Investigation into In-Context Learning Capabilities of Transformers
Published 28 Apr 2026 in cs.LG and cs.AI | (2604.25858v1)
Abstract: Transformers have demonstrated a strong ability for in-context learning (ICL), enabling models to solve previously unseen tasks using only example input output pairs provided at inference time. While prior theoretical work has established conditions under which transformers can perform linear classification in-context, the empirical scaling behavior governing when this mechanism succeeds remains insufficiently characterized. In this paper, we conduct a systematic empirical study of in-context learning for Gaussian-mixture binary classification tasks. Building on the theoretical framework of Frei and Vardi (2024), we analyze how in-context test accuracy depends on three fundamental factors: the input dimension, the number of in-context examples, and the number of pre-training tasks. Using a controlled synthetic setup and a linear in-context classifier formulation, we isolate the geometric conditions under which models successfully infer task structure from context alone. We additionally investigate the emergence of benign overfitting, where models memorize noisy in-context labels while still achieving strong generalization performance on clean test data. Through extensive sweeps across dimensionality, sequence length, task diversity, and signal-to-noise regimes, we identify the parameter regions in which this phenomenon arises and characterize how it depends on data geometry and training exposure. Our results provide a comprehensive empirical map of scaling behavior in in-context classification, highlighting the critical role of dimensionality, signal strength, and contextual information in determining when in-context learning succeeds and when it fails.
The paper presents an empirical characterization of in-context learning geometry in transformers using synthetic Gaussian mixtures.
It systematically varies feature dimensions, context lengths, and task diversity to uncover critical parameter interactions and the emergence of benign overfitting.
The findings demonstrate that effective SNR scaling is vital for overcoming noise and achieving robust generalization despite heavy label corruption.
Empirical Characterization of In-Context Learning in Transformers
Introduction
This work presents an extensive empirical investigation into the geometric and scaling laws that govern in-context learning (ICL) capabilities of transformers, with a focus on linear classification tasks rooted in Gaussian mixture models. Building on prior theoretical frameworks, notably those by Frei and Vardi (Frei et al., 2024), the study systematically explores how in-context generalization emerges as a function of input dimensionality, context size, task diversity, and signal-to-noise ratio (SNR). The paper provides new evidence on the manifestation and boundaries of benign overfitting in transformer models, and contrasts linear theoretical results with the empirical behavior of full-scale, commercially deployed transformer architectures.
Experimental Framework
Task Formulation and Model
The study employs synthetic binary classification tasks where each task instance is described by a randomly sampled class vector and i.i.d. Gaussian noise, yielding a controlled, analytically tractable environment. The key architectural object of analysis is a linear in-context classifier:
The model computes the label-weighted empirical mean of context vectors and projects the query point via a learned matrix W, encapsulating task inference in a geometric manner.
Training proceeds with logistic loss over large batches of independent tasks, ensuring high statistical stability and control over inductive biases.
Context Length (N): Number of labeled in-context examples per task.
Task Diversity (B): Number of distinct tasks per training iteration.
Signal Magnitude (R): Either fixed or scaled with dimension to manipulate SNR.
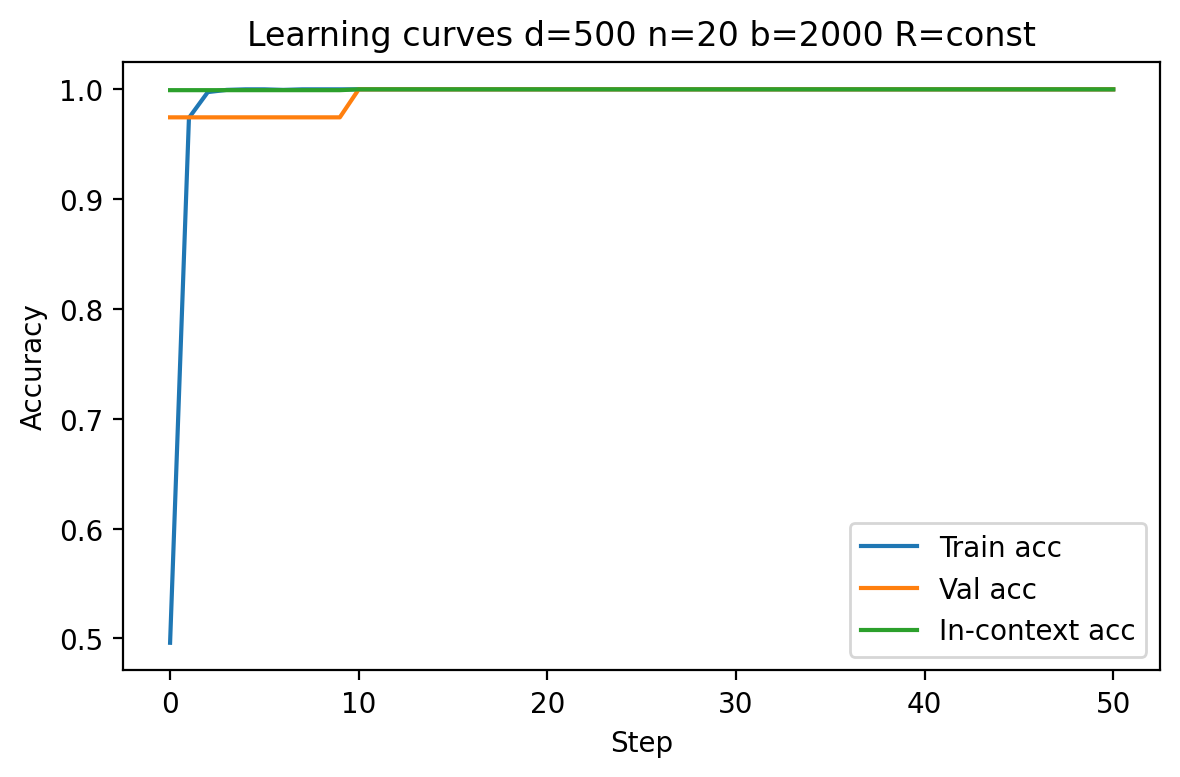
Distinct signal regimes (fixed R and R∝d) are used to decouple the effects of increased feature space from SNR changes.
Results
Influence of Dimensionality and Signal Strength
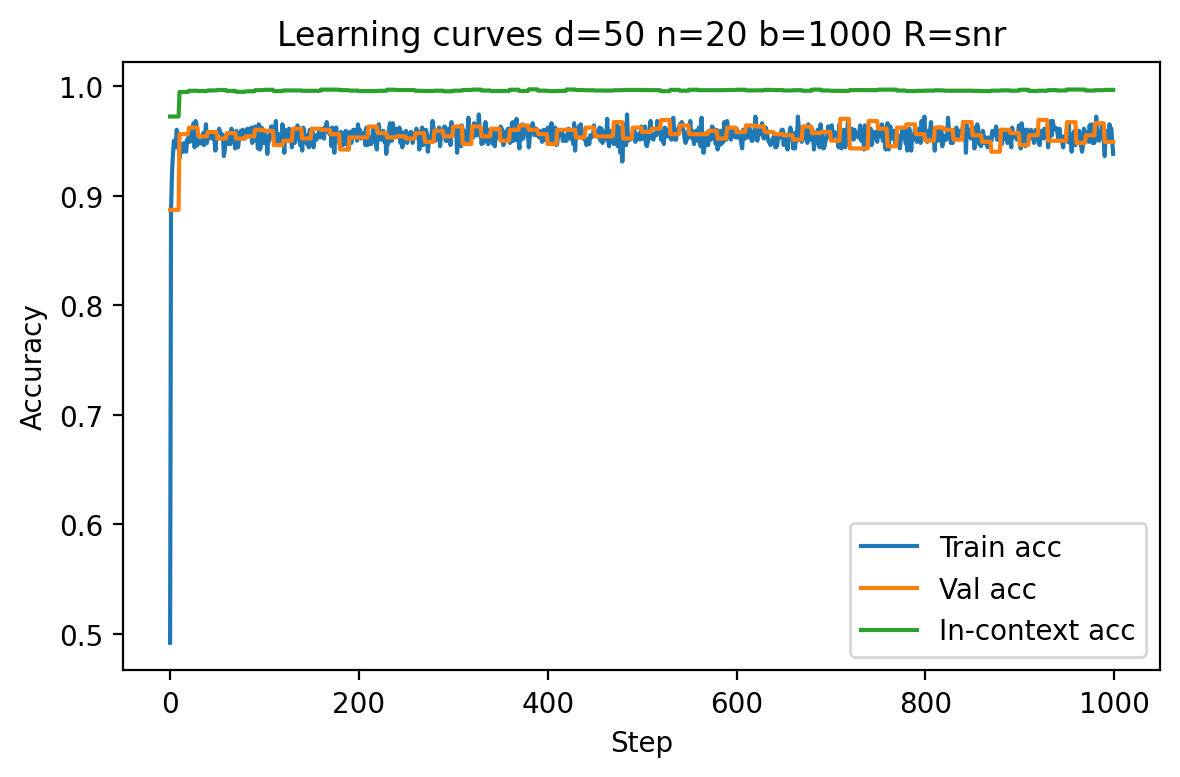
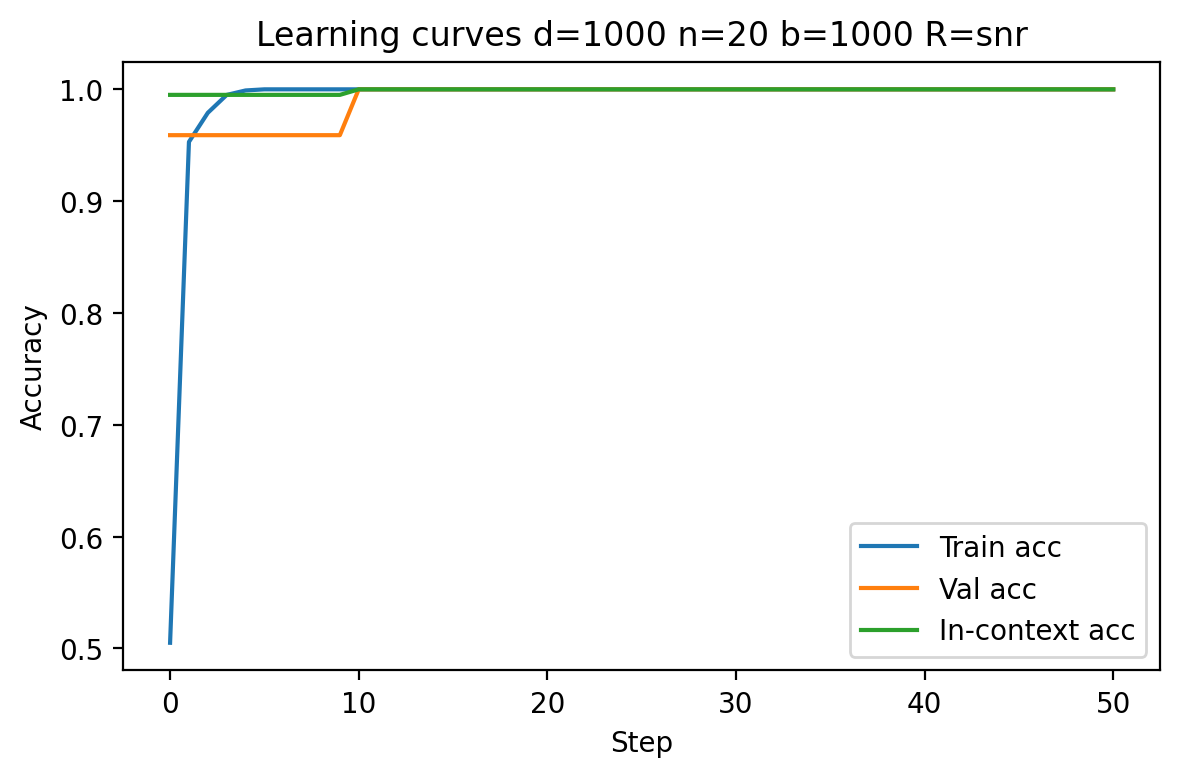
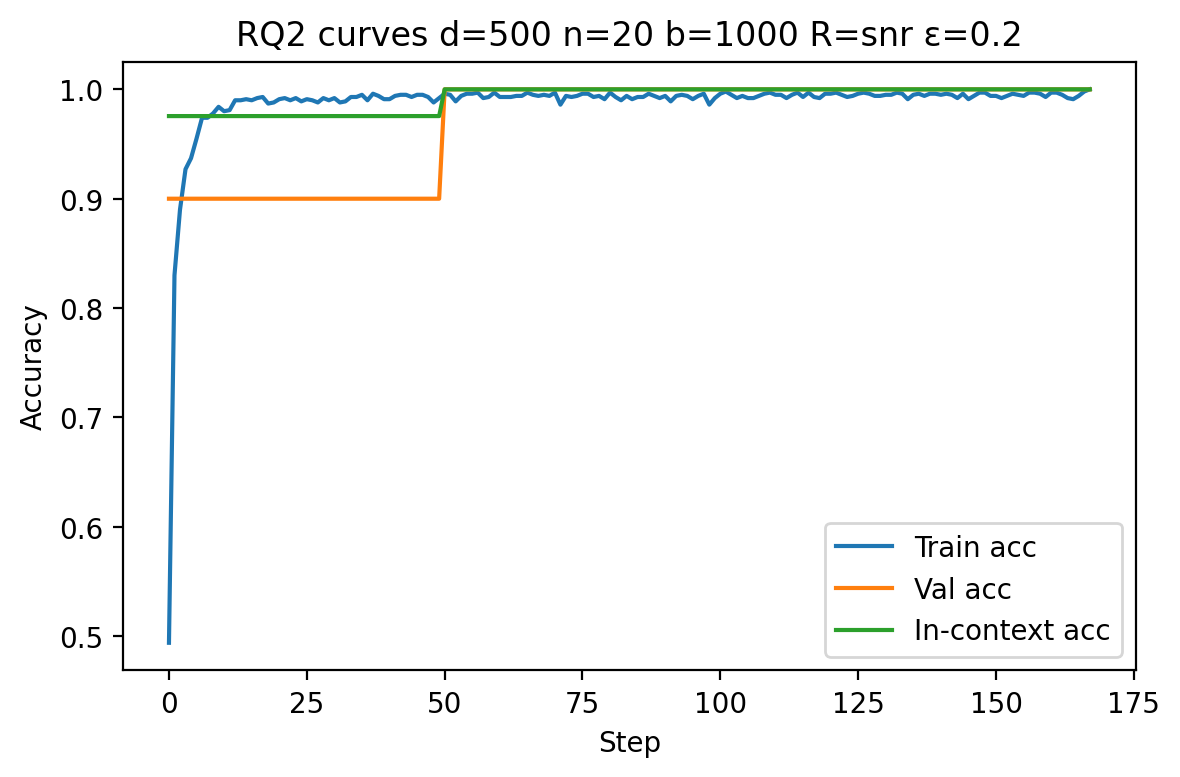
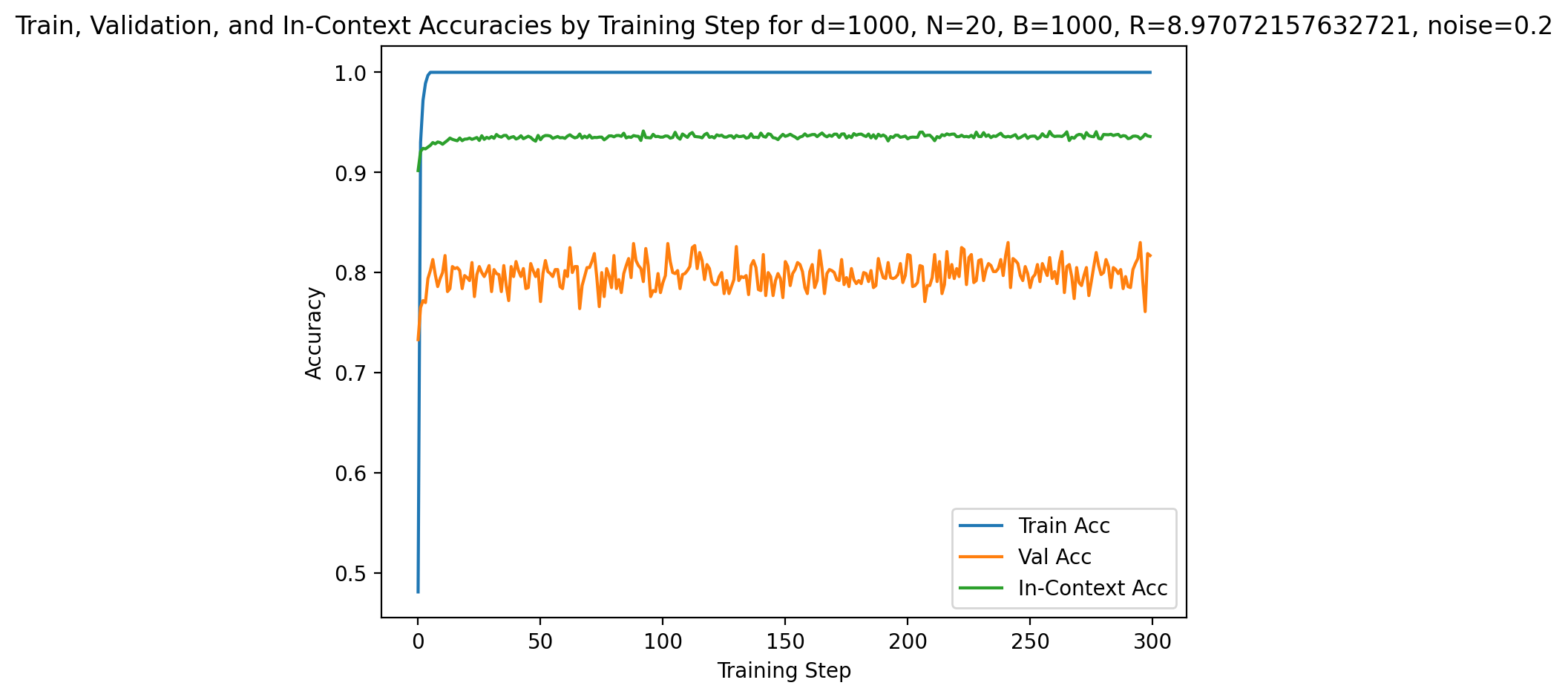
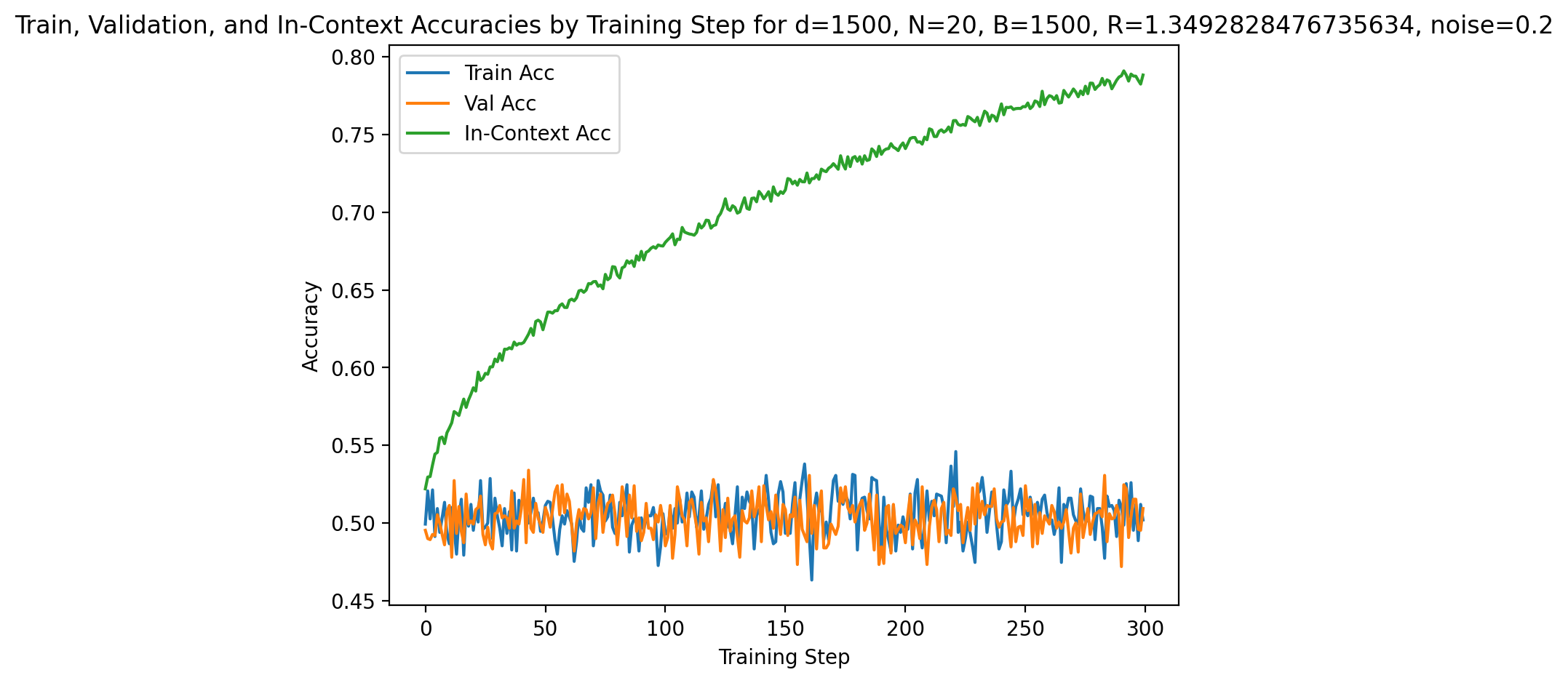
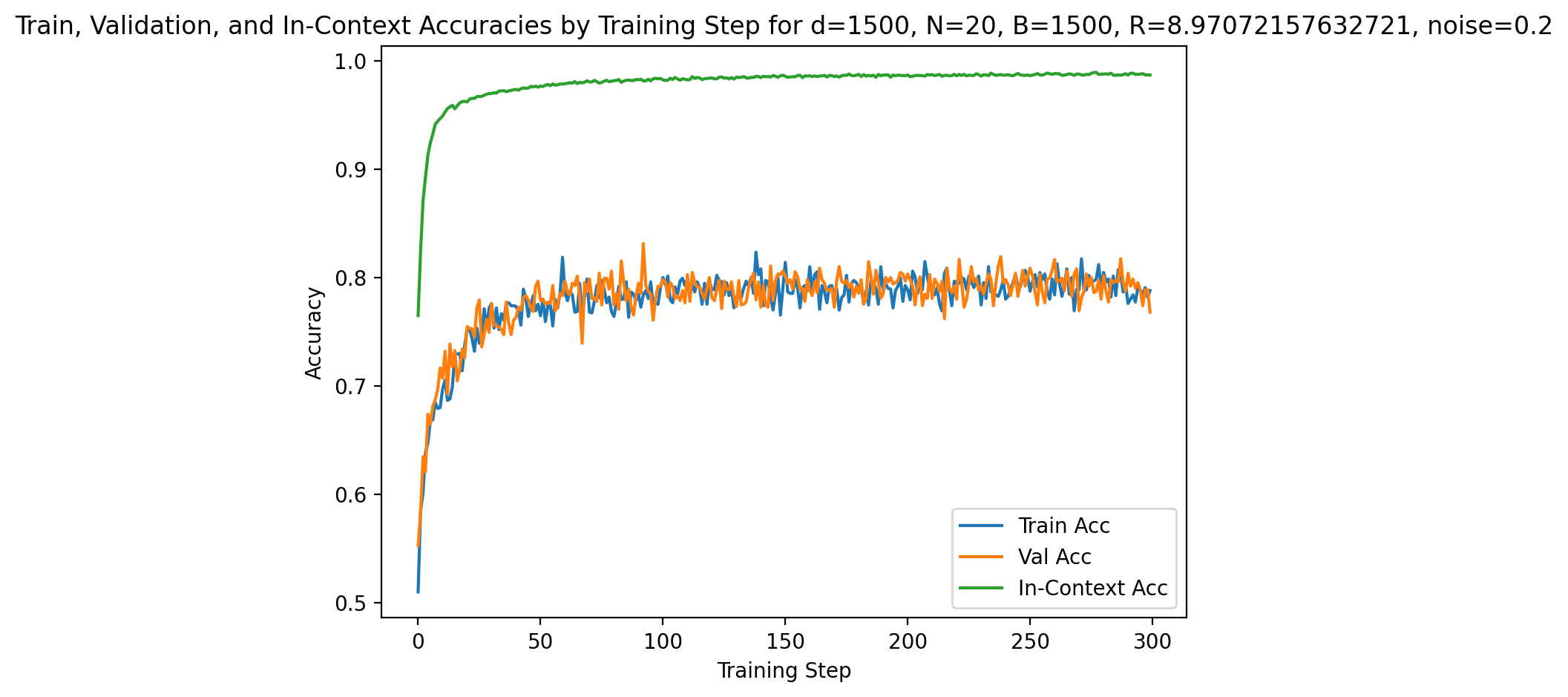
Empirical curves demonstrate that in regimes with fixed R, increasing d slows convergence and may saturate generalization far from optimality due to vanishing SNR. However, when R is scaled with d0, models consistently reach perfect validation and in-context accuracy, regardless of dimension. This is apparent in Figures 1 and 4.
Figure 1: Model performance at low dimension (d1, d2, d3) with SNR scaling; rapid near-optimal generalization is achieved.
Figure 2: Model performance at high dimension (d4, d5, d6) with SNR scaling; signal strength offsets ambient noise, enabling perfect accuracy.
Context Length and Task Diversity
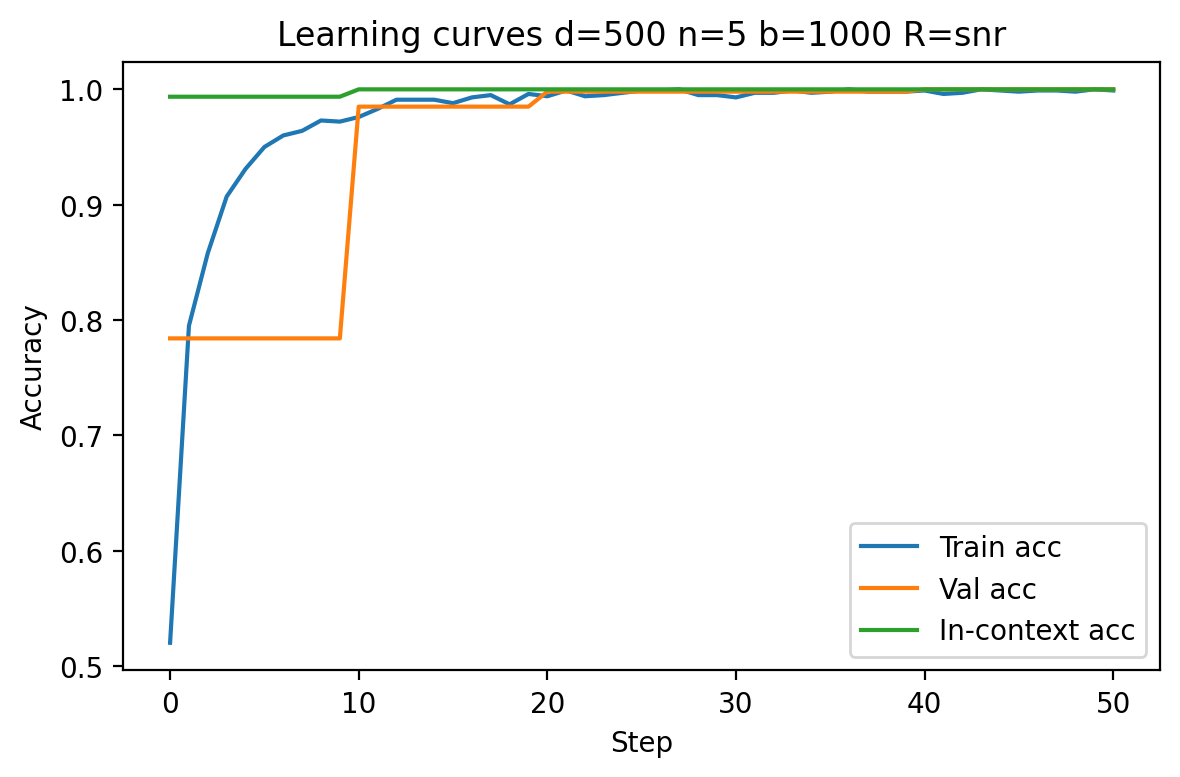
Increasing context size or task diversity systematically boosts both in-context and validation accuracy, with most pronounced effects on generalization (validation accuracy). In low-d7 or low-d8 settings, models show lower initial accuracy and slower convergence, but both metrics saturate to unity with sufficient context/examples (see Figures 6 and 11).
Figure 3: At d9, in-context accuracy is high but generalization lags initially; increasing N0 bridges this gap.
Benign overfitting is probed by systematically injecting label noise into context examples. The phenomenon is observed when in-context accuracy is high despite substantial label corruption, and validation/generalization performance remains robust. This regime arises provided the signal strength is sufficient to offset noise and overparameterization (see Figures 13 and 17).
Figure 5: Benign overfitting at noise N2: model memorizes noisy context but generalizes perfectly on clean queries.
Figure 6: Clear benign overfitting regime—high memorization does not impede generalization.
However, when both context and query labels are noisy, overfitting transitions to classical failure (validation collapses) unless N3 is extremely high (see Figure 7 vs. 20).
Figure 7: Non-benign overfitting—high noise and insufficient signal prevent generalization despite memorization.
Figure 8: Raising signal (N4) reinstates benign overfitting; generalization recovers while memorizing.
Full Transformer Architectures and LLMs
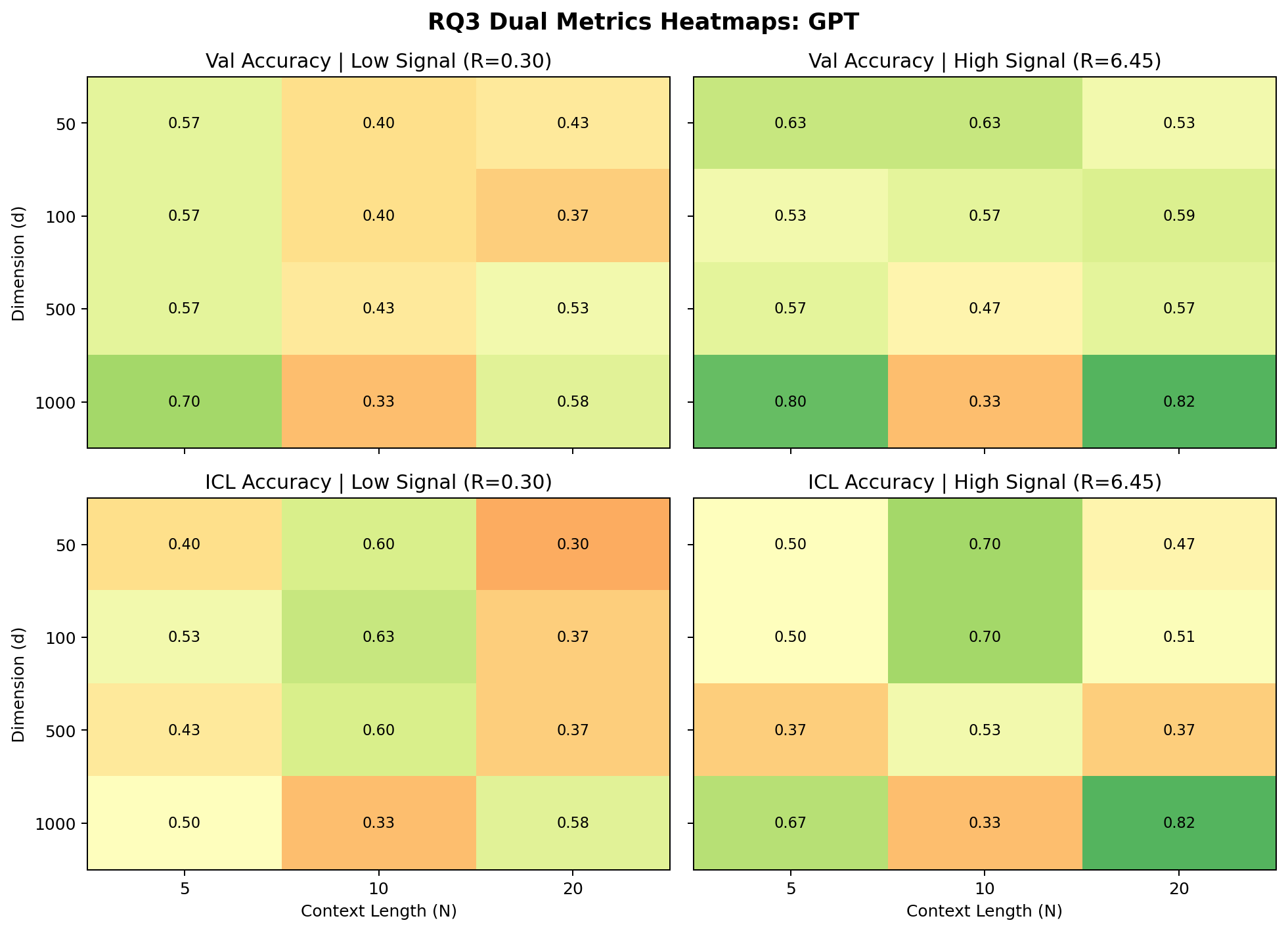
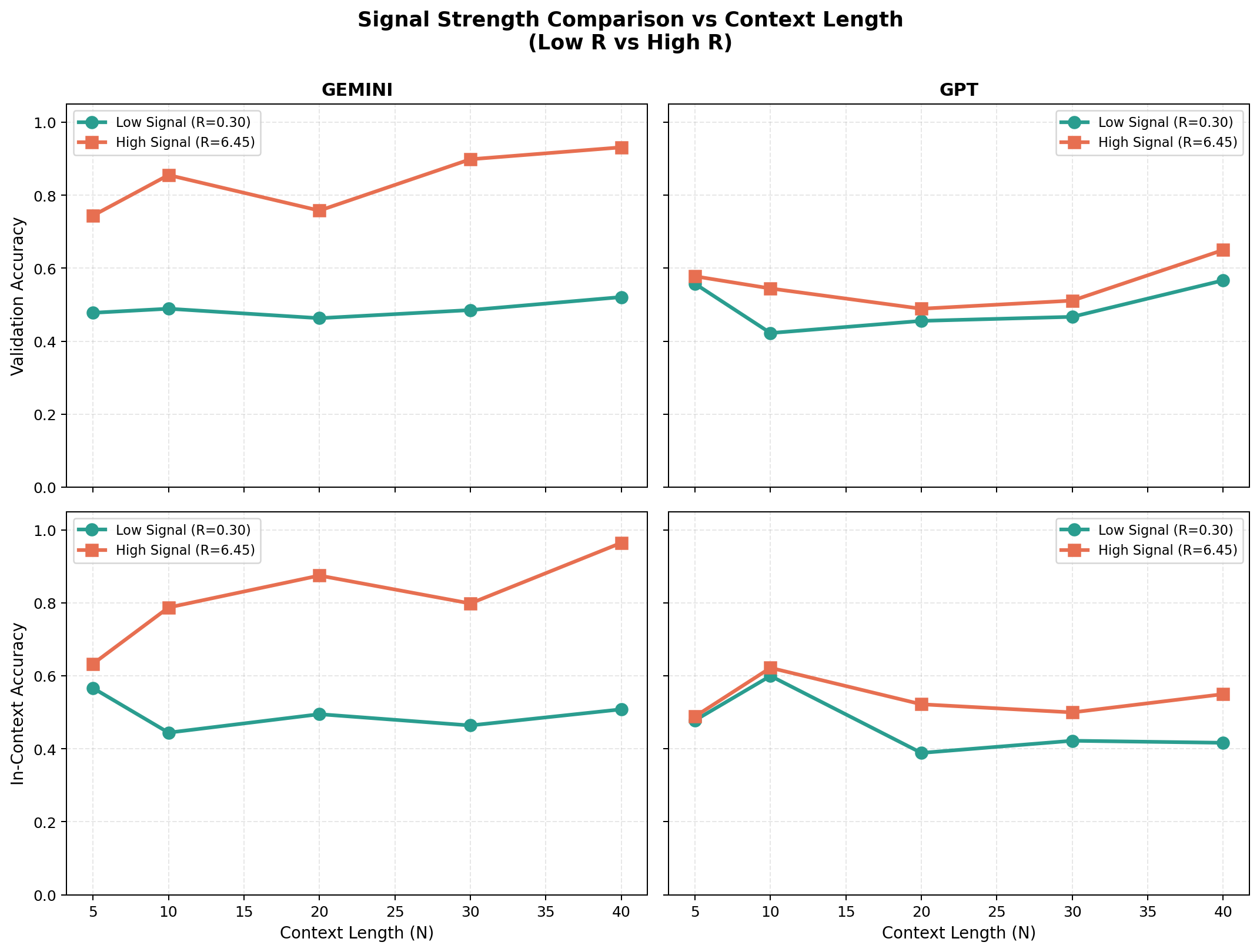
Testing off-the-shelf LLMs (GPT-4-mini, Gemini-2.0-mini) on identically structured tasks reveals that the dichotomy between generalization and memorization persists in these models. Notably, query accuracy is often moderate to high, while in-context (leave-one-out) reconstruction can be substantially lower, indicating asymmetry in task inference and label memorization (see Figures 23 and 25).
Figure 9: ChatGPT-4-mini performance across signal regimes; query and in-context accuracy diverge.
Figure 10: Gemini-2.0-mini, with varying context size, demonstrates similar asymmetry.
Effects of varying dimension and context are configuration-dependent and highlight that there is no universal monotonic improvement direction; interactions between parameters dictate emergent behavior.
SNR scaling is essential: Merely increasing context/examples or model size is insufficient without proportional signal; successful ICL requires balanced geometry.
Benign overfitting can be robust in synthetic, overparameterized regimes—transformers can memorize heavily corrupted context while maintaining out-of-context generalization, provided class-conditional signals are separable.
Generalization-memorization tradeoff: Especially in real-world LLMs, high query prediction need not imply context label reconstruction capability; practitioners must carefully interpret ICL metrics.
Parameter interactions are fundamental: No single hyperparameter dominates; their interplay must be jointly considered when designing ICL systems or scaling to new tasks.
These results refine the empirical landscape for ICL, indicating that future theoretical models should give primacy to geometry and signal scaling, and that practitioners should not expect monotonic gains from context/task scaling absent proper SNR controls.
Conclusion
This study provides a systematic empirical map of ICL generalization in transformers, identifying regime boundaries for generalization and benign overfitting. Key takeaways are that SNR scaling enables high-dimensional generalization, benign overfitting persists in synthetic regimes with sufficient signal, and commercial transformer architectures manifest strong generalization-memorization asymmetries. These findings have practical implications for ML system design and point toward future work integrating geometric analysis with LLM architecture studies.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.