- The paper reveals that VLM-judge uncertainty varies significantly by task, affecting their reliability in scoring.
- Using conformal prediction, VLMs provide interval estimates, indicating task-induced uncertainty remains despite methods employed.
- Findings challenge conventional evaluation metrics, suggesting task-specific approaches for more reliable assessments.
Task-Dependent Uncertainty in Multimodal Evaluation: VLM Judges Can Rank but Cannot Score
Problem Statement and Motivation
Automated evaluation by Vision-LLMs (VLMs) has become standard practice for assessing multimodal AI systems spanning tasks such as chart comprehension, VQA, captioning, and aesthetics assessment. Despite their adoption as "judges" for these tasks, VLMs output only point scores, with no associated reliability measure. This absence is problematic in domains where evaluation ambiguity is compounded by both visual and textual reasoning errors and in safety-critical applications where robust uncertainty quantification is essential. The paper systematically analyzes this reliability gap using conformal prediction (CP) and establishes a principled framework for uncertainty-aware multimodal evaluation.
Methodological Overview
The authors employ conformal prediction, a distribution-free post-hoc calibration technique, to convert point scores from VLM judges into prediction intervals with provable coverage guarantees. CP operates directly on the score-token log-probabilities and does not require retraining of the VLM judge. Multiple CP variants are evaluated, notably R2CCP, which treats regression as classification over fine score grids and is demonstrated to be robust for the task.
Experiments leverage two benchmarks: MLLM-as-a-Judge (14 visual categories; 5,717 samples; single-annotator ground truth) and Polaris (captioning; 8,726 samples; multi-annotator ground truth). Three VLM judges are studied: LLaVA-Critic-7B, Phi-4-reasoning-vision-15B, and Gemini 2.5 Flash, covering both open-source and commercial API-based models.
Empirical Findings: Task-Dependent Uncertainty and Judge Behavior
The central finding is that VLM-judge uncertainty is strongly task-dependent. Interval width, the primary measure of uncertainty, varies by up to 70% across tasks: aesthetics and simple natural image tasks yield tight intervals (~2.08), while vision-heavy and structured reasoning tasks produce wide intervals (~3.50), regardless of judge architecture. The ordering of interval widths across tasks is preserved between judges (Spearman ρ=0.82–0.93).
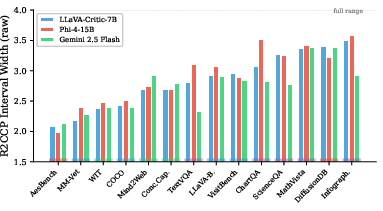
Figure 1: R2CCP interval width across 14 task categories for all three judges; uncertainty is consistent and ordered across judges by task.
A secondary result is the identification of a ranking–scoring decoupling phenomenon: many judges achieve high ranking correlation but fail to assign reliable absolute scores. For example, ChartQA exhibits high Pearson correlation (ρ=0.507) but wide intervals, indicating strong relative ordering with poor score calibration.
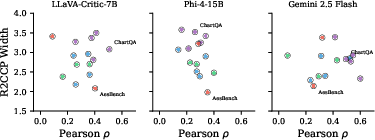
Figure 2: Ranking-scoring decoupling: datasets where judges rank well (high correlation) but intervals are wide, indicating unreliable absolute scoring.
Judge errors are systematically structured: poor responses are consistently overscored (bias up to +1.98 for GT=1) and excellent responses are underscored (bias −1.04 for GT=5), compressing scores toward the mean and inflating uncertainty on ambiguous or visually complex tasks.
Role of Data Quality and Task Structure
The analysis distinguishes the effects of model, method, and data. Results show that interval width is driven largely by task difficulty and annotation quality rather than the conformal method or judge identity. When ground truth is clean and task well-defined (multi-annotator captioning in Polaris), interval width contracts 4.5× (0.68 vs. 3.05), with both achieving 90% coverage.
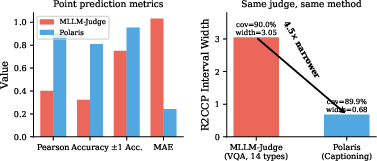
Figure 3: MLLM-Judge vs. Polaris: identical judge and CP method, but interval width is 4.5× narrower on the well-defined captioning task with clean ground truth.
Group-conditional (Mondrian) conformal prediction further improves efficiency, yielding tighter intervals for easy tasks and more robust coverage for hard ones.
Feature fusion (combining logprobs from multiple judges) fails to outperform the single best judge, indicating that logprob discriminative quality supersedes quantity. Model scale is also subordinate to judge specialization: LLaVA-Critic-7B outperforms Phi-4-15B on Polaris despite being smaller, achieving much higher correlation and decisively narrower intervals.
Practical and Theoretical Implications
The findings establish CP interval width as a direct reliability indicator for VLM judge evaluation. Narrow intervals reflect reliable judges suitable for absolute scoring, while wide intervals imply task ambiguity or noisy annotation, recommending rank-based or pairwise comparison evaluation paradigms. Standard metrics (accuracy, correlation) cannot capture these uncertainty dynamics, and reliance on point predictions alone will overstate confidence—particularly in vision-heavy and ambiguous tasks prone to scoring compression and judge bias.
The task-dependent structure of uncertainty suggests new directions for both multimodal evaluation and automated deployment. For safety-critical applications, CP's ability to provide calibrated abstention policies and task-conditional guarantees is promising. From a theoretical perspective, the demonstrated ranking–scoring decoupling challenges evaluation-by-ranks as a universal solution and motivates further research into attainable score calibration in visually structured multimodal systems.
Future developments may focus on task-specific calibration pipelines, improved ground-truth annotation protocols, and deeper integration of uncertainty measures into model selection and system deployment strategies. Extension of this framework to other domains (medical imaging, document analysis) will require targeted validation.
Conclusion
This paper offers a comprehensive quantitative reliability map for VLM-based multimodal evaluation. Uncertainty is chiefly governed by task structure and annotation quality, not model or method. VLM judges exhibit a ranking–scoring decoupling, correctly ordering responses but failing to assign reliable absolute scores on many tasks. Interval width is a direct measure of evaluation reliability; practitioners are advised to interpret narrow intervals as trustworthy and wide intervals as indicative of ambiguity requiring alternative evaluation strategies. Conformal prediction provides a practical, uncertainty-aware mechanism for VLM judge deployment, with principled coverage guarantees and actionable diagnostics for both research and operational decision-making.