- The paper demonstrates that even the best AI agents achieve only 26% success, highlighting fundamental limits in closing the discovery-to-application gap.
- The study employs the SciCrafter benchmark in Minecraft to decompose key capacities such as knowledge identification, experimental discovery, and application.
- Structured scaffolds, including a scientist sub-agent and the Claim-Proof-Constraints-Example format, significantly enhance task performance.
Rigorous Evaluation of the Discovery-to-Application Loop in AI Agents via SciCrafter
Motivation and Benchmark Design
The paper "Can Current Agents Close the Discovery-to-Application Gap? A Case Study in Minecraft" (2604.24697) investigates the fundamental limitations of current AI agents in autonomously navigating the loop from scientific discovery to functional engineering application. Recognizing the prohibitive complexity gap between real-world scientific discovery and engineering—where timescales, resource requirements, and robotic manipulation dominate—the authors introduce SciCrafter, a Minecraft-based benchmark that abstracts these challenges. Tasks are constructed around redstone circuits; agents must design and build devices that ignite lamps in parameterized spatial and temporal patterns, requiring genuine causal mechanism discovery rather than recall of pre-existing solutions.
The evaluation spans multiple frontier LLMs (GPT-5.2, Gemini-3-Pro, Claude-Opus-4.5) embedded in a standardized code agent scaffold for reproducibility. Agents are challenged under scalable task difficulty, with device complexity and required environmental knowledge increasing nonlinearly across task variations and parameter levels.
Capacity Gap Decomposition and Quantitative Results
A central methodological contribution is the decomposition of the discovery-to-application loop into four distinct capacities:
- Knowledge Gap Identification: Recognizing relevant knowledge deficiencies and formulating targeted research questions;
- Experimental Discovery: Conducting systematic experiments to uncover hidden environmental dynamics;
- Knowledge Consolidation: Structuring findings into reusable, explicit forms for downstream application;
- Knowledge Application: The residual capacity attributed to spatial reasoning, code generation, and execution.
The authors operationalize this decomposition via diagnostic interventions: oracle hints, scientist sub-agents, and structured consolidation templates. The marginal gains from each intervention quantify the associated gap.
Baseline performance is sharply constrained: the best agent configuration (Gemini-3-Pro) achieves only 26.0% end-to-end task success, with all contemporary models plateauing at comparable levels regardless of parameter scale.
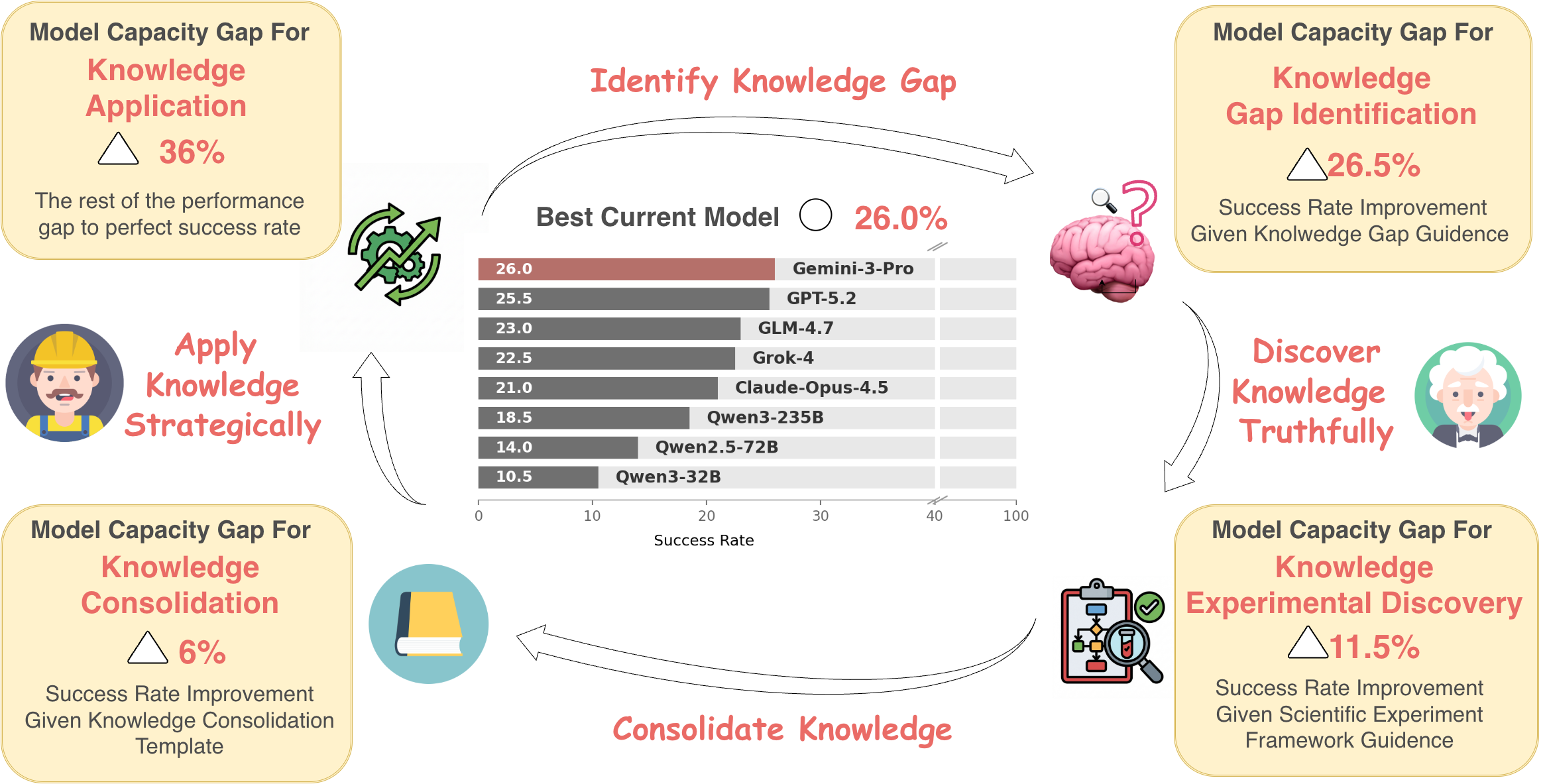
Figure 1: Decomposition of capacity gaps in the discovery-to-application loop; structured interventions reveal dimensions of agent failure and relative significance.
The introduction of oracle hints doubles performance to 52.5%; further integration of a scientist sub-agent yields 64.0%. Knowledge application remains the largest residual gap, yet strikingly, in frontier models the bottleneck shifts towards knowledge gap identification, as agents increasingly fail to raise the right inquiries rather than merely implement solutions.
Methodological Innovations: Scientist Sub-agent and Knowledge Consolidation
The scientist sub-agent is designed to systematize experimental discovery. Prompted with targeted questions, the sub-agent executes hypothesis-driven experiments, maintains detailed logs, and updates a shared knowledge book. The experiment and consolidation templates enforce rigorous scientific workflow, including explicit claims, proofs, constraints, and examples.
Ablation studies demonstrate that the choice of consolidation format is nontrivial; the "Claim-Proof-Constraints-Example" structure achieves a 64.0% success rate, outperforming free-form summaries and less rigorous schemas. This suggests that the structure and explicitness of memory critically modulate downstream reasoning and application performance.

Figure 2: Failure analysis and consolidation ablation; structured reporting and device snapshots reveal the impact of methodical scaffolds.
Qualitative failure analysis further substantiates the gap decomposition: failures cluster as structural (knowledge application), signal propagation (experimental discovery), and wire semantics (knowledge identification). For example, reversed repeater orientation results in catastrophic signal loss, evidencing application failures despite available knowledge.
Task Families, Curriculum, and Scaling Complexity
SciCrafter's task suite encompasses five task families probing spatial and temporal causal reasoning:
- Simultaneous Ignition,
- T-Junction Routing,
- Sequential Activation,
- Equal-Delay Distribution,
- Pulse Extension.
Each is parameterized with scalable difficulty, crossing discrete mechanism thresholds. The tasks force agents to discover and apply environmental mechanics such as signal attenuation, hub-and-branch topologies, repeater placement and delay compensation. General-purpose code agents interact via Model Context Protocol, facilitating reproducible experimentation and modular agent integration.


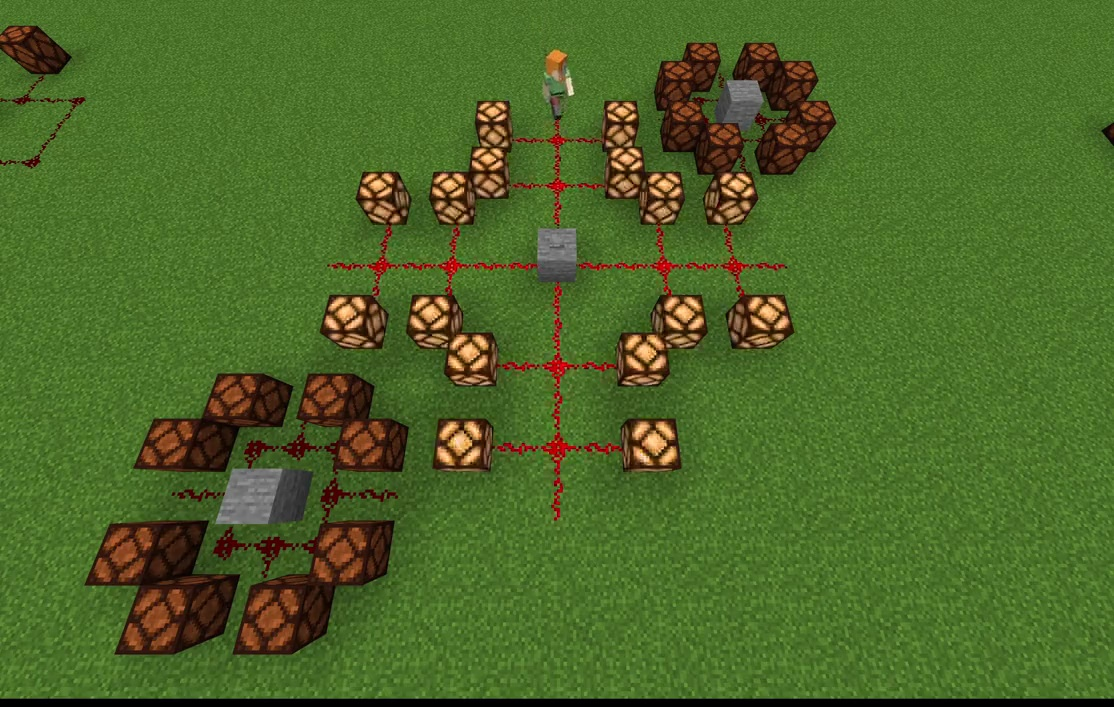

Figure 3: Reference device for 32-lamp simultaneous ignition; correct topology achieves full success, contrasting with failure cases.
Theoretical and Practical Implications
The paper's quantitative and qualitative findings are significant in several respects. First, increasing model scale does not bridge the discovery-to-application gap; fundamental agentic capabilities stall at low success rates. Second, capacity gap attribution reveals that, for frontier LLMs, the dominant bottleneck is shifting towards identifying the right scientific questions—supporting the assertion that scientific curiosity and inquiry precedent effective problem solving. Third, experimental discovery is highly sensitive to the presence of methodical scaffolds; even "known" scientific procedures require explicit templating to be robustly enacted by LLM agents.
The structure of the knowledge book is shown to critically affect performance, with the Claim-Proof-Constraints-Example format yielding substantial improvements. This highlights the necessity for structuring memory and knowledge in AI systems for successful downstream application—a topic tightly coupled to ongoing research in agentic memory architectures.
Future Directions
SciCrafter is released as an open testbed for evaluation and diagnosis of autonomous discovery–application in LLM agents. Future extensions include multimodal vision input for richer agent-environment interaction, randomized environment dynamics to prevent solution memorization, and agent architecture benchmarking disentangled from scaffold limitations.
The synthetic nature of Minecraft, albeit offering precise control and deterministic feedback, leaves open questions about transferability to real-world domains characterized by noisy observations, ambiguous causality, and unconstrained hypothesis spaces. Nevertheless, the diagnostic paradigm presented is instructive for agents operating in both scientific and engineering domains, with implications for cognitive architecture design and the evolution of general AI.
Conclusion
This work delivers a rigorous dissection of the discovery-to-application gap in AI agents, demonstrating that neither current LLMs nor state-of-the-art code agents can autonomously bridge this gap under realistic, scalable causal reasoning challenges. Marginal capacity attribution elucidates the shifting locus of bottlenecks, with curiosity and metacognitive problem identification emerging as the limiting factor in advanced models. The SciCrafter benchmark, together with methodical scaffolds, provides a critical foundation for future research aiming to enhance the autonomy and robustness of agentic scientific discovery and engineering.