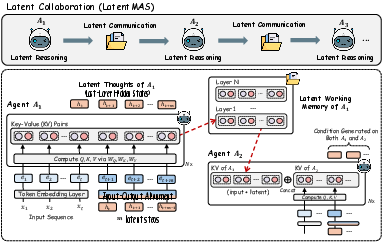
Latent Collaboration in Multi-Agent Systems
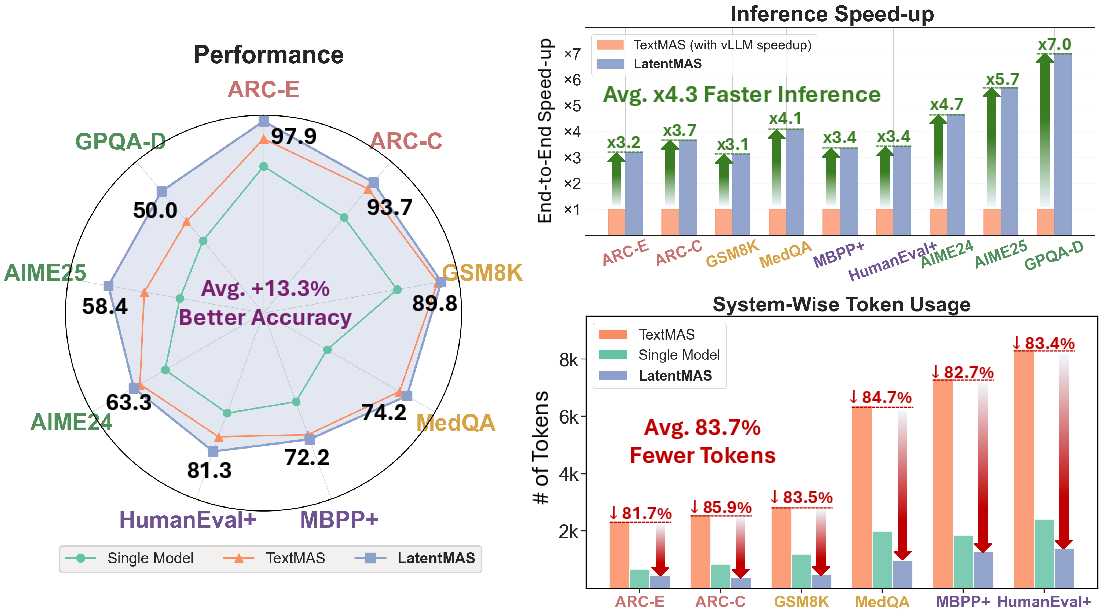
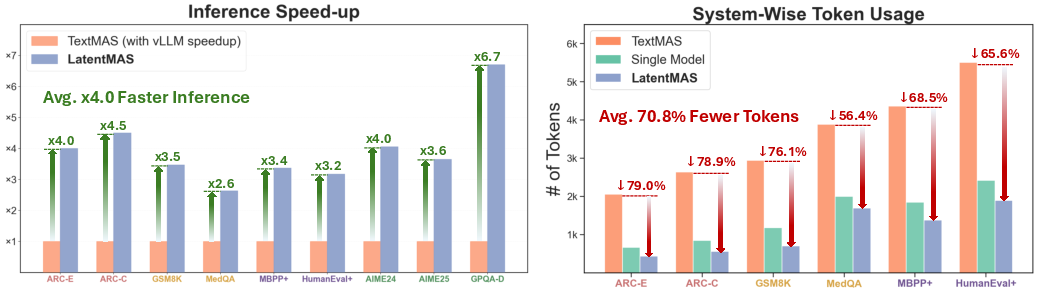
Abstract: Multi-agent systems (MAS) extend LLMs from independent single-model reasoning to coordinative system-level intelligence. While existing LLM agents depend on text-based mediation for reasoning and communication, we take a step forward by enabling models to collaborate directly within the continuous latent space. We introduce LatentMAS, an end-to-end training-free framework that enables pure latent collaboration among LLM agents. In LatentMAS, each agent first performs auto-regressive latent thoughts generation through last-layer hidden embeddings. A shared latent working memory then preserves and transfers each agent's internal representations, ensuring lossless information exchange. We provide theoretical analyses establishing that LatentMAS attains higher expressiveness and lossless information preservation with substantially lower complexity than vanilla text-based MAS. In addition, empirical evaluations across 9 comprehensive benchmarks spanning math and science reasoning, commonsense understanding, and code generation show that LatentMAS consistently outperforms strong single-model and text-based MAS baselines, achieving up to 14.6% higher accuracy, reducing output token usage by 70.8%-83.7%, and providing 4x-4.3x faster end-to-end inference. These results demonstrate that our new latent collaboration framework enhances system-level reasoning quality while offering substantial efficiency gains without any additional training. Code and data are fully open-sourced at https://github.com/Gen-Verse/LatentMAS.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for multiple AI models (called “agents”) to work together. Instead of talking to each other using text (like messages), the agents share their “thoughts” directly inside the model’s hidden space, called the latent space. The system they built is called LatentMAS. It aims to make teamwork between AI models smarter, faster, and more efficient.
What questions did the researchers ask?
They explored three simple questions:
- Can AI agents collaborate using their internal “thoughts” without turning them into words?
- If they share thoughts directly, does any information get lost?
- Is this faster and more powerful than the usual text-based communication between AI agents?
How did they do it?
The authors designed LatentMAS so agents think and collaborate entirely in the model’s hidden space, then only convert the final answer into text.
Thinking in “latent space”
- A LLM has many layers. When it reads text, each token (like a word piece) becomes a vector (a list of numbers) that flows through these layers.
- The “last-layer hidden state” is like the model’s current thought. Normally, the model turns this into a word. In LatentMAS, instead of turning it into a word, the model feeds this “thought” straight back in to keep thinking. This is called auto-regressive latent generation: step-by-step thinking in numbers rather than in words.
Imagine you’re solving a math problem and keep jotting down ideas on a scratchpad. LatentMAS keeps the ideas inside the model as precise “brain signals,” instead of saying them out loud as text.
Sharing a “working memory” between agents
- Modern LLMs store what they’ve seen and thought in something called a KV cache (Key-Value cache). Think of it as a shared notebook that records everything important so far.
- In LatentMAS, one agent finishes thinking and passes its KV cache directly to the next agent. This includes the original input and the new latent thoughts. The next agent continues from there, like inheriting a complete notebook—no retyping, no summarizing.
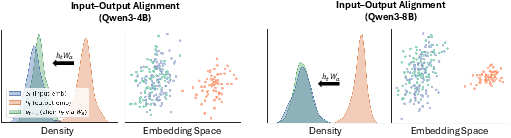
Keeping signals in a safe range (alignment)
- The model’s output thoughts and its input signals don’t always look the same. If you feed the raw output back in, the model could get confused (like plugging a device that needs 110V into a 220V socket).
- To fix this safely without retraining, they added a small adapter (a simple matrix called W_a) that maps each “thought” into a form that looks like a normal input. This keeps the model stable and avoids drifting off into weird states.
Why is this efficient?
- Words (tokens) are limited symbols, but latent thoughts are rich, high-dimensional vectors. One “latent step” can carry much more information than one word.
- They provide theory showing:
- Latent thoughts can be far more expressive than text tokens.
- Passing the KV cache can preserve information “losslessly,” meaning it’s as good as passing the full output—but faster and cheaper.
- Latent collaboration needs less computation than text-based collaboration to reach the same level of reasoning power.
What did they find?
Across nine benchmarks (math, science, commonsense, and code) and different team structures (sequential pipelines and expert hierarchies), LatentMAS:
- Improved accuracy by up to 14.6% compared to strong baselines.
- Reduced the number of generated tokens by roughly 70.8%–83.7%, because agents mostly think in latent space and only decode the final answer.
- Ran 4×–4.3× faster end-to-end, even compared to optimized text-based systems.
They also showed:
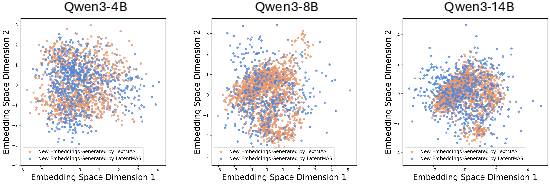
- Latent thoughts cover the same “meaning space” as the tokens that would have been generated, and even include richer variations—so they’re meaningful, not random.
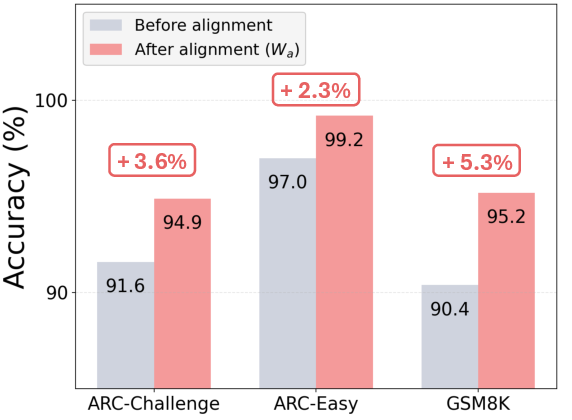
- The alignment adapter (W_a) helps keep the model stable and improves accuracy.
- The method works without extra training and with different model sizes (4B, 8B, 14B).
Why does this matter?
LatentMAS shows that AI agents can collaborate more like humans do internally—sharing full context and rich ideas—rather than constantly translating thoughts into words. This could make:
- Smarter teamwork: AI experts (like math, science, and code agents) can hand over complete, detailed internal reasoning to each other.
- Faster and cheaper systems: Fewer tokens and less computation means lower cost and quicker responses.
- Better performance in tough tasks: The richer “thoughts” help with complex reasoning problems where text chains get long and messy.
In the future, this kind of collaboration could help build more capable AI teams for tutoring, coding assistants, scientific research, and even robots—where quick, precise, and coordinated thinking beats slow, wordy back-and-forth.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that future work could address to strengthen, generalize, and operationalize LatentMAS.
- Cross-model heterogeneity: The latent working-memory transfer assumes agents with compatible architectures (e.g., same hidden dimension, attention setup, RoPE scale, layer count). It is unclear how to transfer KV caches and hidden states across heterogeneous models (different families, sizes, vocabularies, or positional encodings). Define and evaluate cross-model alignment operators/adapters for KV and hidden states.
- Positional encoding and masking during KV transfer: The paper does not specify how positional indices, attention masks, and RoPE/ALiBi phases are handled when concatenating another agent’s KV caches. Provide a rigorous treatment and empirical validation of position renumbering, masking, and rotary phases to guarantee fidelity and stability.
- Validity of theoretical assumptions: Expressiveness and information-preservation theorems rely on the Linear Representation Hypothesis and implicit architectural equivalences. Characterize conditions under which these assumptions hold for modern transformer non-linearities (residual connections, layer norms, saturation) and quantify empirical failure modes.
- Lossless transfer claim boundary conditions: Theorem-level “lossless” equivalence appears to assume identical architectures/parameters across agents and exact numerical operations. Assess effects of floating-point precision, kernel implementations (e.g., FlashAttention), normalization states, dropout config, and minor model mismatches on output equivalence.
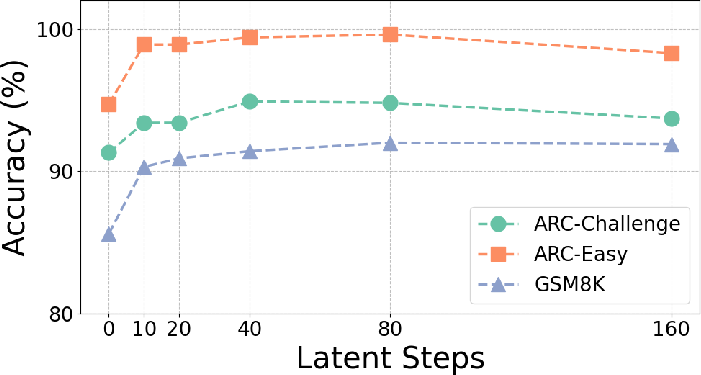
- Stability over long latent chains: Results show alignment mitigates drift, but maximum stable latent step depth m, drift accumulation dynamics, and saturation are not characterized. Provide bounds/diagnostics for drift, and adaptive halting criteria that maintain accuracy under very long latent sequences.
- Dynamic collaboration control: The system uses fixed pipelines and preset latent step counts. Develop policies to adaptively allocate latent steps per agent, decide agent ordering, and terminate collaboration based on confidence/utility signals learned or estimated at inference time.
- Safety, privacy, and robustness: Latent working memory may encode sensitive user data. Evaluate privacy leakage risk, propose encryption/access control for KV caches, test adversarial latent injection and poisoning defenses, and develop interpretable audit tools for latent thoughts.
- Interpretability and oversight: Beyond t-SNE projections, there is no mechanism to decode, summarize, or explain latent thoughts for human review. Design interfaces to translate latent representations into interpretable artifacts or confidence/critique signals for oversight and debugging.
- Tool-use and external API integration: Pure latent collaboration defers decoding until the final answer, limiting mid-pipeline interaction with tools (search, calculators, code execution). Define protocols for hybrid latent–text collaboration that enable tool calls and intermediate verifications without forfeiting efficiency.
- Scalability in memory and distributed systems: Layer-wise KV caches grow with latent steps and number of agents. Quantify memory/network overhead in multi-GPU/multi-node setups, and explore compression, truncation, summarization, or selective layer transfer strategies that preserve utility.
- Compatibility with API-only models: LatentMAS requires internal access to KV caches and hidden states; closed APIs (e.g., proprietary LLMs) do not expose these. Investigate proxy strategies (e.g., lightweight adapters, distillation, or “latent gateways”) that enable partial latent collaboration with black-box models.
- Evaluation breadth: Benchmarks exclude multimodal tasks, embodied/robotics settings, retrieval-augmented long-context QA, dialog, and tool-use-heavy workflows. Extend evaluation to these regimes to test generality and identify domain-specific constraints.
- Metrics beyond accuracy/speed/tokens: The study omits calibration, factuality/hallucination rates, robustness to perturbations, consistency across runs, and error localization metrics. Incorporate these to understand quality trade-offs and failure profiles in latent collaboration.
- Failure case analysis: Some tasks show accuracy declines compared to TextMAS. Provide systematic analyses linking failures to latent step depth, alignment quality, task type, or agent roles, and propose mitigation strategies.
- Alignment operator design (Wa): The linear ridge-regression mapping is computed once per run. Investigate learned/nonlinear alignment, per-layer/per-head mappings, conditioning on position/context, and sensitivity to hyperparameters (e.g., λ). Report computational costs for large d_h (e.g., 30B+ models) and efficiency/accuracy trade-offs.
- Per-layer vs last-layer latents: LatentMAS uses last-layer hidden states for generation. Evaluate whether using intermediate layers or multi-layer fusion improves stability/expressiveness, and when deeper layers harm or help downstream accuracy.
- Cross-agent semantic alignment: Even with the same model family, agents may diverge semantically (domain specialization, varying prompts). Develop shared latent protocols or learned alignment spaces to guarantee semantic coherence of transferred working memory across agents and domains.
- Quantization/pruning/low-precision effects: Many deployments use int8/int4 quantization, pruning, and tensor parallelism. Measure how these affect latent expressiveness, KV transfer fidelity, and the validity of theoretical guarantees.
- Error correction and disagreement handling: Without mid-pipeline text, it is unclear how agents surface disagreements or request clarifications. Create latent “signals” (e.g., confidence vectors, critique flags) and arbitration mechanisms to resolve conflicts during collaboration.
- Final decoding quality and output format constraints: Only the final agent decodes text; tasks requiring intermediate textual artifacts (e.g., step-by-step proofs, code with explanations) may be disadvantaged. Assess fluency/completeness of final decoding and support for intermediate textual outputs when required.
- Hyperparameter selection: There is no principled method for choosing latent steps m per agent or per task. Develop auto-tuning strategies and meta-controllers that balance accuracy, speed, and memory budgets.
- Practical complexity and throughput: Big-O analyses omit constant factors and hardware-specific bottlenecks (memory bandwidth, kernel launch overhead). Provide empirical scaling laws vs d_h, L, m, and N agents on varied hardware and software stacks.
- Benchmarking against latent baselines: Comparisons to related latent methods (e.g., SoftCoT, KV-Comm, cache-based deliberation) are limited. Include head-to-head evaluations and unify interfaces to clarify relative gains and limitations.
- Training opportunities: The framework is training-free; however, joint training or lightweight fine-tuning (e.g., aligning Wa, learning latent protocols, or supervising latent steps) may yield further gains. Explore training objectives and data for improved latent collaboration.
- Concurrency and scheduling: Current design appears sequential/aggregative. Investigate concurrent latent streams, merging strategies, and schedulers for asynchronous collaboration with contention or partial information.
- Retrieval-augmented latent memory: Explore storing and retrieving latent working memory in a vector database for cross-task reuse, long-horizon reasoning, and team memory, with compression and privacy safeguards.
- Position/time semantics across agents: Clarify how chronological ordering is preserved when concatenating caches from different agents and whether “time” semantics degrade in deeper layers. Provide tests and fixes if misalignment occurs.
- Standardization and APIs: There is no standardized interface for latent communication (format, security, versioning). Propose an API/protocol (schemas for KV/hidden transfer, alignment metadata, and governance) to enable broader adoption and reproducibility.
Practical Applications
Immediate Applications
The following bullet points summarize concrete, deployable use cases that can leverage the paper’s training-free latent collaboration framework today, including sector links, potential tools/products/workflows, and key assumptions or dependencies.
- Software engineering (code assistants and DevOps)
- Use case: Multi-agent code generation and review in IDEs (planner → solver → tester → summarizer) using latent working memory to cut token costs and latency while maintaining or improving accuracy (validated on MBPP+ and HumanEval+).
- Products/workflows: “LatentMAS” plugin for VSCode/JetBrains; CI bots that run refactor/test agents under latent collaboration, with only the final patch decoded to text.
- Assumptions/dependencies: Open-weight LLMs with access to last-layer hidden states, KV caches, and input/output embedding matrices; agents sharing compatible hidden dimensions and layer counts (e.g., same model family); integration with HuggingFace/vLLM backends for past_key_values and prefix caching.
- RAG and tool orchestration for enterprise knowledge work
- Use case: Latent planner/critic/synthesizer agents orchestrate retrieval, tool calls, and aggregation without verbose intermediate text, reducing token budgets and speeding up answers for internal QA and analytics.
- Products/workflows: “Latent CoT Orchestrator” SDK; KV Working Memory Bus that brokers layer-wise caches across tool-specific agents; final summarizer decodes only the answer.
- Assumptions/dependencies: Tool-use pipelines already in place; infrastructure capable of routing KV caches between agents; safeguards for tool invocation and error recovery; compatibility across agents’ model internals.
- Customer support triage and escalation
- Use case: Domain-specialized agents (policy, billing, tech) collaborate in latent space and pass a compact working memory to a summarizer for the customer-facing response, reducing latency and API spend.
- Products/workflows: Contact center “latent collaboration mode” with planner/triage/specialist agents; observability dashboards that track cache transfers rather than verbose text logs.
- Assumptions/dependencies: Access to model internals; observability and audit tooling adapted to latent state transfers; fallback to text-based interaction when agents are heterogeneous.
- Education (tutoring for math and science)
- Use case: Multi-expert tutoring agents (math, physics, chemistry) aggregate latent thoughts, improving correctness and response time for problem solving (supported by GSM8K, AIME24/25, GPQA-Diamond results).
- Products/workflows: Classroom and homework assistants with hierarchical latent expert aggregation; mobile apps decoding only final solutions and hints.
- Assumptions/dependencies: Open-weight models deployed on-device or in low-latency edge/cloud; control of prompts/internals; content safeguards for students.
- Healthcare knowledge support (non-diagnostic, informational)
- Use case: Faster medical QA for clinicians and staff using latent collaboration among medical subagents (validated on MedQA), decoding only the final answer to reduce tokens and exposure of intermediate content.
- Products/workflows: Clinical info desk assistant; policy/terminology agents share latent working memory to prevent loss in cross-agent transfer.
- Assumptions/dependencies: Strict human-in-the-loop; non-diagnostic use; compliance logging for latent states; model internals accessible; domain calibration to local terminologies.
- Robotics and embodied systems (near real-time decision pipelines)
- Use case: On-device planner/controller/safety-monitor agents collaborate via KV caches to reduce communication bandwidth and achieve faster control loops than text-based agent pipelines.
- Products/workflows: Embedded agent stacks with a “latent communication bus” for shared working memory; final decoding for commands/events only.
- Assumptions/dependencies: Agents run on compatible on-device models; deterministic latency; memory and compute budgets for cache management; safety cases and fail-safes.
- Cloud inference cost and energy reduction
- Use case: Latent collaboration mode for multi-agent endpoints (sequential or hierarchical) to reduce token generation by 70–80%+ and speed up by 4×+, lowering compute bills and power draw.
- Products/workflows: Cloud platforms exposing a “latent collaboration” flag; scheduling that co-locates agents with shared caches; token-less billing tiers for latent exchange.
- Assumptions/dependencies: Platform control over model internals; enterprise acceptance of latent observability; cache transfer optimized across nodes.
- Privacy-preserving multi-agent collaboration
- Use case: Minimize intermediate text logs and surface only final decoded outputs, reducing potential leakage in the collaboration process.
- Products/workflows: Privacy-by-design agent frameworks that store latent caches ephemerally and redact intermediate states; compliance tools that summarize latent provenance.
- Assumptions/dependencies: Proper policies for latent state retention; secure cache transport/storage; robust redaction and auditing for latent data.
Long-Term Applications
The following bullets highlight opportunities that will likely require further research, standardization, scaling, productization, or policy/regulatory development before wide deployment.
- Cross-model latent interoperability and standards
- Use case: Agents from different vendors collaborate via a standardized “latent language” (KV cache schemas, alignment operators) for plug-and-play multi-agent ecosystems.
- Products/workflows: Latent Interop Protocol and SDK; adapters mapping W_in/W_out/hidden states across models; cross-family cache translators.
- Assumptions/dependencies: Industry standards for cache layout, precision, and layer semantics; vendor cooperation; robust alignment beyond ridge regression (learned or adaptive).
- Secure latent collaboration (guardrails, watermarking, auditability)
- Use case: Safety layers that interpret and gate latent thoughts, detect anomalous cache patterns, apply watermarking to latent traces, and provide audit trails without relying on text intermediates.
- Products/workflows: Latent Safety Gateways; anomaly detection on residual streams; watermarking of cache segments; compliance dashboards for latent provenance.
- Assumptions/dependencies: New metrics and tooling tailored to latent states; regulatory acceptance of non-text auditing; methods to interpret and explain latent content reliably.
- Multi-modal latent collaboration (vision, audio, sensor fusion)
- Use case: Agents exchange latent embeddings across modalities (images, audio, proprioception), sharing working memory for richer perception and reasoning in autonomous systems.
- Products/workflows: Multi-modal KV buses; alignment operators across modality-specific heads; cross-modal summarizers decoding only final outputs.
- Assumptions/dependencies: Access to modality-specific caches; alignment beyond language embeddings; real-time constraints and hardware acceleration.
- Distributed and federated latent collaboration
- Use case: Edge/cloud agents share compressed caches across networks, enabling low-bandwidth cooperative reasoning (e.g., fleet robotics, smart factories, smart homes).
- Products/workflows: Cache compression codecs; streaming protocols for layer-wise KV; federated latent pipelines with privacy guarantees.
- Assumptions/dependencies: Efficient cache compression and transport; bandwidth/latency guarantees; federated security and identity schemes.
- On-device MAS for mobile and IoT
- Use case: Quantized latent pipelines for multi-agent assistants on phones and embedded devices with real-time performance.
- Products/workflows: Hardware-friendly KV memory managers; optimized alignment operators; tiny expert agents with shared caches.
- Assumptions/dependencies: Model quantization/pruning compatible with latent exchange; memory-constrained cache handling; battery-aware scheduling.
- Learned alignment and latent CoT training
- Use case: Train alignment operators or small “bridge” networks to better map last-layer states back to valid input embeddings; fine-tune agents to “speak” a shared latent dialect.
- Products/workflows: Lightweight alignment heads (distilled from W_in/W_out); co-training of multi-agent latent protocols; curriculum for latent CoT consistency.
- Assumptions/dependencies: Labeled or synthetic data for alignment; stability under distribution shifts; generalization across tasks and model scales.
- Domain-certified applications in regulated sectors (healthcare, finance, legal)
- Use case: Clinical decision support, underwriting, and legal drafting with latent collaboration to reduce cost and latency while maintaining fidelity, backed by rigorous validation.
- Products/workflows: End-to-end pipelines with latent experts and audited final decoding; post-hoc explainers that reconstruct textual rationales from latent traces when required.
- Assumptions/dependencies: Extensive validation and monitoring; standards for reconstructing explanations; human oversight; regulatory buy-in for latent-first collaboration.
- Green AI and sustainability policy
- Use case: Policies incentivizing compute-efficient multi-agent designs (latent-first pipelines) that cut energy use and carbon footprint in datacenters.
- Products/workflows: Sustainability reporting for latent vs. text-based agent runs; procurement guidelines for platforms that expose latent collaboration modes.
- Assumptions/dependencies: Accepted measurement frameworks; transparent energy accounting; policy alignment across jurisdictions.
- New developer tooling and observability for latent systems
- Use case: Debuggers and profilers that visualize cache flows, alignment efficacy, and per-layer contributions to final outputs; “agentops” for latent pipelines.
- Products/workflows: Latent Graph Visualizer; cache diffs across agents; performance/accuracy trade-off explorers for latent step depth m; auto-fallback to text when needed.
- Assumptions/dependencies: Rich APIs to inspect caches; standardized logging; evaluation harnesses that correlate latent patterns with downstream accuracy.
- Swarm intelligence and collective reasoning
- Use case: Large MAS swarms exchanging latent working memory for scalable coordination in planning, simulation, and discovery (e.g., materials science, drug design).
- Products/workflows: Hierarchical latent aggregators; memory sharding across sub-swarms; constraint solvers that decode only final plans or designs.
- Assumptions/dependencies: Efficient cache sharding/aggregation; task-specific latent protocols; robust convergence and error containment at scale.
General assumptions and dependencies that affect feasibility
- Access to model internals (KV caches, last-layer hidden states, input/output embedding matrices) is required; black-box API-only models may not be compatible.
- Agent interoperability benefits from shared architecture properties (hidden dimensions, layer counts, attention implementations). Cross-family collaboration currently needs adapters.
- The alignment operator W_a (solved via ridge regression) must be stable across tasks; some benchmarks showed slight accuracy regressions in specific settings, so dynamic gating or fallback to text is prudent.
- Memory footprint and transport of KV caches can be significant; compression and careful scheduling are important in distributed deployments.
- Observability, safety, and compliance in latent space will require new tooling and practices (e.g., watermarking, audit trails, explanation reconstruction).
- Human-in-the-loop and domain guardrails remain essential, especially in regulated sectors (healthcare, finance, legal).
Glossary
- Agentic AI: A paradigm where AI systems act autonomously with coordinated, system-level behaviors. "Model collaboration emerges as the foundation of system-level intelligence in the era of Agentic AI"
- Alignment operator: A linear projection used to map last-layer hidden states back to valid input embeddings without training. "we propose a linear alignment operator"
- Auto-regressive latent thoughts generation: Generating sequences of internal hidden representations step-by-step instead of decoding tokens. "each agent first performs auto-regressive latent thoughts generation through last-layer hidden embeddings"
- Chain-of-agents design: A sequential MAS architecture where specialized agents pass outputs to the next agent in a pipeline. "we adopt a chain-of-agents design"
- Decoder-only Transformers: Transformer models that generate outputs using only decoder blocks, maintaining a cache for past tokens. "In decoder-only Transformers, the Key-Value (KV) cache functions as a dynamic working memory"
- Domain-specialized design: A MAS architecture where multiple agents act as domain experts and are aggregated hierarchically. "we adopt a domain-specialized design"
- Expressiveness of Latent Thoughts: The theoretical capacity of latent representations to encode richer information than discrete tokens. "Expressiveness of Latent Thoughts"
- Hierarchical aggregation: The process of combining multiple agents’ intermediate reasoning into a synthesized final answer. "performs hierarchical aggregation to synthesize and refine the final answer"
- Hierarchical MAS: A multi-agent architecture where domain experts independently reason and a summarizer aggregates their outputs. "under the Hierarchical MAS setting"
- HuggingFace Transformers: A software framework used to access LLM features such as KV caches during inference. "through the past_key_values interface in HuggingFace Transformers"
- Input-Output Distribution Alignment: A technique to align generated hidden states with the statistical structure of input embeddings. "Input-Output Distribution Alignment"
- Key-Value (KV) cache: Layer-wise memory storing attention keys and values from previous steps to avoid recomputation. "Key-Value (KV) cache functions as a dynamic working memory"
- LLM head: The output layer mapping hidden states to vocabulary logits for token prediction. "LLM head that maps the hidden representation to the vocabulary space"
- Latent chain-of-thought (CoT) reasoning: Internal, continuous sequences of reasoning encoded in hidden states rather than text. "latent chain-of-thought (CoT) reasoning"
- Latent collaboration: Coordination among agents entirely via latent representations instead of text. "latent collaboration not only enhances system-level reasoning quality"
- Latent thoughts: Continuous hidden representations generated auto-regressively that capture an agent’s internal reasoning. "We define the continuous output representations H as the latent thoughts"
- Latent working memory: The collection of an agent’s layer-wise KV caches encapsulating input context and generated latent thoughts. "We define its latent working memory as:"
- Linear Representation Hypothesis: An assumption that latent hidden states linearly encode semantic structures used in the expressiveness analysis. "Under the Linear Representation Hypothesis on h"
- past_key_values: An inference API to pass and concatenate KV caches across steps or agents. "through the past_key_values interface"
- Prefix caching: Caching and reusing computations for shared input prefixes to speed up generation. "enabling prefix caching and tensor-parallel inference"
- Pseudo-inverse: A generalized matrix inverse used to compute the alignment projection when matrices are non-square. "the pseudo-inverse"
- Residual stream: The sequence of intermediate representations combined via residual connections across Transformer layers. "through the model's residual stream"
- Ridge regression: A regularized linear regression used to solve for the alignment matrix efficiently. "by solving a ridge regression"
- Tensor-parallel inference: Parallelizing model tensors across devices to accelerate large-model inference. "enabling prefix caching and tensor-parallel inference"
- vLLM backend: An inference engine optimizing LLM serving via efficient caching and parallelization. "with the vLLM backend"
- Working memory transfer: Passing one agent’s latent working memory to another to enable lossless, layer-wise conditioning. "latent working memory transfer mechanism"
Collections
Sign up for free to add this paper to one or more collections.