- The paper presents MultiVul, a multimodal contrastive learning framework that integrates generated natural language comments with code to improve vulnerability detection.
- MultiVul employs a dual-encoder architecture with code and text encoders, using dual CLIP objectives and cross-view consistency regularization to create robust shared representations.
- Experimental results show up to 27.07% F1 score improvement and strong OOD performance, with inference latency comparable to code-only methods ensuring practical deployment.
Learning Generalizable Multimodal Representations for Software Vulnerability Detection
Introduction and Motivation
The paper addresses the challenge of software vulnerability detection, where increasing diversity and prevalence of vulnerabilities in source code stress the limits of conventional static/dynamic analyses and modern deep learning pipelines. Existing neural-based vulnerability detectors, especially those leveraging LLMs, typically use source code as a single modality, neglecting the complementary semantic information available in natural language comments. This modality gap restricts both detection accuracy and generalization, particularly out-of-distribution (OOD), since the learning algorithms overfit narrow code artifacts and fail to encode global program intent and logic that is often explicit or implied in comments.
The work proposes MultiVul, a multimodal contrastive learning framework for vulnerability detection. The method leverages automatically generated code comments at training time and, in a dual-view regime, aligns code and comment representations through a combination of dual CLIP-based similarity learning and cross-view consistency regularization. Code and comment augmentations further enable robust, generalizable embeddings while keeping inference strictly code-only, reflecting real-world deployment.
Framework and Methodology
MultiVul adopts a dual-encoder architecture: code and text encoders project source and corresponding comments, both original and augmented, into a shared embedding space. Dual CLIP objectives are computed for both the original and perturbed (random swap, random deletion) code–comment pairs, promoting semantic alignment across code and textual intent and encouraging robustness to superficial changes. Consistency regularization contracts the representations of original and augmented views, instilling local smoothness and invariance under permitted input perturbations.
For real-world deployment, comments are excluded at test time—code-only inference is performed.
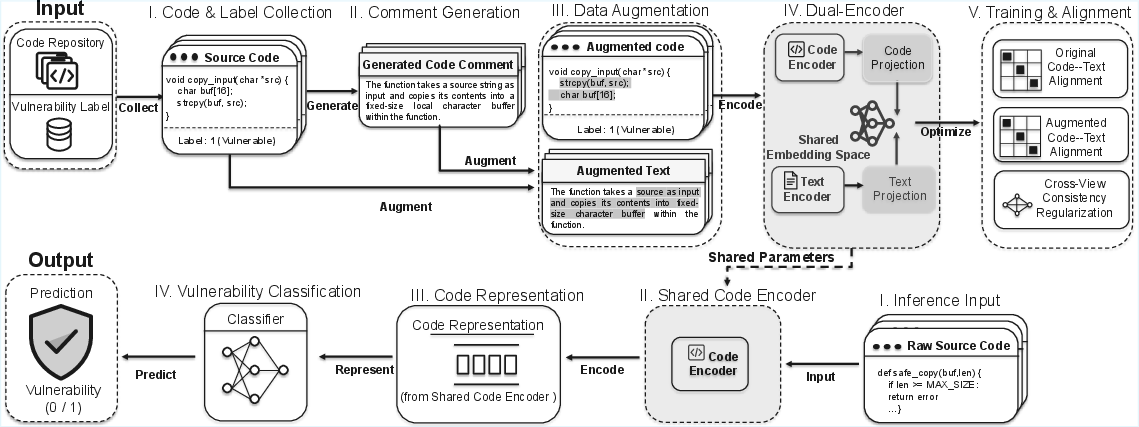
Figure 1: Architecture overview of MultiVul.
Comment generation employs instruction-tuned LLMs (e.g., Qwen2.5-Coder-32B-Instruct) with a critique prompting strategy to minimize hallucination and avoid leakage of vulnerability labels. Perturbations for augmentation include only model-agnostic, lightweight transformations not tied to syntactic or semantic analyses, ensuring language-independence and scalability.
Experimental Design
Evaluation is performed on the benchmark datasets DiverseVul [chen2023diversevul] and Devign [zhou2019devign], using four open LLMs (Qwen2.5-Coder-7B, DeepSeek-Coder-6.7B, StarCoder2-7B, CodeLlama-7B). MultiVul is compared to prompting-based (zero/one/three-shot with/without chain-of-thought) and standard code-only fine-tuning baselines.
Metrics: Accuracy, Precision, Recall, F1 score. OOD generalization is considered by train-test cross-dataset evaluation between DiverseVul and Devign.
Results and Analysis
Detection Effectiveness
MultiVul consistently surpasses both prompting-based and fine-tuning baselines across all datasets and LLMs, with F1 improvements up to 27.07% over prompting methods and 13.37% over code-only fine-tuning. The observed performance gap is especially pronounced on DiverseVul, which is richer in code/project diversity.
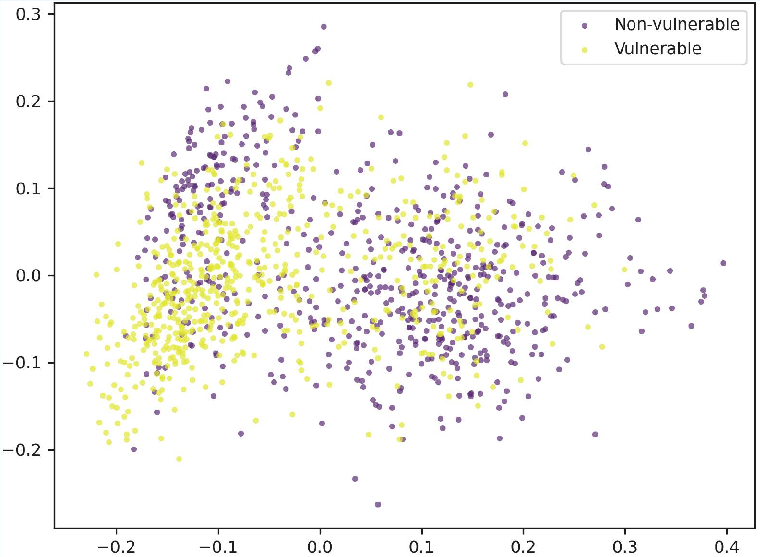
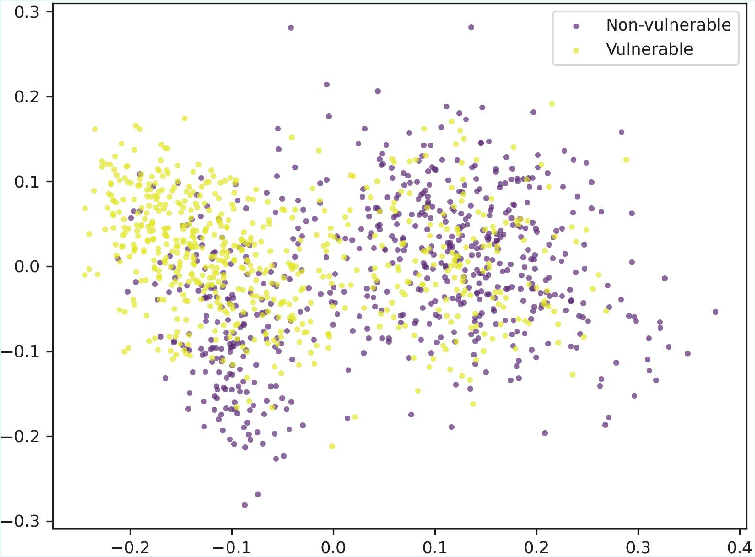
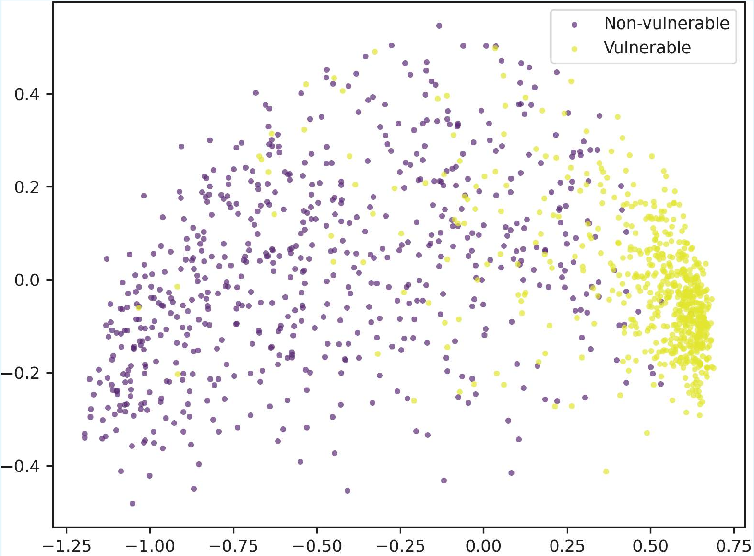
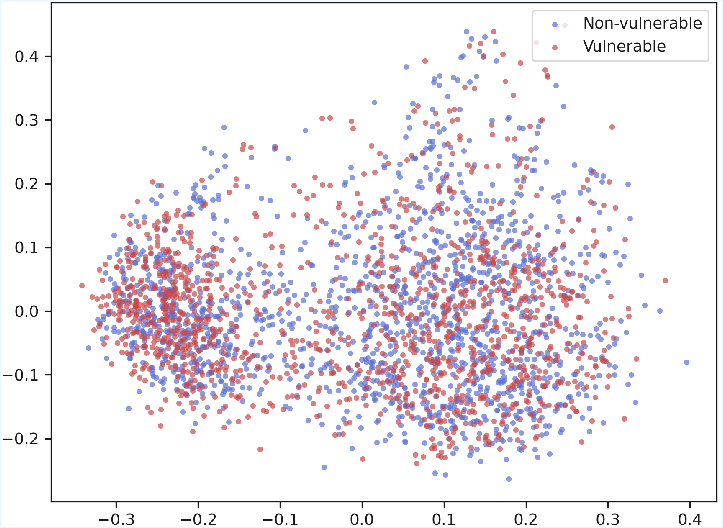
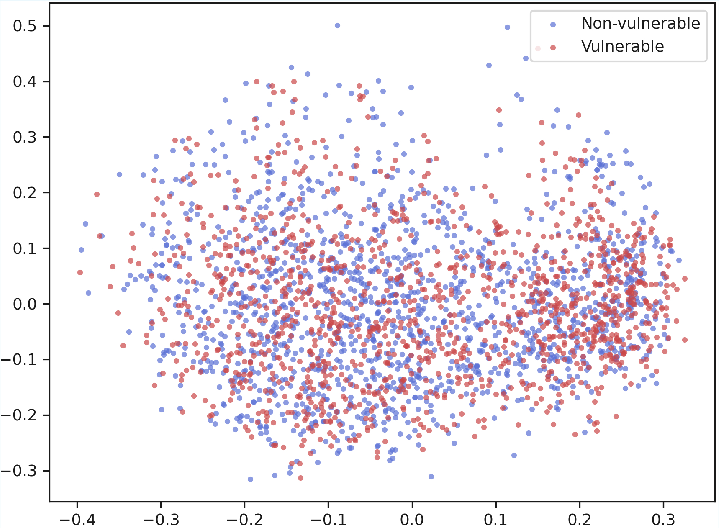
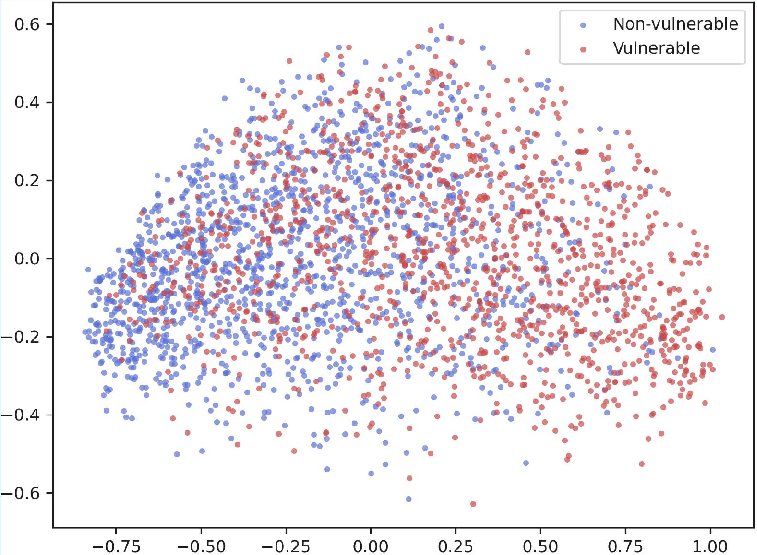
Figure 2: Visualization of code embeddings after dimension reduction using PCA; MultiVul achieves better class separation than Zero-shot or Fine-Tuning on both datasets.
Prompt-based methods, especially with chain-of-thought, inflate Recall but sacrifice Precision, leading to suboptimal trade-offs for real deployments with imbalanced classes. MultiVul’s strong performance is reflected in the structured, separable clustering of code representations revealed by principal component analysis.
Component Analysis
Ablation studies demonstrate that augmented code–comment alignment and cross-view consistency regularization are both necessary for optimal performance. Removing either leads to significant F1 and accuracy drops, particularly under distribution shift (OOD).
Out-of-Distribution Generalization
MultiVul provides substantial gains in cross-dataset generalization: F1 improvements in OOD transfer range up to 17.7% over code-only fine-tuning. Both augmented alignment and consistency regularization are shown to be critical for these results.
Sensitivity and Efficiency
Sensitivity analysis reveals a mild dependence on the scale of the comment generation model; larger LLMs used for generating comments offer marginal in-distribution improvements but provide up to 2.32% gains OOD. In contrast, excessive data augmentation degrades accuracy—mild perturbations yield optimal generalization.
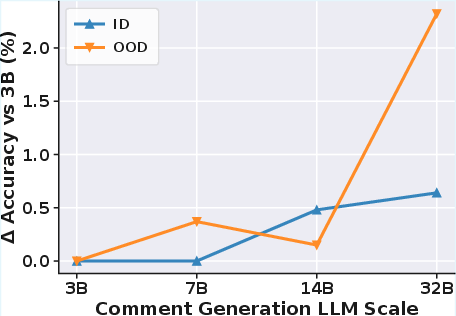
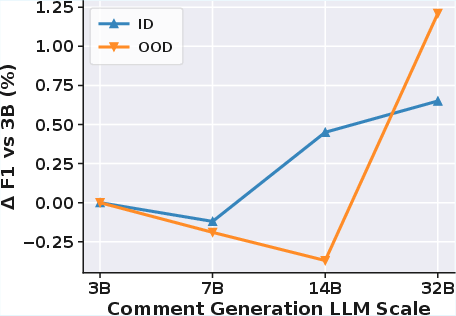
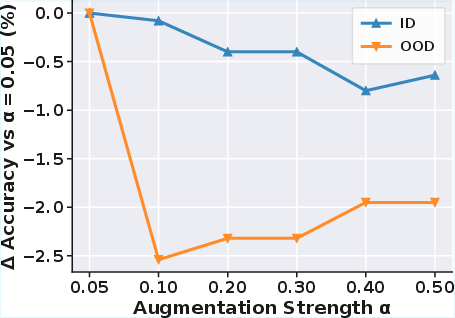
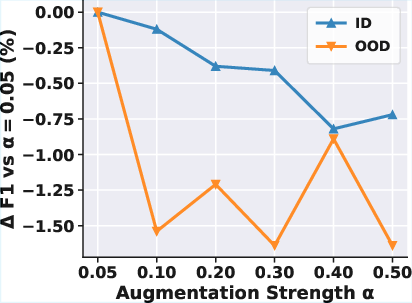
Figure 3: Sensitivity analysis of MultiVul on Qwen2.5-Coder over DiverseVul. Top: impact of comment generation LLM scale; Bottom: effect of data augmentation strength α.
Inference latency for MultiVul is comparable to code-only fine-tuning and one to two orders of magnitude lower than prompting baselines, making it feasible for practical deployment.
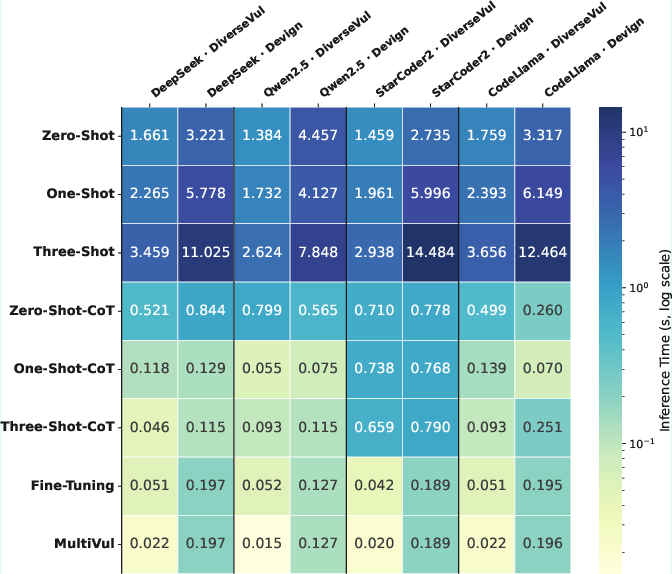
Figure 4: Inference latency across different methods.
Qualitative Analysis
Error analysis by CWE category demonstrates that MultiVul particularly reduces false negatives in categories requiring contextual reasoning (e.g., exceptional-condition handling, memory errors), but offers only marginal improvement for classes like integer overflows that are heavily dependent on value tracking, not necessarily aided by textual alignment.
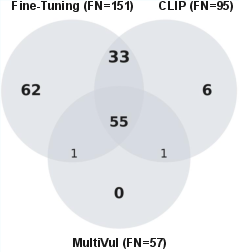
Figure 5: MultiVul resolves 33 vulnerable functions missed by both Fine-Tuning and CLIP, introducing no unique false negatives.
Theoretical and Practical Implications
MultiVul validates the hypothesis that integrating automatically generated NL comments during training can drive code LLMs to superior semantic grounding—extracting and generalizing vulnerability-relevant features that are distributed across code and intent modalities. This moves beyond mere surface code patterns and mitigates overfitting to dataset artifacts. Importantly, the code-only inference paradigm ensures deployment practicality, decoupling the benefits of multimodal training from the limitations of real-world codebase documentation.
The modular use of augmentation and alignment mechanisms points to general applicability for model robustness and transferability in other code intelligence tasks. Future advances may arise from incorporating further modalities (e.g., commit messages, bug reports) and fine-grained, semantic-preserving code transformations.
Conclusion
MultiVul demonstrates that automatic multimodal supervision during training—via generated code comments and explicit alignment/consistency objectives—significantly strengthens LLM-based software vulnerability detection. The framework achieves state-of-the-art performance in both effectiveness and OOD robustness, while maintaining deployment-zero-overhead inference. The systematic component analysis reflects best practices in robust representation learning, and the findings motivate further research in leveraging multimodality and carefully curated augmentations for practical source code analysis.
Cited Paper:
"Learning Generalizable Multimodal Representations for Software Vulnerability Detection" (2604.25711)