Multi-Crit: Benchmarking Multimodal Judges on Pluralistic Criteria-Following
Abstract: Large multimodal models (LMMs) are increasingly adopted as judges in multimodal evaluation systems due to their strong instruction following and consistency with human preferences. However, their ability to follow diverse, fine-grained evaluation criteria remains underexplored. We develop Multi-Crit, a benchmark for evaluating multimodal judges on their capacity to follow pluralistic criteria and produce reliable criterion-level judgments. Covering both open-ended generation and verifiable reasoning tasks, Multi-Crit is built through a rigorous data curation pipeline that gathers challenging response pairs with multi-criterion human annotations. It further introduces three novel metrics for systematically assessing pluralistic adherence, criterion-switching flexibility, and the ability to recognize criterion-level preference conflicts. Comprehensive analysis of 25 LMMs reveals that 1) proprietary models still struggle to maintain consistent adherence to pluralistic criteria--especially in open-ended evaluation; 2) open-source models lag further behind in flexibly following diverse criteria; and 3) critic fine-tuning with holistic judgment signals enhances visual grounding but fails to generalize to pluralistic criterion-level judgment. Additional analyses on reasoning fine-tuning, test-time scaling, and boundary consistency between open-source and proprietary models further probe the limits of current multimodal judges. As a pioneering study, Multi-Crit lays the foundation for building reliable and steerable multimodal AI evaluation.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI “judges” to grade answers more like careful, fair humans. These judges are large multimodal models (LMMs) that can look at images and read text, then decide which of two AI answers is better. The big idea: instead of scoring with just one overall opinion, judges should follow several different rules (criteria) at the same time—like a talent show judge scoring for accuracy, creativity, and clarity separately. The authors build a new benchmark, called Multi-Crit, to test whether AI judges can follow multiple criteria, notice trade-offs between them, and handle situations where the criteria disagree.
What questions did the paper ask?
The paper focuses on two simple questions:
- Can AI judges follow different judging rules (criteria) at once, not just give one overall score?
- Can they spot and correctly handle trade-offs—for example, when one answer is more logical but the other is more creative?
How did they do it?
Think of a science fair with judges. Each project is scored for several things: scientific reasoning, clarity, originality, and presentation. Now imagine those judges are AIs who look at pictures and read answers.
Here’s the approach the authors used, explained in everyday terms:
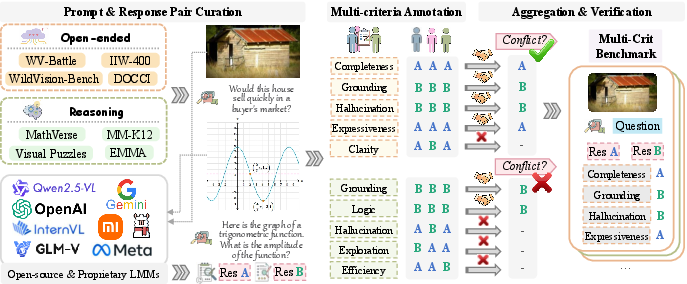
Building the test set (the “fair”)
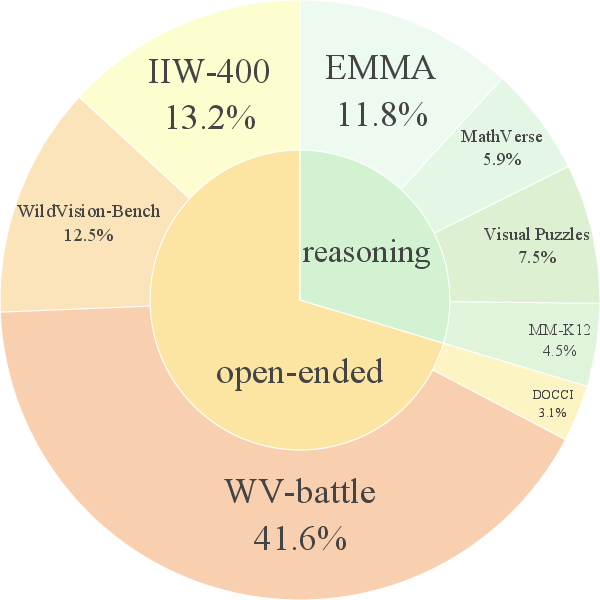
- Two types of tasks:
- Open-ended tasks: free-form answers like describing an image or writing a caption. These are subjective and creative.
- Verifiable reasoning tasks: puzzle-like problems (math, STEM, visual puzzles) where parts of the reasoning can be checked.
- They collected many image-and-question pairs, then generated two different answers for each pair using strong AI models.
Picking challenging examples (hard calls for judges)
- They filtered out easy cases, like when one answer is much longer or when one answer is simply correct and the other is wrong in reasoning tasks.
- They kept the tricky pairs where even top models didn’t all agree, so judging requires careful attention to the criteria.
Getting human judgments by criterion (how real judges work)
- Human experts graded each answer pair on several criteria, one criterion at a time, and explained why.
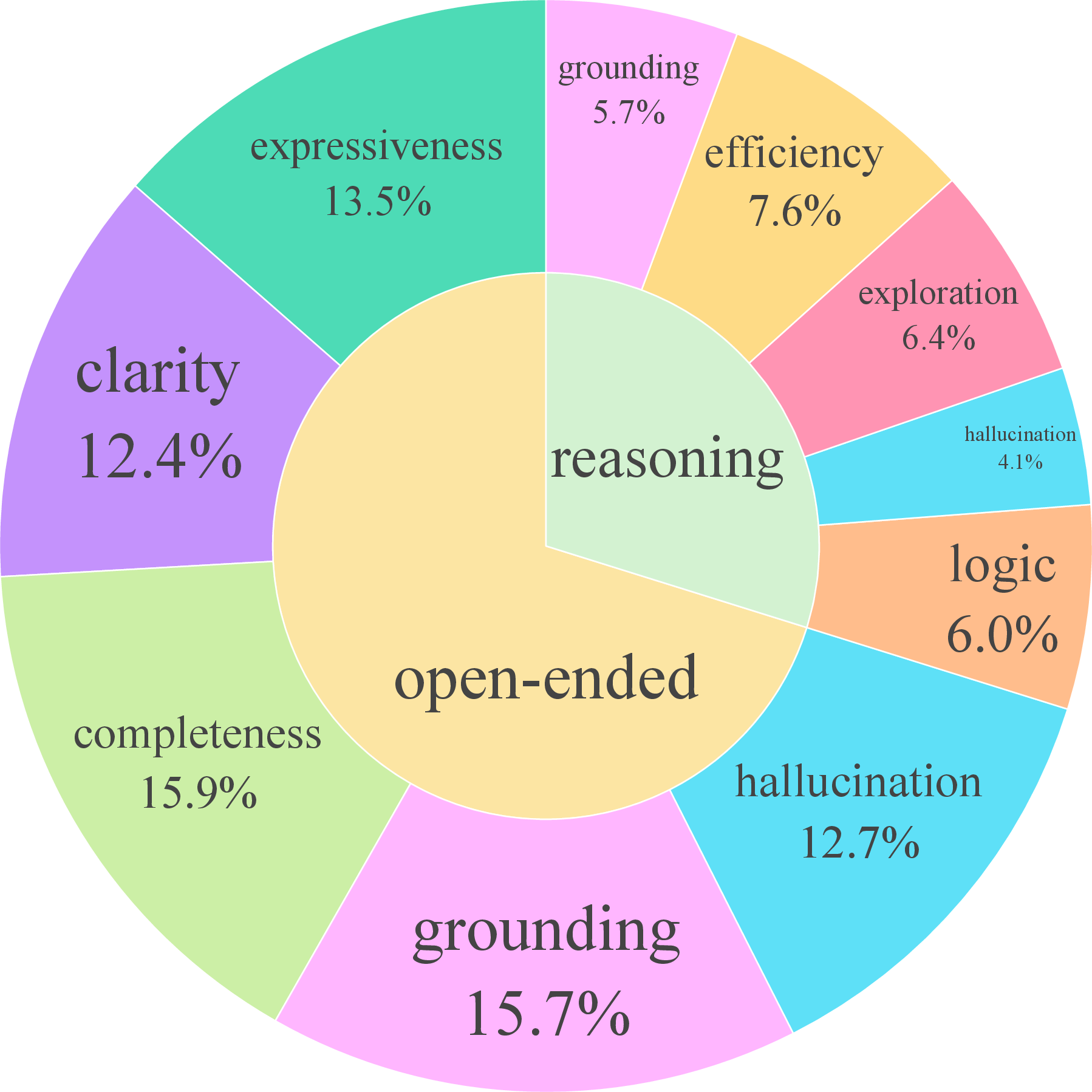
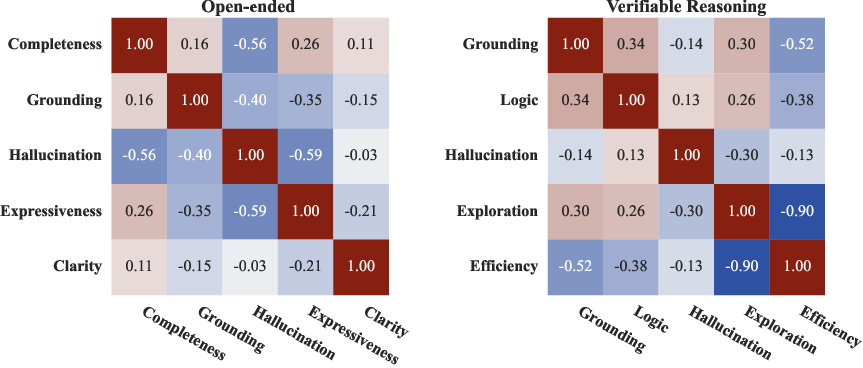
- Example criteria for open-ended tasks include:
- Completeness (covers what was asked)
- Visual grounding (uses details actually seen in the image)
- No hallucination (doesn’t make things up)
- Creativity/expressiveness
- Clarity/coherence
- Example criteria for reasoning tasks include:
- Visual grounding
- Logical steps and consistency
- No hallucination
- Reflection/exploration (thinks through alternatives)
- Conciseness/efficiency
Measuring how good the AI judges are
To see if judges truly follow multiple criteria, the authors used three simple metrics:
- Pluralistic Accuracy (PAcc): Did the judge get every criterion right for a single example? This is strict—one mistake on any criterion means it’s counted as wrong.
- Trade-Off Sensitivity (TOS): When criteria disagree (for example, Answer A is better for logic but Answer B is better for creativity), does the judge also show different preferences across criteria, instead of always picking the same answer?
- Conflict Matching Rate (CMR): In those disagreements, does the judge choose the same side as humans for both criteria (i.e., match the human “A beats B on logic” and “B beats A on creativity”)?
What did they find, and why is it important?
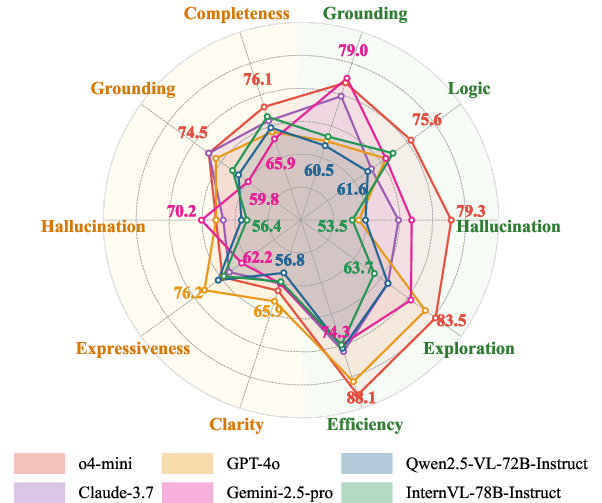
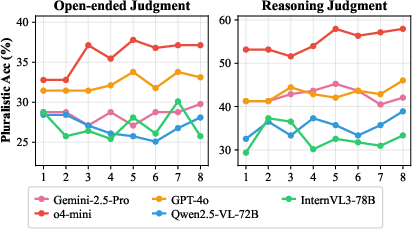
- Pluralistic judging is hard. Even the best models struggled to get everything right at once:
- On open-ended tasks, the top score for PAcc was about 33%.
- On reasoning tasks, the top score for PAcc was about 53%.
- This means that being correct across multiple criteria at the same time is challenging—even for leading AI judges.
- Models handle reasoning better than open-ended tasks. Reasoning tasks are more objective (it’s clearer what’s right), while open-ended tasks are more subjective and depend on fine visual details and style.
- Proprietary models generally did better than open-source ones. They were more accurate by criterion and better at noticing and resolving conflicts between criteria (higher TOS and CMR). Open-source models especially struggled to correctly handle those “this criterion says A, that criterion says B” situations.
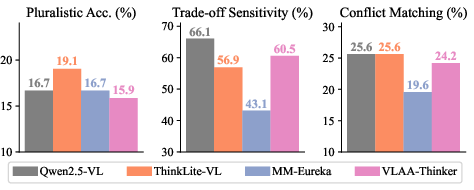
- Fine-tuned “critic” models help in one area but don’t solve the whole problem. Models trained to be judges improved at visual grounding (linking what they say to the image) but didn’t generalize well to handling many different criteria at once or recognizing tough trade-offs.
- Extra tests gave more clues:
- Training models to reason better (using reward-based methods) didn’t improve their ability to notice trade-offs between criteria; sometimes it even made that worse.
- Running a judge multiple times and taking a vote (test-time scaling) helped a bit for the strongest models, but not consistently for others.
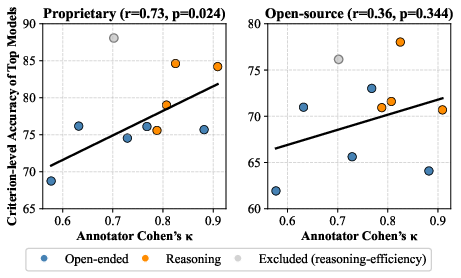
- The best proprietary models’ top criterion scores tracked closely with how much humans agree with each other, suggesting they’re getting closer to human-like judging patterns. Open-source models showed a weaker link.
Why this matters: In the real world, we don’t want AI judges that only say “which answer is better overall.” We want judges that can follow instructions like “score for factual accuracy,” “score for creativity,” or “score for clarity”—and understand that one answer might win in one category and lose in another. That’s essential for fair grading, safe content checks, ranking models, and giving useful feedback for training future AIs.
What does this mean for the future?
- We need AI judges that can be steered by different criteria and handle conflicts between them. This will make automated evaluation fairer and more transparent.
- Training data and methods should include multi-criteria signals, not just single overall preferences. That’s the key step this benchmark encourages.
- Open-source models need better multi-criteria training to catch up, especially in recognizing and correctly resolving trade-offs.
- Multi-Crit gives researchers a clear target: build judges that can follow pluralistic rules, not just one-size-fits-all scoring. This can lead to more reliable evaluations and better feedback loops for improving AI systems themselves.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored.
- Modalities beyond static images: Extend Multi-Crit to video, audio, multi-image inputs, and richer document modalities (e.g., multi-page PDFs) to test temporal reasoning and cross-frame grounding.
- Multilingual coverage: Assess judges on non-English prompts/responses, including code-switching, translation effects, and cross-lingual criterion following.
- Domain breadth: Incorporate high-stakes domains (e.g., medical, legal, safety-critical robotics), chart/table-heavy analytics, and OCR-intensive tasks to probe criterion adherence under specialized constraints.
- Criteria completeness: Add dimensions such as safety/toxicity, fairness/bias, instruction compliance, robustness, uncertainty handling, and external knowledge fidelity (beyond visual grounding) to better reflect real-world evaluation needs.
- Criterion relevance detection: Allow “not-applicable” judgments and evaluate whether judges can correctly abstain or identify non-relevant criteria per prompt.
- Justification quality: Measure criterion-specific critique quality (truthfulness, specificity, visual reference fidelity), not just preference labels; benchmark explanation-grounding (e.g., pointing to image regions).
- Aggregation and weighting: Develop methods to combine multiple criteria into an overall decision, including user-specific utility weighting and conflict-aware aggregation strategies.
- Conflict taxonomy: Systematically characterize and label conflict types (e.g., Logic vs. Conciseness, Grounding vs. Hallucination) to enable targeted analysis and training.
- Metric design: Validate and extend TOS/CMR—e.g., pairwise conflict coverage rates, per-criterion confusion matrices, calibration-aware metrics, and robustness to random disagreements—so trade-off sensitivity isn’t inflated by arbitrary criterion differences.
- Confidence and abstention: Collect judge confidence per criterion; evaluate calibration (e.g., Brier score, reliability diagrams) and the impact of allowing “tie/uncertain” beyond the current ≤10% tie constraint.
- Human agreement granularity: Report inter-annotator agreement per criterion (not only split-level averages); analyze criteria with low consensus to identify inherently ambiguous dimensions.
- Annotation diversity: Broaden annotator demographics (non-CS experts, cross-cultural perspectives) and measure how diversity affects criterion definitions, agreement, and model alignment.
- Dataset scale and distribution: Increase sample size, balance across sources, and publish per-source performance to reveal domain-specific weaknesses and avoid overfitting to particular prompt types.
- Selection bias from filtering: Quantify how using GPT/Gemini/Claude for “difficulty filtering” shapes the benchmark’s disagreements; compare to alternative filtering (e.g., human-only selection, diverse ensembles) to reduce bias toward specific model quirks.
- Reasoning-pair correctness constraint: Revisit the design choice to keep only pairs where both answers are correct or both incorrect; study judge behavior when one answer is objectively correct and the other is not.
- Automated verifier reliability: Validate GPT-4o-mini’s reasoning correctness judgments with human verification or multi-verifier ensembles; measure error rates and their impact on benchmark labels.
- Pair curation heuristic: Test whether MiniLM-L6 cosine distance reliably captures criterion-level differences; evaluate alternative diversity measures (semantic, structural, visual grounding differences).
- Prompt sensitivity: Measure robustness to judge prompt templates, phrasing variations, and instruction formatting; study multi-turn criterion switching within a single session (context retention, drift).
- Pluralistic training: Design and evaluate fine-tuning pipelines that use criterion-level labels (not holistic rewards) to improve pluralistic adherence, conflict resolution, and trade-off sensitivity across criteria.
- RL and self-consistency: Investigate multi-criterion RL objectives, chain-of-thought strategies, and specialist-judge ensembles that preserve trade-off recognition (addressing the reported degradation under holistic reasoning RL).
- Adversarial robustness: Stress-test judges with adversarial or obfuscated responses (e.g., subtle hallucinations, misleading visual cues) and measure resilience across criteria.
- Length bias analysis: Quantify residual sensitivity to response length after normalization and develop mitigation strategies (e.g., length-aware scoring, structure-focused prompts).
- Generalization to new criteria: Evaluate zero-shot criterion following for unseen dimensions and prompt-adaptive criterion interpretation (e.g., dynamically instantiated rubrics).
- Stability and reproducibility: Track proprietary model version drift; propose protocols (e.g., frozen snapshots, open-source surrogates) for stable longitudinal benchmarking.
- Cost/latency trade-offs: Report computational cost of multi-criterion judging and majority-vote test-time scaling; study efficient strategies that maintain accuracy without prohibitive inference overhead.
- Human upper bounds: Compute human PAcc/TOS/CMR to contextualize model performance; analyze gaps per criterion to target areas where models diverge most from human evaluators.
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, leveraging Multi-Crit’s benchmark, metrics (PAcc, TOS, CMR), curation pipeline, and empirical findings.
- MLOps quality assurance for multimodal systems (software, robotics, media)
- Use Multi-Crit’s metrics in CI/CD to gate releases of vision-language features (e.g., captioning, chart interpretation, UI understanding). Set minimum thresholds per criterion (e.g., Hallucination ≥ 70%, Grounding ≥ 65%), and track pluralistic prompt-level metrics (PAcc, TOS, CMR) over time.
- Findings-informed model assignment: use o4-mini for verifiable reasoning QA, GPT-4o for trade-off sensitivity audits, and avoid relying solely on open-source judges for conflict resolution.
- Assumptions/Dependencies: access to proprietary models; representative internal evaluation data; alignment between internal criteria and Multi-Crit’s definitions.
- Conflict-aware A/B testing and ranking of model variants (software product development)
- Replace single “overall preference” scoring with criterion-level pairwise judgments; surface trade-offs (e.g., better expressiveness vs worse hallucination) using TOS and CMR to inform product decisions.
- Workflow: run judges per criterion, detect conflicts, present decision-ready dashboards; escalate cases where conflicts impact safety (hallucination) or compliance (grounding).
- Assumptions/Dependencies: clear business-aligned criterion weights; existing experimentation platform; human oversight for safety-related conflicts.
- Safety and hallucination audits for regulated domains (healthcare, finance, public sector)
- Apply criterion-focused hallucination and logic checks on multimodal outputs like medical image summaries, financial chart analyses, and document understanding, prioritizing CMR in conflict-heavy prompts.
- Findings-based guidance: proprietary judges outperform open-source on conflict resolution; critic fine-tuning helps visual grounding but not conflict handling—use multi-judge ensemble for critical decisions.
- Assumptions/Dependencies: strict data privacy controls; domain-adapted criteria definitions; human review for high-stakes outputs.
- Accessibility and content quality control for large catalogs (e-commerce, media, education)
- Judge alt-text/image captions using open-ended criteria (Grounding, Factuality, Clarity) to reduce hallucinations and improve relevance; route failures to human editors.
- Tools: “Caption QA” pipeline with Multi-Crit metrics; automatic conflict detector to flag captions that are expressive but not grounded.
- Assumptions/Dependencies: catalog images/text availability; acceptance that open-ended PAcc is low—use criterion-specific gating and human-in-the-loop.
- Multi-criteria grading and feedback in education (STEM homework with diagrams, charts, math)
- Use reasoning criteria (Logic, Grounding, Exploration, Efficiency) to provide rubric-aligned feedback on student solutions and explanations; visualize trade-offs (e.g., high exploration vs low efficiency) to teach reflective reasoning.
- Assumptions/Dependencies: institution-approved usage policies; teacher calibration; guardrails for hallucination detection.
- Immediate improvements to judge-based training pipelines (RLAIF/RLHF for multimodal models)
- Insert Multi-Crit judges as pre-training evaluators to filter/score synthetic data, focusing on high Grounding and low Hallucination; avoid using reasoning-tuned models alone as judges (finding: reduced trade-off recognition).
- Assumptions/Dependencies: training infrastructure; prompt templates per criterion; human sampling for edge cases.
- Test-time scaling for evaluations where feasible (software QA)
- Use majority voting across multiple judge runs to modestly improve PAcc (most helpful for o4-mini and GPT-4o, per findings); apply cost-aware thresholds to decide when to invoke scaling.
- Assumptions/Dependencies: compute budget; diminishing returns on weaker models; careful monitoring to avoid “false confidence.”
- Internal dataset curation using the Multi-Crit pipeline (industry and academia)
- Replicate the paper’s three-stage filtering and multi-criterion annotation to build domain-specific, conflict-rich evaluation sets (e.g., clinical imaging, CAD diagrams, compliance documents).
- Assumptions/Dependencies: expert annotators; time/cost for rigorous annotations; inter-annotator calibration processes (e.g., Cohen’s κ targets).
- Procurement and governance checklists (policy and enterprise risk)
- Require vendors to report PAcc, TOS, and CMR on representative tasks; mandate disclosure of judge consistency on open-ended vs reasoning splits; call for conflict-aware evaluation plans.
- Assumptions/Dependencies: organizational buy-in; standardized reporting templates; harmonization with existing AI governance frameworks.
Long-Term Applications
Below are applications that require further research, scaling, or development to become robust and widely deployable.
- Pluralistic criterion-aware judge/reward models (software platforms, AI infrastructure)
- Train judges explicitly on criterion-level signals (beyond holistic preferences) to improve conflict resolution and adherence across diverse rubrics; develop “Judge-as-a-Service” APIs with per-criterion outputs, calibrated confidence, and conflict reports.
- Dependencies: large-scale, high-quality multi-criterion annotations; robust rubric generalization; model interpretability and justification quality.
- Multi-objective optimization for generation (software, media, education)
- Use PAcc/TOS/CMR to guide multi-objective RL or decision-theoretic generation: dynamically balance criteria (e.g., clarity vs creativity vs grounding), learn user-specific weights, and expose controls in UX.
- Dependencies: reliable reward shaping; preference learning; user studies to validate criterion weightings and outcomes.
- Domain-specialized clinical and financial judges (healthcare, finance)
- Build judges with domain rubrics (e.g., clinical grounding, diagnostic caution, chart interpretation accuracy, regulatory compliance) and conflict-aware decision policies (escalate to human for high-risk conflicts).
- Dependencies: expert-labeled datasets; regulatory acceptance; rigorous bias/safety assessments; liability frameworks.
- Standardization and certification of multi-criteria evaluation (policy, standards bodies)
- Integrate pluralistic metrics into standards (e.g., ISO-like) for multimodal AI evaluation; define minimum thresholds per criterion and conflict-handling protocols for safety-critical deployments.
- Dependencies: cross-industry consensus; audit tooling; verified benchmark suites; alignment with legal/regulatory regimes.
- Cross-modal expansion: video/audio and sensor fusion (robotics, media, autonomous systems)
- Extend Multi-Crit concepts to temporal and multi-sensor tasks; evaluate planning/execution traces with criteria like spatiotemporal grounding, causal logic consistency, and uncertainty communication.
- Dependencies: new datasets and rubrics; scalable annotation tools; domain-specific evaluators for complex modalities.
- Autonomous curation of conflict-rich evaluation sets (software tooling, data ops)
- Build tools that automatically mine prompts and create response pairs likely to exhibit criterion conflicts; ensemble judges filter trivial cases; humans annotate only nuanced, high-value examples.
- Dependencies: reliable conflict pre-detectors; active learning loops; annotation UX; budget and data governance.
- Superhuman multimodal judges (research, evaluation services)
- Aim beyond human-level inter-annotator consistency (observed correlation suggests proprietary models approach human upper bounds); develop methods to detect human blind spots and provide richer justifications.
- Dependencies: scalability of annotations; improved explanation quality; robust meta-evaluation to validate “superhuman” claims.
- Agentic workflows guided by conflict-aware judges (robotics, software agents)
- Use judges to steer agent decision-making: identify trade-offs, propose alternative plans, and adjudicate between conflicting goals (e.g., speed vs accuracy) in perception-action loops.
- Dependencies: reliable real-time judging; closed-loop integration; safety constraints; transparency requirements.
- Personalized, criterion-steered assistants (daily life, education, creative work)
- Users set rubric preferences (e.g., creativity high, hallucination low, grounding medium); assistants adapt outputs and show trade-off explanations for transparency and trust.
- Dependencies: user interfaces for preference control; on-device or private judging; fairness and accessibility considerations.
- Enterprise risk dashboards and SLAs (enterprise AI governance)
- Create dashboards that track PAcc/TOS/CMR by use case, data domain, and release; include SLAs specifying minimum per-criterion performance, escalation paths for conflicts, and audit trails.
- Dependencies: MLOps integration; logging and compliance infrastructure; governance adoption.
- Accessibility compliance at scale (policy, platforms, e-commerce)
- Enforce multi-criteria quality of alt-text and visual descriptions across large catalogs; build conflict-aware triage (e.g., expressive but ungrounded descriptions flagged for human correction).
- Dependencies: integrated content pipelines; annotator availability; continuous monitoring and retraining.
Each long-term application depends on expanding Multi-Crit’s approach (pluralistic criteria design, conflict-aware metrics, rigorous human annotation) to new domains and modalities, and on closing current gaps highlighted in the paper (e.g., low open-ended PAcc, weaker conflict handling in open-source judges, limited generalization from critic fine-tuning).
Glossary
- Autoregressive: A generation process where the model predicts the next token conditioned on previously generated tokens. "in an autoregressive manner."
- BT-style reward models: Reward-modeling approach with specialized output heads trained on preference signals. "BT-style reward models with dedicated reward heads"
- CMR (Conflict Matching Rate): A metric measuring whether a judge correctly resolves ground-truth conflicts between criterion-based judgments. "Conflict Matching Rate (CMR)."
- Cohen’s κ: A chance-corrected statistic for inter-annotator agreement. "Cohenâs "
- Cosine distance: A measure of dissimilarity between vectors derived from cosine similarity. "largest cosine distance between their MiniLM-L6~\cite{wang2020minilm} embeddings"
- Cross-model pairs: Pairs of responses generated by two different models for the same prompt. "cross-model pairs, generated by randomly selecting two different LMMs"
- Criterion-level accuracy: Accuracy computed per evaluation criterion rather than a single overall label. "criterion-level accuracy"
- Criterion-level conflicts: Situations where different criteria prefer different responses for the same pair. "criterion-level conflicts"
- Criterion-level preferences: Per-criterion labels specifying which response is preferred. "criterion-specific preferences:"
- Criterion-level upper bound: The best achievable accuracy per criterion for a model or group. "the criterion-level upper bound of proprietary models"
- Criterion-switching flexibility: A judge’s ability to change its preference based on the specified evaluation criterion. "criterion-switching flexibility"
- Data contamination: Leakage of evaluation content into training data that biases results. "To minimize data contamination, we generate candidate responses"
- Ensemble-based difficulty filtering: A filtering step that uses multiple judges’ agreement to retain challenging examples. "Ensemble-based difficulty filtering:"
- Generative judges: Models that produce textual justifications and scores (or preferences) for evaluation. "generative judges that produce textual justifications and scores"
- GRPO: A policy-optimization method used to fine-tune models with reward signals. "three GRPO-finetuned models"
- Hallucination: Model outputs that assert unsupported or incorrect details not grounded in the input. "hallucination detection"
- Holistic judgment signals: Single, overall feedback labels that do not differentiate among multiple criteria. "holistic judgment signals"
- Inter-annotator agreement: The degree to which different annotators provide consistent labels. "Inter-annotator agreement is quantified"
- Intra-model pairs: Pairs of responses produced by the same model via sampling to induce diversity. "intra-model pairs, produced by the same model via temperature sampling."
- LMM-as-a-Judge: Using large multimodal models as evaluators of other models’ outputs. "LMM-as-a-Judge"
- LMMs (Large Multimodal Models): Models that process and generate across multiple modalities (e.g., text and images). "Large multimodal models (LMMs) are increasingly adopted as judges"
- Majority vote: Aggregating multiple judgments by selecting the option with the most votes. "take a majority vote for each criterion sample"
- MiniLM-L6 embeddings: Vector representations from the MiniLM-L6 model used to compare response content. "MiniLM-L6~\cite{wang2020minilm} embeddings"
- Multimodal prompt: An input consisting of both visual (image) and textual components. "Given a multimodal prompt consisting of an image and a user query"
- Open-ended generation: Tasks where outputs are free-form and not strictly constrained by references. "open-ended content generation"
- Pairwise preference judgments: Evaluations where the judge chooses the better of two responses. "pairwise preference judgments, accompanied by textual justifications"
- PAcc (Pluralistic Accuracy): A metric requiring the judge to be correct across all criteria for a sample. "Pluralistic Accuracy ()."
- Pluralistic criteria following: The capacity to adhere to multiple, potentially conflicting evaluation criteria. "pluralistic criteria following"
- Preference aggregation: Combining multiple annotators’ labels into a final decision. "Preference Aggregation and Final Verification."
- Preference trade-offs: Conflicting advantages across criteria between two responses. "recognize preference trade-offs"
- Reinforcement fine-tuning: Adapting models using reward signals via reinforcement learning methods. "through reinforcement fine-tuning"
- RLVR: Reinforcement Learning from Verifiable Rewards, using objective checks as feedback signals. "Does RLVR on multimodal reasoning improve judgment in reasoning traces?"
- Reward models: Models trained to provide scalar or preference signals guiding evaluation or training. "reward models"
- Scalar scores: Single numeric ratings assigned to responses under a given criterion. "either scalar scores for individual responses or pairwise preference judgments"
- Test-time scaling: Improving performance by running multiple evaluations at inference and aggregating results. "test-time scaling effects"
- Top-p: Nucleus sampling parameter controlling the cumulative probability mass from which tokens are sampled. "top- of 0.95"
- TOS (Trade-off Sensitivity): A metric indicating whether the judge recognizes differing preferences across criteria. "Trade-off Sensitivity (TOS)."
- Verifiable reasoning: Tasks whose answers or steps can be objectively checked for correctness. "verifiable reasoning tasks"
- Verifiable reasoning filtering: Keeping only response pairs where correctness is not trivial for reasoning evaluation. "Verifiable reasoning filtering:"
- Visual grounding: Referencing and aligning claims to observable elements in the image. "Visual Grounding"
- Visual–textual grounding: Aligning and evaluating consistency between visual content and textual descriptions. "visualâtextual grounding and alignment"
Collections
Sign up for free to add this paper to one or more collections.

