- The paper presents a semantic quantum circuit cache that reduces redundant quantum circuit evaluations by detecting semantically equivalent circuits using ZX-calculus and WL graph hashing.
- The method scales effectively in distributed setups, achieving up to 11.2× speedup on real hardware and reducing up to 91.98% of redundant subcircuit executions during wire cutting.
- It integrates seamlessly with hybrid quantum-classical workflows, ensuring resource efficiency and portability through backend-agnostic implementations with LMDB and Redis.
Semantic Quantum Circuit Caching for Scalable Hybrid Quantum-Classical Workflows
Introduction and Motivation
The exponential growth of hybrid quantum-classical workflows for near-term quantum computing exposes substantial inefficiencies from redundant quantum circuit execution. This redundancy arises when workflows generate large ensembles of circuits that, though they differ at the syntactic level due to gate reordering, compilation artifacts, or parameter choices, are semantically equivalent and implement the same quantum operation. Traditional quantum software stacks, which define circuit identity based on syntactic representations (e.g., QASM strings or gate lists), are not equipped to recognize and eliminate such inefficiency.
"A Semantic Quantum Circuit Cache for Scalable and Distributed Quantum-Classical Workflows" (2604.26788) addresses this bottleneck by introducing the Quantum Circuit Cache, a system primitive that detects semantic circuit equivalence and enables persistent, backend-agnostic reuse of quantum computations in distributed classical-quantum workflows. The cache transparently identifies semantically equivalent circuits across randomizations, parameter sweeps, compiler passes, and workflow stages, serving as a content-addressable system designed to amortize both classical and quantum resource consumption.
Methods: Semantic Hashing via ZX-calculus and Weisfeiler–Leman Graph
Key to the Quantum Circuit Cache is the use of ZX-calculus for semantics-preserving reduction, followed by isomorphism-invariant Weisfeiler–Leman (WL) graph hashing to produce deterministic, backend-independent identifiers for circuits. Incoming circuits are first transformed into ZX-calculus graphs and reduced via a robust, deterministic sequence of rewrite rules that normalize superficial structural differences while preserving quantum semantics.
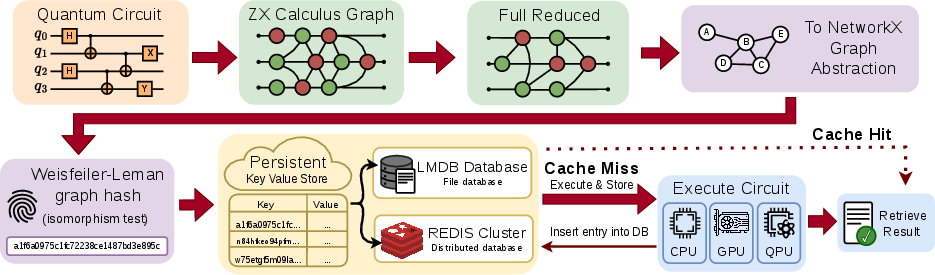
Figure 1: End-to-end workflow of the Quantum Circuit Cache, from ZX-calculus graph reduction to Weisfeiler--Leman hash key generation and distributed cache lookup/execution.
The reduced ZX-calculus graphs are serialized in a canonical form and hashed using WL refinement, which aggregates vertex attributes and topology to construct a concise, stable fingerprint invariant to gate ordering, local circuit rewrites, and most compiler artifacts. This pipeline does not guarantee complete equivalence detection due to the non-uniqueness of ZX normal forms, but in practical workloads (especially Clifford+T-dominated, variational ansätze, and subcircuits from wire cutting), convergence is reliable and effective. The resulting hash serves as a cache key for storing or retrieving simulation results, measurement statistics, or QPU execution metadata.
The cache utilizes two backends: a local, memory-mapped disk solution (LMDB) suited for modest parallelism and lightweight deployments, and a distributed Redis cluster for high-parallelism HPC environments. Both support constant-time lookup and can be ported between deployments via a universal LMDB dump/restore mechanism.
Evaluation: Distributed Wire Cutting and QAOA Workloads
Wire Cutting
Wire cutting decomposes large quantum circuits into many subcircuits by inserting “cuts” and expanding the resulting operator basis. For c cuts, this produces 8c (or 2×8c) subcircuits, most of which are structurally redundant. Evaluation on 48-qubit Hardware-Efficient Ansatz (HEA) and random circuits with four wire cuts demonstrates that the cache can eliminate up to 91.98% of redundant execution—equivalent to avoiding 7,544 quantum subcircuit simulations out of 8,192 total.
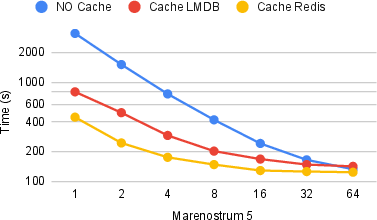
Figure 2: Total execution time for HEA circuits with four wire cuts and varying compute nodes; distributed cache reduces wall time substantially, with Redis backend showing better scaling at high parallelism.
Both LMDB and Redis backends significantly reduce runtime across node count; Redis, with concurrent writes and internal sharding, outperforms LMDB under high concurrency, achieving up to 7.0× speedup on one node and at least 1.6× speedup at 64 nodes. Notably, similar speedup is observed in random circuits—demonstrating that strong regularity is not a prerequisite for high-effectiveness circuit caching.
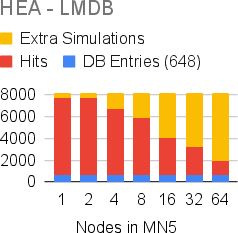
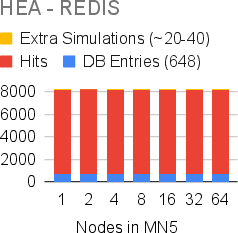
Figure 3: Cache behavior for HEA circuits using an LMDB backend, showing the dominance of cache hits but increased extra simulations under higher parallelism due to the single-writer constraint.
Cache hit behavior and extra simulation due to concurrent writes are further dissected: Redis supports multiple writers, stabilizing the system at large scale, whereas LMDB’s single-writer model can cause limited redundant computation under heavy load.
Direct validation on a 35-qubit superconducting quantum processor (MareNostrum Ona) confirms the systems-level benefit, as semantic caching yields an 11.2× speedup for HEA circuits with four wire cuts—reducing physical QPU time from an estimated 20.5 hours to only 1.83 hours by avoiding duplicate subcircuit execution.
QAOA with Differential Evolution
Variational algorithms such as QAOA, often evaluated over dense parameter grids with evolutionary or gradient-free optimizers, feature significant redundancy in the underlying circuit structure after parameter discretization and ZX-calculus reduction. The cache was evaluated on Max-Cut QAOA for 24-vertex random graphs, using Differential Evolution (DE) optimizers across three levels of parameter discretization and three circuit depths.
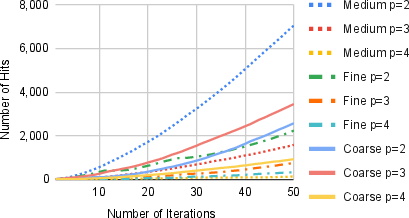
Figure 4: Cumulative cache hits versus DE optimizer iteration for QAOA at different depths and discretizations, demonstrating increasing reuse as optimization proceeds.
Cache reuse is particularly prominent for coarser and medium discretizations, avoiding up to 27.6% of circuit evaluations in p=2 QAOA with medium discretization—consistently lowering execution cost without affecting optimization convergence or final solution quality. Even for finer discretizations and deeper circuits, thousands of executions are bypassed. This effect is robust across random seeds and workloads, validating that much of the computational effort in variational quantum algorithms is redundant under semantics-aware analysis.
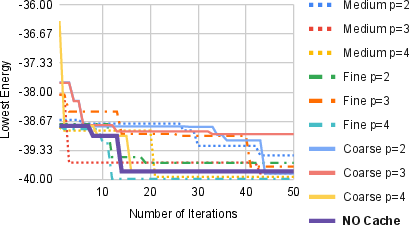
Figure 5: Convergence of best Max-Cut energy for all configurations, indicating that cache-enabled equivalence detection does not adversely impact optimizer behavior but reduces redundant computation.
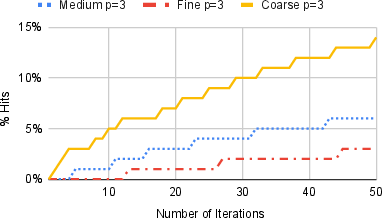
Figure 6: Cache hit percentage for p=3 as a function of optimizer iterations, confirming that coarser discretizations achieve consistently higher rates of cache reuse.
Cache effectiveness scales with population size in DE optimizers, as illustrated by the increase in avoided simulations with larger populations, indicating the method's suitability for future HPC-scale quantum-classical optimization.
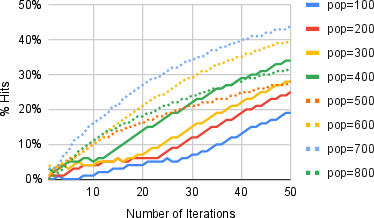
Figure 7: Total avoided circuit simulations as a function of population size, showing the scaling benefit in parallel/hybrid optimizer settings.
Implementation Considerations
Overhead introduced by semantics-based hashing and reduction is minimal relative to quantum circuit execution time. Cache lookup, ZX-calculus reduction, and WL hashing collectively take approximately 0.13 seconds per cache miss, while a typical 28-qubit simulation with Qiskit Aer requires >35 seconds. Consequently, even moderate cache hit rates substantially amortize the extra pipeline computation.
For backend storage, LMDB is memory efficient (on the order of hundreds of bytes per full statevector), while Redis incurs higher per-entry overhead due to serialization and distributed infrastructure, but provides the necessary scaling for very high concurrency.
Implications and Future Directions
Semantic quantum circuit caching represents a systems-level advance in hybrid quantum computing, abstracting equivalence detection from a verification tool to a persistent, distributed service primitive. Its introduction establishes a foundation for future quantum workflow orchestration, enabling backends to treat quantum circuits as reusable computational artifacts much as classical HPC systems exploit memoization and checkpointing.
Practical implications include:
- Substantial speedup of current hybrid workloads, especially for wire cutting, error mitigation, quantum chemistry VQEs, benchmarking, and distributed parameter sweeps.
- Efficient utilization of scarce QPU resources: redundant evaluation on hardware is dramatically reduced, directly lowering operational costs and queue time.
- Scalable deployment on existing HPC infrastructure: the system is backend-agnostic and suitable for both shared-memory and distributed-memory quantum-classical pipelines.
- Transparent integration: quantum algorithms and classical optimizers require no modification; cache mediation is handled at the systems layer.
- Portability across deployments: the LMDB snapshotting mechanism ensures caches can be archived, shared, and restored.
Several avenues for further development and research are highlighted:
- Improved normal forms for ZX-calculus: increased equivalence detection completeness would expand hit rates, especially for deep, entangled circuits.
- Support for dynamic circuits: extending semantic representation to circuits with classical flow or adaptive measurements.
- Cache-aware workload placement and optimizer-integration: potential for integrating cache awareness into scheduler heuristics or optimizer sampling strategies.
- Heterogeneous mix of backend types: unifying cache semantics across CPUs, GPUs, and future large-scale QPUs.
Conclusion
The Quantum Circuit Cache establishes semantic circuit equivalence as a powerful, scalable mechanism for suppressing redundant quantum computation in distributed, hybrid classical-quantum environments. Empirical results in wire cutting and variational quantum optimization demonstrate strong hit rates and speedups up to 11.2× on real hardware. The approach is portable, backend-independent, and highly effective even in the presence of structural noise and compiler randomness.
As hybrid and distributed quantum-classical workflows become the standard for near-term quantum computing, systems techniques such as semantic caching will be crucial. Future application domains—including quantum error mitigation, quantum chemistry, and large-scale benchmarking—stand to benefit significantly from this paradigm. The methodology generalizes broadly, opening avenues for further research into architecture-level integration, cache-coherent quantum-classical scheduling, and algorithm-cache co-design.