- The paper demonstrates that integrating multi-modal representations enhances detection by leveraging code tokens, AST features, and stylometry signals.
- The model employs a reduced non-terminal AST and RoBERTa-style transformer, achieving up to a 48% absolute F1 score improvement on benchmarks like BigVul.
- The paper reveals that coding style features improve adversarial resilience against basic obfuscation, though challenges remain against coordinated attacks.
VulStyle: Multi-Modal Pre-Training for Code Stylometry-Augmented Vulnerability Detection
Introduction
VulStyle introduces a multi-modal pre-training paradigm for software vulnerability detection by unifying function-level token sequences, reduced non-terminal AST nodes, and code stylometry (CStyle) features. In contrast to earlier approaches relying solely on token or AST-level representations, VulStyle demonstrates that coding style—captured at the structural and syntactic level—contains complementary vulnerability signals particularly salient in memory-unsafe languages such as C/C++. This essay provides a technical summary and analysis of the VulStyle model, the methodological choices underlying its architecture, its empirical effectiveness, and broader implications for the vulnerability detection landscape.
Methodology: Multi-Modal Code Representation
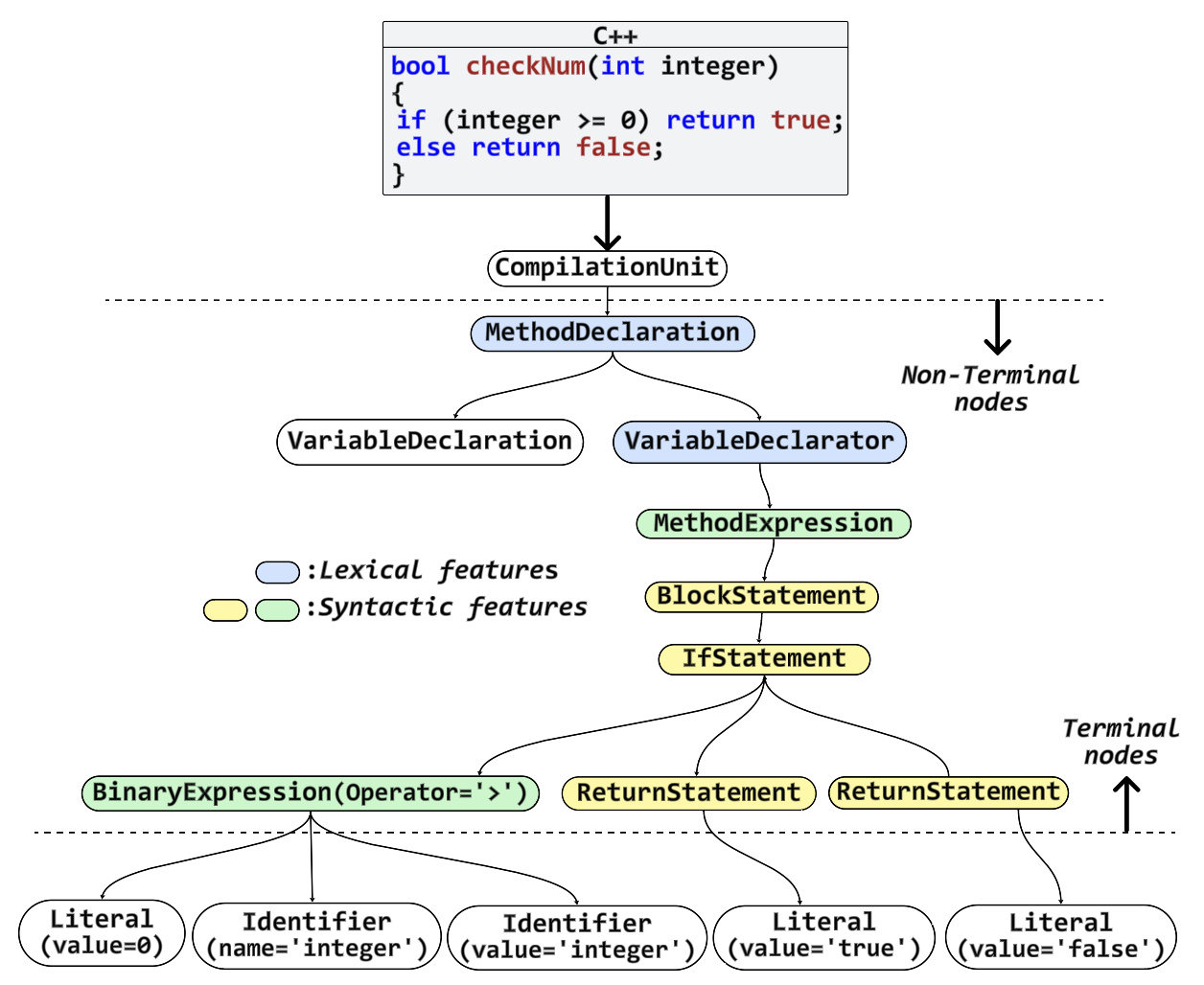
VulStyle leverages three distinct modalities for representing code: function-level token sequences, a reduced set of non-terminal AST nodes, and feature-rich code stylometry vectors. The principal motivation for this design is to capture not only what the code nominally does (semantics) and how it is structured (hierarchy and control/data flow), but also patterns of how developers habitually implement risky constructs.
Figure 1: VulStyle’s architecture showing integrated token, non-terminal AST, and stylometry (CStyle) representations through a RoBERTa-style transformer for pre-training and fine-tuning.
The pre-training phase uses masked language modeling (MLM) on a corpus exceeding 4.9 million functions drawn from CodeSearchNet, VulBERTa, DiverseVul, and Big-Vul. Fine-tuning incorporates CStyle-augmented vulnerability annotations from standard benchmarks including Devign, BigVul, DiverseVul, REVEAL, and VulDeePecker, employing supervised classification objectives.
Model Architecture
VulStyle adapts the RoBERTa-Base transformer as its backbone, extending the input vocabulary and embedding space to accommodate both token and AST-derived sequence streams. The model comprises 12 encoder layers and employs byte-pair encoding. During both pre-training and fine-tuning, inputs are composed as concatenated sequences of code tokens, reduced AST nodes, and stylometric vectors, allowing cross-modal self-attention to induce joint representations.
The MLM procedure randomly masks 15% of modality tokens to stimulate contextual recovery not just from local tokens, but also from correlated stylometric and structural features. For fine-tuning, a classification head is added to optimize binary targets (vulnerable vs. non-vulnerable).
Empirical Results and Analysis
VulStyle achieves state-of-the-art (SOTA) F1 scores on BigVul and VulDeePecker, with gains ranging from 4% to 48% over competitive transformer and GNN-based baselines. On other datasets (Devign, REVEAL, DiverseVul), VulStyle maintains highly competitive or best-average performance, exhibiting stable generalization despite dataset and labeling variance.
Key findings from the reported experiments include:
- BigVul: F1 95.06% (vs. 89.06% UniXcoder, 47.01% VulBERTa-MLP)—a 48% absolute improvement over the strongest purely code-token-based approach, attributable to stylometric and reduced-AST signals correlating with real-world risky programming practices.
- VulDeePecker: F1 97.76% (vs. 93.44% UniXcoder)—confirming robust detection amidst diverse real-world and synthetic vulnerability test cases.
- Ablation analysis demonstrates that both AST and CStyle signals are complementary: neither alone provides SOTA accuracy, but their synergy yields the strongest detection capability.
The error analysis underscores characteristic failure modes:
- False Positives are driven by code exhibiting “risky” style but semantically safe logic.
- False Negatives cluster around logic flaws invisible to the stylometric and structural modalities (e.g., cryptographic misuse with consistently professional style).
Stylometry and Adversarial Robustness
A salient theoretical contribution of VulStyle is the formalization of a threat model considering attacker attempts at vulnerability obfuscation via stylistic and structural perturbation. By incorporating CStyle features (which are statistically harder to mask without significant refactoring) and structural AST features, VulStyle demonstrates resilience to light obfuscation such as renaming or formatting changes. However, the model is not robust to sophisticated adversaries who coordinate cross-modality, compiler-preserving modifications—pointing to the need for integrating even deeper semantic and symbolic reasoning in future models.
Limitations
VulStyle inherits limitations of function-level detectors: lack of modeling of inter-procedural or global-program context, and dependence on the quality and diversity of labeled vulnerability datasets. Stylometric signals are also less effective on templated or machine-generated code (e.g., LLM-created codebases), where homogenous authorial patterns may defeat the system’s inductive bias. As benchmark datasets continue to suffer from mislabeling and annotation noise, empirical comparability remains predominantly relative, not absolute.
Implications and Future Directions
VulStyle’s strong empirical results confirm that multi-modal code representation is critical for exposing subtle vulnerability patterns linked to recurring developer behavior, especially in programming languages with notorious memory safety problems. Practically, this methodology signals a maturation in static vulnerability detection, where integrating developers’ idiomatic habits with structural program features enables more robust pretrained detectors applicable in CI/CD pipelines, secure supply-chain code reviews, and automated patch vetting.
Theoretically, the work calls for continued exploration of multi-modal architectures, potentially fusing graph neural representations, symbolic execution outputs, and dynamic analysis traces with stylometry-aware deep models. Addressing adversarial robustness and scaling to real-world, multi-language, and LLM-generated code contexts remain pivotal targets for future development.
Conclusion
VulStyle presents a well-motivated, technically rigorous approach to software vulnerability detection that combines code stylometry, reduced AST structure, and function-level content in a single transformer framework. This enables detection of vulnerabilities correlated with risky implementation habits, yielding SOTA metrics across established C/C++ benchmarks. Although limitations remain in the domain of semantics-only vulnerabilities and adversarially constructed examples, the multi-modal paradigm sets a strong foundation for next-generation vulnerability detectors and invites further inquiry into cross-modality and semantic-rich program understanding.
References
For further reference, see the full paper "VulStyle: A Multi-Modal Pre-Training for Code Stylometry-Augmented Vulnerability Detection" (2604.26313).