- The paper introduces a unified framework that combines transitivity violation analysis and split conformal prediction to assess instance-level LLM judge reliability.
- It reveals that aggregate metrics mask significant per-document inconsistencies, especially in fluency and consistency evaluations.
- The study shows that prediction set width correlates with error, offering a robust trust signal for selective human review.
Diagnosing Per-Instance Reliability in LLM-as-Judge Systems
Introduction
The adoption of LLM-as-judge paradigms for automatic NLG evaluation has outpaced the development of principled methodologies for assessing their reliability at the per-instance level. Aggregate statistics typically used to summarize LLM judge behavior are insufficiently granular and systematically mask instance-level inconsistencies critical for scientific evaluation and high-stakes deployment. "Diagnosing LLM Judge Reliability: Conformal Prediction Sets and Transitivity Violations" (2604.15302) introduces a unified analytic framework leveraging two complementary diagnostics: transitivity violation analysis in pairwise preference data and split conformal prediction for informative uncertainty quantification in direct scoring. Together, these analyses illuminate the latent heterogeneity in LLM judge behavior and identify actionable trust signals for deployment.
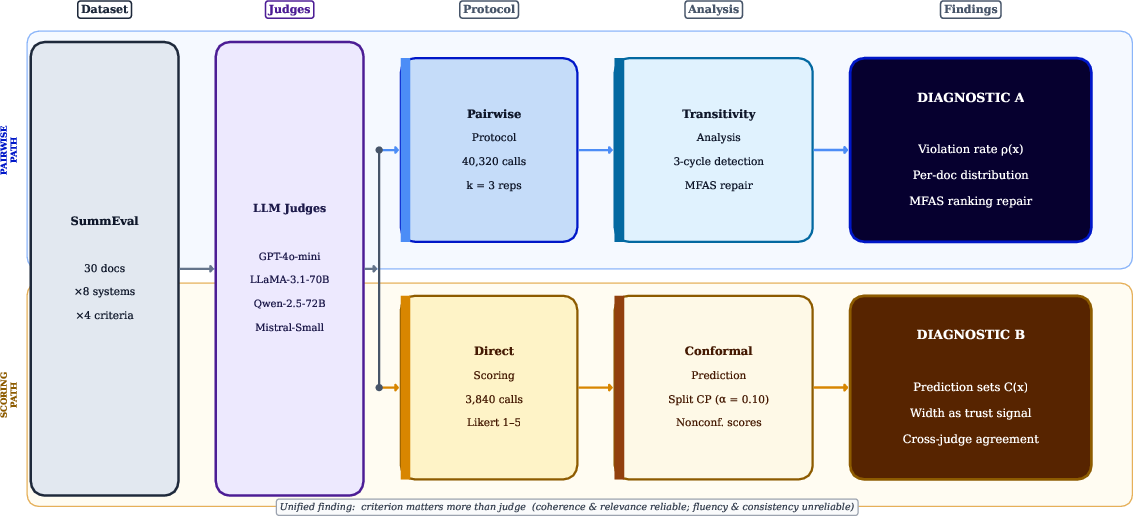
Figure 1: Overview of the dual diagnostic pipeline, comprising pairwise preference-based transitivity analysis and direct-scoring-based conformal prediction, applied to four LLM judges on SummEval.
Transitivity Violations in Pairwise Evaluation Protocols
The first diagnostic targets tournament-theoretic transitivity violations—directed 3-cycles in the pairwise preference graphs constructed by LLM judges. Classic social choice results establish that directed cycles (e.g., A≻B, B≻C, C≻A) arise most commonly when systems are closely matched, yet aggregate violation rates are often misleadingly low. This work conducts a per-document analysis of SummEval outputs judged by four state-of-the-art instruction-tuned models (GPT-4o-mini, LLaMA-3.1-70B, Qwen-2.5-72B, Mistral-Small-3.1), revealing that while mean violation rates ρˉ fall between 0.8% and 4.1%, 33–67% of documents exhibit at least one cycle, with outliers exceeding 30% for some judge–criterion pairs.
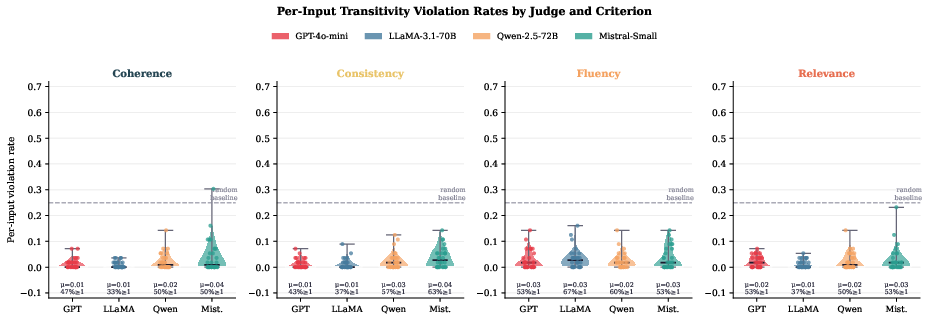
Figure 2: Distribution of per-document transitivity violation rates; long-tailed distributions expose input-specific concentration of judge inconsistencies, particularly for fluency.
This heterogeneity is criterion-dependent: fluency and consistency consistently incur the highest violation incidence, whereas coherence and relevance exhibit narrower distributions. The study further establishes that aggregation or tournament repair using MFAS (Minimum Feedback Arc Set) algorithms does not systematically improve agreement with human preference rankings; the majority of cycles represent sparse, instance-local noise, not systematic bias.
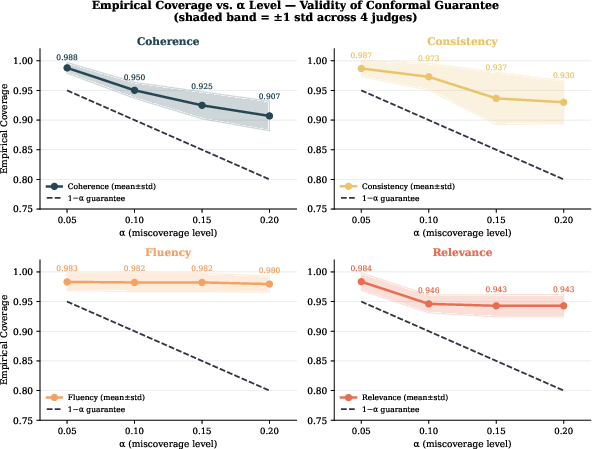
The second diagnostic leverages split conformal prediction to produce finite-sample, distribution-free coverage guarantees on LLM-as-judge direct Likert scores. Here, the LLM's score for each system output is wrapped with a prediction set, C(x), which is guaranteed to contain the rounded mean human annotation at least (1−α) fraction of the time across trials. The width of this set serves as a reliability indicator: width 1 indicates maximal LLM confidence, width 5 (covering the whole Likert scale) signals full judge uncertainty.
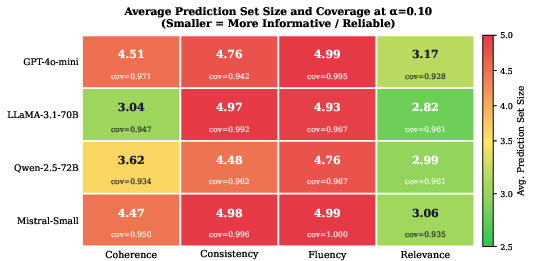
Figure 3: Heatmap of average prediction set size at α=0.10 across judges and criteria; coherence and relevance are consistently judged more reliably (smaller sets) than fluency and consistency.
Empirical results robustly align with the theoretical coverage guarantee across all judges, criteria, and significance thresholds. Critically, criterion rather than judge identity is the principal axis of reliability: prediction set widths for coherence and relevance are generally ≤3, while fluency and consistency produce widths near the maximum, regardless of model. This property is preserved across several calibration regimes and is not an artifact of judge-specific noise—set width shows significant cross-judge correlation on hard documents, corroborating that it indexes instance-level difficulty.
Prediction Set Width as an Error and Difficulty Signal
Prediction set width exhibits a strong and interpretable relationship with absolute error between LLM and human Likert scores. When pooling across all judges and criteria, Spearman correlation reaches rs=+0.576 (p<10−100), establishing width as a practical and robust trust signal for selective acceptance or escalation of automated judgments.
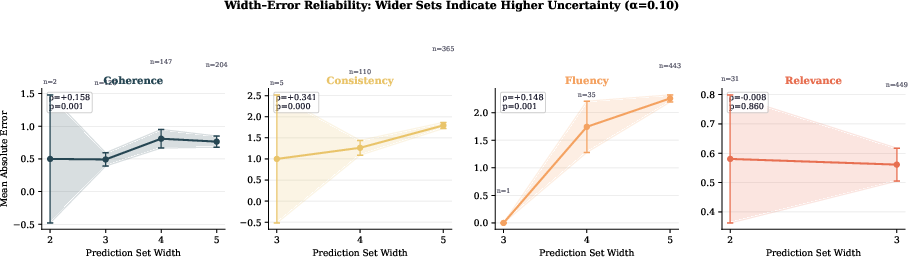
Figure 4: Pooled reliability diagrams indicating that set width is monotonic in LLM judge absolute error; wider sets correspond to increased disagreement with human annotation.
The cross-judge width agreement analysis further isolates width as a document-level difficulty signal. For fluency, consistency, and relevance, inter-judge Spearman B≻C0 consistently exceeds +0.3 and peaks above +0.8 in some model pairs, with B≻C1 significance for the majority of comparisons. The sole exception is coherence, which demonstrates less cross-judge concordance, likely due to increased variance in system outputs for this criterion and divergent model-internal representations.
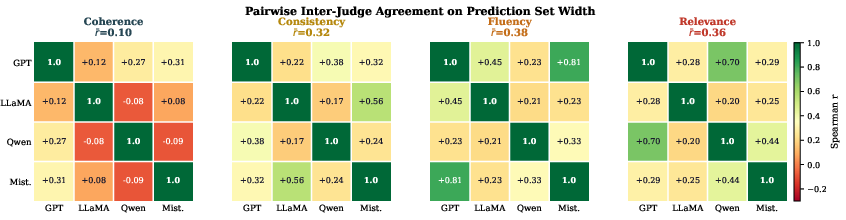
Figure 5: Inter-judge width agreement matrices highlight strong off-diagonal correlations for fluency and relevance, supporting the interpretation of set width as reflecting input difficulty.
Practical Recommendations and Implications
This analysis converges on several implications for the design and interpretation of LLM-as-judge evaluation frameworks:
Theoretically, these findings suggest that LLM-as-judge deployment in evaluation must integrate uncertainty quantification and selective triage to mitigate the risks of over-trusting automated system annotations, emphasizing robust aggregation procedures and per-criterion reliability analysis.
Conclusion
"Diagnosing LLM Judge Reliability: Conformal Prediction Sets and Transitivity Violations" (2604.15302) provides a precise, statistically-grounded framework for scrutinizing LLM-as-judge reliability at the instance level. The diagnostic toolkit sharply exposes the shortcomings of aggregate metrics, establishes conformal set width as a practical deployment trust signal, and demonstrates that reliability is primarily criterion-driven, not judge-driven. These contributions provide methodological foundations for safer, more principled use of LLM-based evaluation in NLG, and point toward selective, uncertainty-aware human-in-the-loop protocols as the path forward.