MineNPC-Task: Task Suite for Memory-Aware Minecraft Agents
Abstract: We present \textsc{MineNPC-Task}, a user-authored benchmark and evaluation harness for testing memory-aware, mixed-initiative LLM agents in open-world \emph{Minecraft}. Rather than relying on synthetic prompts, tasks are elicited from formative and summative co-play with expert players, normalized into parametric templates with explicit preconditions and dependency structure, and paired with machine-checkable validators under a bounded-knowledge policy that forbids out-of-world shortcuts. The harness captures plan/act/memory events-including plan previews, targeted clarifications, memory reads and writes, precondition checks, and repair attempts and reports outcomes relative to the total number of attempted subtasks, derived from in-world evidence. As an initial snapshot, we instantiate the framework with GPT-4o and evaluate \textbf{216} subtasks across \textbf{8} experienced players. We observe recurring breakdown patterns in code execution, inventory/tool handling, referencing, and navigation, alongside recoveries supported by mixed-initiative clarifications and lightweight memory. Participants rated interaction quality and interface usability positively, while highlighting the need for stronger memory persistence across tasks. We release the complete task suite, validators, logs, and harness to support transparent, reproducible evaluation of future memory-aware embodied agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “MineNPC-Task: Task Suite for Memory-Aware Minecraft Agents”
1) What is this paper about?
This paper introduces a fair, reusable way to test AI helpers in Minecraft. These helpers are meant to act like smart teammates: they should make a plan, ask quick questions when they’re unsure, and remember useful information. The authors built a “task suite” and a test system that measures how well such AIs do on real player requests without letting them cheat.
2) What questions are the researchers trying to answer?
The paper focuses on simple, practical questions:
- How can we fairly test AI helpers in Minecraft using only what a normal player can see and do?
- What kinds of tasks do real players ask for (not made-up lab prompts)?
- Where do AI helpers struggle, and what helps them recover?
- Does letting the AI ask short clarifying questions and use lightweight memory make a difference?
- How can we make results transparent and easy for other people to repeat and compare?
3) How did they do it?
The authors built a test system that runs inside Minecraft using Mineflayer (a public tool to make Minecraft bots that use the same in-game actions as players). They collected real requests by playing with experienced Minecraft players and turned those requests into simple, reusable task templates.
Here’s how the system works, step by step:
- Plan preview: The AI shows a short plan (about 3–5 steps) before acting, like a checklist.
- Clarifying question: If the plan has missing details (for example, “Which pickaxe?” or “How far should I search?”), the AI asks just one targeted, context-aware question.
- Action via code: The AI writes small bits of JavaScript that call Mineflayer’s public APIs to do things like navigate, mine, craft, and place blocks. A quick reviewer checks the code and limits retries to avoid endless loops.
- Judge from in-game evidence: A simple “validator” decides pass or fail using only what’s visible inside the game—changes to inventory, tools, position, nearby blocks/entities, and recent chat. No hidden shortcuts, no admin commands.
- Memory: The AI keeps lightweight notes, like named places (landmarks), items (artifacts), preferences (e.g., “search within 10 blocks”), and what went wrong or right. Each memory has a “how we learned it” tag, such as told, seen, or inferred.
- Logs for reproducibility: The system records plans, clarifications, code tries, successes/failures, and memory reads/writes so other researchers can repeat tests and compare models fairly.
Think of it like playing with a careful teammate who:
- Shows you the plan,
- Asks one smart follow-up if needed,
- Plays by the same rules you do,
- Has a referee that judges only by what actually happened,
- Keeps simple notes to do better next time.
4) What did they find, and why does it matter?
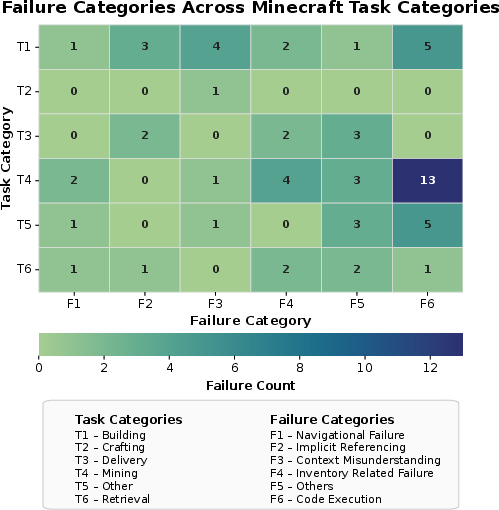
They tested the setup with GPT-4o during live co-play with 8 experienced players. Across 44 tasks made by players (216 smaller subtasks), about 33% of the subtasks failed (71 out of 216). Common trouble spots included:
- Code/execution issues: wrong parameters or small mistakes that stopped actions.
- Inventory/tool handling: trying to use the wrong tool or not having the right item.
- Referencing errors: saying “this block” or “over there” without a shared viewpoint.
- Navigation problems: getting lost or struggling to reach a place.
- Context misunderstandings: not fully grasping what the player meant.
Good news: asking short clarifying questions and using simple memory often helped the AI recover or improve. Players generally liked the interaction and the interface, and they found memory helpful—but they wanted the AI to remember “fixes” more persistently across tasks and sessions.
Why this matters: The results highlight realistic challenges that AI game teammates face. By revealing where and why things break, the benchmark helps researchers build better, more reliable, and more understandable AI helpers. Because the tests are fair and repeatable, other teams can use the same setup to compare different models without hidden advantages.
5) What is the impact, and what comes next?
This work provides a solid foundation to improve AI teammates in open-world games:
- Fair comparisons: Because the system uses only public in-game tools and visible evidence, researchers can compare different AIs under the same rules.
- Better design: The findings encourage designs that plan in small steps, ask questions when unsure, and use memory wisely.
- Real tasks: Using player-authored requests makes the tests more realistic and useful for actual gameplay.
The authors plan to:
- Test more AI models under the same setup,
- Add more tasks and variations,
- Report richer metrics (like partial credit, time, distance, and resource costs),
- Improve pre-action checks and memory persistence,
- Release artifacts so the community can reproduce results and expand the benchmark.
Overall, this paper helps turn AI helpers from “guessers” into “teammates” who plan, ask, remember, and learn—without cheating—making them more trustworthy and useful for players.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s current benchmark and evaluation snapshot.
- External validity: How well does the Mineflayer-bounded setup generalize to other game engines, sensing/action envelopes, or modded servers that expose different APIs and affordances?
- Cross-model comparability: Without ablations or baselines, it is unknown how different LLMs (sizes, architectures, VLM vs. text-only), decoding settings, or prompting strategies affect outcomes under identical constraints.
- Component contributions: The causal impact of design choices (plan previews, single-turn clarification, lightweight reviewer, retry cap K, memory store) is not quantified via controlled ablations.
- Task representativeness: The expert-authored, modest task pool may under-cover key gameplay facets (e.g., Nether/End, redstone, automation, villager trading, complex combat, multi-session megabuilds).
- Template fidelity and bias: It is unclear how normalization into parametric templates alters user-authored intent or introduces hidden biases in slot structure, defaults, and dependency graphs.
- Validator validity and reliability: Pass/fail judgments based on bounded evidence may yield false positives/negatives; no inter-rater or cross-implementation agreement, error analysis, or sensitivity to noisy state is reported.
- Metric granularity: Lack of partial credit and efficiency metrics (time, steps, distance, resource cost, damage taken) obscures meaningful progress and trade-offs across approaches.
- Variance quantification: Run-to-run variability from pathing, chunk loading, and world topology is acknowledged but not quantified (e.g., seeds, confidence intervals, effect sizes, power analysis).
- Policy enforcement robustness: How reliably does the harness detect and prevent subtle bounded-knowledge violations (e.g., implicit large-area scans via movement, latent map knowledge in code)?
- Code reviewer coverage: The lightweight review is not characterized for recall/precision on common API/parameter faults; no static checks, unit tests, or fuzzing to expand failure detection.
- Memory effectiveness: The contribution of the typed memory store (hits/misses, staleness handling, provenance effects) to success and efficiency is not measured or stress-tested across sessions.
- Memory persistence and scope: Long-term, cross-task/session generalization of corrections/preferences is limited; policies for consolidation, decay, and conflict resolution are unspecified.
- Clarification policy: The “single targeted question” constraint may be suboptimal; the trade-offs of multi-turn clarification strategies on success, latency, and user burden remain unexplored.
- Deictic grounding: Failures on references like “the block I’m looking at” suggest missing egocentric/shared-attention grounding; integration of richer VLM perception or joint attention mechanisms is open.
- Navigation and mapping: With no global map/seed introspection, what lightweight mapping (e.g., topological landmarks, SLAM-lite) yields robust navigation while respecting the policy?
- Tool/affordance reasoning: Recurrent tool misuse indicates a need for robust affordance models (durability, variants, prerequisites); how to couple recipe graphs with real-time inventory constraints?
- Failure taxonomy to root causes: Current labels are symptomatic; a causal mapping to pipeline stages (routing, planning, code-gen, review, execution, judging, memory) and cross-annotator reliability are missing.
- Aggregation and fairness: Subtask-level denominators may bias against longer decompositions; principled aggregation to task-level scores and normalization across task difficulty is not defined.
- Human factors and sample size: Small-N (8 experts) with potential learning/Hawthorne effects; no controlled comparisons (e.g., with/without memory visibility, different UI cues) or demographic diversity analysis.
- Language robustness: Generalization to non-English, slang, typos, and code-switching is unknown; no tests for multilingual or noisy instruction robustness.
- Adversarial and OOD robustness: The benchmark lacks targeted probes for adversarial prompts, misleading context, or out-of-distribution goals and environments.
- Cost/latency trade-offs: Token usage is logged but not analyzed; how latency, retries, and model cost impact UX and success remains unmeasured.
- Repair-loop efficacy: Criteria for when to retry, replan, or escalate are heuristic; success rates and optimal policies for bounded repair and partial replans are unstudied.
- Leaderboard governance: While artifacts are released, standardized seeds, scoring scripts, submission protocols, and governance for a public leaderboard are not specified.
- Dependency on API coverage: Tasks requiring behaviors outside Mineflayer’s public APIs are excluded; how to benchmark such capabilities fairly is open.
- Evidence sources for judging: The evaluator references an NPC camera frame alongside state deltas; the exact role of visual frames in machine judgment vs. human oversight needs clarification and tests for drift.
- Data and privacy: Scope and licensing of released logs (e.g., screen/audio), plus privacy/safety handling in human dialogues, are not detailed.
- Training-data contamination: Potential prior exposure of GPT-4o to Mineflayer docs and Minecraft agent prompts is unaddressed; policies for mitigating/assessing contamination effects are needed.
- Safety and ethics: Guardrails for destructive actions, griefing, or risky behaviors, and content moderation in chat, are not formally evaluated.
- Multi-agent/team settings: The framework targets single-agent co-play; extensions to multi-agent coordination, role allocation, and shared memory are open.
Glossary
- AgentBench: A benchmark for evaluating LLM agents on open-ended tool use and web interaction. "LLM agent evaluations study open ended tool use and web interaction (AgentBench, WebArena) \citep{agentbench2023,webarena2023}"
- ALFRED: A vision–language embodied benchmark for multistep instruction following in household environments. "Suites that span vision, language, and action such as ALFRED \citep{shridhar2020alfred}, TEACh \cite{teach2021}, and EmbodiedQA \citep{das2018embodiedqa}"
- ALFWorld: A text-centric environment that blends TextWorld with embodied task settings for training and evaluation. "Text centric environments and curricula such as TextWorld, ALFWorld, ScienceWorld, and BabyAI offer controllable abstractions for reasoning, exploration, and sample efficiency \citep{textworld2018,alfworld2021,scienceworld2022,babyai2019}."
- anthropomorphism: Attribution of human traits to non-human agents, used to frame evaluation in game worlds. "Complementary literatures on NPC believability, social presence, and anthropomorphism provide additional frames for evaluating expectations in game worlds \citep{articleonnpdbeilievability, Nowak2003}."
- BabyAI: A gridworld platform and curriculum for language-guided agent training. "Text centric environments and curricula such as TextWorld, ALFWorld, ScienceWorld, and BabyAI offer controllable abstractions for reasoning, exploration, and sample efficiency \citep{textworld2018,alfworld2021,scienceworld2022,babyai2019}."
- BEHAVIOR: A simulator and benchmark emphasizing program-like decompositions of everyday activities and structured evaluation. "while BEHAVIOR and VirtualHome emphasize program like decompositions of everyday activities and structured evaluation protocols \citep{behavior2021,puig2018virtualhome}."
- bounded-knowledge policy: A rule that limits agent perception/action to public in-game interfaces and forbids privileged shortcuts. "A bounded-knowledge policy forbids admin commands (e.g., /give, /teleport), global map/seed introspection, and bulk scans beyond loaded chunks; attempts that trigger a forbidden call are marked invalid."
- co-play: Live collaborative gameplay with human experts used to elicit natural tasks. "tasks are elicited from formative and summative co-play with expert players"
- composable tasks: Tasks designed to be combined or built from components in open-world evaluations. "introducing scalable, composable tasks in open-world environments"
- deictic phrasing: Context-dependent references (e.g., “this”, “that”) tied to the speaker’s perspective. "deictic phrasing such as “the block I'm looking at.”"
- dynamic memory consolidation: The process by which agents reorganize and stabilize experiences into durable memory. "Recent LLM systems investigate experience distillation and dynamic memory consolidation for situated tasks \citep{sarch2024vlm, Hou_2024}."
- EmbodiedQA: A benchmark where agents answer questions through embodied interaction in simulated environments. "Suites that span vision, language, and action such as ALFRED \citep{shridhar2020alfred}, TEACh \cite{teach2021}, and EmbodiedQA \citep{das2018embodiedqa}"
- egocentric references: References defined relative to the agent’s current viewpoint or camera. "Add focused tests for egocentric references and tool–affordance errors;"
- evaluation harness: A standardized framework for running, logging, and judging agent behavior. "We present MineNPC-Task, a user-authored benchmark and evaluation harness for testing memory-aware, mixed-initiative LLM agents in open-world Minecraft."
- experience distillation: Techniques to compress and reuse knowledge from prior interactions. "Recent LLM systems investigate experience distillation and dynamic memory consolidation for situated tasks \citep{sarch2024vlm, Hou_2024}."
- global map/seed introspection: Reading the world’s generation parameters or global maps beyond normal in-game observation. "A bounded-knowledge policy forbids admin commands (e.g., /give, /teleport), global map/seed introspection, and bulk scans beyond loaded chunks;"
- Habitat: A high-performance simulator for embodied AI tasks and reproducible loops. "Platform efforts including Habitat, iTHOR, and ProcTHOR provide large scale scene generation and reproducible perception and action loops \citep{savva2019habitat,ithor,procthor2022}"
- iTHOR: An interactive extension of the THOR environment supporting embodied tasks. "Platform efforts including Habitat, iTHOR, and ProcTHOR provide large scale scene generation and reproducible perception and action loops \citep{savva2019habitat,ithor,procthor2022}"
- in-world evidence: Observable state changes available inside the game used to judge success. "and judges only from in-world evidence with lightweight memory."
- intent routing: Parsing user input into structured intents and parameters for planning/execution. "Intent routing parses chat into {intent, slots, confidence}."
- loaded chunks: The regions of a Minecraft world currently simulated/visible to the client. "nearby entities/blocks within loaded chunks"
- Malmo: A platform/interface for AI experimentation within Minecraft. "Malmo established a widely used interface and experimental substrate \citep{johnson2016the,hofmann2019minecraft}."
- MCU benchmark: Minecraft Universe; a benchmark emphasizing scalable, composable tasks. "Recent efforts, such as the Minecraft Universe (MCU) benchmark~\cite{MCU2023,MCU2023arxiv}, move in this direction by introducing scalable, composable tasks"
- memory persistence: The durability of stored context across tasks and time. "highlighting the need for stronger memory persistence across tasks."
- MineDojo: A platform/dataset aggregating internet-scale Minecraft knowledge and goals. "MineDojo aggregates cross-modal knowledge and goals \citep{fan2022minedojo};"
- Mineflayer: A JavaScript API for Minecraft bots used to constrain perception and actions to public interfaces. "The benchmark runs inside a Mineflayer envelope so perception and action are limited to public, in-game APIs;"
- mixed-initiative: An interaction style where both human and agent plan, clarify, and act. "memory-aware, mixed-initiative LLM agents in Minecraft."
- model-agnostic: Designed to work across different models without special assumptions. "The framework is model-agnostic: an LLM proposes a short plan, asks at most one targeted clarifying question"
- nearest- queries: A retrieval method that returns the most similar memory items to the current context. "can be retrieved with nearest- queries scoped to the current task."
- parametric templates: Task blueprints with slots and explicit preconditions for instantiation. "normalized into parametric templates with explicit preconditions and dependency structure"
- partial replan: Recomputing only the failing part of a plan after a breakdown. "on failure it offers a bounded repair and partial replan."
- plan preview: A brief, legible summary of intended steps shown before execution. "The agent presents a brief plan preview that breaks the request into a handful of subtasks,"
- ProcTHOR: A procedurally generated extension of THOR for large-scale embodied tasks. "Platform efforts including Habitat, iTHOR, and ProcTHOR provide large scale scene generation and reproducible perception and action loops \citep{savva2019habitat,ithor,procthor2022}"
- provenance: Recorded origin of a memory item (e.g., told, seen, inferred). "stores the preference with provenance told."
- ReAct: A prompting strategy that interleaves reasoning traces with tool calls. "prompting methods such as ReAct integrate reasoning traces with tool calls \citep{yaoproreact2023}."
- skill library: A collection of reusable programmatic skills the agent can invoke during gameplay. "against Mineflayer APIs and a skill library;"
- slot binding: Resolving unspecified parameters in a task via clarification or context. "often requiring dialog to bind underspecified slots."
- slot parameters: Named fields in a task template that must be filled before execution. "a small set of slot parameters"
- STEVE-1: A generative model for text-to-behavior in Minecraft. "STEVE-1 targets text-to-behavior generation \citep{lifshitz2024steve1generativemodeltexttobehavior};"
- TaskFeedback: A structured record from the evaluator indicating success/failure, rationale, and suggestions. "The evaluator produces a structured TaskFeedback record that states success or failure"
- task(request): A routing label denoting actionable user input parsed from chat. "Chat request routed to task(request)."
- TextWorld: A framework for training/evaluating agents in text-based games. "Text centric environments and curricula such as TextWorld, ALFWorld, ScienceWorld, and BabyAI"
- tool–affordance errors: Mistakes due to mismatches between tools and their intended capabilities/actions. "Add focused tests for egocentric references and tool–affordance errors;"
- typed store: A memory subsystem with typed entries (landmarks, artifacts, preferences) and provenance. "A simple typed store persists named landmarks, artifacts, preferences, and records of commitments/breakdowns."
- validator-backed outcomes: Judgments supported by simple validators that consume bounded, in-world evidence. "produces validator-backed outcomes suitable for controlled comparisons across LLMs."
- VirtualHome: A simulator modeling household activities with program-like task specifications. "while BEHAVIOR and VirtualHome emphasize program like decompositions of everyday activities"
- Voyager: An LLM-powered agent that autonomously acquires and reuses skills in open-ended play. "Voyager demonstrates autonomous skill acquisition and reuse in open-ended play \citep{wang2023voyager};"
- WebArena: A benchmark for evaluating LLM agents on web interaction tasks. "LLM agent evaluations study open ended tool use and web interaction (AgentBench, WebArena) \citep{agentbench2023,webarena2023}"
Practical Applications
Immediate Applications
Below are specific, deployable applications that can be realized with the released MineNPC-Task suite, harness, validators, and design patterns as-is or with minimal adaptation.
- [Industry] Internal benchmarking of LLM-powered NPCs (Games)
- What: Use MineNPC-Task’s bounded-knowledge, validator-backed harness to compare NPC or co-pilot agents across model versions and prompts.
- Tools/products/workflows: CI-integrated benchmark runs; per-subtask reports; failure heatmaps; regression gates before game updates.
- Dependencies/assumptions: Access to Mineflayer/Minecraft server; LLM API; teams accept no-admin, public-API constraints.
- [Industry] QA automation for gameplay features (Games)
- What: Turn common player tasks (build, farm, mine) into automated regression suites to detect breakages in navigation, crafting, inventory handling.
- Tools/products/workflows: Scheduled bot runs; validator dashboards; “golden” task templates; diff-based run comparisons.
- Dependencies/assumptions: Stable validator specs; minimal world seeding variance; reproducible server configurations.
- [Industry + Academia] Agent evaluation methodology transfer to web/tool agents (Software)
- What: Port “plan-preview → single-turn clarification → bounded execution → validator judgment” to web automation and tool-use tasks (e.g., WebArena-style setups).
- Tools/products/workflows: Validator SDK for web state; plan-delta logging; bounded-repair UI components.
- Dependencies/assumptions: Clear, machine-checkable success criteria; sandboxed, observable tools; no hidden APIs.
- [Industry] Interaction design patterns for assistants (Software/HCI)
- What: Adopt short, legible plans; exactly-one targeted clarification; bounded repair prompts; memory with provenance in consumer or enterprise assistants.
- Tools/products/workflows: UI widgets for plan previews; memory viewers; “ask-to-act” confirmations; scoped preference stores.
- Dependencies/assumptions: User acceptance of clarifying questions; product telemetry/audit needs; privacy controls for memory.
- [Industry] Trust, safety, and audit instrumentation for agents (Software/Games)
- What: Use bounded-knowledge policies, validator-only judging, and structured TaskFeedback to enforce safe capabilities and auditable outcomes.
- Tools/products/workflows: Policy enforcement layer; capability whitelists; post-hoc runbooks; failure rationales.
- Dependencies/assumptions: Clear capability boundaries; organizational buy-in for audit trails.
- [Academia] Reproducible research on embodied agents (AI/Robotics-in-sim)
- What: Run controlled studies on planning, memory, and mixed-initiative behavior with publicly released tasks, prompts, validators, and logs.
- Tools/products/workflows: Baseline replications; ablation studies; cross-model leaderboards under identical envelopes.
- Dependencies/assumptions: Community reuse of the public-API contract; stable task templates.
- [Academia] HCI studies on co-play, memory visibility, and transparency (HCI)
- What: Investigate how plan previews, clarifications, and surfaced memory affect trust, efficiency, and error recovery.
- Tools/products/workflows: User studies; Likert measures; manipulation of memory visibility and repair options.
- Dependencies/assumptions: IRB and ethics approvals; participant recruitment; consistent world setups.
- [Education] Course modules and capstone projects (CS/AI/HCI)
- What: Use the harness for labs on grounded tool use, planning, evaluation design, and failure analysis.
- Tools/products/workflows: Starter kits with task templates and validators; rubric-aligned metrics (success/attempts, clarifications).
- Dependencies/assumptions: Classroom compute; Minecraft or analogous sandbox access.
- [Industry + Daily life] Community “AI helper NPC” with bounded powers (Games/Accessibility)
- What: Deploy a server-side helper NPC that plans, asks one question when needed, and acts safely (no admin commands).
- Tools/products/workflows: Server plugin; memory of landmarks/artifacts; player-configurable capability toggles.
- Dependencies/assumptions: Moderation and abuse prevention; costs of LLM inference at scale.
- [Industry] Data-driven model/product improvement via failure taxonomies (Software/Games)
- What: Mine logs for recurrent breakdowns (code execution, inventory/tool misuse, navigation) to prioritize prompting, tool APIs, or static checks.
- Tools/products/workflows: Error taxonomy dashboards; pre-execution static checklists; skill-library hardening.
- Dependencies/assumptions: Representative task mix; robust tagging of failure categories.
- [Policy] Internal evaluation standards for agent deployments (Compliance/Risk)
- What: Adopt “no privileged shortcuts,” “public evidence only,” and “validator-backed outcomes” as pre-release gates for agentic features.
- Tools/products/workflows: Checklists; capability audits; reproducibility playbooks.
- Dependencies/assumptions: Policy alignment; ability to sandbox agent capabilities.
Long-Term Applications
These directions require further research, porting, scaling, or engineering beyond the current Minecraft/Mineflayer envelope.
- [Industry + Academia] Cross-engine, cross-domain embodied-agent standard (Games/Sim)
- What: Generalize the bounded-API + validator framework to Unity/Unreal/Roblox and to synthetic homes/warehouses.
- Tools/products/workflows: Engine adapters; domain-specific validator packs; public leaderboards.
- Dependencies/assumptions: Public, auditable action interfaces; standardized world seeding; community governance.
- [Robotics] Memory-aware, mixed-initiative robots with safety gates (Home/Warehouse)
- What: Transfer “plan-preview + targeted clarification + validator checks + bounded repair” to mobile manipulators in homes or logistics.
- Tools/products/workflows: Pre-execution safety validators; egocentric reference resolution; human-in-the-loop repair UIs.
- Dependencies/assumptions: Reliable perception; safe low-level controllers; simulators for pretraining; rigorous safety certification.
- [Daily life] Smart-home and AR assistants that ask before acting (Consumer IoT/AR)
- What: Assistants that surface short plans, ask one precise question for missing slots, and execute with bounded device permissions.
- Tools/products/workflows: Permission scoping; provenance-tagged preferences; on-device validators (e.g., energy/time caps).
- Dependencies/assumptions: Ecosystem APIs; user consent; privacy-preserving memory.
- [Healthcare] Mixed-initiative clinical aides in simulation and documentation (Health IT)
- What: Apply clarification-first plan previews and validator-like checks to order entry, documentation, and simulation training environments.
- Tools/products/workflows: “No-privilege” sandboxes; structured validators (allergy, dose, interaction checks); audit logging.
- Dependencies/assumptions: Medical-grade validation; regulatory compliance; human oversight; domain-tuned models.
- [Enterprise] Bounded-permission process automations with audit trails (IT/DevOps/Back office)
- What: Agents that plan, request missing parameters, and operate within least-privilege envelopes across tickets, runbooks, and CI/CD.
- Tools/products/workflows: Agent IDE with planner templates; capability policies; validator-based success metrics.
- Dependencies/assumptions: Tooling observability; RBAC integration; change-management approvals.
- [Education] Adaptive sandbox tutors with persistent, provenance-tagged memory (EdTech)
- What: Long-horizon projects in learning games/sims where the tutor remembers student preferences and constraints, surfacing them transparently.
- Tools/products/workflows: Memory viewers; task templates aligned to curricula; partial-credit validators.
- Dependencies/assumptions: Student privacy; on-device or federated memory; robust scaffolding.
- [Industry] Agent IDE/platform productization (Software)
- What: Package planner templates, code-gen reviewer, validator SDK, memory store with provenance, telemetry dashboard, and repair-loop UI into a platform.
- Tools/products/workflows: Plugins for popular stacks (browser, CLI, RPA); marketplace for validator/task packs.
- Dependencies/assumptions: Sustained developer ecosystem; model-agnostic adapters; cost controls.
- [Policy/Standards] Certification schemes for agentic systems (Safety/Compliance)
- What: Define certification criteria based on “public evidence only,” bounded capabilities, reproducible validators, and auditable logs.
- Tools/products/workflows: Third-party test suites; conformance reports; red-team protocols for reference resolution and memory staleness.
- Dependencies/assumptions: Multi-stakeholder standards bodies; legal frameworks; sector-specific validator catalogs.
- [Industry + Academia] Skill libraries with embedded validators and tests (Software/Robotics)
- What: Distribute reusable skills (navigate, mine/craft, fetch/return, pick-and-place) that ship with tests and task templates.
- Tools/products/workflows: Versioned skill registries; continuous evaluation; “no hidden shortcuts” linting.
- Dependencies/assumptions: Community contribution norms; semantic versioning; cross-domain abstractions.
- [Research] Robustness probes for egocentric references and memory staleness (AI/HCI)
- What: Expand targeted benchmarks to diagnose deictic language errors, stale preferences, and recovery behaviors.
- Tools/products/workflows: Focused micro-tasks; UI affordances for memory surfacing/confirmation; ablation suites.
- Dependencies/assumptions: Stable data collection; multi-model comparisons; annotated error corpora.
Notes on feasibility and transfer
- Model performance is a bottleneck: success depends on LLM reliability in code generation, tool use, and clarification quality.
- Public-API envelopes are essential: transferring to new domains requires auditable, bounded action/observation interfaces.
- Validators drive reproducibility: each domain needs simple, machine-checkable success criteria; partial-credit and efficiency metrics may be required for maturity.
- Memory must be privacy-safe and provenance-aware: provenance tags (seen/told/inferred) help with trust but require explicit consent and retention policies.
- Human-in-the-loop remains critical: bounded repair loops and explicit approvals are key to safety in high-stakes environments.
Collections
Sign up for free to add this paper to one or more collections.