- The paper presents PNPF, a method that unifies phase-based feedback and safety through closed-loop neural potential functions for motion generation.
- It employs two energy functions—a nominal energy to ensure task progress and a safety energy using neural SDF—to guide recovery and obstacle avoidance.
- Empirical evaluations show significant improvements in DTW distance and endpoint accuracy across various robotic manipulation tasks, validating the method's robustness.
Reactive Motion Generation with Phase-varying Neural Potential Functions
Motivation and Problem Statement
Learning-from-Demonstration (LfD) demands robust policies for robot motion that generalize from limited demonstrations and adaptively recover from perturbations. Existing dynamical systems (DS) approaches bifurcate into state-only models, which offer reactivity but struggle with trajectory intersections, and phase/time-dependent models, which manage repeated state visits but sacrifice robust feedback. Second-order DS models, incorporating velocity for disambiguation at intersections, become vulnerable to velocity disturbances and ambiguities arising from nearly identical position-velocity pairs yielding different onward actions. Phase-based movement primitives, conversely, exhibit limitations in recovering after spatial or temporal perturbations due to their open-loop nature.
Methodology: Phase-varying Neural Potential Functions (PNPF)
PNPF establishes a unified framework for reactive motion generation by learning artificial potential functions conditioned on a closed-loop phase variable derived from task progress, not temporal scheduling. The formulation leverages two distinct energy functions:
- Nominal Energy: Scalar measure of task progress, designed to decrease monotonically along synthesized nominal trajectories, serves as the basis for closed-loop phase estimation.
- Safety Energy: Encodes a demonstration-driven safe set via a neural Signed Distance Function (SDF), guiding recovery to the demonstrated region and constraining exploration to reliably validated states.
The potential function ϕ(x∣s), parameterized jointly by robot state x and phase s, yields a vector field −∇xϕ(x∣s) that efficiently steers the robot towards task completion while maintaining safety compliance. The phase variable is updated via ϕnominal(x), enabling closed-loop synchronization with task progression and effective handling of repeated states.

Figure 1: Reactive motion generation scenarios illustrating ambiguous velocity-based branch points in knotting and 8-shaped periodic tasks.
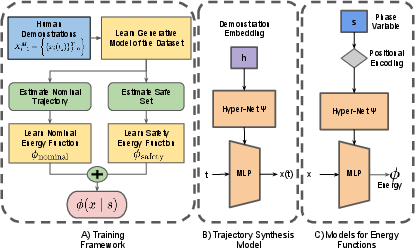
Figure 2: Architectural overview, including neural field-based potential function construction and hypernetwork-driven trajectory generation.
Trajectory Synthesis and Energy Function Modeling
Demonstrations are augmented using a decoder-only neural generative model, densifying interpolated trajectories and estimating the nominal path and safe region. The nominal trajectory is selected by minimizing dynamic time warping (DTW) distance to demonstrations, and the safe set is defined by a continuous SDF constructed from densely sampled states along interpolated trajectories. Two energy functions are then modeled:
- Safety Energy: ϕsafety(x)=relu(λsafety⋅SDF(x)), where the SDF provides a smooth distance metric from the safe set boundary.
- Nominal Energy: Remaining arc length along the nominal trajectory, projected to nearest points for off-path states, ensures monotonic progress encoding.
These energies are compositional, enabling additional terms (e.g., for obstacle avoidance) following standard potential function formulations.
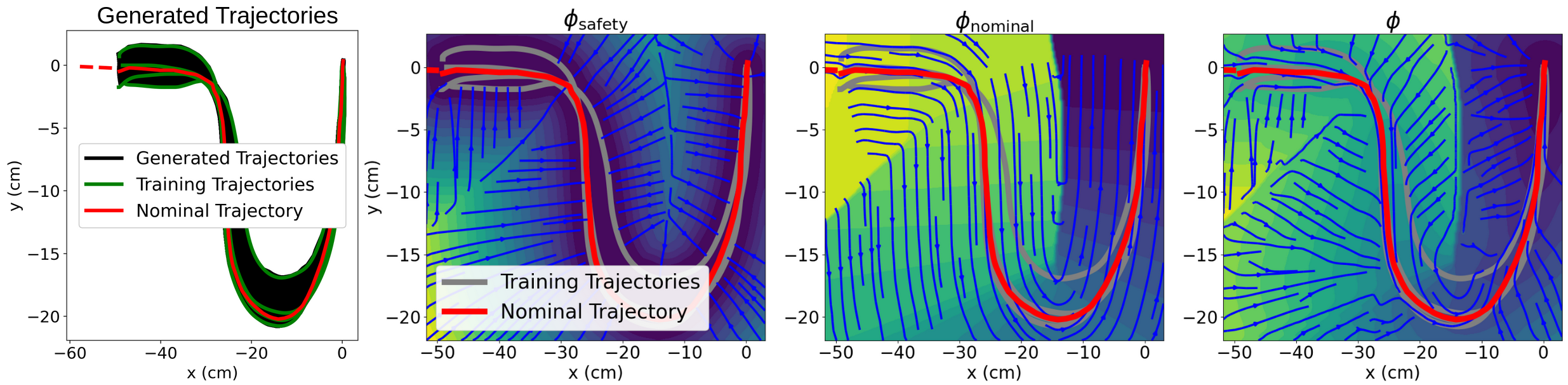
Figure 3: Generated trajectories and potential function ϕ(x), showing dense coverage of the safe set, monotonic nominal path, and distinct energy gradients.
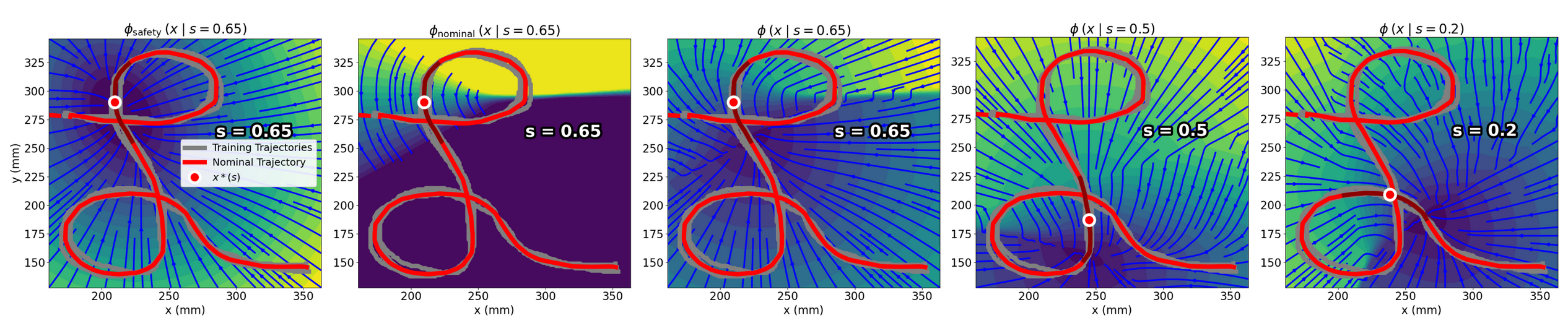
Figure 4: Phase-varying visualizations of nominal and safety energies, illustrating velocity disambiguation for repeatedly visited states across different task phases.
Theoretical Foundations: Stability and Smoothness
PNPF's closed-loop system admits a Lyapunov candidate in ϕ(x∣s), guaranteeing regional asymptotic convergence for locally consistent (unimodal) demonstration sets. Architecturally, neural fields (MLPs with ReLU activations and hypernetwork phase conditioning) impose spectral bias for smooth, low-frequency energy landscapes, critical for continuous vector field generation. Gradient-based and lightweight sampling-based safeguards ensure recovery from rare spurious stationary points arising from local gradient cancellations.
Periodic and 6D Motion Extensions
Periodicity is enabled via sinusoidal phase input augmentation, generalizing potential functions and trajectory synthesis to cyclic tasks. Full 6D motions (including orientation) are handled by axis-angle representations in the tangent space of terminal quaternions, allowing angular velocity computation for direct control.
Empirical Evaluation and Benchmarks
Systematic benchmarking across LASA, LAIR, CHAR, CHAR-Periodic (2D), and RoboTasks (6D) datasets demonstrates consistent superiority in DTWD, Fréchet distance, and endpoint accuracy metrics relative to NODE and CONDOR baselines, particularly in scenarios with repeated state visits and trajectory intersections. CHAR and CHAR-Periodic especially highlight PNPF's capability to resolve ambiguities and maintain correct phase progression, reducing DTWD by up to 80% compared to CONDOR.
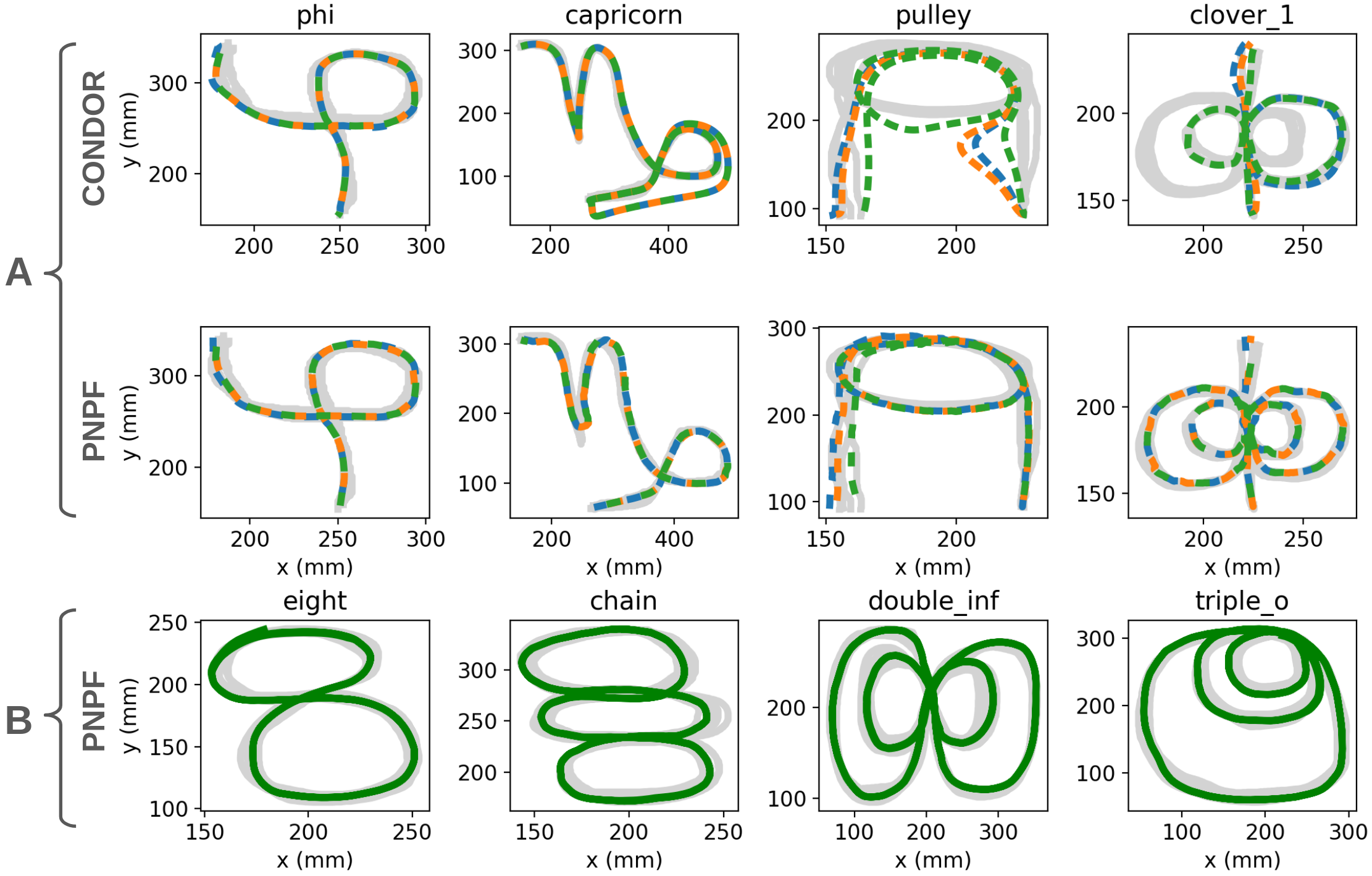
Figure 5: Comparative analysis of PNPF and CONDOR; PNPF reproduces periodic motions faithfully, avoids mismodeling and missing segments prevalent in second-order baseline.
PNPF's robustness against spatial perturbations and obstacle-induced deviations is established through rollout analysis and visual interpretation. Obstacle avoidance is achieved by integrating repulsive potentials, while spatial disturbances (e.g., manual end-effector repositioning and task-frame shifts) are smoothly corrected via closed-loop phase updates, without skipping or repeating segments.
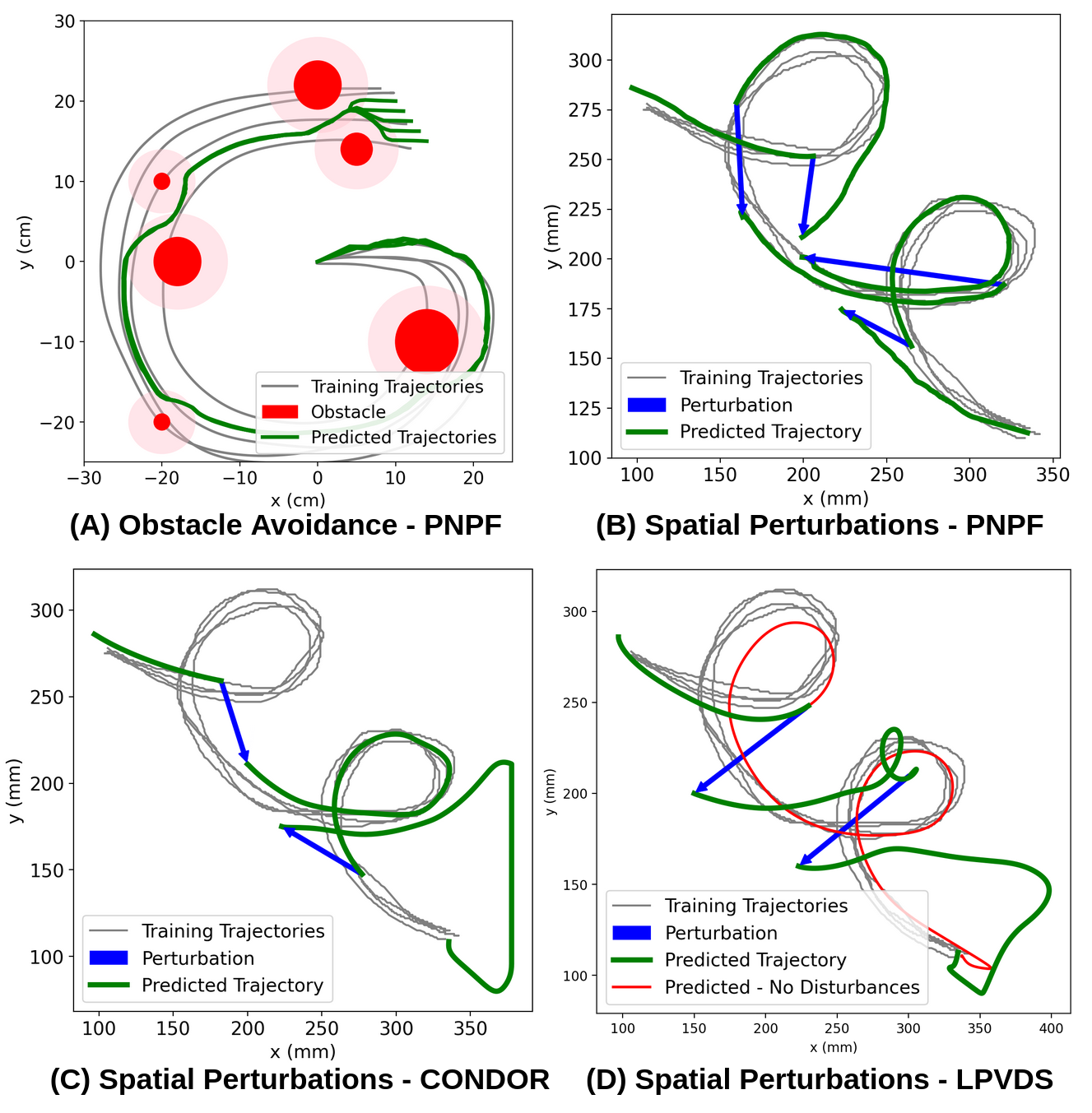
Figure 6: Robustness analysis for obstacle avoidance and spatial perturbations; PNPF maintains task fidelity while baselines (CONDOR, LPVDS) fail to recover.
Real-world Robotic Manipulation Experiments
Three manipulation tasks—knotting, pouring, and 3D wiping—are executed on a UR10 robot using kinesthetic demonstrations. The framework operates in real time, with consistent task execution across varied initializations and perturbation scenarios. Obstacle avoidance is validated with AprilTag-tracked cubes, and spatial disturbances (task frame shifts and manual end-effector displacement) are corrected without critical task steps being missed.


Figure 7: Real robot scenarios—obstacle variations, task frame shifts, and end-effector displacements—validate PNPF’s reactivity in live manipulations.
Implications and Future Directions
PNPF addresses key limitations in DS-based LfD for reactive motion generation, particularly handling task intersections, repeated states, and perturbation recovery. The closed-loop phase variable mitigates ambiguity in progression and velocity, while neural field-based energy modeling ensures smooth, stable control. Practical applications span assembly, manipulation, and cyclic tasks, where robustness to disturbances and compliance with safety constraints are critical.
Current limitations include excessive smoothing in regions of sharp curvature and potential sensitivity to demonstration artifacts. Future work will focus on refining energy term design to preserve directional structure, enhance robustness to noisy demonstrations, and incorporate multimodal sensory feedback (visual, force). Extensions to highly multimodal tasks and automatic demonstration artifact detection/mitigation are promising avenues.
Conclusion
"Reactive Motion Generation via Phase-varying Neural Potential Functions" (2604.26450) proposes a principled approach to LfD-based robot control that unifies reactivity and expressive task modeling through closed-loop phase-conditioned neural potential functions. Empirical and theoretical evaluations confirm improved robustness, generalization, and practical effectiveness across diverse motion generation scenarios. The phase-varying architecture establishes a foundation for further advancements in interpretable and adaptive robot policy learning.