- The paper demonstrates that off-the-shelf VLMs exhibit a correctness bias by relying on language priors rather than precise visual cues.
- The study shows that preprocessing methods like cropping and skeleton overlays yield only isolated performance gains in action quality assessment.
- The research highlights significant limitations in prompt engineering, urging the need for domain-adaptive, temporally grounded VLM innovations.
Empirical Evaluation of Vision-LLMs for Action Quality Assessment
Problem Setting and Motivation
Action Quality Assessment (AQA) is critical in domains such as physical therapy, sports training, and competitive judging due to its potential for automated, objective, and real-time evaluation of movement execution. Traditional approaches to AQA have primarily involved specialized deep models and regression-based score prediction, often offering limited interpretability and adaptability. Contemporary interest has shifted toward Vision-LLMs (VLMs) given their prompt-based flexibility, inherent multi-modality, and capacity for explaining assessments via reasoning traces. This paper rigorously investigates whether state-of-the-art VLMs—specifically Gemini 3.1 Pro, Qwen3-VL, and InternVL3.5—can reliably judge action quality across a spectrum of physical activities and tasks without task-specific fine-tuning (2604.08294).
Experimental Design
A diverse suite of datasets is adopted to probe VLM capabilities:
- LLM-FMS: Keyframe-based exercise images with VQA.
- EgoExo-Fitness: Video-based fitness actions with technical guideline verification.
- Fitness-AQA: Gym exercise videos annotated with form errors.
- FineFS: Figure skating clips scored for Grade of Execution (GOE).
- MTL-AQA: Olympic diving videos with judge execution scores.
Tasks cover classification, error detection, guideline-based verification, and regression. Multiple modalities are explored, including RGB frames and skeleton representations, alongside various preprocessing methods.
Model probing is broad: base inference, cropping and keypoint overlays, multi-step reasoning, domain guidelines (positive and negative), and in-context learning (ICL) are exhaustively applied. Systematic analysis of prediction distributions, prompt phrasing effects, and contrastive task formulations expand the probe to VLM biases and failure modes.
Results: Quantitative and Qualitative Assessment
Across classification and regression tasks, VLMs yield marginal improvements over naive baselines (random guess, mean regression). While Gemini 3.1 Pro outperforms others on image-based data, overall results confirm VLMs' inability to reliably ground decisions in visual evidence for fine-grained movement assessment.
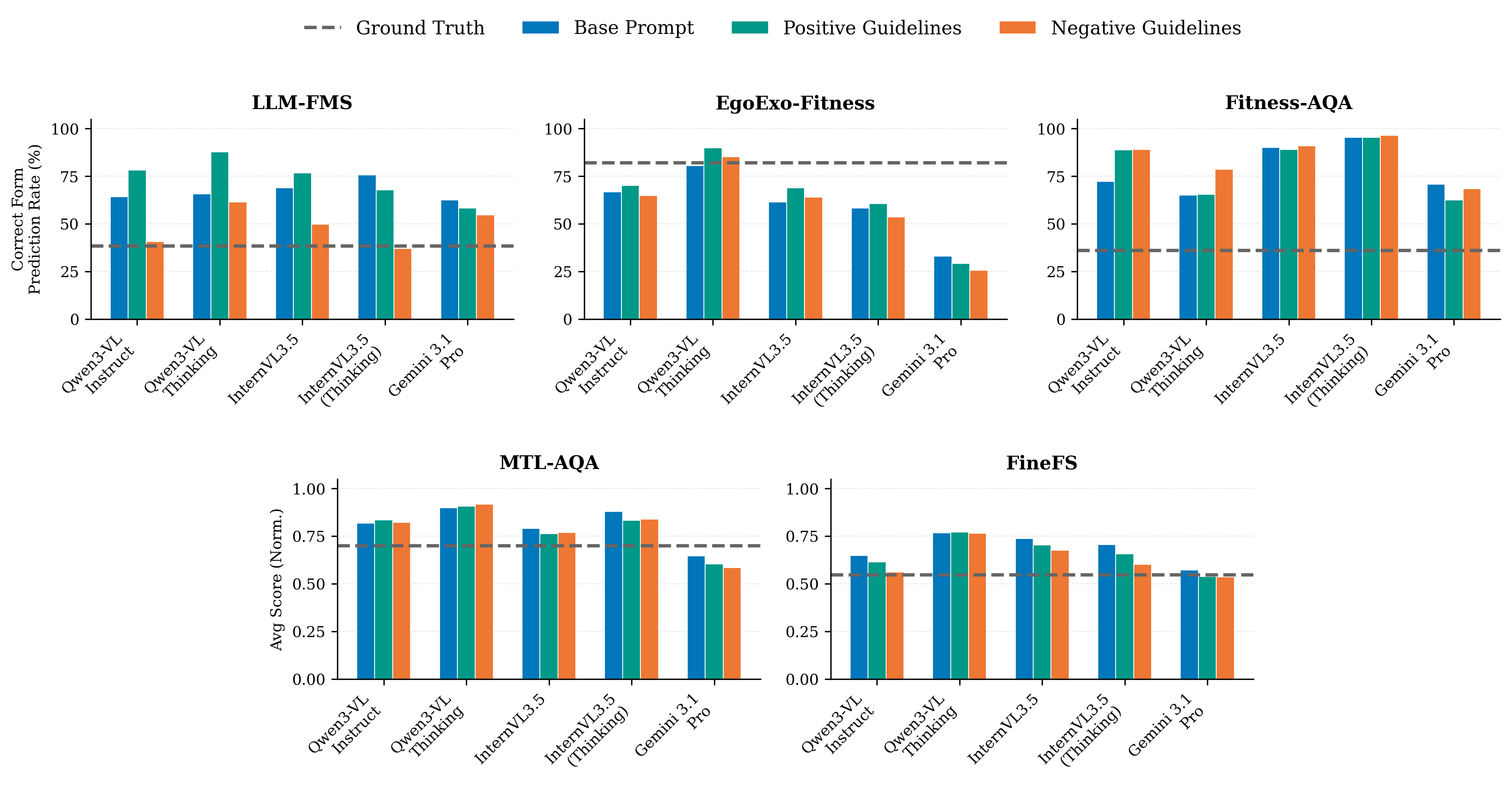
Figure 1: Prompt engineering strategies modulate VLM action quality predictions, but prediction correctness and regression values remain largely insensitive to visual content and are biased towards correct execution.
The inclusion of skeleton overlays and cropping provides isolated performance gains in certain models and tasks but does not generalize. Skeleton-only renders degrade performance in both classification and regression, indicating that VLMs cannot extract temporal and spatial cues necessary for nuanced movement quality assessment from abstract keypoints alone.


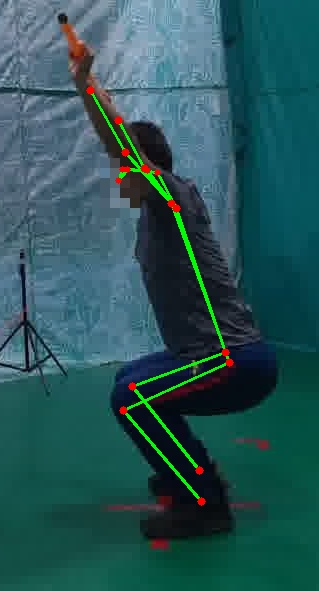
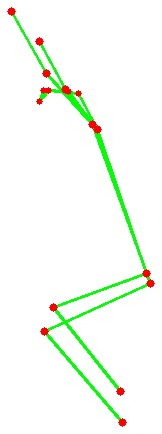
Figure 2: Example preprocessing for LLM-FMS dataset demonstrates impact of visual cropping and keypoint overlays.


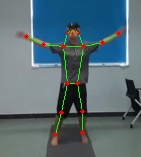
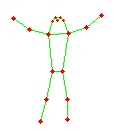
Figure 3: EgoExo-Fitness preprocessing visualizations illustrate skeleton-based enhancement methods applied to video frames.



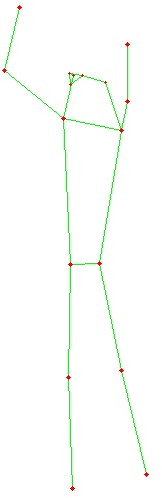
Figure 4: Fitness-AQA preprocessing examples highlight the variance introduced by cropping and skeleton-only rendering.
Prompt Engineering and Systematic Biases
Standard prompt engineering strategies, including reasoning templates, visual grounding cues, and technical guidelines, yield only marginal and inconsistent improvements. Notably, ICL demonstrates moderate gains for regression on image-based AQA but fails on video due to context window limitations.
Two systematic biases are uncovered:
- Correctness Bias: VLMs overwhelmingly predict correct execution regardless of visual evidence, reflective of reliance on language priors versus actual sensory grounding.
- Prompt Sensitivity: Predictions are highly susceptible to superficial linguistic framing; positive and negative guideline variants induce consistent shifts in task outcomes independent of semantic equivalence.
Contrastive task reformulation, designed to neutralize such biases, reveals only modest improvement over random, except for tasks with large execution score gaps, implying that VLMs are only sensitive to macroscopic visual cues and fail on fine-grained comparison.
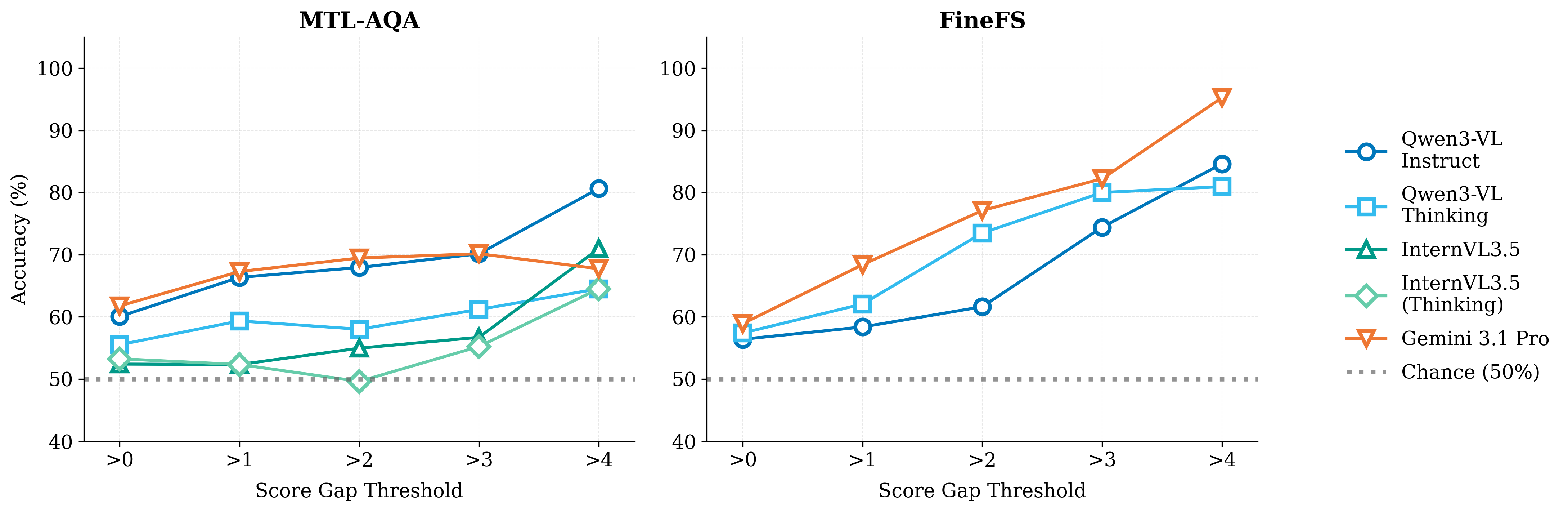
Figure 5: Accuracy on contrastive FineFS and MTL-AQA tasks is monotonically correlated with ground-truth score gap, affirming VLM sensitivity to coarse differences while failing subtle discrimination.
Reasoning Trace Analysis
Inspection of VLM-generated reasoning exposes persistent anchoring in prior domain knowledge. Models default to descriptions of ideal form and exercise execution ("The person is in a squat, so the trunk is likely parallel") rather than detailed visual analysis. This corroborates the correctness bias and the observed lack of visual understanding, limiting the explainability and reliability of generated feedback.
Implications and Future Directions
This work establishes a comprehensive baseline for AQA using VLMs, identifying clear limitations and actionable failure modes. The practical implication is that off-the-shelf VLMs cannot yet be deployed for reliable, automated AQA in real-world environments due to insufficient grounding and susceptibility to linguistic shortcutting.
From a theoretical perspective, these results highlight fundamental challenges at the intersection of vision-language grounding, prompt robustness, and sensorimotor understanding. Future research must address:
- Architectures integrating domain-adaptive visual encoders and temporal dynamics with explicit grounding mechanisms.
- Fine-tuning VLMs on domain-specific movement datasets to combat correctness and prompt sensitivity biases.
- Leveraging skeleton or pose representations in models with hybrid vision-language architectures that can temporally contextualize action execution.
The clear inadequacy of current models for fine-grained AQA raises broader questions regarding VLM versatility outside high-level object and scene recognition, necessitating methodological advances in multimodal learning.
Conclusion
Empirical evaluation demonstrates that general-purpose VLMs are fundamentally unreliable for action quality assessment across classification, error detection, and complex regression tasks. No preprocessing or prompting strategy achieves consistently robust performance. The identified biases—over-reliance on prior knowledge and prompt framing—are intrinsic but not solely responsible for underperformance. Future progress requires methodological innovation in multimodal representation learning and explicit grounding strategies. This work serves as a benchmark for systematically evaluating and advancing VLM-based AQA under real-world constraints.

