- The paper introduces a hardware- and depth-aware compiler that restructures logical circuits, enabling parallel execution of distributed CNOT gate sequences.
- The compiler uses bucket-based grouping and multi-pass sweeps to identify and parallelize sequential CNOT operations, reducing depth from O(n) to constant overhead.
- Empirical benchmarks on realistic and synthetic circuits show substantial depth reductions, enhancing execution fidelity in distributed quantum systems.
Logical-to-Physical Compilation for Depth Reduction in Distributed Quantum Systems
Introduction
Distributed quantum architectures, composed of multiple spatially separated quantum nodes connected via photonic links, are a leading approach for scaling quantum computing in the NISQ regime. However, the translation of logical quantum circuits to efficient physical execution in such settings poses substantial challenges, most notably a significant increase in circuit depth due to the sequential nature of distributed two-qubit (CNOT) gates. Circuit depth directly impacts the overall fidelity of computations as it increases susceptibility to noise and decoherence. The paper "Logical-to-Physical Compilation for Reducing Depth in Distributed Quantum Systems" (2603.29536) addresses this bottleneck by introducing a hardware- and depth-aware compiler that restructures logical quantum circuits for distributed platforms, specifically targeting parallelizable patterns in distributed CNOT gate sequences.
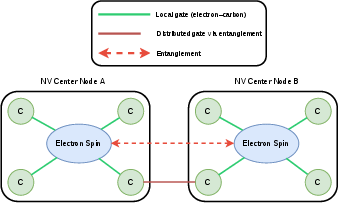
Figure 1: Two NV‑center nodes in a distributed quantum computer. Each node contains an electron spin (communication qubit) and four 13C nuclear spins (memory qubits). Entanglement is generated via photonic links for distributed quantum gates.
Theoretical Foundations: Parallelism in Distributed CNOTs
The core insight is that logical sequences of CNOT gates sharing either a control or target qubit, though apparently sequential in the logical circuit, can be mapped to parallel physical operations if appropriate shared entanglement is available. The baseline decomposition treats each distributed CNOT as a multi-step protocol requiring separate entanglement generation and conditional local operations, thus scaling depth linearly with the number of gates.
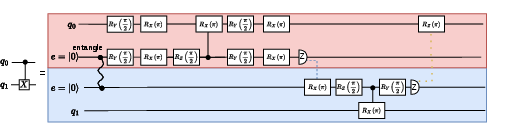
Figure 2: Standard implementation of a distributed CNOT gate; the logical CNOT is realized as a sequence of entanglement generation, communication, and local qubit operations, setting the baseline depth.
When several CNOTs share a control qubit, the logical-to-physical mapping can be transformed to exploit a multipartite entanglement resource, allowing all such gates to be implemented simultaneously, effectively compressing depth from O(n) to a constant overhead plus one per additional gate.
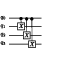
Figure 3: Sequence of logical CNOTs sharing a control qubit. Though sequential at the logical level, these can be decomposed into a parallel implementation.
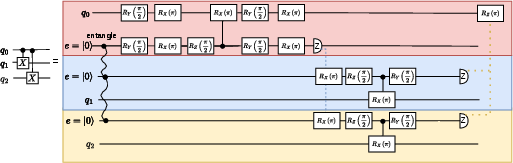
Figure 4: Parallel decomposition of n distributed CNOTs with a shared control qubit across n nodes; multipartite entanglement enables simultaneous execution.
Similarly, for sequences with a shared target qubit, an alternative decomposition—again leveraging appropriately distributed entanglement—permits parallel execution.
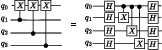
Figure 5: Alternative decomposition for parallel distributed CNOTs sharing a target qubit.
Critically, the physical resource enabling these decompositions is a multipartite entangled state among the nodes, which the paper demonstrates can be established efficiently.
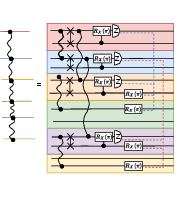
Figure 6: Entanglement creation protocol to distribute the multipartite state enabling parallel distributed CNOTs.
Compiler Architecture and Algorithm
The compiler operates by parsing the logical circuit into buckets representing parallelizable layers, followed by multi-pass sweeps (forward and backward) to restructure buckets containing distributed CNOTs that share control/target qubits. A key design constraint is that only transformations guaranteeing non-increasing circuit depth are allowed, ensuring no regression in performance. The decomposition stage algorithmically identifies maximal groups of CNOTs within each bucket that are parallelizable, applies the corresponding physical decomposition, and returns an optimized circuit.
The bucket-based grouping and joint decomposition scheme afford significant depth reductions in distributed settings, whereas previous compilers either ignored such distributed parallelism or risked sub-optimal scheduling due to lack of hardware-awareness.
Empirical Results
The compiler was benchmarked on both realistic quantum circuits (e.g., Deutsch-Jozsa and Bernstein-Vazirani circuits from MQTBench) and over 1,000 synthetic circuits engineered to contain distributed CNOT patterns. In all tests, the compiler never increased circuit depth—owing to its conservative transformation criteria—and consistently achieved substantial reductions for circuits exhibiting sequential distributed CNOT chains. For circuits with inherent logical parallelism, the compiler left the depth unchanged, demonstrating robustness and avoidance of overfitting.

Figure 7: Relative circuit depth improvements for DJ and BV circuits with increasing qubit count, demonstrating scaling of compiler effectiveness.
A comprehensive synthetic benchmark revealed depth reductions across high fractions of the test set with no depth increases; relaxing conservatism in the transformation criteria yielded larger reductions in some cases, but at the cost of introducing depth increases, motivating the choice of conservative bucket merging as a practical strategy.
Implications and Future Directions
The integration of hardware-aware decomposition and depth-driven scheduling in logical-to-physical compilation as demonstrated in this work establishes a clear methodology for leveraging physical layer capabilities in distributed quantum platforms. From a practical standpoint, this supports improved fidelity and feasibility of NISQ-era algorithms executed on modular quantum computing architectures, enabling deeper circuits before the onset of noise-induced failure. Theoretically, it motivates further investigations into the interaction of circuit structure, hardware topology, and quantum resource distribution.
Further progress can be envisaged in:
- Extending this framework to non-all-to-all connected architectures and more general entanglement distribution strategies.
- Incorporating joint optimization across multiple layers of abstraction, e.g., integrating routing and error correction with logical gate scheduling.
- Dynamically adapting compiler strategies to emerging physical architectures with richer native entanglement operations.
Conclusion
This paper introduces a logical-to-physical quantum circuit compiler for distributed quantum systems that uncovers and leverages parallelism in sequential-looking logical CNOT gate sequences. Through a combination of bucketization, rescheduling, and hardware-specific multi-gate decomposition, the compiler achieves consistent and scalable reductions in circuit depth without sacrificing correctness. This development is emblematic of the broader trend toward tightly coupled, hardware-aware software stacks in quantum computing, and sets the stage for further advancements in NISQ-era and distributed quantum compilers.