- The paper presents the FIRM framework, which leverages tailored data pipelines and reward shaping (CME and QMA) to achieve high human-aligned image editing and generation.
- It introduces innovative pipelines—'difference-first' for editing and 'plan-then-score' for generation—that significantly reduce hallucinations and reward hacking.
- Experimental results on FIRM-Bench demonstrate that FIRM models outperform both proprietary and open-source models in accuracy and efficiency.
Faithful Image Reward Modeling: Bridging Reliability Gaps in Critic-Guided Image Editing and Generation
Introduction and Motivation
The paradigm shift toward Reinforcement Learning (RL) in image editing and text-to-image (T2I) generative modeling has surfaced a critical challenge: the reliability of reward models that serve as critics during the optimization process. Existing Multimodal LLMs (MLLMs), while excelling at general vision-language comprehension, routinely exhibit hallucinations, ignore fine-grained spatial or attribute directives, and emit noisy reward distributions when deployed zero-shot in image editing or generation tasks. This unreliability induces optimization failures, including reward hacking, stagnation, or degeneration to trivial solutions, critically bottlenecking progress in faithful image generation or intricate editing.
The FIRM (Faithful Image Reward Modeling) framework (2603.12247) comprehensively addresses these issues by constructing specialized, highly reliable reward models for both image editing (FIRM-Edit-8B) and T2I generation (FIRM-Gen-8B), orchestrated through meticulously engineered data curation pipelines and advanced reward shaping strategies. This work establishes new performance benchmarks in both subfields, with reward models demonstrably outperforming both proprietary and open-source incumbents in their alignment with human preference.
Data Curation and Reward Modeling Pipelines
A core innovation underlying FIRM is its bespoke reward data construction methodology, tailored for the unique challenges posed by image editing versus generation.
For image editing, the "difference-first" pipeline mitigates the evaluation mismatch observed in MLLMs: while models perform poorly as direct critics, they excel at describing visual differences between source and edited images. The approach leverages strong MLLMs to generate comprehensive difference reports, then conditions reward assessment on these, isolating task-execution (execution score) from context preservation (consistency score), with expert prompt design to elicit fine-grained supervision.
For T2I generation, the "plan-then-score" pipeline decomposes complex prompt requirements into a checklist using a large LLM as a planner. This plan is then supplied to a powerful MLLM evaluator, which systematically audits each dimension and aggregates performance, sharply reducing the attention dilution and hallucination observed in single-shot MLLM scoring.
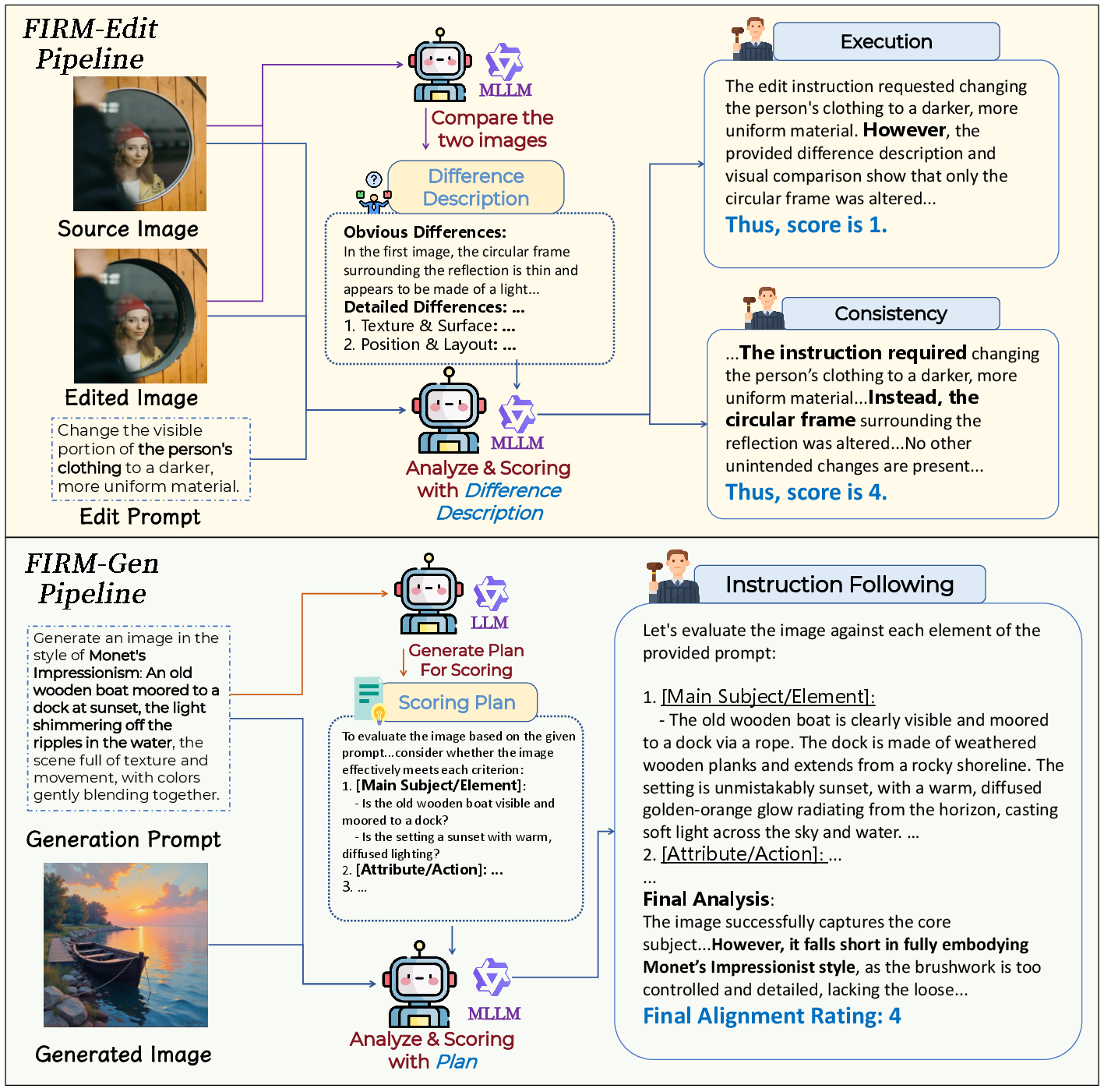
Figure 1: FIRM's data curation architecture: "difference-first" for editing, and "plan-then-score" for generation reward dataset construction.
These pipelines synthesize two large-scale, high-quality datasets: FIRM-Edit-370K (editing) and FIRM-Gen-293K (generation), enabling task-specialized reward model pretraining/fine-tuning.
FIRM-Bench: A Rigorous Human-Aligned Evaluation Standard
To validate the faithfulness and human alignment of the learned critics, FIRM introduces FIRM-Bench, a human-expert-scored benchmark spanning both editing (execution, consistency) and generation (instruction following). Prompts are sourced from diverse, challenging datasets and images from heterogeneous models, with a uniform ground-truth score distribution.
Empirical results reveal that both FIRM-Edit-8B and FIRM-Gen-8B surpass leading proprietary (e.g., GPT-5, Gemini-3-Pro) and open-source (Qwen3-VL, InternVL3.5) reward models in mean absolute error (MAE) with respect to human annotation, even at lower parameter budgets.

Figure 2: FIRM reward models provide judgments more consistent with human assessment than strong baselines, as shown by qualitative FIRM-Bench examples.
Simple linear or fixed weighted reward formulations in RL pipelines are susceptible to reward hacking: e.g., optimizing for high consistency but not executing edits, or producing degenerate T2I outputs that trivially maximize instruction following while sacrificing visual quality.
To counteract this, FIRM introduces:
- Consistency-Modulated Execution (CME): For editing, the reward is RCME=Execution⋅(w1+w2⋅Consistency), enforcing execution as a primary reward with consistency as a multiplicative gain, sharply suppressing strategies that hack the reward surface.
- Quality-Modulated Alignment (QMA): For T2I, RQMA=InsFollowing⋅(w1+w2⋅Quality), ensuring that purely instruction-satisfying but low-quality generations are penalized, especially for simple prompts.
Ablation studies demonstrate the necessity of these formulations: naive alternatives result in significant performance collapse or misalignment.
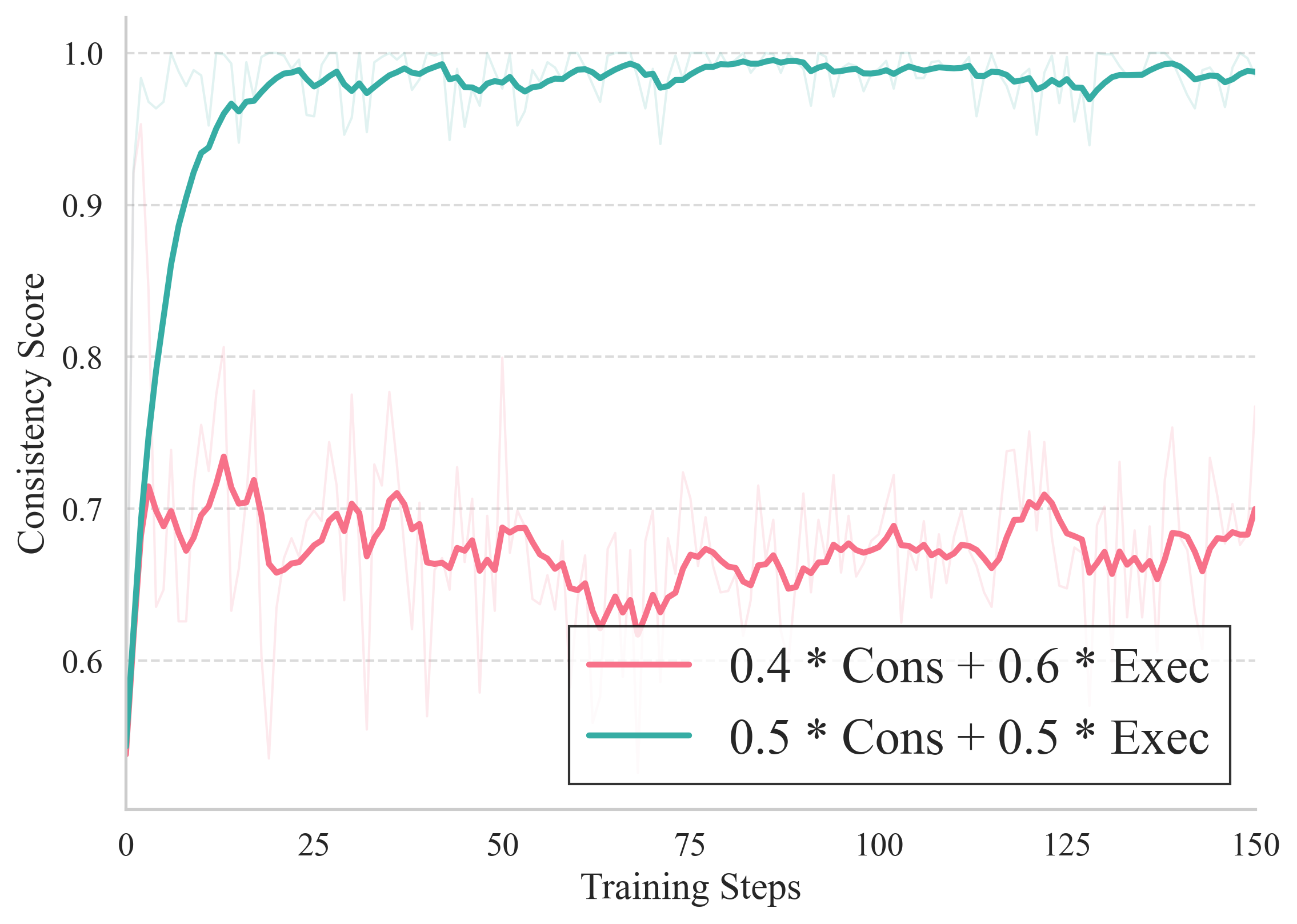
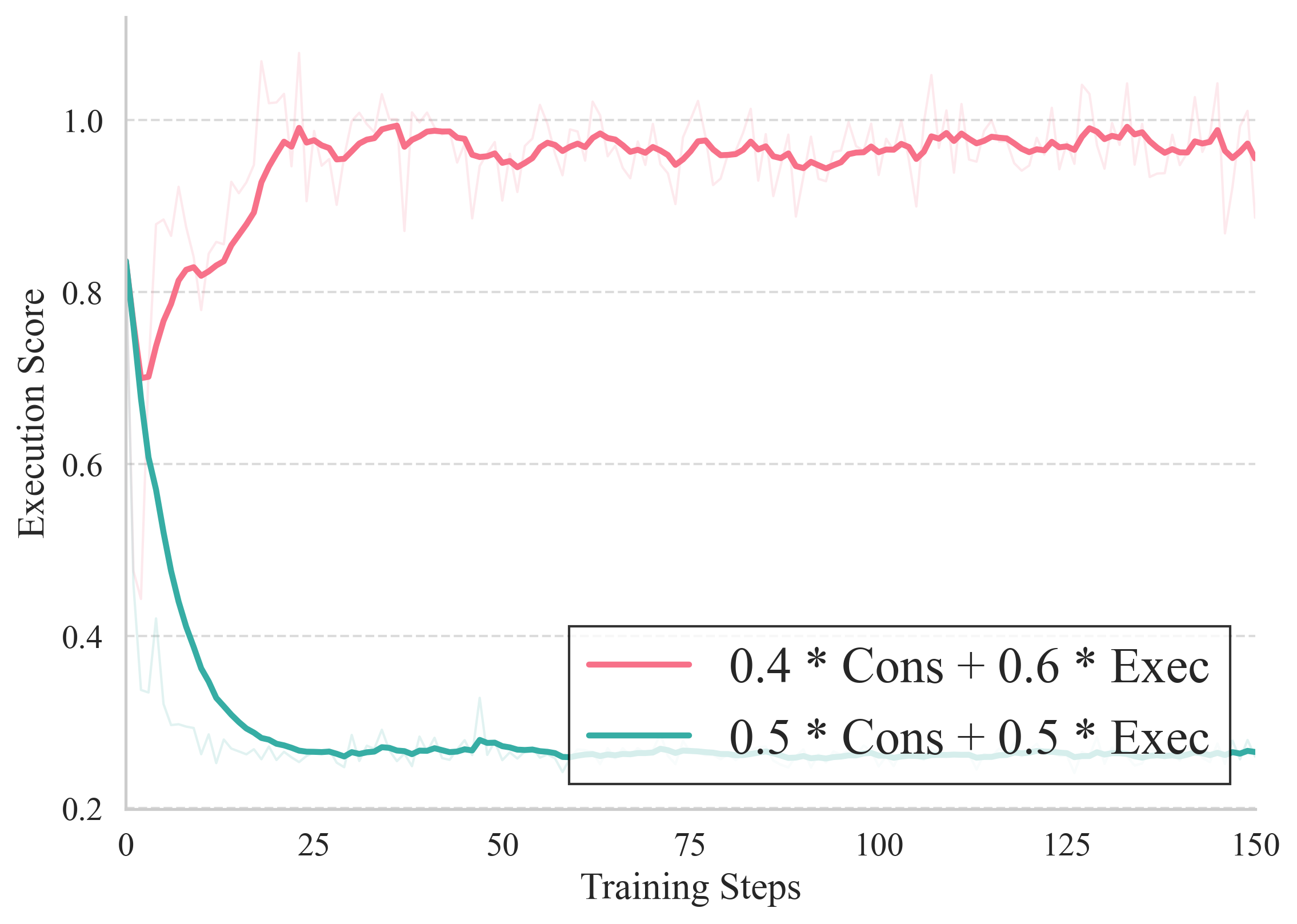
Figure 3: Reward trajectories illustrate how raw weighted sum rewards suffer from credit assignment failures, whereas CME provides stable optimization without reward hacking.
Experimental Results
Reward Model Alignment
On FIRM-Bench, FIRM-Edit-8B achieves the lowest MAE for execution (0.53) and a strong consistency MAE (0.73), outperforming even much larger proprietary models (e.g., GPT-5, Gemini-3-Pro) as well as all open-source baselines. FIRM-Gen-8B exhibits similar strengths, especially on hard T2I examples.
RL-Guided Image Editing
When FIRM-Edit-8B is deployed as a critic in RL fine-tuning, FIRM-Qwen-Edit establishes new SOTA on GEditBench (G_Overall: 7.84) and highly competitive performance on ImgEdit. Notably, these gains require far fewer RL samples than prior state-of-the-art models—demonstrating efficient credit assignment and data efficiency.

Figure 4: Qualitative image editing comparisons validate the perceptible fidelity gain of FIRM-guided RL over competitive baselines.
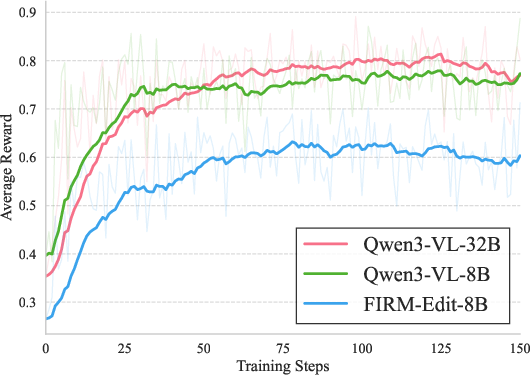
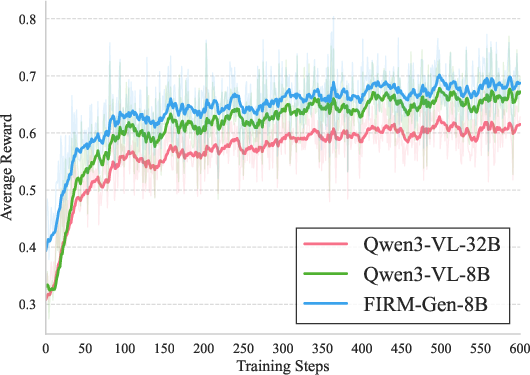
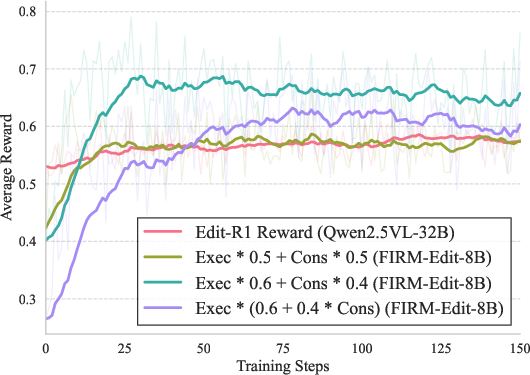
Figure 5: RL reward curves: FIRM-based critics provide sharper discrimination, avoid optimistic bias, and support stable long-horizon policy improvement.
RL-Guided Text-to-Image Generation
Analogous performance gains are realized in T2I. FIRM-SD3.5 (SD3.5-Medium + RL with FIRM-Gen-8B) exceeds baseline SD3.5 and Qwen3-VL reward model RL across all major benchmarks (GenEval, DPG-Bench, TIIF, UniGenBench++), particularly as prompt complexity increases—highlighting FIRM’s robustness in complex compositional scenes.

Figure 6: Representative T2I generations via FIRM reward RL show visible improvements in instruction following and visual quality.
Theoretical and Practical Implications
This work empirically and methodologically redefines the standard for critic-guided RL in generative vision. It demonstrates:
- General-purpose MLLMs are insufficient as high-fidelity critics for fine-grained editing or compositional generation, regardless of scaling.
- Careful data pipeline engineering and specialized reward decoupling (difference-first and plan-then-score) significantly magnify critic accuracy relative to human evaluation.
- Multiplicative reward shaping (CME, QMA) is essential for circumventing reward hacking and fostering alignment with target objectives.
- Data, not just model size, constrains critic performance—a result generalizable to other domains (e.g., video, 3D, controllable synthesis).
Practically, these insights inform the design of robust RL alignment for any generative model requiring semantic, controllable, or human-aligned outputs. With the release of all FIRM datasets, benchmarks, and code, FIRM provides both methodology and infrastructure for scalable, reliable reward modeling.
Conclusion
FIRM sets a comprehensive new direction for reward modeling in RL-driven image editing and generation. By coupling tailored data curation, specialized reward model pretraining, rigorous benchmarks, and principled reward shaping, it enables demonstrably more faithful alignment with human intent and visual fidelity. This framework is likely to become foundational for subsequent work on RL-aligned vision-language foundation models, reward-guided creative pipelines, and scalable critic-centric generative systems.