ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing (2601.03467v1)
Abstract: Instruction-driven image editing with unified multimodal generative models has advanced rapidly, yet their underlying visual reasoning remains limited, leading to suboptimal performance on reasoning-centric edits. Reinforcement learning (RL) has been investigated for improving the quality of image editing, but it faces three key challenges: (1) limited reasoning exploration confined to denoising stochasticity, (2) biased reward fusion, and (3) unstable VLM-based instruction rewards. In this work, we propose ThinkRL-Edit, a reasoning-centric RL framework that decouples visual reasoning from image synthesis and expands reasoning exploration beyond denoising. To the end, we introduce Chain-of-Thought (CoT)-based reasoning sampling with planning and reflection stages prior to generation in online sampling, compelling the model to explore multiple semantic hypotheses and validate their plausibility before committing to a visual outcome. To avoid the failures of weighted aggregation, we propose an unbiased chain preference grouping strategy across multiple reward dimensions. Moreover, we replace interval-based VLM scores with a binary checklist, yielding more precise, lower-variance, and interpretable rewards for complex reasoning. Experiments show our method significantly outperforms prior work on reasoning-centric image editing, producing instruction-faithful, visually coherent, and semantically grounded edits.
Sponsor


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ThinkRL-Edit, a new way for AI to edit images based on written instructions. The main idea is to make the AI “think” carefully before changing a picture, so it can follow complex instructions more accurately. Instead of only focusing on making the final image look good, the method focuses on visual reasoning—understanding what the instruction means for the specific image—before the edit happens.
What problem are they solving?
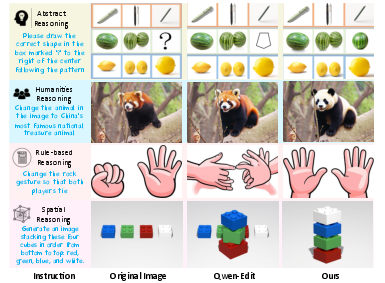
Many image-editing AIs can make nice-looking pictures, but they sometimes misunderstand tricky instructions. For example, “Move the blue mug to the left of the red book, but keep the lighting the same.” That requires the AI to reason about positions, colors, and consistency, not just draw something that looks good. The paper shows how current methods struggle with this kind of reasoning-centric editing.
Goals and Questions
The authors want to answer simple but important questions:
- How can we help an AI think through an editing instruction step by step before it draws the final image?
- How can we reward the AI fairly for edits that both follow the instruction and keep the image consistent and high-quality?
- How can we make the “grading” of the AI’s edits more stable and less random, especially for complicated instructions?
How the Method Works (Explained Simply)
ThinkRL-Edit uses reinforcement learning (RL), which is like training a player by giving points for good moves. The AI tries different edits, gets scores (rewards), and learns what works best. But the paper adds three new ideas to make this training much better for reasoning.
Before the details, here are a few terms in everyday language:
- Visual reasoning: The AI’s “thinking” about what the instruction means for the specific picture.
- Generation/synthesis: The actual drawing or changing of the image.
- Vision-LLM (VLM): An AI that can look at pictures and understand text, then judge how well an edit followed the instruction.
Here’s what the method does:
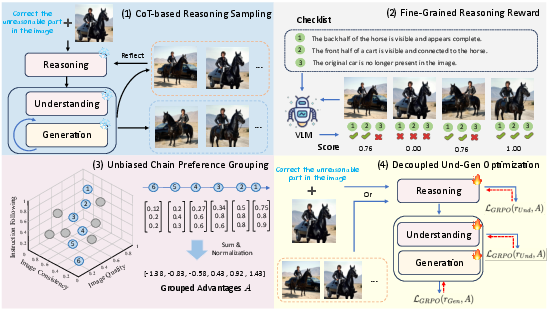
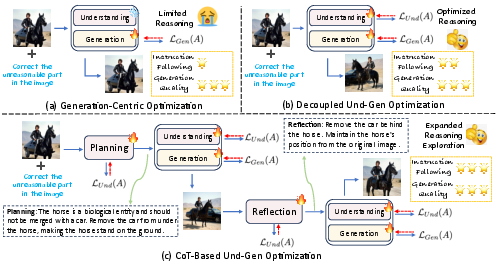
- Separate thinking from drawing:
- Imagine the AI has two halves: an “understanding” half that thinks and plans, and a “generation” half that edits the image.
- The paper trains both halves, but keeps them clearly separate. First the AI plans, then it edits, rather than mixing the two.
- Chain-of-Thought (CoT) planning and reflection:
- CoT means the AI writes out a short step-by-step plan, like “1) Identify the blue mug. 2) Move it left of the red book. 3) Keep lighting and background the same.”
- Reflection means the AI looks at the first result and revises the plan once before trying again.
- This forces the AI to explore different “ideas” for how to edit, not just different drawing strokes.
- Fair ranking across multiple goals:
- Editing has several goals: follow the instruction, keep the image consistent, and stay high-quality.
- Many older methods just mash these into one score with fixed weights (like averaging grades from math, art, and PE). That can be unfair—for example, leaving the image unchanged gets a great “consistency” score but fails the instruction.
- The paper’s solution is to build an “unbiased preference chain”: it only learns from samples where the ranking agrees across all goals, reducing bias toward any single goal.
- Stable yes/no checklist rewards:
- Instead of asking a VLM for a vague 1–5 score, the method creates a custom checklist of yes/no questions based on the instruction and the original image. For example:
- “Is the mug now left of the book?” Yes/No
- “Is the background unchanged?” Yes/No
- “Is the lighting consistent?” Yes/No
- Counting the “yes” answers gives a clear, low-variance score that’s more reliable and easier to interpret.
- Explore beyond “denoising”:
- Some methods only try randomness in the drawing stage (like rolling different dice while sketching).
- This method adds exploration in the thinking stage too, so the AI can consider different reasoning paths before drawing.
Main Findings and Why They Matter
The authors tested their method on two tough benchmarks designed for reasoning-centric edits: KRIS-Bench and RISE-Bench. They also ran a user study.
Key results:
- Much better instruction following: On KRIS-Bench, ThinkRL-Edit significantly increased how well the AI followed instructions compared to strong baselines.
- Stronger reasoning under new conditions: On RISE-Bench, which includes edits involving time, cause-and-effect, space, and logic, ThinkRL-Edit showed large improvements, meaning it can generalize its reasoning to new types of tasks.
- People preferred the results: In a user study, participants chose ThinkRL-Edit’s edits most often for instruction following, consistency, and quality.
Why this matters:
- The edits are not just pretty—they make logical sense and match what the user asked.
- The AI’s decision process is more transparent and stable, thanks to planning steps and checklist-based rewards.
What This Could Change
- Smarter photo editing tools: Apps could reliably follow complex requests, like “Make the sky cloudy but keep the reflection in the lake accurate.”
- Better design and content creation: Designers could give detailed multi-step instructions and get faithful results.
- More trustworthy AI: The method encourages step-by-step thinking and fair scoring, which can reduce surprising or incorrect edits.
Limitations and Future Directions
- Slower editing: Planning and reflecting adds thinking time, so edits take longer.
- Possible solution: The authors suggest exploring “latent CoT,” where the AI encodes its reasoning in a compact form inside its internal representations, speeding things up while keeping the benefits of structured thinking.
Summary
ThinkRL-Edit teaches an image-editing AI to think before it draws. It plans, reflects, and uses fair, stable rewards to learn. This leads to edits that follow instructions better, stay visually consistent, and look high-quality—even for tricky, reasoning-heavy tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following points unresolved:
- Reproducibility of the reward pipeline: the checklist questions are constructed with proprietary VLMs (e.g., Gemini), but the exact prompt templates, question generation heuristics, and post-processing rules are not specified or released, hindering replication and controlled comparison.
- Quality of checklist questions: there is no evaluation of the semantic coverage, ambiguity rate, or answerability of generated binary questions, nor procedures to detect and correct poorly formed items (e.g., leading, underspecified, or visually unverifiable questions).
- Reward model dependence and circularity: the same or similar VLM families (e.g., Qwen3-VL) are used for training rewards and potentially for benchmark scoring, risking overfitting to a particular reward model’s idiosyncrasies and inflated gains; cross-reward-model validation is missing.
- Binary rewards vs nuance: replacing interval scores with yes/no checklists may lose granularity for subtle edits (e.g., minor geometric alignment, color tone changes). How to capture fine-grained compliance without reintroducing unstable scalar rewards is not explored.
- Multi-lingual and domain robustness: checklist construction and reasoning evaluation are only demonstrated for a single language and photo domain; performance under different languages, domain shifts (medical, satellite, sketches), and cultural references is untested.
- UCPG algorithm clarity and guarantees: the “unbiased chain preference grouping” lacks formal definition and theoretical analysis (e.g., consistency, bias, convergence). Acceptance rate, computational overhead, and gradient variance under UCPG are not reported.
- Comparison to alternative multi-objective RL: there is no head-to-head evaluation against established multi-objective formulations (e.g., Pareto front methods, scalarization with adaptive weights, constrained RL), leaving unclear whether UCPG is superior beyond the reported ablations.
- Credit assignment across modules: decoupled updates to
π^{Und}andπ^{Gen}use a unified editing reward, but how credit is attributed when improvements in reasoning degrade synthesis (or vice versa) is not studied; mechanisms for balancing or decoupling advantages are absent. - CoT reliability and faithfulness: no metric or study assesses whether generated CoT steps causally explain the subsequent edit (vs post-hoc rationalizations). Methods to measure CoT faithfulness or enforce action-grounded reasoning are missing.
- Adaptive planning/reflection depth: only one reflection is used; there is no exploration of adaptive or learned stopping criteria, diminishing returns with multiple reflections, or task-dependent planning depth.
- Latency and compute trade-offs: the paper notes nearly doubled editing time with CoT, but provides no quantitative breakdown of latency, memory, and energy costs, nor optimization strategies (e.g., caching, distillation, partial CoT) for interactive use.
- Training dataset transparency: the instruction-based image editing dataset
𝓓is unspecified (size, sources, licenses, annotation standards), preventing analysis of data biases and limiting reproducibility. - Generalization beyond Qwen-Edit: results are reported mainly on Qwen-Edit; transferability to other unified models (e.g., OmniGen, Emu3, Transfusion), pure diffusion backbones, or flow-matching variants is untested.
- Benchmark evaluation bias: KRIS and RISE scores rely heavily on automated evaluators; the paper lacks blinded, large-scale human evaluations with statistical significance tests and detailed protocols to avoid evaluator bias.
- Quality–reasoning trade-off on RISE: the method improves reasoning but reduces overall quality compared to Qwen-Edit (e.g., RISE “Overall Quality” drops from 86.9 to 62.5). A systematic analysis of when and why edits compromise quality—and how to mitigate this trade-off—is missing.
- Robustness to adversarial and ambiguous instructions: failure modes under negations, compound instructions, conflicting constraints, or adversarially phrased prompts are not characterized; safeguards (e.g., uncertainty estimates, refusal policies) are absent.
- Localized edits and geometric precision: the framework does not analyze fine-grained, localized edits (e.g., pixel-level geometry, precise alignment) where visual consistency can mask inadequate instruction following; integrating geometric constraints or ROI-aware rewards is unexplored.
- Multi-turn and interactive editing: the method is evaluated on single-turn editing; how reasoning chains evolve across multi-turn dialogs, incremental edits, or user corrections is open.
- Multi-image and video editing: extending the reasoning–generation decoupling to video frames, temporal consistency, and multi-reference inputs is not addressed.
- Hyperparameter sensitivity: key parameters (group size
G, timestep ratioτ, noise scheduleσ_t, reflection depth) lack sensitivity analyses; data-driven schedules or automated tuning remain open. - Sample efficiency and acceptance rate: UCPG’s filtering may discard many samples; empirical acceptance rates, impact on sample efficiency, and strategies to recover informative but partially inconsistent samples are not reported.
- Safety and content moderation: the approach does not consider safety policies (e.g., preventing harmful or unethical edits), nor alignment mechanisms to enforce content guidelines in the reasoning stage.
- Checklist calibration: no procedures exist for calibrating VLM confidence on yes/no answers, detecting answer bias (e.g., “yes”-bias), or reconciling disagreements between multiple evaluators.
- Human preference study limitations: the user study is small (20 participants, 24 comparisons) without demographic details, blinding procedures, or significance testing; scaling and replicating with diverse user pools are needed.
- Open-sourcing and auditability: code, trained checkpoints, reward prompts, and evaluation scripts are not declared for release, preventing external auditing, robustness checks, and community adoption.
Glossary
- Chain-of-Thought (CoT): A prompting and training technique where models generate intermediate reasoning steps to improve logical consistency and interpretability. "Chain-of-Thought (CoT)~\cite{wei2022chain} reasoning improves the ability of LLMs to solve complex problems by emulating human step-by-step thinking."
- Checklist-based evaluation: An assessment method that scores outputs via a set of binary (yes/no) questions tailored to each instance, yielding fine-grained, lower-variance rewards. "we replace conventional interval-based scoring with a fine-grained checklist-based evaluation."
- Cross-Attention Control: A technique that manipulates or constrains cross-attention maps in diffusion models to steer edits in a controlled manner. "cross-attention control~\cite{hertz2022prompt,wang2023enhancing}"
- Diffusion trajectory: The path taken through the denoising process of a diffusion model, which can be altered to effect specific edits. "Traditional approaches achieve accurate editing by modifying the diffusion trajectory without additional training"
- Flow Matching: A generative modeling paradigm that learns vector fields to transport noise to data, enabling deterministic generation via ODEs (and extensions to SDEs). "flow matching models~\cite{lipman2022flow}"
- Flow-ODE: The deterministic ordinary differential equation formulation used in flow matching to generate samples. "FlowGRPO\citep{liuflow} convert the deterministic Flow-ODE to an equivalent SDE:"
- FlowGRPO: An algorithm that adapts GRPO to flow matching by introducing stochasticity into generation trajectories for better exploration. "For example, FlowGRPO~\cite{liu2025flow} expands the search space by converting ODE-based denoising into SDE-based sampling"
- Fully Sharded Data Parallelism (FSDP): A distributed training technique that shards model states across devices to reduce memory usage and enable larger models. "we employ Fully Sharded Data Parallelism (FSDP) for the trainable modules along with gradient checkpointing."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that stabilizes updates using group-relative advantages over sampled outputs. "advanced algorithms such as Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath,wei2025skywork,xue2025dancegrpo,liu2025flow, wang2025pref} have shown strong potential"
- Group-relative advantage: A normalized advantage computed relative to a group of samples to stabilize policy optimization. "GRPO \citep{shao2024deepseekmath} introduces a group-relative advantage to stabilize policy updates."
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution, commonly used as a regularizer in RL objectives. "- \beta D_{\text{KL}(\pi_\theta || \pi_{\text{ref})"
- Latent inversion: The process of mapping an input image into a model’s latent space to preserve fidelity during subsequent edits. "latent inversion for fidelity preservation"
- Mask-guided blending: An editing technique that uses masks to restrict or guide where edits are applied, blending generated and original regions. "mask-guided blending~\cite{wang2025dreamtext,avrahami2022blended,wang2024primecomposer}"
- Multi-modal LLM (MLLM): A large model that processes and reasons over multiple modalities (e.g., vision and language) jointly. "Multi-modal LLMs (MLLMs)"
- Ordinary Differential Equation (ODE): A mathematical formulation defining deterministic evolution; in generative modeling, used to describe flow-based generation. "ODE-based denoising"
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm that aligns model behavior with human preferences via learned reward signals. "Reinforcement Learning from Human Feedback (RLHF)~\citep{ouyang2022training} has emerged as the dominant paradigm"
- Stochastic Differential Equation (SDE): A differential equation that includes stochastic noise terms, enabling randomized generative trajectories. "SDE-based sampling"
- Unbiased Chain Preference Grouping (UCPG): A ranking-based strategy that orders candidates across multiple reward dimensions without collapsing them into a single weighted score. "we introduce an unbiased chain preference grouping strategy"
- Vision-LLM (VLM): A model that jointly understands images and text, often used to evaluate instruction-following or reasoning in edits. "vision-LLMs (VLMs)~\cite{Qwen25VL, chen2024internvl}"
- Wiener process: A continuous-time stochastic process with independent Gaussian increments, used to model noise in SDEs. "where denotes Wiener process increments"
Practical Applications
Below are actionable, real-world applications derived from the paper’s findings, methods, and innovations. Each item notes sectors, prospective tools/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be prototyped or deployed now with current models, data, and infrastructure.
- Reasoning-centric consumer photo editing (voice or text instructions)
- Sectors: Consumer software, mobile apps, social media
- Tools/Workflows: “Plan–Reflect–Edit” mode in photo apps; on-device or cloud API that generates a short plan (CoT), performs the edit, reflects once, and finalizes; user-visible “reasoning summary” panel for transparency and quick correction
- Assumptions/Dependencies: Requires access to a capable unified editing model (e.g., Qwen-Edit or comparable) and a VLM for checklist evaluation; planning + reflection adds latency (~2× per paper); cloud inference may be necessary for quality and speed
- Creative production pipelines for agencies and studios (brief-to-variant generation with hard constraints)
- Sectors: Advertising/marketing, media/entertainment, e-commerce content studios
- Tools/Workflows: Batch “brief compiler” to convert complex creative briefs into checklist questions; unbiased chain preference grouping to avoid trivial “unchanged but consistent” outputs; automated triage that rejects edits failing the checklist gate
- Assumptions/Dependencies: Stable, domain-tuned checklists that encode brand and legal constraints; GPU budget for RL fine-tuning and inference; versioned audit logs for creative compliance
- Product image editing at scale with compliance gates
- Sectors: E-commerce/retail, marketplaces
- Tools/Workflows: Bulk edits like “swap background to seasonal theme, keep SKU color/size, remove extraneous logos” with a checklist that tests instruction-following (IF), visual consistency (VC), and visual quality (VQ); CI/CD-style quality gates using the binary checklist
- Assumptions/Dependencies: Robust reference-image consistency metrics; ability to encode catalog-specific constraints into task-specific checklists; throughput considerations at peak content-refresh times
- Editorial redaction and anonymization with verifiable reasoning
- Sectors: Newsrooms, legal/e-discovery, compliance
- Tools/Workflows: Instruction “redact faces except public officials,” “blur license plates but retain brand logos,” with binary checklists for policy rules; CoT explanations archived as audit artifacts for compliance reviews
- Assumptions/Dependencies: Accurate person/entity recognition integrated into the understanding module; clear organizational policies translatable to binary checklist items
- Design and UI mock-up editing (layout- and constraint-aware edits)
- Sectors: Software design, product teams
- Tools/Workflows: Figma/Photoshop plugins that perform layout edits like “move CTA to the right, ensure contrast meets WCAG AA,” using checklists as acceptance tests; “reflect” step proposes alternative placements if constraints fail
- Assumptions/Dependencies: Domain checkers (e.g., WCAG contrast) connected to the reward scaffolding; vector/raster hybrid support in the editing pipeline
- Benchmarking and QA harness for reasoning-centric editing models
- Sectors: MLOps, model evaluation vendors, academia
- Tools/Workflows: KRIS/RISE-like harness with sample-specific checklists; regression dashboards tracking IF/VC/VQ across categories (spatial, causal, logical); low-variance binary rewards to stabilize A/B testing and model gating
- Assumptions/Dependencies: Access to VLMs that can reliably answer binary questions; test-set maintenance to reduce prompt leakage and overfitting
- Human-in-the-loop annotation with binary checklists
- Sectors: Data labeling providers, research labs
- Tools/Workflows: Rater UI that converts instructions to binary questions; inter-rater agreement boosted via explicit checklists; cheaper, lower-variance preference data for RLHF/RLAIF
- Assumptions/Dependencies: Good prompt templates to construct fair, unambiguous binary questions; training raters to align with the checklist rubric
- Multi-objective RL alignment for vision–language tasks (beyond editing)
- Sectors: Foundation model alignment, applied AI
- Tools/Workflows: Port the unbiased chain preference grouping to other multi-objective settings (e.g., code generation with correctness + style + security; T2I with content safety + prompt faithfulness + aesthetics)
- Assumptions/Dependencies: Availability of per-dimension RMs or checkers; careful choice of grouping thresholds to avoid discarding too many samples
- Accessible photo editing via natural language
- Sectors: Accessibility, daily life
- Tools/Workflows: Voice-to-edit with plan preview and one-step reflection; simplified “why this change?” explanation for users with limited dexterity or vision
- Assumptions/Dependencies: Robust speech-to-text and co-reference resolution; latency tolerable for interactive use
- Research baselines and reproducibility assets
- Sectors: Academia
- Tools/Workflows: Use decoupled Und–Gen optimization as a baseline for new unified models; standardized experiments on KRIS/RISE; ablations with and without plan/reflect at inference
- Assumptions/Dependencies: Open or licensed access to base models (e.g., Qwen-Edit, Qwen3-VL), training compute (FSDP), and datasets with reasoning-heavy instructions
Long-Term Applications
These require further research, scaling, or engineering (e.g., latency, robustness, domain guarantees).
- Latent Chain-of-Thought for fast, private, and on-device editing
- Sectors: Consumer apps, edge AI
- Tools/Workflows: Replace linguistic CoT with compact latent reasoning tokens; unify visual/text signals in a latent space; single-pass “plan–reflect” compressed into the generator
- Assumptions/Dependencies: New architectures and training recipes; evidence that latent CoT preserves interpretability and control; efficient on-device accelerators
- Video editing with temporal, causal, and narrative reasoning
- Sectors: Film/TV, game studios, social video platforms
- Tools/Workflows: Sequence-level plan–reflect that enforces character continuity, lighting/motion consistency, and causal story constraints; multi-frame checklist rewards (temporal IF/VC/VQ) and chain preference across time
- Assumptions/Dependencies: Temporal reward models; scalable sampling with acceptable latency; prevention of drift across frames
- Domain-governed editing for regulated sectors (audit-ready by design)
- Sectors: Healthcare, insurance, public sector
- Tools/Workflows: Encoded policy checklists (e.g., “no alteration of diagnostic regions,” “preserve measurement overlays”) with immutable CoT logs; automated compliance reports
- Assumptions/Dependencies: Domain-validated reward checkers; third-party certification; strict data privacy and provenance tracking; risk management for hallucinations
- CAD/architecture and industrial design edits under physical/code constraints
- Sectors: AEC (architecture, engineering, construction), manufacturing
- Tools/Workflows: Reasoning-guided edits that respect building codes or manufacturability (e.g., “move sink, keep drain slope constraints”); physics- or rule-aware checklist rewards
- Assumptions/Dependencies: Integration with CAD kernels and simulation; verified rule bases; robust grounding from image-like previews to structured geometry
- Standardized governance via checklist-based audits for generative systems
- Sectors: Policy/regulation, platform governance
- Tools/Workflows: Public, domain-specific binary checklists for measuring instruction faithfulness, safety, and content provenance; interoperable audit artifacts (CoT + checklist + outcomes)
- Assumptions/Dependencies: Cross-stakeholder agreement on rubrics; mitigation of VLM biases; procedures for appeals and human review
- End-to-end creative agents that plan, edit, and iterate across modalities
- Sectors: Marketing automation, product content ops
- Tools/Workflows: Agents that translate a brief to a storyboard, generate/edit images and short videos, run checklist-based QA, reflect, and publish; integrate with DAM/CMS
- Assumptions/Dependencies: Reliable tool-use orchestration; unified multi-modal reward models; cost-effective closed-loop iteration at scale
- Data generation and curriculum design for reasoning-rich multimodal training
- Sectors: Foundation model training, edtech
- Tools/Workflows: Synthetic pipelines that produce instruction–image pairs with associated binary checklists; curricula that progressively increase reasoning difficulty; UCPG to prevent collapse to single-objective shortcuts
- Assumptions/Dependencies: High-quality synthetic generators; guardrails against reward hacking; careful stratification to avoid spurious correlations
- Cross-domain multi-objective RL with unbiased chain preference
- Sectors: Software engineering, security, scientific ML
- Tools/Workflows: Apply UCPG to code agents (correctness, performance, style), scientific visualization (accuracy, clarity, aesthetics), or safety-critical planning (goal satisfaction, safety margins, efficiency)
- Assumptions/Dependencies: Reliable, decomposed reward dimensions; scalable sampling to obtain consistent total orders; theoretical and empirical guarantees against mode collapse
- Privacy-preserving, provenance-aware editing with explainable logs
- Sectors: Enterprise IT, digital asset management
- Tools/Workflows: Cryptographic provenance (e.g., C2PA) plus CoT/checklist logs; differential privacy or secure enclaves for sensitive assets; enterprise search over rationale and constraints
- Assumptions/Dependencies: Standards adoption; efficient storage and retrieval of logs; balancing transparency with IP protection
- Education and training in visual reasoning and composition
- Sectors: Education, design schools
- Tools/Workflows: Tutors that show stepwise reasoning behind edits (composition rules, spatial logic), assign exercises with auto-graded binary checklists, and provide reflective feedback
- Assumptions/Dependencies: Pedagogically sound rubrics; avoidance of overfitting to checklists; accessibility features and multilingual support
Notes on cross-cutting dependencies and risks:
- Checklist fidelity and bias: Binary questions must be specific, unambiguous, and context-aware; biased or incomplete checklists can misguide RL and QA.
- Compute and latency: CoT planning and reflection increase cost; streaming or speculative decoding could mitigate but needs engineering.
- Licensing and privacy: Base models (Qwen-Edit/Qwen3-VL) and VLM APIs must be licensed appropriately; sensitive images require strict handling and provenance.
- Reward gaming: Systems can “learn the checklist” rather than the task; randomization, adversarial tests, and periodic rubric refreshes reduce this risk.
Collections
Sign up for free to add this paper to one or more collections.