- The paper introduces a unified visual semantic unit that fuses visual, textual, and collaborative signals to construct high-quality semantic IDs for recommendation.
- It details the novel NU-RQ-VAE method which employs learnable non-uniform transformations to correct skewed embedding distributions prior to quantization.
- Experiments on Amazon datasets demonstrate that CARD significantly outperforms baselines with improvements exceeding 10% in Recall@10 and NDCG metrics.
The paper addresses item representation in generative recommendation frameworks, focusing on constructing high-quality Semantic IDs (SIDs) for effective autoregressive next-item prediction. SID construction in generative recommenders faces two principal challenges: (1) insufficient supervision for heterogeneous fusion impeding effective multimodal signal integration, and (2) non-uniform semantic distributions causing codeword imbalance and generation bias in discrete SID space. Traditional approaches either rely on modality-specific encoders or employ post-hoc fusion/alignment mechanisms, resulting in semantic gaps, insufficient discriminability, and suboptimal quantization when embeddings are highly skewed, especially across dense item clusters and sparse long-tail regions.
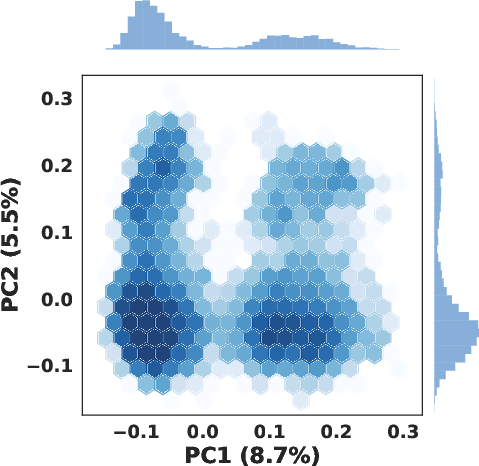
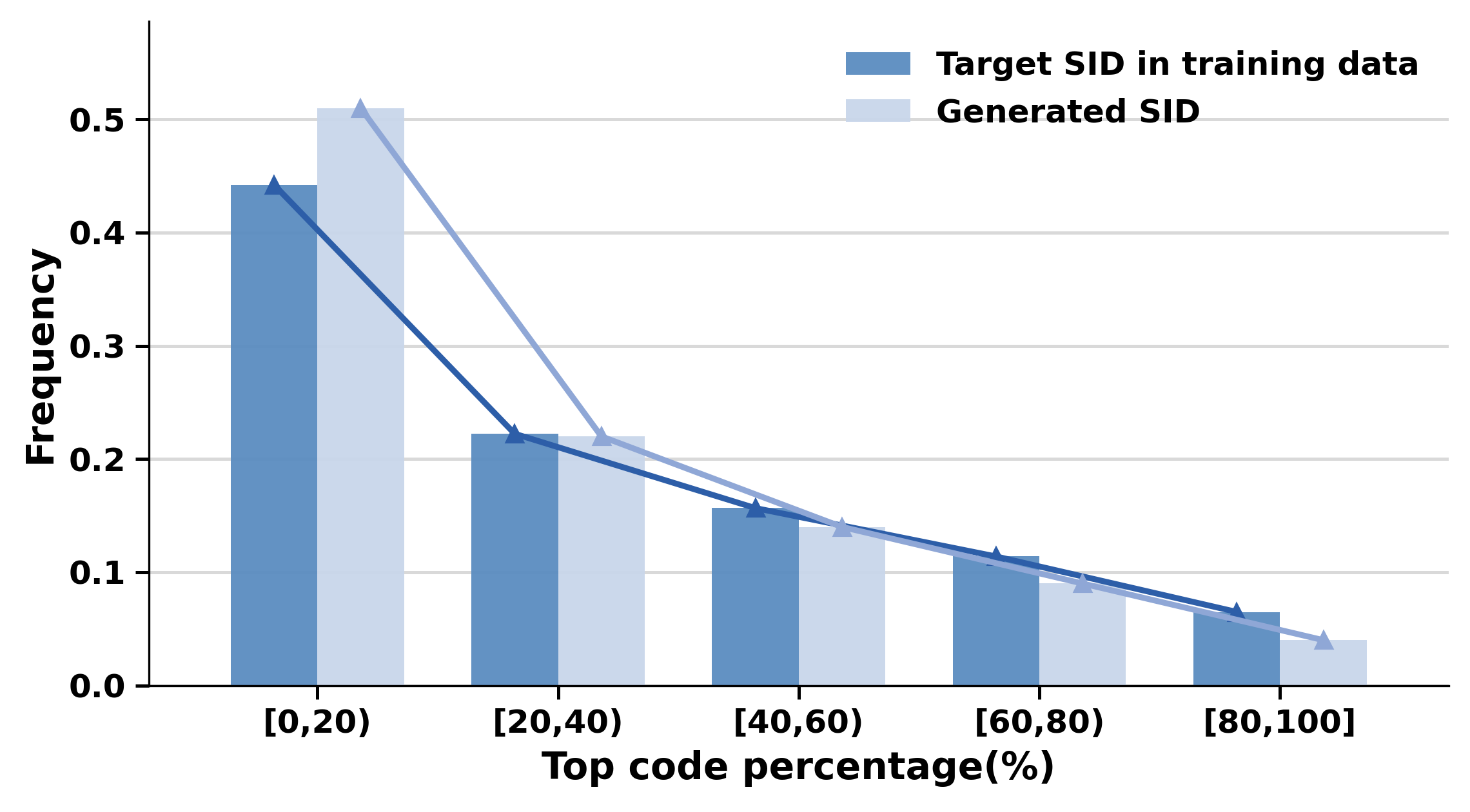
Figure 1: PCA visualization shows dense clusters versus sparse regions for item embeddings (left), and highly skewed codeword usage that causes generation bias (right).
To reconcile these limitations, the CARD framework introduces pre-encoding fusion using visual semantic units, which embed textual, visual, and collaborative signals into a unified structured image. This image is processed by a vision-language encoder (SigLIP2), effectively conducting holistic semantic modeling before discrete quantization.
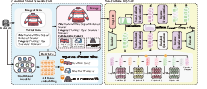
Figure 2: CARD overview: item signals unified via card-style image; encoded with SigLIP2; quantized with NU-RQ-VAE; SIDs used for generative next-item prediction.
Visual semantic units comprise: the visual region (item image), textual region (attributes rendered as text panels), and collaborative region (collaborative neighbors rendered as thumbnails with titles, extracted via metric-based neighbor search in latent space). This fusion circumvents modality-specific encoder limitations and empowers the encoder to extract semantically consistent, quantization-friendly embeddings.

Figure 3: Examples of visual semantic units integrating visual, textual, and collaborative signals for Clothing and Food datasets.
Given the observed highly non-uniform semantic distribution in item representations, the paper proposes NU-RQ-VAE—a residual quantization variational autoencoder incorporating learnable, invertible non-uniform transformations. Two instantiations are introduced:
- Kumaraswamy-based CDF transformation: leveraging closed-form parameterization to map original semantic embeddings to an approximately uniform latent space, ideal for distributions bounded in [0,1].
- Scaled Logistic-Logit transformation: tailored for bell-shaped latent distributions (empirically validated in both T5 and SigLIP2 embeddings), implemented through parameter-invariant scaling around the domain boundaries.
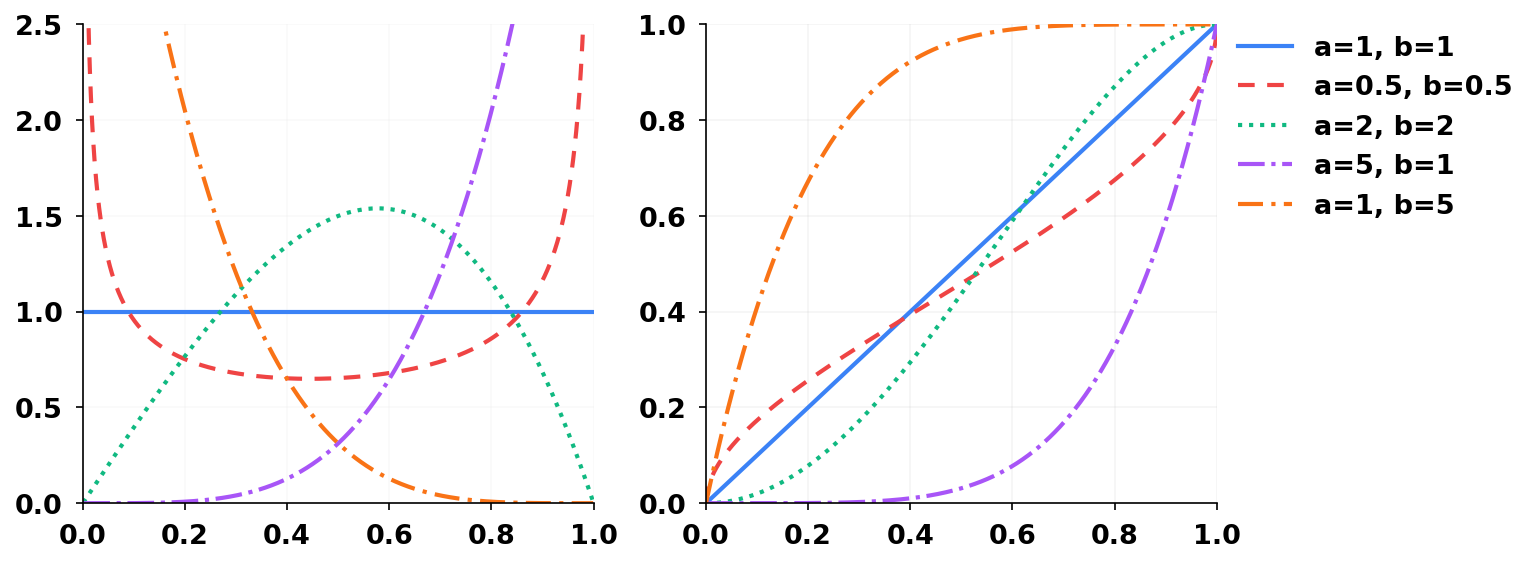
Figure 4: PDF/CDF of the Kumaraswamy distribution, demonstrating tractability for reparameterizing non-uniform semantic distributions.
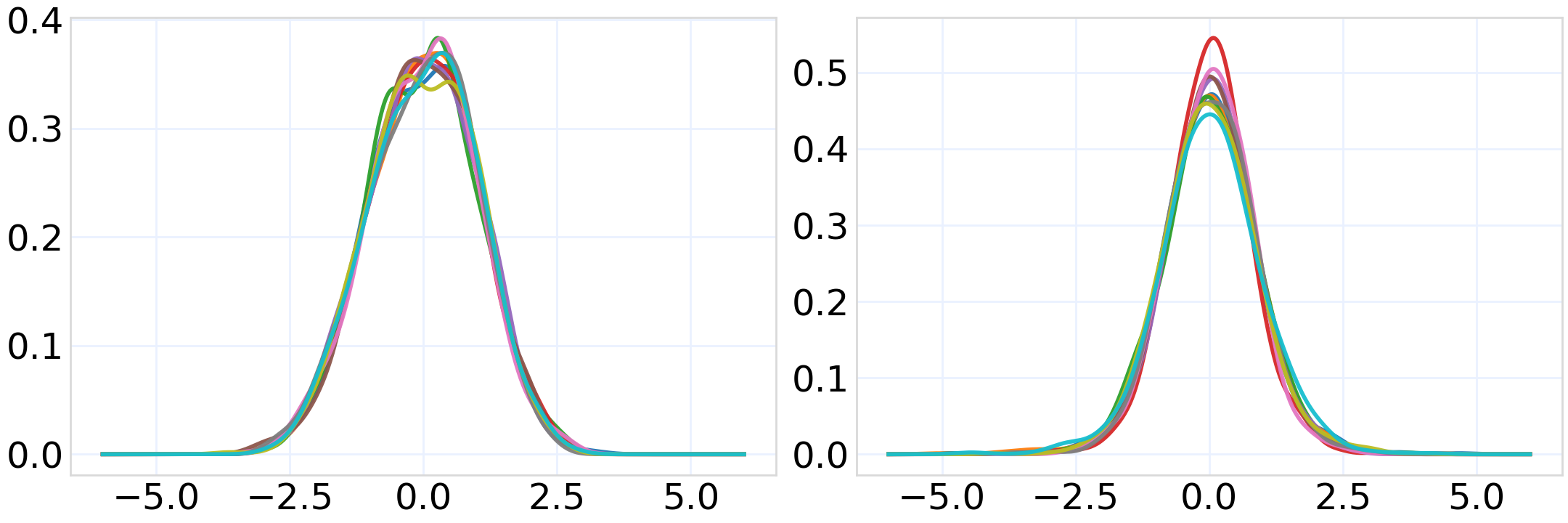
Figure 5: Embedding histograms from T5 and SigLIP2 show bell-shaped distributions, motivating scaled logistic/logit transformations.
Non-uniform transformation T is applied prior to quantization, with the inverse T−1 during reconstruction. Consistency loss ensures stability and semantic fidelity. Quantization is performed with multi-level codebooks, subsequently decoded for autoregressive sequence generation.
Experimental Validation and Numerical Results
Rigorous evaluation on three Amazon datasets (Food, Phones, Clothing) demonstrates that CARD significantly outperforms both classical sequential recommenders (GRU4Rec, SASRec, BERT4Rec) and recent generative recommenders (TIGER, LETTER, MQL4GRec, MACRec) by wide margins across Recall@K and NDCG@K metrics. CARD's improvement is attributed to better integration across modalities and effective correction of distributional skew during quantization.
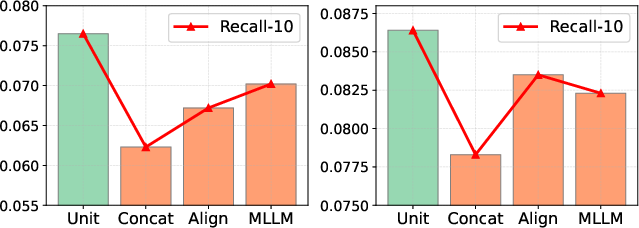
Figure 6: Recall@10 comparison for multimodal fusion strategies. CARD's unified visual semantic unit surpasses concatenation, contrastive alignment, and LLM joint encoding.
Ablation studies reveal that removing any semantic region (visual, textual, or collaborative) degrades performance, and reverting to standard quantization aggravates codeword imbalance and generation bias. Analysis of plug-and-play robustness shows non-uniform quantization consistently yields stable gains across diverse quantization schemes (RQ-VAE, R-VQ) with relative improvements >10% for Recall@10.
Distributional Analysis and SID Quality
Application of non-uniform transformations yields more balanced embedding distributions and significantly increases effective codeword utilization in SID space. Generated SID distributions match target SID distributions more closely, mitigating generation bias.
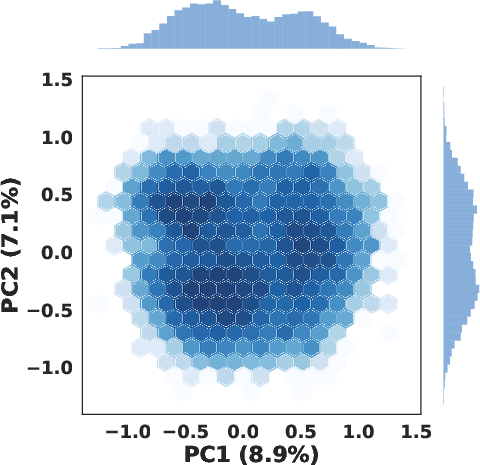
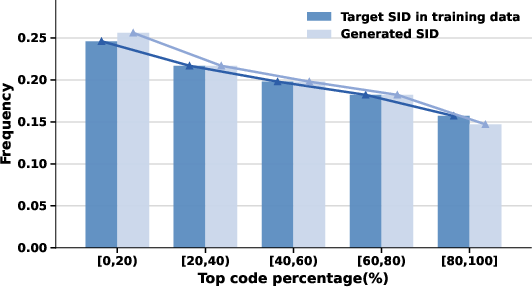
Figure 7: Embedding distribution post non-uniform transformation (left) and balanced codeword usage (right) indicating reduced generation bias.
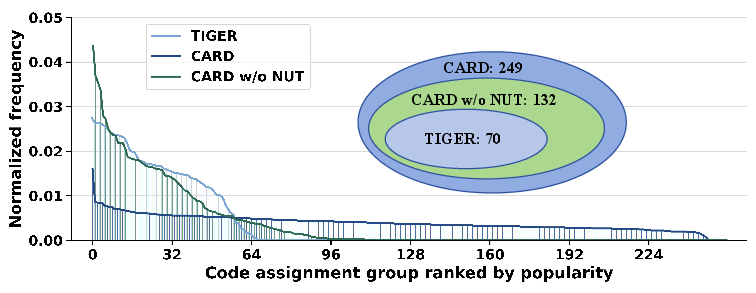
Figure 8: Codeword utilization: CARD with non-uniform transformation attains more balanced codebook usage compared to TIGER and standard variants.
Practical and Theoretical Implications
The findings indicate that holistic multimodal fusion via visual semantic units is preferable for SID construction under insufficient supervision, as it produces embeddings that are semantically rich and quantization-friendly. Non-uniform quantization is quantizer-agnostic and robust, suitable for generative recommendation scenarios typified by distributional skew and high interaction sparsity. The methodology could generalize to broader semantic tokenization and codebook-based generative modeling tasks.
Future work may automate visual semantic unit construction, potentially leveraging generative vision-LLMs or graph-based structured rendering, improving scalability for large-scale item corpora.
Conclusion
CARD presents a comprehensive solution to SID construction for generative recommendation, resolving two pivotal challenges: modality fusion and quantization in non-uniform embedding spaces. Through unified visual semantic modeling and learnable, invertible non-uniform transformations, CARD achieves superior recommendation performance, balanced SID generation, and strong robustness to distributional variations. This paradigm marks a substantial step toward reliable, distribution-aware SID generation and points to future opportunities in automated representation structuring for scalable, plug-and-play generative recommendation systems.