World-R1: Reinforcing 3D Constraints for Text-to-Video Generation
Abstract: Recent video foundation models demonstrate impressive visual synthesis but frequently suffer from geometric inconsistencies. While existing methods attempt to inject 3D priors via architectural modifications, they often incur high computational costs and limit scalability. We propose World-R1, a framework that aligns video generation with 3D constraints through reinforcement learning. To facilitate this alignment, we introduce a specialized pure text dataset tailored for world simulation. Utilizing Flow-GRPO, we optimize the model using feedback from pre-trained 3D foundation models and vision-LLMs to enforce structural coherence without altering the underlying architecture. We further employ a periodic decoupled training strategy to balance rigid geometric consistency with dynamic scene fluidity. Extensive evaluations reveal that our approach significantly enhances 3D consistency while preserving the original visual quality of the foundation model, effectively bridging the gap between video generation and scalable world simulation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI systems that turn text into videos behave more like they understand the real 3D world. Today’s video models can make pretty videos, but when the “camera” moves a lot, objects can wobble, stretch, or disappear in ways that don’t make sense. The authors propose World‑R1, a way to “teach” these models the rules of 3D space so scenes stay consistent as the camera moves—without rebuilding the model or adding heavy extra parts.
What questions were the researchers trying to answer?
- How can we get a text‑to‑video model to keep objects solid and steady (3D‑consistent) when the camera moves around?
- Can we do this without expensive 3D datasets or slowing down video creation with complicated add‑ons?
- Can the model still make good‑looking, creative videos while following 3D rules and camera instructions in the text?
How did they do it? (Explained simply)
Think of training like a game with a scorecard. The model makes videos; “judges” watch and give scores. The model learns to get higher scores over time.
- Teaching by rewards (Reinforcement Learning):
- The model is asked to make a video from a text prompt like “Orbit around a castle at sunset.”
- Several “judge” systems score the result:
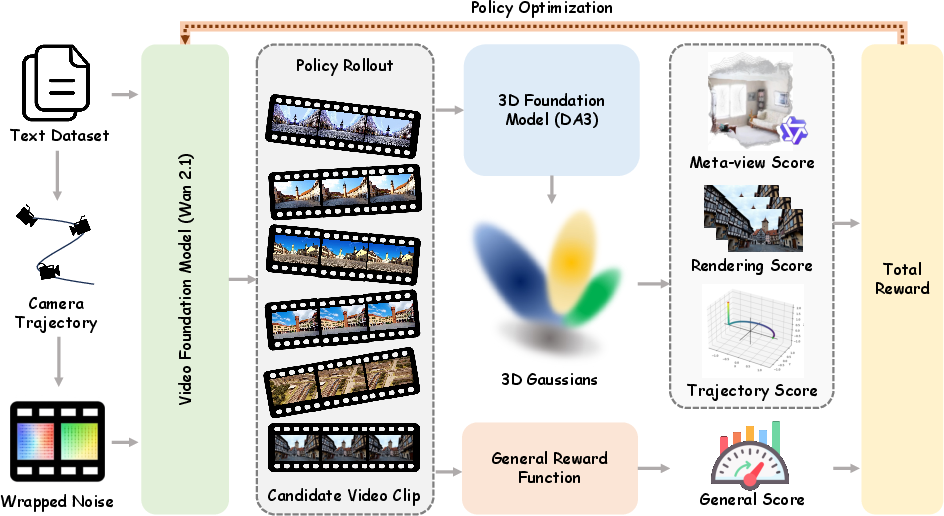
- 3D check: A 3D tool tries to rebuild the scene from the video, like recreating a set using a cloud of tiny glowing dots (a simple way to represent 3D called “Gaussian splats”). If re‑rendered views match the original frames and also look right from a new angle, the score goes up. If walls bend or objects jump around, the score drops.
- Camera check: The model is told a camera path (e.g., orbit left). The score is higher if the video’s camera movement matches that path.
- Quality check: Another system rates how pleasing and clear the frames look, so the model doesn’t get “ugly but consistent.”
- The model adjusts itself to maximize these combined scores. This “learn by trial and error with feedback” is reinforcement learning. They use an efficient method called Flow‑GRPO‑Fast to make this feasible for video.
- Quiet camera control (no extra modules):
- Instead of adding a new camera‑control box to the model, they sneak the camera plan into the model’s starting “noise.” Video diffusion models begin from random noise; by gently “steering” this noise to match the desired camera motion, the model is nudged to move the camera correctly—like tilting the starting marble track so the marble rolls along a chosen path.
- A pure text practice set:
- They made a practice set of about 3,000 text prompts that describe many kinds of scenes (cities, nature, even surreal worlds) and many camera moves (push in, pan, orbit, mixes of moves).
- No real videos are used here—just text. This lets the model practice following instructions without being biased by a fixed video dataset.
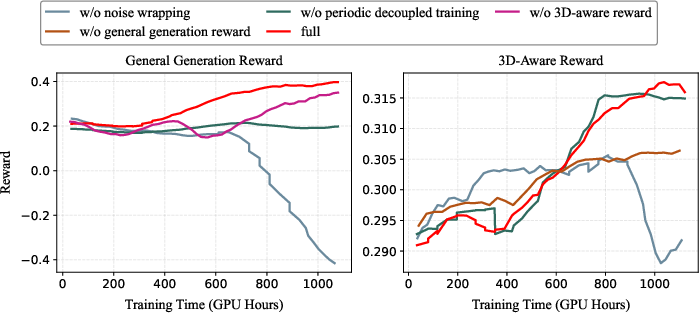
- Balanced training schedule:
- If you force 3D rules too hard, soft things that naturally move (like people, animals, cloth, waves) can look “frozen.”
- So they train in cycles: most steps enforce strong 3D consistency; then some steps focus only on general video quality and lively motion. This keeps both rigid structures (buildings, rooms) and non‑rigid motion (people, trees) looking right.
What did they find, and why is it important?
- Much better 3D consistency:
- When they rebuild and re‑render the generated scenes, the match to the original video is much tighter than with standard models. They report big gains on common measures of consistency and clarity (e.g., a large boost in PSNR and better SSIM/LPIPS), meaning fewer “wobbles,” warps, and disappearing objects.
- Good visuals are preserved:
- On a public video quality benchmark, their model scores higher in aesthetics, imaging quality, and how consistently subjects stay the same across frames—so it doesn’t trade beauty for stability.
- People prefer it:
- In a blind user study, viewers chose World‑R1 most of the time—especially for geometry (92% win rate) and camera accuracy (76% win rate). Overall, it was preferred in 86% of comparisons.
Why this matters:
- It nudges video models from “pretty pictures in a row” toward “a believable 3D world you can move through.” That’s crucial for things like virtual tours, games, robotics training, and driving simulators—anywhere the camera needs to move and the world should stay physically sensible.
What’s the big picture?
World‑R1 shows you can teach a text‑to‑video model to respect 3D reality by giving it smart feedback—without changing its internal wiring or needing big 3D datasets. It’s a scalable way to turn today’s video generators into “world simulators” that can handle camera moves reliably while still making attractive, varied videos.
Limits and future directions:
- Training still costs a lot because reinforcement learning needs many video trials and scores.
- The final quality still depends on how strong the base video model is.
- Future work could make training cheaper and plug into even stronger base models for finer motions, longer videos, and more complex scenes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, organized by theme to aid follow-up research.
Reward design and supervision dependencies
- Robustness of the 3D-aware reward to failure modes of the reconstruction pipeline: how Depth Anything 3 + 3DGS behave under textureless regions, thin structures, specular/transparent surfaces, occlusions, rolling shutter, or heavy motion blur; quantify reward reliability and calibration in these regimes.
- Sensitivity of the reward to dynamic scenes: 3DGS assumes near-static geometry, yet non-rigid or multi-body motion is common; the paper disables the 3D reward periodically but does not offer a principled 4D/dynamic reward—design and evaluate dynamic-scene rewards that do not suppress motion.
- Scale ambiguity and trajectory alignment: monocular reconstruction yields unknown scale; the paper aligns E with estimated Ē but does not describe scale handling—propose and assess scale-aware or scale-invariant trajectory metrics (e.g., Sim(3) alignment).
- Reward hacking and cross-model validity: the approach may overfit to the specific 3D model and VLM (Depth Anything 3, Qwen3-VL); quantify cross-model generalization by swapping reward providers (alternative depth/pose/NeRF/GS pipelines; alternative VLMs) and measuring stability.
- Semantic meta-view scoring reliability: using a VLM to evaluate meta-view renders can be biased by aesthetics or text priors; assess false positives/negatives, adversarial prompts, and prompt-irrelevant “gaming” of VLM scores.
- Limited physical constraints in reward: no explicit handling of lighting, shadows, occlusion ordering, or contact/collision; explore augmenting rewards with photometric consistency, shading/illumination cues, or differentiable physics checks.
- Reward aggregation and weighting: the paper does not specify how weights are set or adapted; study automatic reward weight tuning, reward normalization across scales, and the impact of each component on convergence/stability.
- Temporal quality vs framewise aesthetic reward: aesthetics are averaged on the first K frames; evaluate whether this biases early frames and harms long-range temporal coherence; explore sequence-level perceptual/temporal rewards.
Camera conditioning and control
- Planar homography approximation and fixed reference depth: the noise-warping prior assumes a fronto-parallel plane at z_ref, which is inaccurate for scenes with large depth variation; evaluate failure cases and investigate depth-aware or layered flow priors for noise transport.
- Limited control interface: camera conditioning is inferred from keyword tokens and concatenated templates; support for explicit numeric pose/intrinsics/FOV inputs, time-varying intrinsics, or continuous control is not demonstrated.
- Long-horizon control drift: camera priors are injected only via initial noise wrapping; assess trajectory adherence over long sequences and investigate mid-trajectory control or recurrent conditioning to prevent drift.
- Complex motion composition: the approach concatenates simple motions; benchmark generalization to arbitrary, continuous camera paths and abrupt changes; quantify control accuracy beyond template motions.
Dataset and training protocol
- Dataset scale and coverage: the “Pure Text Dataset” has ~3,000 Gemini-authored prompts; quantify domain coverage (e.g., materials, weather, interiors/exteriors, stylized content), linguistic diversity (languages, compositional complexity), and long-tail phenomena.
- Synthetic text-only supervision: no real video-text pairs or real trajectories are used; evaluate generalization to in-the-wild prompts and real camera instructions; test on benchmarks with ground-truth camera paths.
- Dynamic subset handling: periodically disabling the 3D reward is a coarse mechanism; explore finer-grained strategies (e.g., segmentation- or part-aware rewards, motion masks) and report sensitivity to cycle length and proportions.
- Hyperparameter sensitivity: the paper lacks ablations on reward weights, KL coefficient β, group sizes, SDE noise schedule, denoise reduction timesteps, and training cycle hyperparameters; provide robustness envelopes.
Evaluation and metrics
- Heavy dependence on reconstruction-based metrics: PSNR/SSIM/LPIPS on 3DGS re-renders entangle model progress with reconstruction quality; systematically report reconstruction confidence/coverage, failure rates, and a broader set of reconstruction-independent metrics (beyond the brief MVCS mention).
- Dynamic-scene evaluation: metrics and reconstructions largely target rigid scenes; add protocols that isolate rigid vs non-rigid fidelity, e.g., layered consistency, optical-flow consistency, occlusion-aware metrics, or actor-centric tracking stability.
- Control accuracy with ground truth: trajectory alignment uses Ē estimated from the generated video; evaluate against known ground-truth camera paths (e.g., synthetic datasets or controlled prompts with explicit numeric paths).
- Diversity and mode collapse: show quantitative diversity metrics (e.g., CLIP-based intra-prompt variance, semantic entropy, trajectory diversity) to ensure RL does not reduce generative variety.
- Longer videos and higher resolutions: experiments focus on 832×480 and relatively short clips; benchmark scaling to higher resolutions (e.g., 1080p/4K) and long durations with hard camera paths, and report failure modes.
Scalability, efficiency, and stability
- Training cost and sample efficiency: RL with repeated rollouts and reward computation is expensive; quantify GPU hours and propose/assess strategies for sample-efficient RL (e.g., off-policy reuse, reward models, cached critics, distillation).
- Stability of Flow-GRPO-Fast: provide analysis of variance across runs, failure cases (e.g., KL collapse, oscillations), and convergence diagnostics; explore alternatives like offline reward modeling or hybrid supervised/RL schedules.
- Inference-time performance: implicit camera control adds flow computation and keyword parsing; quantify added latency and memory vs base models, and study robustness to ambiguous or conflicting instructions.
Generalization and robustness
- OOD content and styles: depth and VLM rewards may underperform on cartoons/anime, line-art, surreal/abstract scenes, or extreme lighting; evaluate robustness across styles and consider style-aware rewards or adapters.
- Multi-object, crowded, and cluttered scenes: reported limitations include dense multi-object composition; create stress tests for occlusion ordering, small object permanence, and inter-object consistency.
- Materials and photometric effects: reflective, translucent, or refractive materials challenge depth and consistency; quantify performance on such cases and explore specialized priors or reward terms.
- Cross-dataset and cross-backbone transfer: verify if the learned policy generalizes across different backbones (beyond Wan), and whether the learned improvements transfer when swapping reward models.
Safety, ethics, and misuse
- Increased realism risk: improved geometric consistency increases the plausibility of synthetic videos; assess risks of misuse (e.g., deepfakes) and propose detection/traceability measures (watermarking, provenance).
- Bias propagation from reward models and dataset: analyze how VLM and depth-model biases (content, geography, culture) shape generation; measure and mitigate bias amplification.
Reproducibility and release
- Access to training data and code: the Pure Text Dataset is proprietary; clarify release plans or provide generation templates and seeds; detail training scripts, reward computations, and model checkpoints for reproducibility.
- Detailed reward definitions: key implementation specifics (exact weights, normalization, VLM prompts, meta-view sampling strategy, and trajectory alignment procedure) are not fully specified; provide precise formulas and settings.
Integration and future directions
- Combining training-time RL with inference-time 3D steering: evaluate whether lightweight inference-time geometric guidance further improves consistency without large latency.
- Physics- and illumination-aware rewards: integrate differentiable rendering or learned reflectance models to enforce lighting/shadow consistency and physical plausibility.
- Toward explicit 4D representations: investigate whether the RL-tuned model can directly produce temporally consistent 4D assets (e.g., Gaussians/NeRFs) or auxiliary 3D outputs to assist downstream tasks (SLAM, planning).
Practical Applications
Overview
Below are practical applications derived from World-R1’s findings and methods. Items are grouped into Immediate Applications (deployable with today’s models, tooling, and compute) and Long-Term Applications (requiring further research, scaling, or productization). Each entry notes sectors, concrete use cases, potential tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Geometrically consistent text-to-video for media production
- Sectors: media/entertainment, advertising, gaming, social content
- Use cases:
- Pre-visualization, animatics, and virtual scouting with camera-path–faithful fly-throughs (e.g., orbit, push-in, pan) that avoid geometry warping
- Auto-generating B-roll, product reveal shots, and stylized camera tours with stable backgrounds and subject permanence
- Cutscene ideation for games with consistent camera moves from text prompts
- Tools/products/workflows:
- “World-consistent T2V” plug‑ins for NLE/VFX suites (Premiere, DaVinci, Unreal Bridge) that accept a prompt + camera path tokens
- Prompt templates + camera-path libraries; a camera-path–to–noise-warp module employing implicit camera conditioning (noise wrapping)
- Assumptions/dependencies:
- Availability of a fine-tuned World-R1 checkpoint or ability to fine-tune a base T2V model via the RL pipeline
- Camera control is prompt-driven; complex multi-constraint cinematography may need bespoke path scripting
- Final outputs are non-metric and should not be used for precise measurements
- Synthetic data generation with improved 3D consistency
- Sectors: robotics, autonomous systems, computer vision, retail (CV), insurance (CV), security
- Use cases:
- Training perception models (depth, pose, tracking, segmentation) with parallax-consistent sequences to reduce temporal drift
- Dataset augmentation for scene-understanding tasks (e.g., indoor navigation, warehouse robotics) with controlled camera trajectories
- Tools/products/workflows:
- “Consistent video synthesizer” that batch-generates prompt-based sequences with fixed camera paths for model pretraining
- Reward-driven filtering: use the 3D-aware reward as a data quality gate for synthetic videos
- Assumptions/dependencies:
- Generalization from synthetic to real depends on prompt/domain coverage; dynamics of non-rigid agents still limited
- Reward backbone (3DGS recon + VLM scoring) must be available at scale
- Rapid previsualization for architecture and real estate
- Sectors: AEC (architecture, engineering, construction), real estate, interior design
- Use cases:
- Text-described room/building walkthrough concept videos that hold walls/floors stable during camera moves
- Marketing tours for listings (conceptual/stylized), interior mood boards with consistent geometry
- Tools/products/workflows:
- “Prompt-to-walkthrough” SaaS with standard fly-through paths (entry → living room → balcony) as trajectory presets
- Assumptions/dependencies:
- Not a CAD replacement; outputs are visually coherent but not metrically accurate
- Works best for concepting/marketing, not compliance or engineering documentation
- Education and scientific communication visuals
- Sectors: education, public outreach, museums, publishing
- Use cases:
- Camera-guided explainer videos (e.g., orbit a molecule, fly through a cell/galaxy) with reduced spatial artifacts
- Architecture/history lessons with smooth, consistent camera paths to support narration
- Tools/products/workflows:
- “Lesson storyboarder” that maps lecture text to camera paths and generates clip batches; prompt libraries aligned to curricula
- Assumptions/dependencies:
- Scientific/architectural fidelity is illustrative; expert review needed for accuracy-sensitive topics
- Evaluation and QA for generative video via 3D consistency metrics
- Sectors: software (ML tooling), model evaluation, policy/compliance
- Use cases:
- CI/QA harness for video generators to detect geometric hallucinations during model iterations
- Benchmark suites for internal A/B testing of T2V quality with reconstruction-based PSNR/SSIM/LPIPS and meta-view VLM checks
- Tools/products/workflows:
- “3D Consistency Evaluator” service that reconstructs 3DGS from generated videos and computes reward/metrics; integrates with MLOps dashboards
- Assumptions/dependencies:
- 3DGS recon reliability varies with content; metrics should be used comparatively rather than as absolute pass/fail
- Camera-control authoring without architectural changes
- Sectors: software (creative tools), developer tooling
- Use cases:
- Drop-in SDK to add robust camera-path adherence to existing T2V apps without modifying base inference graphs
- Tools/products/workflows:
- A lightweight “noise-transport” library exposing trajectory-to-flow projection + discrete noise transport APIs
- Assumptions/dependencies:
- Best performance when trajectories are compatible with the flow-projection assumptions (e.g., moderate parallax, reference depth heuristic)
- Dataset curation using the Pure Text Dataset design
- Sectors: academia, ML R&D, startups
- Use cases:
- Constructing instruction-following corpora for camera control decoupled from visual biases
- Curriculum learning: from single-action to composite trajectories
- Tools/products/workflows:
- Prompt generation templates and taxonomies; automated difficulty stratification for RL fine-tuning
- Assumptions/dependencies:
- Quality of LLMs used to author prompts (e.g., Gemini) and diversity coverage impact downstream generalization
Long-Term Applications
- Interactive, explorable 4D scene generation for XR
- Sectors: AR/VR, gaming, virtual production
- Use cases:
- On-demand, explorable environments from text that maintain 3D coherence across long horizons and free camera control
- Fast previsualization evolving toward runtime asset generation for game engines
- Tools/products/workflows:
- T2V→4D pipelines that extract stable 3D assets (e.g., via refined 3DGS→mesh workflows) with material estimates and collision proxies
- Assumptions/dependencies:
- Requires stronger dynamic content modeling, longer sequences, and consistent view-dependent effects; improvements in reconstruction fidelity
- Closed-loop world models for robotics and autonomy
- Sectors: robotics, autonomous driving, drones, logistics
- Use cases:
- Training control and planning policies in visually consistent, generative simulators that can vary scenes and sensor paths
- Scenario stress testing (rare edge cases) with realistic parallax and temporal coherence
- Tools/products/workflows:
- “Generative simbench” coupling World-R1‑like generators with physics engines and agent models; sensor emulation (RGB, depth, LiDAR)
- Assumptions/dependencies:
- Needs long-horizon consistency, accurate multi-agent dynamics, and physical plausibility beyond geometry; integration with physics-based simulators
- Domain-specific medical and industrial training simulators
- Sectors: healthcare (surgical/endoscopic), energy (plant inspection), manufacturing (QA), utilities
- Use cases:
- Anatomy-consistent procedural videos for pretraining vision models; camera manipulation mimicking scopes/borescopes
- Drone/robot inspection sequences in industrial facilities with realistic parallax
- Tools/products/workflows:
- Fine-tuned sector models with specialized prompts and reward critics (domain VLMs, anatomy/asset priors)
- Assumptions/dependencies:
- Requires stringent domain priors, higher resolutions, and validation against expert benchmarks; regulatory acceptance for training data
- Digital twins and urban-scale planning visualization
- Sectors: smart cities, civil engineering, transportation planning
- Use cases:
- Rapid concept videos of infrastructure alternatives from textual briefs; consistent fly-throughs for stakeholder reviews
- Tools/products/workflows:
- Planning assistants that translate planning specs into camera tours and scenario variants (day/night, traffic density)
- Assumptions/dependencies:
- For decision-making, outputs must approach metric/semantic accuracy; integration with GIS/BIM and regulatory datasets
- Compliance and provenance tooling for synthetic media
- Sectors: policy, platforms, media governance
- Use cases:
- Standardized tests for “world-modeling quality” and consistency of synthetic videos as part of model disclosure or platform policy checks
- Tools/products/workflows:
- Auditing suites leveraging World-R1‑style reconstruction and multi-view critics to score models; metadata/provenance integration (e.g., C2PA)
- Assumptions/dependencies:
- Agreement on benchmarks and thresholds; performance variability across content classes; compute costs for auditing at scale
- Automated cinematic agents
- Sectors: entertainment tech, creator economy, education
- Use cases:
- Agents that draft storyboards and generate consistent multi-shot sequences (matching geometry across cuts and reframes)
- Tools/products/workflows:
- Multi-shot planners that stitch trajectories and maintain subject/background continuity with RL rewards spanning shots
- Assumptions/dependencies:
- Requires cross-shot identity/appearance control, memory across long contexts, and finer-grained motion semantics
- Improved dataset filtering and de-biasing via 3D-aware rewards
- Sectors: academia, model training platforms
- Use cases:
- Large-scale filtering of web video data for training by removing clips with severe multi-view inconsistency
- Tools/products/workflows:
- Pretraining data pipelines that run fast 3D-consistency proxies (e.g., lightweight 3DGS or depth priors) at scale
- Assumptions/dependencies:
- Efficient, low-cost approximations of the reward; careful handling to avoid over-filtering creative or non-rigid content
Cross-Cutting Dependencies and Assumptions
- Compute and cost: RL fine-tuning with Flow‑GRPO requires substantial GPU budgets for rollouts and reward computation; inference is not slower, but training is.
- Reward model availability: The approach depends on pre-trained 3D foundation models (e.g., Depth Anything 3/3DGS) and VLMs (e.g., Qwen‑VL) and aesthetic scorers (HPSv3); licensing and service access may constrain commercial deployment.
- Base model limits: World-R1 inherits capabilities and failure modes of the underlying video foundation model (e.g., resolution, fine-grained non-rigid motion, very long horizons).
- Camera control mechanism: Implicit camera conditioning via noise warping assumes reasonable parallax and a reference-depth heuristic; extreme depth variation may degrade control.
- Non-metric geometry: Outputs are geometrically consistent for viewing, not metrically accurate; applications requiring measurements must integrate CAD/BIM or photogrammetry.
- Data and prompts: Performance depends on the diversity and structure of the pure text dataset and prompt engineering quality; domain transfer may require targeted prompt sets and rewards.
- Ethical and policy context: As with other high-fidelity generators, provenance and disclosure mechanisms are advisable for public-facing deployments.
Glossary
- 3D-aware reward: A composite reward that measures geometric, appearance, and control consistency to enforce 3D fidelity during training. "We define the 3D-aware reward $R_{\text{3D}$ as a linear combination of three distinct consistency metrics tailored to geometry, appearance, and control accuracy:"
- 3D foundation models: Pre-trained models specialized for 3D understanding (e.g., depth, reconstruction) used to provide geometry-aware feedback. "Utilizing Flow-GRPO, we optimize the model using feedback from pre-trained 3D foundation models and vision-LLMs"
- 3D Gaussian Splatting (3DGS): A real-time 3D representation that models scenes as collections of anisotropic Gaussians for fast differentiable rendering. "We employ 3DGS~\cite{kerbl20233d,ye2025gsplat} to reconstruct the underlying scene geometry for each generated video."
- 3D parallax: Apparent displacement of scene points across views due to camera motion, used to distinguish true 3D structure from 2D drift. "We employ an analysis-by-synthesis strategy to distinguish between genuine 3D parallax and 2D content drift."
- 3D priors: Prior knowledge or constraints about 3D geometry injected into models to improve spatial consistency. "While existing methods attempt to inject 3D priors via architectural modifications, they often incur high computational costs and limit scalability."
- analysis-by-synthesis: An approach that evaluates generated outputs by reconstructing and re-rendering them to assess underlying structure. "We leverage the inherent consistency requirements of the real world to construct a robust reward mechanism via analysis-by-synthesis."
- bipartite graph: A graph with two disjoint sets of nodes where edges connect across sets; used here to discretize transport of noise. "which formulates noise warping as a mass transport problem on a bipartite graph induced by the flow field."
- clipped surrogate objective: The PPO-style objective that clips policy updates to stabilize reinforcement learning. "where $\mathcal{L}_{\text{clip}$ denotes the standard PPO-style clipped surrogate objective, and is the probability ratio between the current and old policies."
- denoise reduction strategy: A training acceleration technique that reduces denoising timesteps without sacrificing inference quality. "Furthermore, Flow-GRPO employs a denoise reduction strategy, using fewer timesteps during training to accelerate convergence without sacrificing inference quality."
- DiT architectures: Diffusion Transformer architectures used in modern video generation as a shift from U-Net designs. "While early approaches relied on U-Net-based diffusion architectures, recent state-of-the-art models~\cite{kong2024hunyuanvideo,yang2025cogvideox,wan2025wan} have shifted towards DiT architectures."
- discrete noise transport: A method to warp initial noise across frames while preserving variance, formulated as a discrete transport problem. "we adopt the discrete noise transport mechanism from Go-with-the-Flow~\cite{burgert2025go}, which formulates noise warping as a mass transport problem on a bipartite graph induced by the flow field."
- extrinsic matrices: Camera pose matrices specifying position and orientation in 3D space for each frame. "We first map the prompt to a deterministic sequence of camera extrinsic matrices "
- Flow-GRPO: An online RL framework adapting GRPO to flow-matching generative models by introducing stochasticity and policy updates. "Flow-GRPO~\cite{liu2025flow} enhances flow matching models by integrating online RL to optimize generation quality."
- Flow-GRPO-Fast: A variant of Flow-GRPO that injects noise into ODE trajectories to enable faster, stochastic training. "To further accelerate training, Flow-GRPO-Fast~\cite{liu2025flow} injects noise into the deterministic ODE trajectory at randomly selected intermediate steps, switching to SDE sampling."
- flow matching: A generative modeling framework that learns continuous-time velocity fields to transform noise into data. "Flow-GRPO~\cite{liu2025flow} enhances flow matching models by integrating online RL to optimize generation quality."
- fronto-parallel plane: A planar approximation of scene depth assumed to be parallel to the image plane at a fixed depth. "We adopt a pinhole camera model and approximate the scene geometry as a fronto-parallel plane located at a constant reference depth $z_{\text{ref}$."
- Go-With-The-Flow: A paradigm that controls motion by manipulating the initial noise and its transport, without extra modules. "Recognizing that foundation models are inherently insensitive to camera motion without guidance, our approach builds upon the Go-With-The-Flow~\cite{burgert2025go} paradigm."
- GRPO: Group Relative Policy Optimization, a critic-free policy gradient method that normalizes rewards within sampled groups. "GRPO~\cite{shao2024deepseekmath} has emerged as a more efficient alternative by eliminating the need for a critic network."
- HPSv3: A perceptual scoring metric that approximates human preference judgments for image aesthetic/quality assessment. "where denotes the HPSv3~\cite{ma2025hpsv3} score evaluated on each frame ."
- homography (planar homography): A projective transformation mapping between two views of a planar scene under a pinhole camera. "its projected coordinate in frame is derived via the planar homography induced by the relative camera motion:"
- implicit camera conditioning: Conditioning the model on camera motion by encoding trajectory information into the noise instead of using explicit pose inputs. "we introduce an implicit camera conditioning strategy that embeds trajectory priors directly into the latent noise."
- KL-divergence: A regularization term that penalizes deviation of the current policy from a reference policy in RL. "which incorporates a KL-divergence constraint to prevent deviation from the reference policy $\pi_{\text{ref}$:"
- latent noise: The initial random tensor in diffusion/flow models whose structure can influence generated trajectories. "we introduce an implicit camera conditioning strategy that embeds trajectory priors directly into the latent noise."
- LPIPS: A learned perceptual image patch similarity metric used to quantify perceptual differences between frames. "quantifying the similarity via the negated perceptual distance (~\cite{zhang2018unreasonable})."
- Markov Decision Process (MDP): A formalism for sequential decision-making defining states, actions, transitions, and rewards. "Flow-GRPO~\cite{liu2025flow} formulates the denoising process as a Markov Decision Process (MDP)."
- meta-view: A novel viewpoint used to render reconstructions for evaluating geometry beyond the original camera path. "Specifically, the geometric integrity term $\mathcal{S}_{\text{meta}$ is computed by rendering 3D Gaussians from a novel meta-view."
- Multi-View Consistency Score (MVCS): A reconstruction-independent metric that quantifies consistency across multiple views. "we additionally report a reconstruction-independent Multi-View Consistency Score (MVCS) in \cref{sec:additional_exp}."
- noise wrapping: A technique to inject structured motion into the noise by warping it according to projected flows/trajectories. "we synthesize a camera trajectory and embed it into the latent space via noise wrapping~\cite{burgert2025go} to achieve implicit camera conditioning."
- ordinary differential equation (ODE): A deterministic continuous-time equation used to define the flow sampler before adding stochasticity. "While standard flow matching relies on deterministic ODE solvers, RL requires stochasticity for effective exploration and advantage estimation."
- optical flow: A dense field of pixel-wise motion vectors between frames, here used to project trajectories into 2D. "we project the 3D camera trajectory into a sequence of 2D dense optical flow fields."
- pinhole camera model: A geometric camera model that projects 3D points onto a 2D image plane through a single point. "We adopt a pinhole camera model"
- PPO: Proximal Policy Optimization, a widely used RL algorithm employing clipped objective updates. "While PPO~\cite{schulman2017proximal} has been the standard for LLMs, it incurs prohibitive computational costs when applied to high-dimensional visual data."
- PSNR: Peak Signal-to-Noise Ratio, a reconstruction metric measuring fidelity between generated and re-rendered frames. "We measure the extent to which the video maintains structural coherence by calculating the PSNR, SSIM~\cite{wang2004image}, and LPIPS~\cite{zhang2018unreasonable}"
- reinforcement learning (RL): A learning paradigm where agents optimize behavior by interacting with an environment and receiving rewards. "RL~\cite{sutton1998reinforcement} has recently shown immense potential in aligning generative models with human preferences."
- reverse-time Stochastic Differential Equation (SDE): A stochastic formulation of the sampling dynamics introducing noise while preserving marginals. "Flow-GRPO converts the deterministic flow ODE () into a reverse-time Stochastic Differential Equation (SDE):"
- SDE sampling: Sampling procedure that uses stochastic dynamics (SDE) rather than deterministic ODEs to enable exploration. "Flow-GRPO-Fast~\cite{liu2025flow} injects noise into the deterministic ODE trajectory at randomly selected intermediate steps, switching to SDE sampling."
- semantic critics: Auxiliary models that assess semantic plausibility or alignment, used here to evaluate rendered novel views. "while employing vision-LLMs (VLMs)~\cite{Qwen3-VL,Qwen2.5-VL,Qwen2-VL,Qwen-VL} as semantic critics to evaluate the plausibility of rendered novel views (meta-views)."
- standard Normal distribution: The unit-variance, zero-mean Gaussian distribution preserved across frames after noise transport. "This discrete transport scheme ensures that camera-induced spatial structure is injected into the initial noise while maintaining its standard Normal distribution across frames."
- trajectory alignment: A measure of how closely the generated camera motion matches the specified target trajectory. "We compute a 3D-aware reward score based on meta-view evaluation, rendering fidelity, and trajectory alignment, combined with a general generation reward."
- trajectory priors: Prior information about intended camera motion embedded into the model to guide generation. "we introduce an implicit camera conditioning strategy that embeds trajectory priors directly into the latent noise."
- U-Net-based diffusion architectures: Early diffusion model backbones using U-Net networks for denoising, common before transformer-based designs. "While early approaches relied on U-Net-based diffusion architectures, recent state-of-the-art models~\cite{kong2024hunyuanvideo,yang2025cogvideox,wan2025wan} have shifted towards DiT architectures."
- VBench: A standardized evaluation benchmark for video generation assessing multiple quality dimensions. "Furthermore, we utilized VBench~\cite{huang2024vbench} as a standardized benchmark to evaluate general video quality."
- vision-LLMs (VLMs): Models that jointly process visual and textual inputs, used here to assess semantic consistency. "while employing vision-LLMs (VLMs)~\cite{Qwen3-VL,Qwen2.5-VL,Qwen2-VL,Qwen-VL} as semantic critics to evaluate the plausibility of rendered novel views (meta-views)."
- Wiener process: A continuous-time stochastic process representing Brownian motion, used as the noise term in SDEs. "where controls the noise level and denotes the Wiener process."
Collections
Sign up for free to add this paper to one or more collections.

