- The paper introduces transformer-based models for static vulnerability detection, achieving up to 98.8% F1 score on balanced datasets.
- The methodology fine-tunes DistilBERT, CodeBERT, and Gemma-2B on program slices to capture both local and global code contexts.
- The study demonstrates that strategic data balancing significantly reduces computational costs while maintaining high detection accuracy.
Introduction
Software vulnerability detection remains a critical challenge in modern software engineering, particularly for C/C++ systems where memory management and pointer manipulation introduce substantial attack surfaces. Traditional approaches such as symbolic execution and static taint analysis are constrained by scalability and their inability to generalize to diverse vulnerability patterns. The advent of deep neural networks, especially RNN-family models such as BiLSTM and BiGRU, improved detection by learning from program slices but inherently lacked the capacity to leverage long-range code dependencies due to context window limitations.
This work systematically investigates transformer architectures for static vulnerability detection, fine-tuning DistilBERT, CodeBERT, and Google Gemma-2B on program slices from C/C++ code. By leveraging transformers' global self-attention, the models capture both local and global contexts around vulnerability constructs—API calls, array usage, pointer manipulation, and arithmetic expressions. The research examines the impact of data balancing strategies, demonstrating that carefully designed training sets significantly amplify model effectiveness even at moderate computational budgets.
Data Preparation and Sampling Strategies
Transformer-based models' effectiveness is often compromised by severe class imbalance inherent in vulnerability datasets—non-vulnerable samples vastly outnumber vulnerable instances. The authors propose two hypothesis-driven down-sampling strategies to address this:
- Hypothesis 1: Equal Distribution by Subclass: The dataset is balanced by including all vulnerable instances per vulnerability subclass and a random, equal-sized non-vulnerable subset for each. This facilitates the retention of vulnerability-specific features while averting model bias.
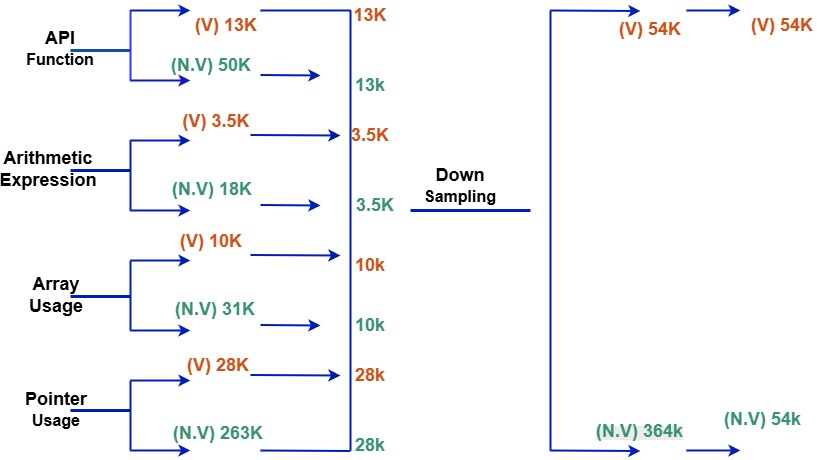
Figure 1: Down-sampling under Hypothesis 1 ensures each vulnerability subclass has balanced distributions between vulnerable and non-vulnerable samples.
- Hypothesis 2: Balance by Smallest Subclass: The dataset is strictly balanced using the smallest subclass (e.g., Arithmetic Expression's 3,475 vulnerable samples), mirrored for non-vulnerables per subclass. This yields a minimal, highly uniform dataset for determining model performance under resource-constrained data regimes.
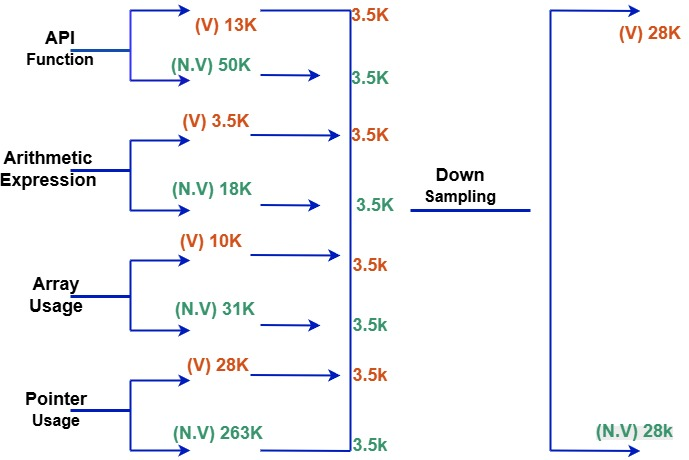
Figure 2: Under Hypothesis 2, all subclasses are limited to the size of the smallest one, maximizing class balance at the expense of dataset scale.
These strategies are critical for isolating the effects of data selection on transformer model performance, particularly for small footprint versus large-scale training regimes.
The experimental design evaluates three leading transformer architectures:
- DistilBERT: A compact 6-layer encoder retaining 97% of BERT's accuracy but incurring significantly less computational overhead, making it suitable for practical deployments.
- CodeBERT: A 12-layer bimodal transformer (RoBERTa backbone), pre-trained across code and natural language modalities for enhanced code-structure understanding, especially for intricate semantic vulnerabilities.
- Gemma-2B: A decoder-only 2B-parameter LLM designed for efficiency, adapted here for binary code classification.
Consistent fine-tuning protocols are applied to all models—learning rate 2×10−5, AdamW, batch size 8, sequence length 512, 5 epochs with early stopping, weight decay 0.01, dropout 0.1—to isolate the effects of architecture and training data on downstream code vulnerability detection accuracy.
Full Vulnerability Training (Strategy 2)
When trained on the full balanced subset (56k vulnerable, 56k non-vulnerable samples), DistilBERT achieves a peak F1 of 98.8%, notably higher than previous DistilBERT (~88.9%) and CodeBERT (~89.2%) results reported on SARD. CodeBERT and Gemma-2B also attain high F1-scores (96.2% and 96.9%, respectively), at the expense of increased training time and memory consumption.
Minimal Subset Training (Strategy 1)
On a strictly minimal balanced set (3,475 samples per class per subclass), all models maintain competitive F1-scores above 95%. DistilBERT and CodeBERT train in 0.13–0.24 GPU hours, while Gemma-2B requires over 12 hours. This reflects the strong value of careful data balancing and the diminishing returns from model scaling for modestly sized, well-designed datasets.
Generalization to Full Test Set (Strategy 3)
When small balanced subsets are used for training but evaluated against the complete large-scale test corpus, F1-scores drop by 8–10%, underscoring generalization failures. Despite this, DistilBERT and CodeBERT remain competitive with significantly more resource-intensive architectures.
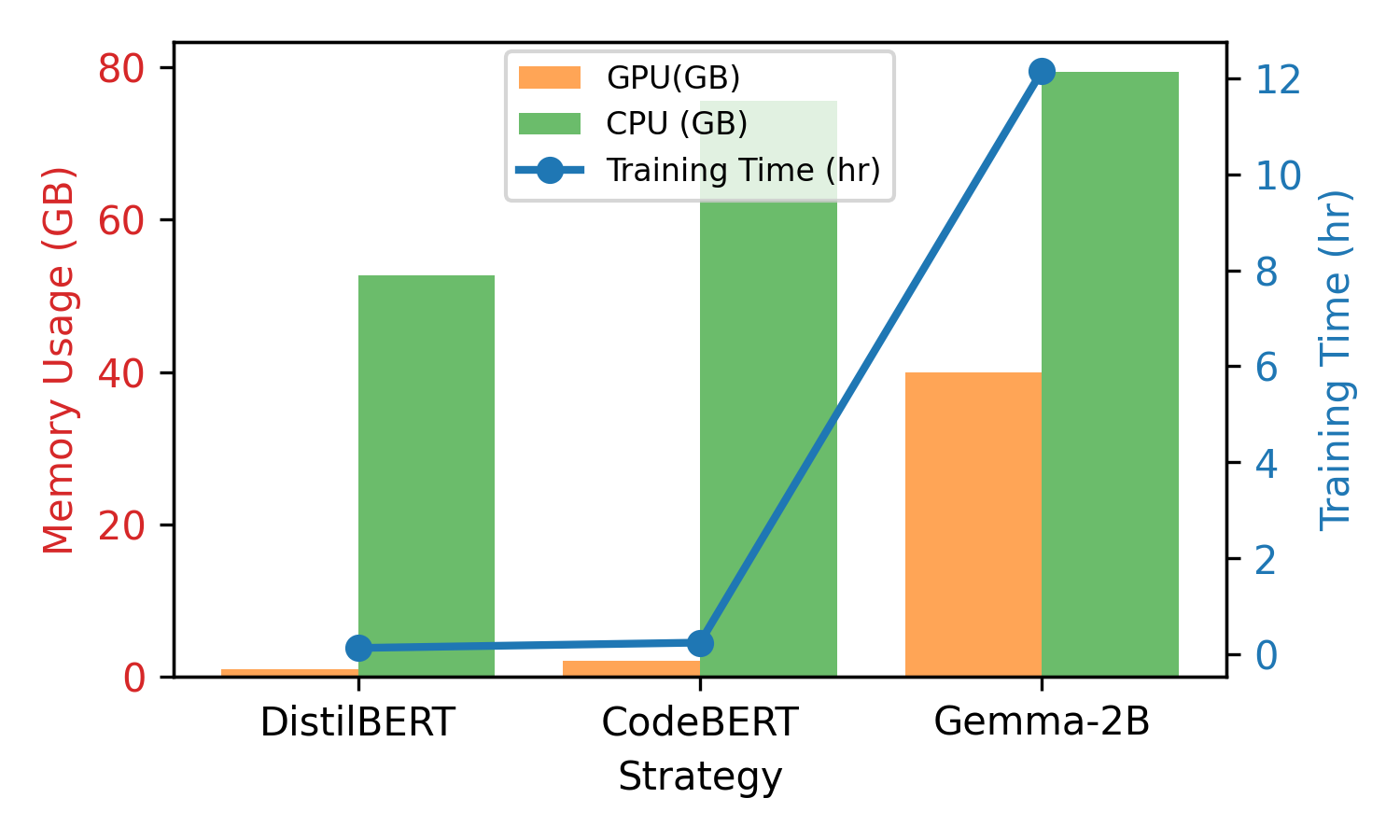
Figure 3: Model performance degrades on the full test set when trained solely on a small, balanced subset, indicating limited generalization.
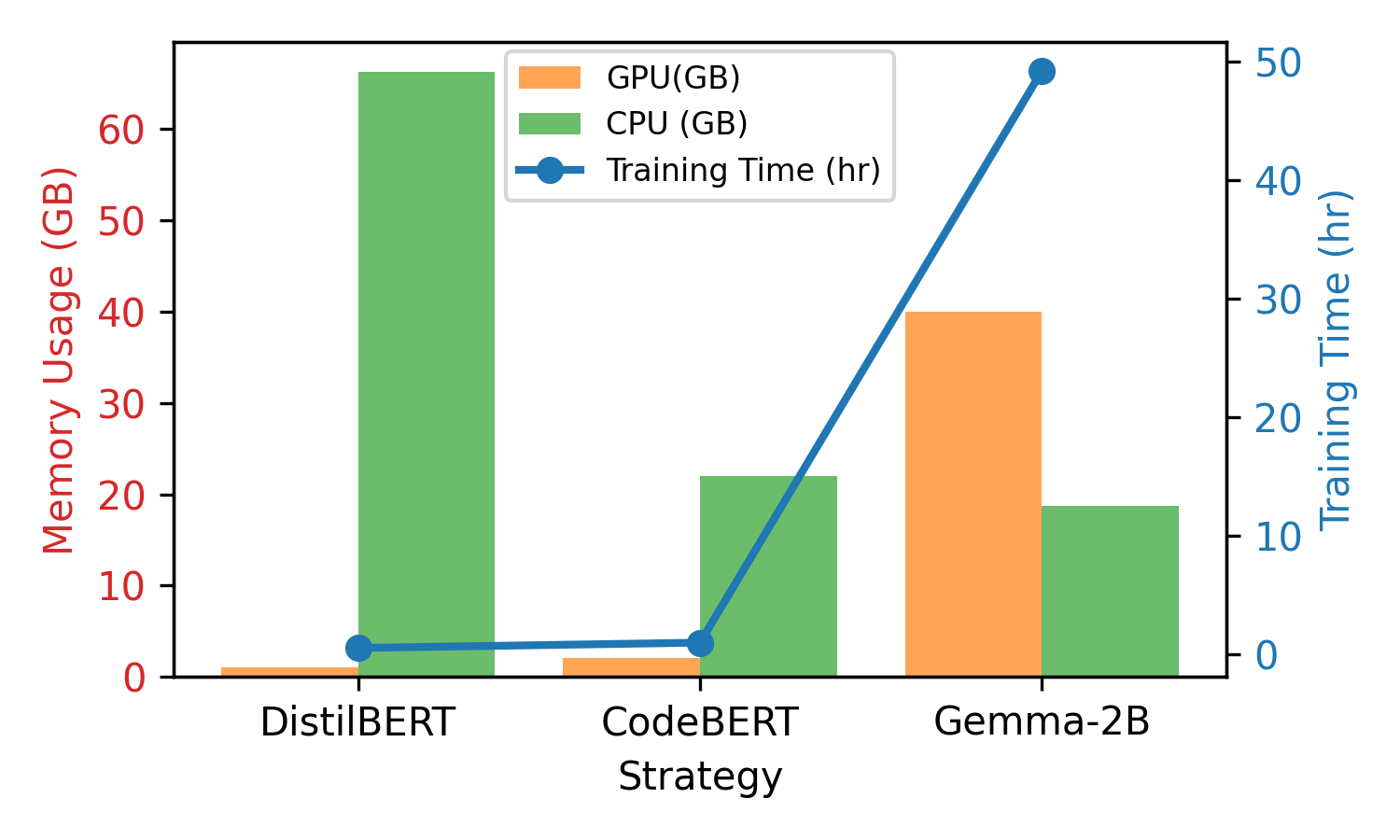
Figure 4: With the full vulnerability training set, model performance improves, confirming data volume–accuracy correlation.
Architectural and Data Strategy Trade-offs
A critical empirical finding is the efficiency–accuracy Pareto frontier: Balanced, smaller transformers like DistilBERT close the accuracy gap with much larger LLMs when well-tuned and supplied with balanced training data. For instance, DistilBERT reached within 2% F1 of Gemma-2B while incurring almost 40× less training time and 20× lower memory usage. This suggests that, for vulnerability detection, investing in data curation and balance is as impactful as architectural complexity.
Practical Deployment Implications
Resource-constrained applications (e.g., CI/CD security scans, edge analysis) can leverage small transformer models for near-optimal detection. Scaling up to LLMs should be reserved for scenarios requiring marginal F1 improvements under abundant compute budgets.
Theoretical Insights and Future Directions
The results expose the limitations of overly large models for code vulnerability detection relative to thoughtful data strategies. New research directions include exploring transformer variants with code-specific pretraining tasks, integrating symbolic reasoning with self-attention, and examining domain adaptation between languages. Further, improvements in program slice selection and automated dataset augmentation can yield consistent accuracy gains without model overparameterization.
Conclusion
Transformer-based approaches, specifically those leveraging efficient architectures like DistilBERT, offer highly effective solutions for C/C++ vulnerability detection when paired with carefully balanced datasets. The study provides strong evidence that model scaling beyond modest-sized transformers offers only marginal improvement relative to the computational cost, while data-centric strategies—especially balancing and slicing—are clear force multipliers for accuracy. Future AI advancements in software security should focus on intelligent data curation, domain-specific pretraining, and architectural efficiency to democratize vulnerability detection across diverse deployment environments (2604.00112).

