that LLMs can achieve even lower entropy estimates, suggesting potential overfitting.
Entropy Measurement of the Ukrainian Language via Shannon's Character-Guessing Protocol
Introduction
The quantification of a language's entropy is foundational to theoretical and applied linguistics, providing a metric for unpredictability, redundancy, and information density. This paper conducts the first comprehensive application of Shannon's human character-guessing experiment to Ukrainian, addressing the absence of such empirical measurement in the literature. The experimental protocol replicates and extends methodologies established for English [Ren et al., 2019], with careful adjustment to account for the engagement dynamics and linguistic structure of Ukrainian. The work offers robust entropy bounds for Ukrainian, situates these results amid comparative linguistic entropy studies, and performs a parallel benchmark using state-of-the-art LLMs as computational predictors.
Experimental Design and Methodology
The experiment recruited 184 volunteers to participate in a web-based next-character guessing task on Ukrainian news text. Participants were provided with 70-character context windows, reflecting a deliberate tradeoff between data coverage and participant retention, and asked to iteratively guess subsequent characters until correct. The user interface imposed a throttling delay to disincentivize random guessing and optimize cognitive focus.
Figure 1: User interface used during the experiment.
Text data was sourced from five Ukrainska Pravda news articles published between August 2025 and January 2026. Preprocessing filtered sentences to those 120–200 characters in length, standardized character sets, and removed non-informative tokens, targeting regular, well-formed news discourse. Session quotas and eligibility constraints were implemented to generate incentive structure alignment.
A total of 44,765 guesses were amassed (including both complete and partial sessions), of which 17,023 represented correct first guesses. These correct guesses are the principal data points for entropy estimation, with the number of attempts per character, per position, forming the empirical basis for lower and upper bounds following Shannon's formalism.
Entropy Bound Estimation
The entropy of Ukrainian was evaluated by computing per-position lower and upper entropy bounds in the character sequence, focusing on positions 70–110 due to observation volume and context stabilization. To mitigate variability, the results were pooled and further trimmed—removing 65% of the lowest-performing sessions post-outlier removal—yielding 4,869 high-fidelity observations.
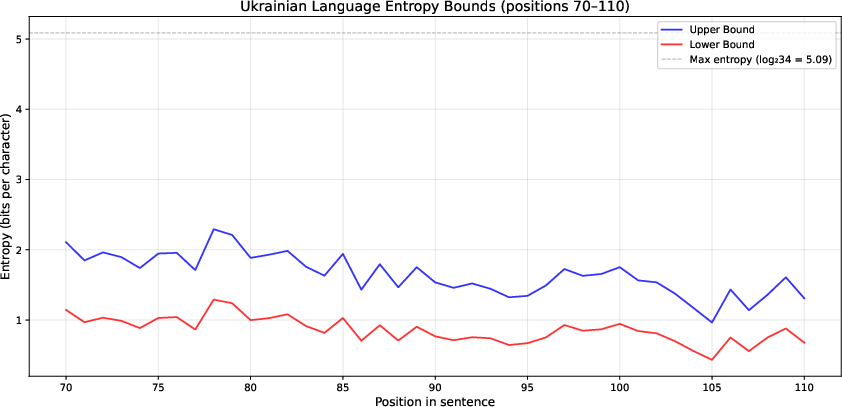
Figure 2: Lower and Upper bounds of entropy per position for positions 70-110.
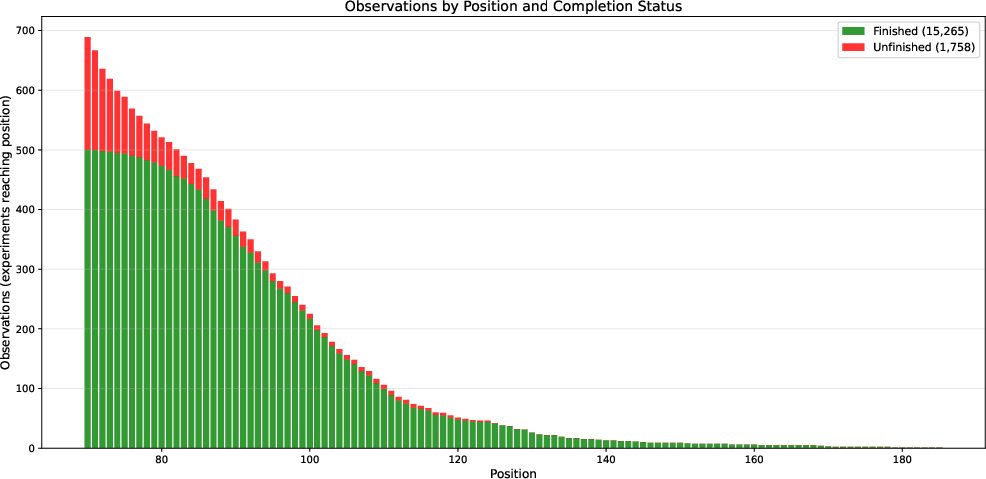
Figure 3: Number of observations gathered per position.
The upper bound of the entropy rate was determined by the aggregate of upper bound estimates across character positions, weighted by per-position sample size. The finalized upper entropy bound was Hupper=1.201 bits per character (bpc), while the lower bound was Hlower=0.599 bpc.
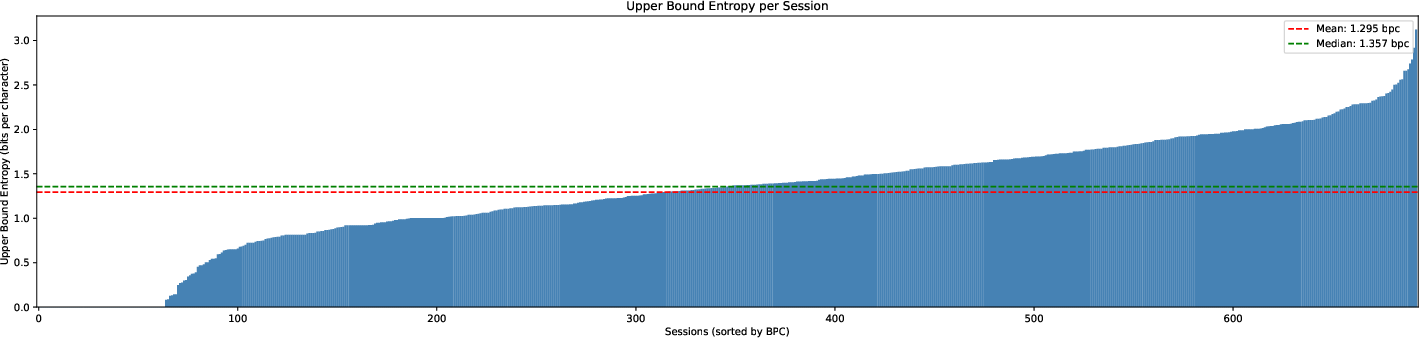
Figure 4: BPC per session for all sessions, ordered by performance.
A bootstrap analysis yielded a 95% confidence interval of [1.10, 1.19] for Hupper, indicating reasonable statistical robustness within the constraints of the sample size and participant engagement profiles.
Comparative Analysis and Implications
Cross-Linguistic Comparison
The upper bound result for Ukrainian (1.201 bpc, 76.4% redundancy) aligns closely with prior results for English (approx. 1.22 bpc, 74.3% redundancy) obtained under a similar protocol [Ren et al., 2019]. The marginal difference in maximum entropy—arising from alphabet size (34 vs 27)—is not reflected in the effective entropy, suggesting a universality in the informational redundancy of Indo-European languages' regular written news texts.
The experiment's result improves upon n-gram based conditional entropy approaches, which for N=9 previously yielded $1.25$–$1.40$ bpc for Ukrainian [Babenko & Sushko, 2012], confirming the trend to lower entropy with longer, human-cognized contexts.
LLM Benchmarking
To contextualize human performance, a suite of transformer-based LLMs—spanning parameter scales and degrees of Ukrainian support—were evaluated by computing token-level log probability on the same test corpus, normalized to per-character bits.
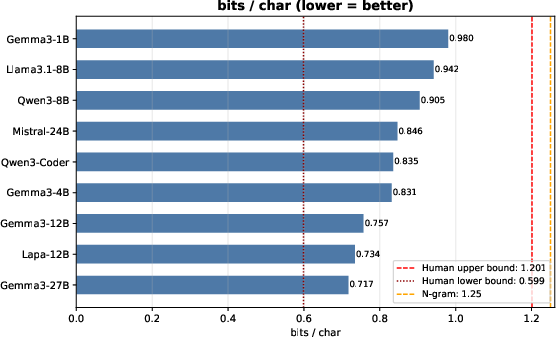
Figure 5: LLM Results for Shannon's experiment.
Models such as Gemma-3 (27B), Lapa-12B, and other modern architectures achieved BPC as low as 0.717. Most LLMs provided entropy estimates below the human lower bound, indicating strong sequence modeling, domain fit, and in some cases probable overfitting to constrained test domains.
This empirical gap highlights several points:
- LLMs can approach, and in practical settings surpass, human lower bound performance on out-of-training news text.
- The overfitting possibility remains a fundamental challenge for interpreting LLM-based entropy results as true upper bounds of linguistic entropy.
- Improved LLM tokenizer design and parameter scaling appear beneficial but do not singularly determine predictive efficiency.
Practical and Theoretical Consequences
Accurate measurement of language entropy informs a range of applications:
- Cross-linguistic comparative linguistics: The proximity of Ukrainian and English entropy validates prior theoretical assertions regarding the universality of information density across typologically related languages.
- Data compression and coding theory: Updated entropy bounds enable more realistic target metrics for lossless encoding schemes and guide the evaluation of compression algorithms.
- Benchmarking neural architectures: LLMs' ability to approach or surpass lower entropy bounds suggests the utility of human-derived entropy as a floor for model evaluation and directs scrutiny toward the confounding role of training data coverage and memorization.
- Natural language complexity estimation: The results constrain hypotheses on the upper bounds of cognitive predictability of natural languages in controlled register.
Future Research Trajectories
Recommendations for subsequent work include: increasing the sample size (>100,000 observations); employing stricter controls and compensation structures to enhance data quality; greater topical and stylistic variety in datasets; and leveraging private, bespoke corpora to preclude lookup-based cheating. LLM-based entropy estimation presents an opportunity for further methodological refinement but warrants careful assessment of contamination, overfitting, and representativeness relative to target linguistic domains.
Conclusion
The first systematic estimation of Ukrainian entropy using the Shannon guessing-game paradigm yields an upper bound of 1.201 bpc, closely paralleling English under parallel conditions and extending cross-linguistic evidence of high redundancy in Indo-European languages' written standard forms. Modern transformer-based LLMs produce even lower empirical entropies on the same corpus, underscoring the potential and pitfalls of using neural models for entropy assessment. The findings substantiate both the methodological rigor of human-centric character-guessing experiments and the modeling prowess of modern LLMs, while delineating clear directions for future large-scale, high-fidelity investigations of language entropy.