Kwai Summary Attention Technical Report
Abstract: Long-context ability, has become one of the most important iteration direction of next-generation LLMs, particularly in semantic understanding/reasoning, code agentic intelligence and recommendation system. However, the standard softmax attention exhibits quadratic time complexity with respect to sequence length. As the sequence length increases, this incurs substantial overhead in long-context settings, leading the training and inference costs of extremely long sequences deteriorate rapidly. Existing solutions mitigate this issue through two technique routings: i) Reducing the KV cache per layer, such as from the head-level compression GQA, and the embedding dimension-level compression MLA, but the KV cache remains linearly dependent on the sequence length at a 1:1 ratio. ii) Interleaving with KV Cache friendly architecture, such as local attention SWA, linear kernel GDN, but often involve trade-offs among KV Cache and long-context modeling effectiveness. Besides the two technique routings, we argue that there exists an intermediate path not well explored: {Maintaining a linear relationship between the KV cache and sequence length, but performing semantic-level compression through a specific ratio $k$}. This $O(n/k)$ path does not pursue a ``minimum KV cache'', but rather trades acceptable memory costs for complete, referential, and interpretable retention of long distant dependency. Motivated by this, we propose Kwai Summary Attention (KSA), a novel attention mechanism that reduces sequence modeling cost by compressing historical contexts into learnable summary tokens.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for LLMs to handle very long texts without running out of memory or getting too slow. The method is called Kwai Summary Attention (KSA). It helps the model “remember” earlier parts of a long document by creating short summaries along the way, so the model doesn’t have to store every detail from start to finish.
What questions were the researchers asking?
The team focused on a simple problem: How can we make LLMs read and reason over very long texts (tens of thousands to hundreds of thousands of tokens) without using too much memory or losing important information?
In everyday terms:
- Can we keep the “important parts” of earlier text without keeping everything?
- Can we do this in a way that still lets the model understand far-away details (like a note from the first chapter when you are reading the last chapter)?
- Can this work well with other memory-saving tricks people already use?
How does their method work?
Think of reading a huge book and putting a sticky note at the end of every few pages that summarizes the key points. When you get far into the book, you won’t reread every page—you’ll skim the sticky notes to remember what happened earlier, and you’ll carefully read only the nearby pages.
That’s KSA in a nutshell:
- Summary tokens (the “sticky notes”):
- Every k text tokens (for example, every 8 tokens), the model inserts a special “summary token.”
- That summary token looks only at its chunk (those k tokens) and learns a compact summary.
- Over time, you get a line of summaries that represent the entire past.
- Text tokens (the “current pages”):
- Each new text token looks back at:
- nearby recent text (for fine detail), and
- earlier summary tokens (for far-away memory).
- It does not read every past token—just local text plus earlier summaries.
- Sliding chunk attention (clean information flow):
- The model moves in chunks, not one token at a time, so it doesn’t accidentally “half-see” a chunk.
- A past chunk is either fully visible as text (if it’s nearby) or fully summarized (if it’s farther away). Nothing important gets lost at the boundary.
- Efficient “memory shelf” design (for speed):
- The stored information (keys/values the model needs to reuse) is laid out like neatly organized shelves.
- This lets the model grab everything it needs in one quick read, instead of lots of small, slow reads.
Why this helps:
- Instead of storing information about every single token forever, KSA stores summaries every k tokens. That reduces storage roughly by a factor of k while still keeping the big picture.
- It keeps local detail where it matters (nearby tokens) and uses summaries for long-range context.
What did they find?
The researchers tested KSA against other methods on both long-context tasks and general benchmarks (knowledge, math, and coding).
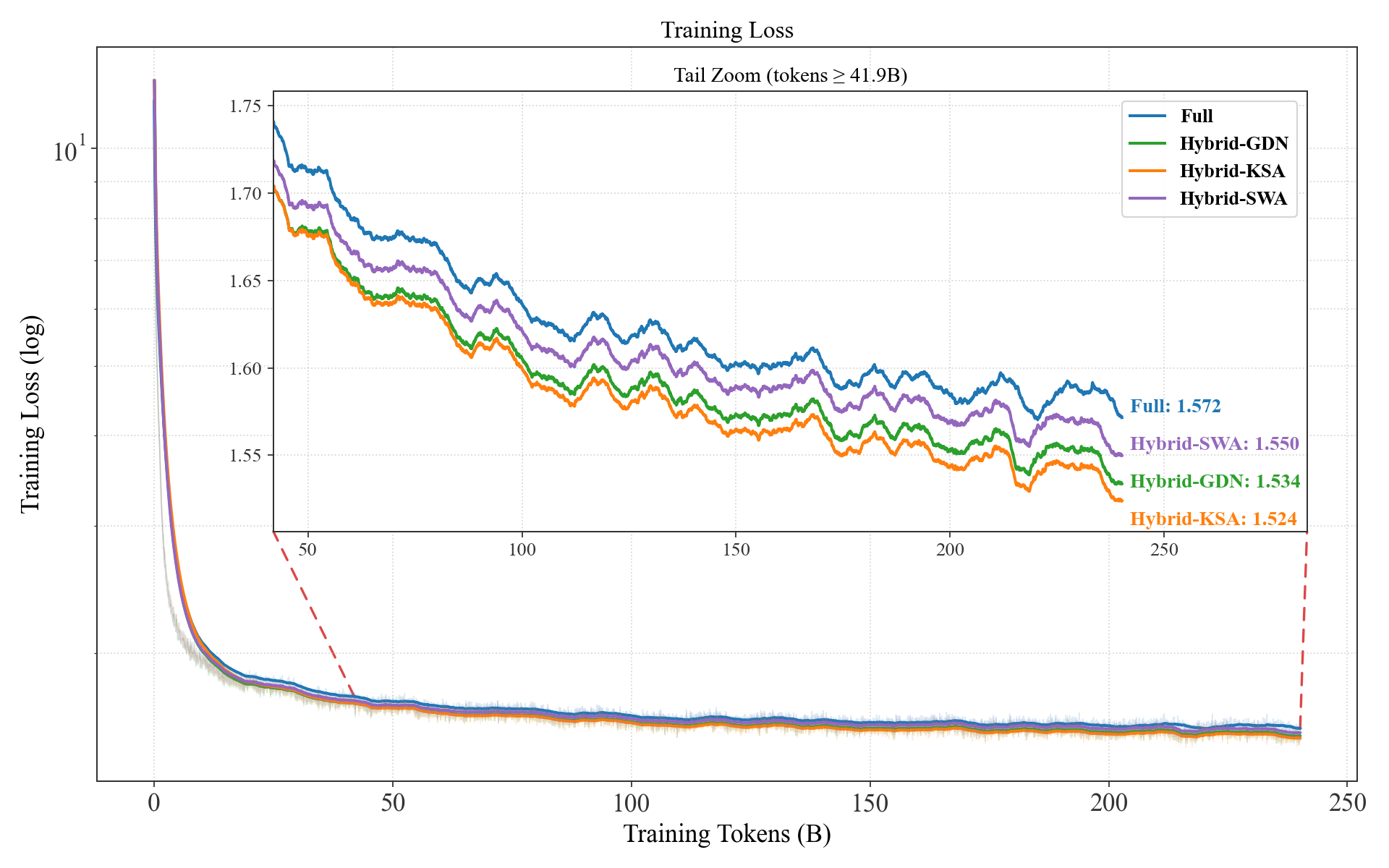
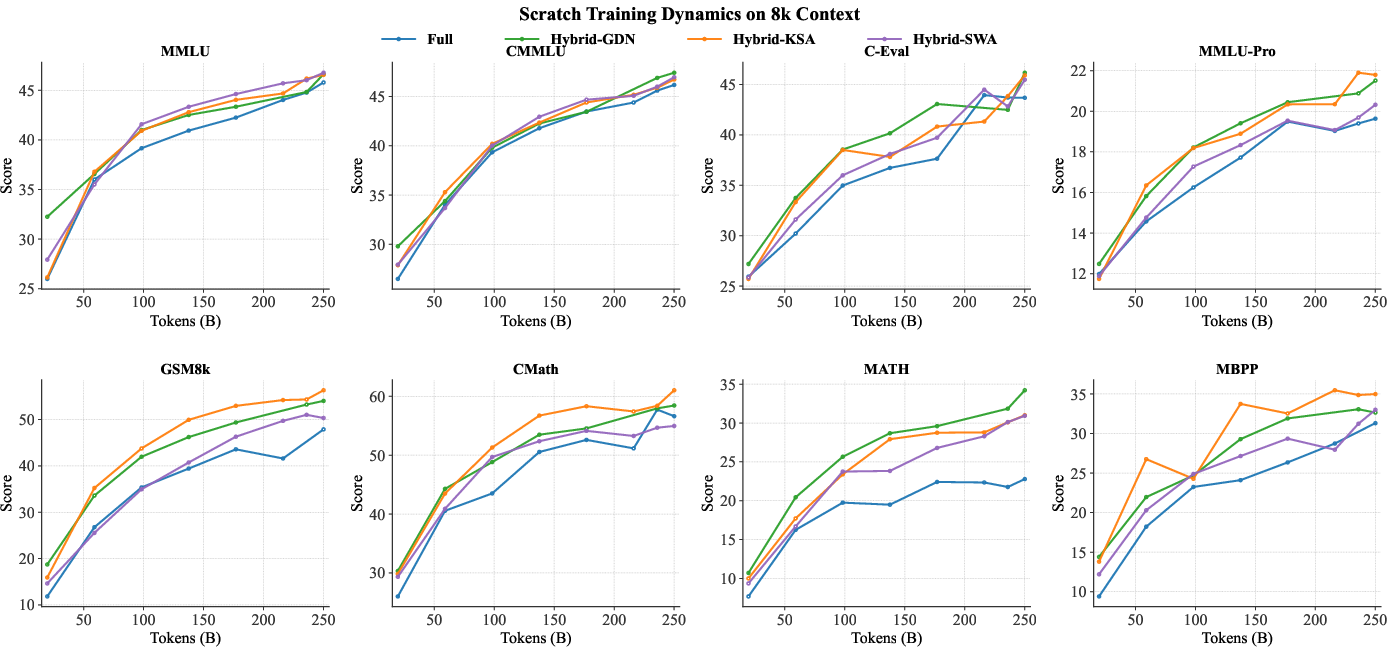
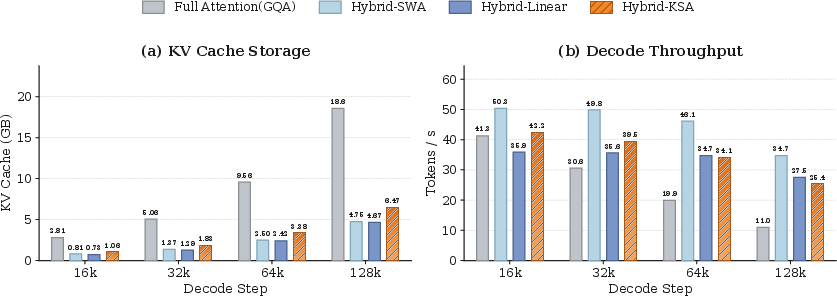
- On long-context tests (like RULER up to 128K tokens), KSA—especially the “hybrid-KSA” version that mixes KSA with normal full attention—scored the best or among the best. At the longest length (128K), hybrid-KSA outperformed standard full attention and other efficient methods.
- On general knowledge, math, and coding tasks (like MMLU, GSM8K, MBPP, HumanEval), KSA stayed competitive with full attention and usually beat other efficient (memory-saving) alternatives. In some cases, it even slightly improved over full attention on specific tasks.
- KSA works “orthogonally” with other memory-saving tricks:
- You can combine KSA with methods like GQA or MLA to shrink memory further.
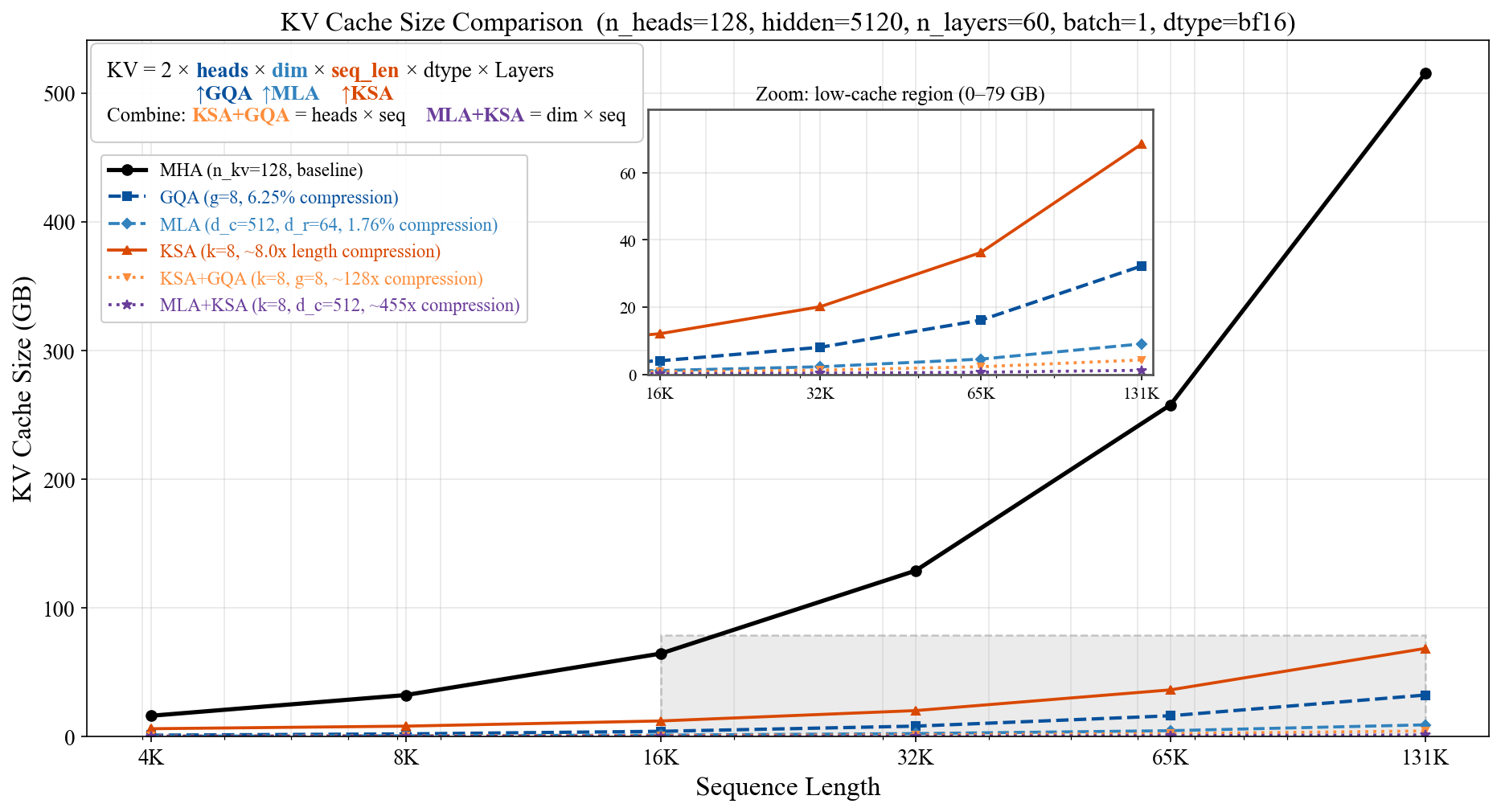
- In practice, the team reports around 8× extra reduction in the model’s memory cache (the “KV cache”) during inference when combining KSA with these methods—while keeping performance strong.
In short: KSA keeps long-range understanding strong while cutting memory use a lot, and it plays nicely with other efficiency techniques.
Why does this matter?
- Longer context, fewer compromises: Many fast methods lose long-distance details (like “local-only” windows) or blur them (like some linearized methods). KSA keeps distant information understandable and traceable by routing it through summary tokens.
- Better for real tasks: Agents, coding assistants, and research tools often need to refer back to far-away information (earlier steps, earlier files, earlier messages). KSA helps models do that at large scales without exploding memory and cost.
- Practical and compatible: Because KSA reduces how many past tokens need to be stored (by summarizing them) and can be combined with head- or dimension-level compression methods, it’s a flexible building block for future long-context LLMs.
Final takeaway
Kwai Summary Attention is like adding well-placed sticky notes through a long document: the model keeps reading nearby text in detail and relies on the summaries for far-away parts. This simple idea helps models handle much longer contexts with much less memory, while staying accurate on both long-document tasks and everyday benchmarks. It could make future AI assistants better at long conversations, big codebases, and complex multi-step reasoning—without breaking the bank on memory and speed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Lack of theoretical guarantees on information fidelity: no formal bounds or analyses of how much long-range information is lost when replacing distant text tokens with a single summary token per chunk.
- Unclear capacity of a single summary token per chunk: no ablation on using multiple summaries per chunk, adaptive number of summaries, or larger summary embeddings to capture heterogeneous chunk semantics.
- Fixed, content-agnostic chunking (size k) and windowing (C): no exploration of adaptive chunking based on content boundaries (e.g., sentences/paragraphs) or dynamic adjustment of k/C during training/inference.
- No principled method to choose k and C: missing guidelines or sensitivity analyses showing how k (chunk size) and C (sliding chunk count) impact accuracy, memory, and latency across tasks and lengths.
- Unexplored depth placement and mixing strategy: only a 3:1 KSA:Full ratio is tested, but no study of which layers should be KSA vs Full, nor whether non-uniform placement yields better performance/efficiency.
- Scalability to ultra-long contexts (≥256K–1M): results stop at 128K; no evidence on summarization error accumulation, degradation rate with growing number of summary tokens, or stability at million-token scales.
- Error accumulation across many chunks: no analysis of how summary-token chaining affects long chains of reasoning or multi-hop retrieval over hundreds/thousands of chunks.
- Limited evaluation breadth for long-context: only RULER is reported; no results on LongBench, LV-Eval, InfiniteBench, Needle-in-a-Haystack, QuALITY, or real-world long-document QA/retrieval.
- Generalization to agentic and multi-turn settings: claims about agent trajectories and memory are not validated on multi-turn dialogue or long-running tool-use/agent benchmarks.
- No measurement of wall-clock speedups: KV-cache savings are discussed, but missing end-to-end prefill/decoding throughput, latency, memory bandwidth profiling, and kernel-level speed gains on real hardware.
- Orthogonality claims with MLA not empirically validated: while KSA+MLA is motivated theoretically, no experiments or ablations demonstrate stability, performance, or kernel implications of the combination.
- Summary KV cache growth vs sequence length: summary buffer scales as O(n/k); no exploration of when this becomes a bottleneck, nor strategies to prune or compress historical summaries.
- Interaction with RoPE and extrapolation: KSA changes RoPE theta mid-training and places summaries at chunk ends, but no study of positional extrapolation behavior, alternative scaling (NTK/YaRN), or sensitivity to theta.
- Training compute and cost accounting: sequence augmentation adds n/k tokens; training FLOPs, memory, and wall-clock comparisons vs baselines are not reported.
- Stability and convergence from scratch: although CPT uses distillation and annealing, there is no analysis of training stability when training KSA from scratch across different k/C values and data mixes.
- Distillation/annealing hyperparameters unspecified: the weights (α, β), annealing window (s_start, s_end), and their sensitivity are not reported, limiting reproducibility and tuning guidance.
- Risk of degeneracy of summary tokens: no diagnostics to detect collapsed or uninformative summaries; no regularizers/auxiliary objectives beyond CPT distillation to ensure summaries carry diverse, salient content.
- Mask correctness and boundary conditions: while chunk-level sliding avoids partial coverage, no tests are shown for edge cases (short sequences, chunk underflow/overflow, BOS/EOS handling).
- Emission control for summary tokens: summary tokens are added to the vocabulary, but it is not stated how the model is prevented from generating them at inference time in open-ended decoding.
- Allocation of Q/K/V parameters for summaries at inference: annealing removes extra summary projections, but there’s no evidence that performance is retained across tasks post-removal or that merging doesn’t regress long-context ability.
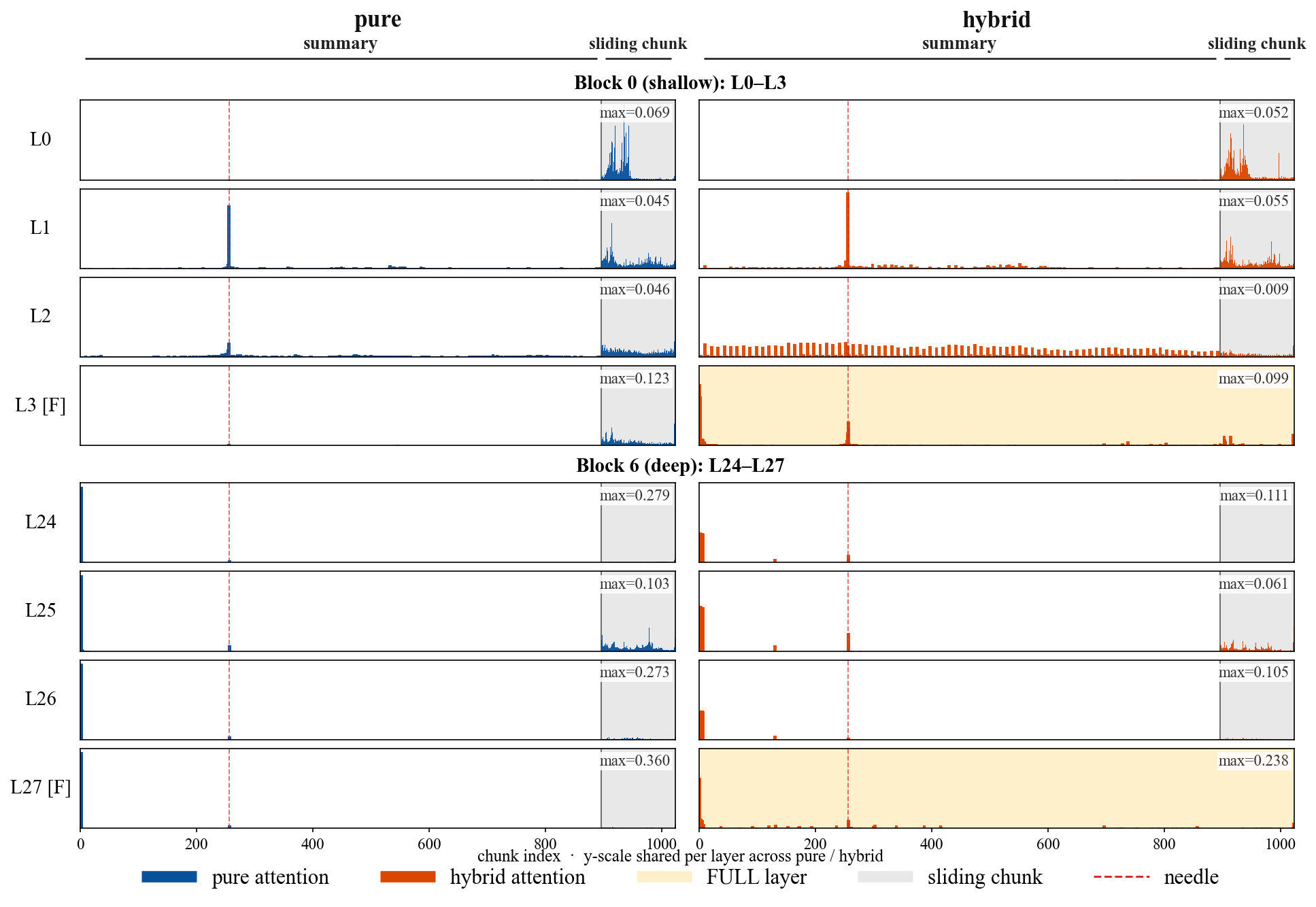
- Inter-layer information routing: no analysis of how summary tokens interact with attention heads across depth (e.g., do early layers overfit to local text while later layers over-rely on summaries?).
- Mechanistic interpretability: no probing of what summaries encode, how attention mass shifts between summaries and local tokens, or whether long-range semantics are faithfully represented.
- Robustness to content domain shifts: long-context evaluations are synthetic/structured; no tests on legal/biomedical long documents, codebases, or multilingual long texts beyond CMMLU.
- Multilingual and code-specific chunking: chunk sizes and SCA are language- and tokenization-agnostic; no exploration of how variable tokenization granularity (e.g., CJK, code) affects summary fidelity.
- Interaction with KV-optimized architectures: while KSA is mixed with Full, there is no study combining KSA with MoE, LoRA, speculative decoding, or paged attention to assess cumulative system-level effects.
- Memory fragmentation and batching in real servers: the contiguous K/V layout is described for single sequences, but batching, variable-length requests, padding, and dynamic chunk boundaries are not addressed.
- Fault tolerance and streaming: no guidance for streaming inputs, partial resets, or mid-stream changes in k/C; unclear how to maintain correctness when user context is updated irregularly.
- Downstream finetuning and RL: impact of KSA on SFT, DPO/RLHF, and tool-use finetuning is not studied; unclear whether summary routing helps or hinders alignment signals.
- Safety and bias: changing attention topology may shift reliance on distant context; no analysis of hallucination reduction, factuality, bias propagation through summaries, or toxicity behavior.
- Data details and contamination: high-level dataset categories are given, but specific sources, filtering, contamination checks (especially for evals like MMLU-Pro), and licenses are not fully disclosed.
- Reproducibility gaps: some critical implementation details (exact masks, kernel block sizes, annealing schedule, α/β, k/C per stage, layer placement of KSA vs Full) are missing or underspecified.
- Applicability beyond decoder-only LMs: no exploration of KSA in encoders, encoder-decoder architectures, cross-attention, or multimodal settings where summary routing might behave differently.
- Comparison to alternative token-level compression: no head-to-head with token selection/pruning, pooling, recurrence with learned memories, or state-space models that also target long-range efficiency.
- Failure modes on local tasks: potential degradation on tasks requiring precise token-level alignment (e.g., structured extraction, code diffing) is not examined when summaries mediate long-range context.
- Adaptive gating between local and summary signals: KSA uses a hard mask; no exploration of learnable gates or attention sparsity schedules to balance local vs global information dynamically.
- Practical guidance for deployment: no recipe for selecting k, C, and KSA:Full ratios given hardware constraints, latency targets, and task requirements; no ablation translating KV savings to token/s throughput.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage KSA’s summary-token compression, sliding-chunk attention, and inference kernels to reduce KV cache and bandwidth while preserving long-range reasoning.
- Large-scale LLM serving cost and energy reduction (software/cloud, energy)
- What: Integrate KSA (alone or with GQA/MLA) in inference stacks to shrink KV cache to O(n/k) and cut HBM reads during decode via contiguous ring-buffer KV layouts.
- Tools/workflows: Plugins for vLLM/TGI/TensorRT-LLM; “summary KV ring-buffer” scheduling; block-sparse prefill kernels; hybrid-KSA layer mixing (e.g., 3:1).
- Assumptions/dependencies: Models must be trained or CPT’d with KSA; runtime needs support for KSA masks and cache layout; correct choice of chunk size k and mixing ratio; hardware-friendly kernels available for target GPUs.
- Long-context chatbots and customer support agents (customer service, sales)
- What: Maintain multi-turn histories (tens of thousands of tokens) with lower latency/memory, reducing hallucinations and improving resolution of historical context.
- Tools/workflows: Session memory organized by chunks; summary tokens as priors for distant turns; hybrid-KSA models deployed via existing chatbot platforms.
- Assumptions/dependencies: Multi-turn training data; careful k and sliding-chunk settings to avoid critical info loss; monitoring for evaluation drift vs. full attention.
- Code assistants and code agents in IDEs (software development)
- What: Handle multi-file repositories, long diffs, and extended tool traces with significantly lower KV memory, improving responsiveness in code synthesis and refactoring.
- Tools/workflows: Hybrid-KSA checkpoints fine-tuned on code; IDE integrations; streaming decode with contiguous KV slices.
- Assumptions/dependencies: Sufficient code long-context CPT; verify that summary compression does not erase fine-grained dependencies (imports, variable scopes).
- Legal and enterprise document analysis (legal, finance, enterprise IT)
- What: Analyze 100K+ token contracts, filings, and policies with lower memory while retaining cross-reference integrity via summary-token relays.
- Tools/workflows: E-discovery/reporting pipelines using KSA models; chunk-aware ingestion and evaluation; long-document QA with reduced KV.
- Assumptions/dependencies: Domain-specific finetuning; validation for citation faithfulness; ensure chunk boundaries align with document structure where possible.
- Healthcare EHR and longitudinal chart summarization (healthcare)
- What: Process years of patient notes, labs, and imaging reports with reduced memory and improved cross-visit reasoning.
- Tools/workflows: On-prem KSA-enabled models; chunked EHR ingestion; summary tokens as longitudinal memory for clinical assistants.
- Assumptions/dependencies: Regulatory/privacy compliance; clinical finetuning; verification that summarization does not omit safety-critical details.
- Session-based recommendation and personalization (media, e-commerce)
- What: Use KSA to model long user sessions efficiently, enabling richer histories without exploding KV cache.
- Tools/workflows: KSA-based session encoders; online serving with sliding-chunk windows; replay buffers that persist summary tokens.
- Assumptions/dependencies: Integration with existing recsys infra; latency budgets; training data with long sessions.
- RAG context packing and serving optimization (enterprise search, developer tools)
- What: Serve larger retrieved contexts per query at lower memory cost; summaries route long-range dependencies, reducing need for aggressive truncation.
- Tools/workflows: RAG pipelines that pre-chunk documents and respect chunk boundaries; dynamic k tuned to retrieval size.
- Assumptions/dependencies: Tight integration with retrievers; careful evaluation on retrieval faithfulness; chunk-aware prompt assembly.
- On-device or edge assistants with extended memory (mobile, embedded)
- What: Run longer-context assistants offline on memory-limited hardware by lowering KV footprint and bandwidth demands.
- Tools/workflows: KSA models distilled to small sizes; mobile kernels ported to Metal/Vulkan/NN runtimes; chunk-aware session memory.
- Assumptions/dependencies: Mobile-optimized kernels; power constraints; quality retention at small parameter counts.
- Enterprise knowledge management and internal QA (enterprise software)
- What: Bots that reason over large handbooks, SOPs, and wiki spaces using KSA to retain more context within the same memory budget.
- Tools/workflows: Chunk-aware indexing; “summary caches” persisted across sessions; hybrid layers to balance accuracy and cost.
- Assumptions/dependencies: Access control and data governance; persistent summary storage design; internal evaluation for reliability.
- Academic experimentation and teaching (academia)
- What: Use the open-source KSA recipes and kernels to prototype long-context architectures and study KV-memory/quality trade-offs.
- Tools/workflows: Reproduce CPT warmups (distillation + annealing); ablations on k, sliding C, and hybrid ratios; benchmark on RULER and general tasks.
- Assumptions/dependencies: Compute availability; adherence to provided training schedules and RoPE theta choices; kernel suitability for available hardware.
- Sustainability and procurement decisions (policy/operations)
- What: Adopt KSA-backed models to reduce inference energy per token and cloud costs; inform green AI metrics and purchasing.
- Tools/workflows: Dashboards tracking KV cache size and HBM traffic; cost/CO2 reporting integrated with serving.
- Assumptions/dependencies: Accurate hardware telemetry; standardized baselines to compare energy savings across models and workloads.
Long-Term Applications
These opportunities likely require additional research, scaling, or ecosystem support before broad deployment.
- Multimodal long-context processing (vision/audio/video, AV, media)
- What: Extend summary-token compression to long video/audio streams (per-segment summaries) for surveillance analytics, long-form video Q&A, or AV logs.
- Tools/workflows: KSA variants for vision-language transformers; segment-aware kernels; multimodal CPT curricula.
- Assumptions/dependencies: Designing summary tokens for non-text modalities; new kernels for large spatial-temporal tensors; robust evaluation datasets.
- Hierarchical agent memory and “LLM OS” (agent platforms, software)
- What: Persistent, interpretable memory built from learned summaries (e.g., per task or episode), enabling long-horizon planning and recall.
- Tools/workflows: Memory managers that store/retrieve learned summaries; session-to-session persistence; chunk-aware retrieval policies.
- Assumptions/dependencies: Read/write policies for memory safety; cross-session identity and privacy; training for memory reliability.
- Long-horizon RL and robotics (robotics, autonomy)
- What: Use KSA to stabilize long-trajectory credit assignment by routing distant dependencies through summaries; better planning and control over extended horizons.
- Tools/workflows: RL pipelines with KSA-based critics/policies; trajectory chunking with learned summaries; evaluation on manipulation/navigation tasks.
- Assumptions/dependencies: Demonstrated gains vs. recurrent baselines; safety and interpretability in closed-loop control.
- Hardware–software co-design for KV-efficient decoding (semiconductors, cloud)
- What: Accelerator support for contiguous summary-KV ring buffers, block-sparse prefill, and chunk-aware scheduling.
- Tools/workflows: Runtime/driver features for single-slice KV reads; ISA or compiler intrinsics for KSA masks.
- Assumptions/dependencies: Vendor adoption; hardware timelines; standardization of KSA-like layouts across frameworks.
- Federated and privacy-preserving analytics via learned summaries (healthcare, finance)
- What: Share compressed summaries instead of raw tokens across institutions/users to lower bandwidth and privacy risk.
- Tools/workflows: Summary-exchange protocols; differential privacy on summary tokens; validation for leakage.
- Assumptions/dependencies: Proofs/metrics of privacy; regulatory acceptance; robustness against inversion attacks.
- Corpus-level “summary layers” for fast long-document QA (publishing, legal, research)
- What: Build hierarchical indices where every chunk has learned summaries, enabling multi-granular retrieval and scalable QA.
- Tools/workflows: Offline precomputation of persistent summary tokens; multi-level retrieval schemes aligned to chunk boundaries.
- Assumptions/dependencies: Training workflows for persistent summaries; storage formats; evaluation on cross-document tasks.
- Adaptive compression and learned chunking (all sectors using LLMs)
- What: Dynamic k and chunk boundaries based on content density (e.g., denser chunks for code/math, larger for narrative text).
- Tools/workflows: Controllers that adjust k/C per segment; reinforcement learning to optimize visibility masks; curriculum schedules.
- Assumptions/dependencies: Stability during training/inference; masking correctness; runtime complexity management.
- Cross-model interoperability of summaries (platforms/ecosystems)
- What: Exchange of learned summaries across different models/systems to reduce duplication of compute and accelerate workflows.
- Tools/workflows: APIs/standards for serializing summary tokens; compatibility layers for RoPE/positional encodings.
- Assumptions/dependencies: Representational alignment across models; IP/licensing; security controls.
- Standards and regulation for compressed-attention in critical systems (policy, compliance)
- What: Certification frameworks that evaluate fidelity and explainability of summary-based long-context reasoning in safety-critical domains.
- Tools/workflows: Test suites for information retention and attribution; audit logs tracking summary usage and visibility.
- Assumptions/dependencies: Agreement on benchmarks and thresholds; collaboration with regulators and standards bodies.
- Unified personal memory across applications (consumer, productivity)
- What: Personal assistants that maintain years of emails, notes, chats via summary-based memory with interpretable recall paths.
- Tools/workflows: OS-level services to store summaries locally; privacy-preserving synchronization; chunk-aware search.
- Assumptions/dependencies: Strong privacy guarantees; user controls and transparency; device/cloud coordination.
Glossary
- AdamW: An optimization algorithm that combines Adam with weight decay for better generalization. "Optimizer & \multicolumn{2}{c}{AdamW (, )}"
- Agentic era: A phase of AI research focusing on agent-like systems with memory and multi-step reasoning. "In the Agentic era, obtaining extensive memory across multi-turn conversations and accurately retrieving historical contexts are prerequisites for highly intelligent agents and long chain-of-thought reasoning."
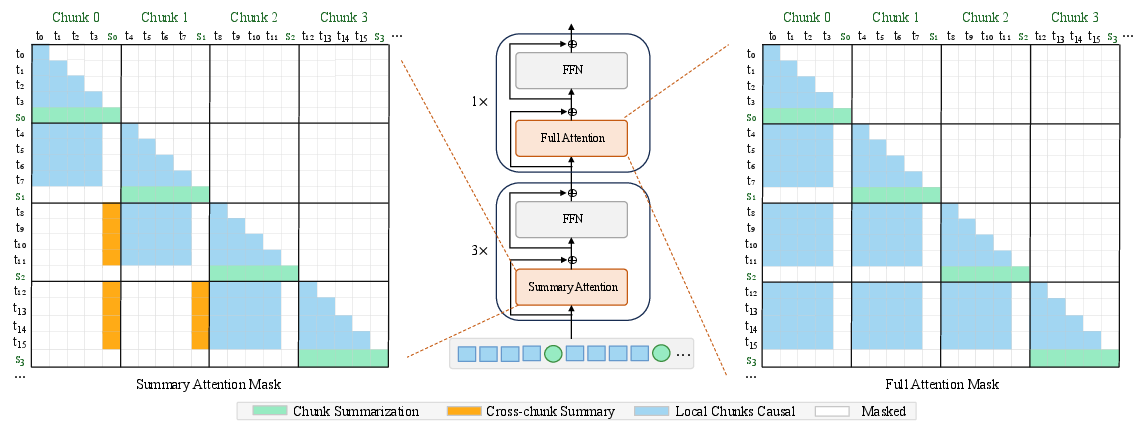
- Attention mask: A mask that defines which tokens are visible to each other during attention computation. "The attention mask of KSA is a structured sparse mask defined jointly by the local sliding window of text tokens and the visibility of distant summary tokens."
- Auto-regressive decoding: A generation process where each token is produced conditioned on all previous tokens. "The nature of auto-regressive decoding requires every generation step to take all previous KV entries into account, resulting in a memory-bandwidth bottleneck rather than a compute-bound one."
- Block-sparse attention kernel: An attention implementation that computes only selected blocks to reduce memory/computation. "To address this, we design a block-sparse attention kernel for training and prefill, and a summary KV cache for decoding, addressing compute efficiency and memory cost respectively."
- C-Eval: A Chinese evaluation benchmark covering multiple disciplines and exam-style tasks. "For general knowledge, MMLU and its extensions, CMMLU, C-Eval, and MMLU-Pro, assess knowledge breadth and reasoning across diverse domains via multi-choice questions"
- CMath: A Chinese mathematics benchmark assessing mathematical reasoning. "For mathematics, GSM8K, CMATH, and MATH cover problems from grade-school multi-step arithmetic to competition-level symbolic reasoning"
- CMMLU: A Chinese-language extension of the MMLU benchmark. "For general knowledge, MMLU and its extensions, CMMLU, C-Eval, and MMLU-Pro, assess knowledge breadth and reasoning across diverse domains via multi-choice questions"
- Continual pre-training (CPT): Further pre-training a model after initial training to adapt or extend capabilities. "we perform comprehensive from-scratch (Scratch) or continual pre-training (CPT) experiments on a wide range of downstream benchmarks"
- Decay factors (α_t): Coefficients that progressively attenuate older information in certain recurrent/linear attention mechanisms. "as new tokens arrive, older information is progressively attenuated by the decay factors "
- Diagonal gating: A mechanism in linear attention models that gates state updates along the diagonal, shaping memory retention. "the linear GDN mechanism compresses the entire sequence history into a fixed state matrix through diagonal gating."
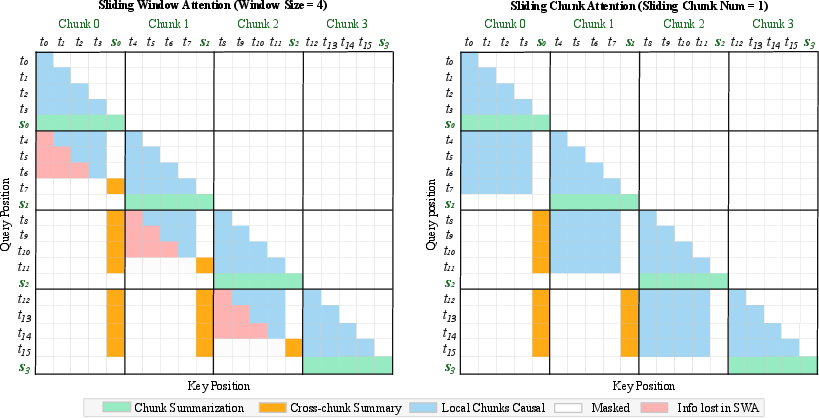
- FIFO buffer: A First-In-First-Out memory structure that keeps the most recent items by discarding the oldest. "SWA maintains latest recent tokens in a FIFO buffer, with a fixed cache size $2wgd$."
- Gated DeltaNet (GDN): A linear attention mechanism that maintains a fixed-size state with gated updates. "This branch replaces the majority of layers with efficient attention variants that carry a much smaller KV cache, fundamentally decoupling the KV cache from sequence length in some layers. However, the drawback is also obvious: for linear attention, the fixed-size state is inherently lossy compression, in which long-range information becomes blurred and unattainable; local variants, on the other hand, completely discard any context outside the window, thus losing perception of the distant information." (e.g., "linear kernel GDN")
- Gradient clipping: A technique to limit the magnitude of gradients to stabilize training. "Gradient Clipping & \multicolumn{2}{c}{$1.0$}"
- Grouped Query Attention (GQA): An attention variant where multiple query heads share the same key/value heads to reduce cache. "In standard MHA, each of the attention heads maintains its own KV states, the GQA proposes a simple-yet-effective technique to organize the total heads into groups, where same group of Q-heads shared the same cached KV-heads."
- GSM8K: A grade school math benchmark focusing on multi-step arithmetic reasoning. "For mathematics, GSM8K, CMATH, and MATH cover problems from grade-school multi-step arithmetic to competition-level symbolic reasoning"
- HBM (High Bandwidth Memory): A type of memory with high throughput used for accelerating data transfer. "the kernel only loads non-zero block pairs from HBM to SRAM for computation."
- Head grouping: Combining multiple attention heads into groups that share key/value to reduce memory. "The core idea of this branch is to compress the per-token KV cache through head grouping and sharing, or low-rank KV projection."
- HumanEval: A code generation benchmark evaluating functional correctness via unit tests. "For code, MBPP and HumanEval evaluate program synthesis from natural language, with HumanEval further emphasizing functional correctness through unit tests on more complex and realistic coding tasks."
- Hybrid-KSA: An architecture mixing Kwai Summary Attention with full attention blocks. "Our hybrid-KSA (8 sequence compression, $3$:$1$ KSA/Full mixture ratio) leads on multiple long-context retrieval tasks and achieves competitive general understanding ability with other Hybrid variants."
- KL regularizer: A Kullback–Leibler divergence term used to align model output distributions. "We therefore introduce a KL regularizer on the output logits to provide a higher-level alignment between the KSA student and the full-attention teacher."
- KV cache: Stored keys and values from past tokens used during attention, critical for efficient decoding. "the KV cache scales linearly with sequence length, while the attention computation scales quadratically."
- LM head: The final linear projection mapping hidden states to vocabulary logits in LLMs. "Let denote the shared LM head, and and be the final-layer hidden states of the teacher and student, respectively."
- Linear attention: Attention mechanisms that scale linearly by maintaining fixed-size states or kernel tricks, often lossy for long-range info. "Compared with SWA and Linear attention, it has the potential that preserving full fidelity over long-range dependency, more friendly for long-context reasoning, agent trajectories, and downstream RL training signals."
- Low-rank KV projection: Compressing keys/values into a lower-dimensional latent space to reduce cache. "The core idea of this branch is to compress the per-token KV cache through head grouping and sharing, or low-rank KV projection."
- MBPP: A code synthesis benchmark with small programming problems. "For code, MBPP and HumanEval evaluate program synthesis from natural language"
- MATH: A benchmark of competition-level mathematical problems requiring symbolic reasoning. "For mathematics, GSM8K, CMATH, and MATH cover problems from grade-school multi-step arithmetic to competition-level symbolic reasoning"
- Mean squared error (MSE) loss: A loss measuring squared differences, used for aligning intermediate representations. "and employ a mean squared error (MSE) loss:"
- Memory-bandwidth bottleneck: A performance limit where data movement, not compute, dominates runtime. "resulting in a memory-bandwidth bottleneck rather than a compute-bound one."
- Multi-Head Attention (MHA): The standard attention mechanism using multiple parallel heads. "Naive Multi-Head Full Attention (MHA)~\cite{vaswani2017attention}."
- Multi-head Latent Attention (MLA): An attention variant compressing KV into low-rank latent vectors with decoupled RoPE keys. "Compared with GQA, MLA takes a more aggressive approach by projecting all KV information into low-rank latent vectors."
- Orthogonality (of KV cache compression): Independent optimization dimensions whose effects multiply when combined. "Given the above discussion, GQA, MLA, and KSA are orthogonal to each other:"
- Parameter annealing: Gradually transitioning parameters (e.g., from auxiliary to main) during training. "we propose a parameter annealing strategy that gradually absorbs the independent summary parameters into the main LLM weights."
- Position id: The positional index assigned to a token, affecting positional encoding. "Moreover, summary token position id is the same with its own chunk's last text token's."
- Prefill kernel: The attention kernel used to process the prompt (prefill) phase efficiently. "In the training / prefill kernel, Q/K/V are split into fixed-size blocks"
- Q/K/V: Queries, Keys, and Values—the core matrices used in attention computations. "In the training / prefill kernel, Q/K/V are split into fixed-size blocks"
- QKV projections: Linear projections that produce queries, keys, and values from hidden states. "Specifically, at each summary position, we perform two QKV projections on the same hidden state:"
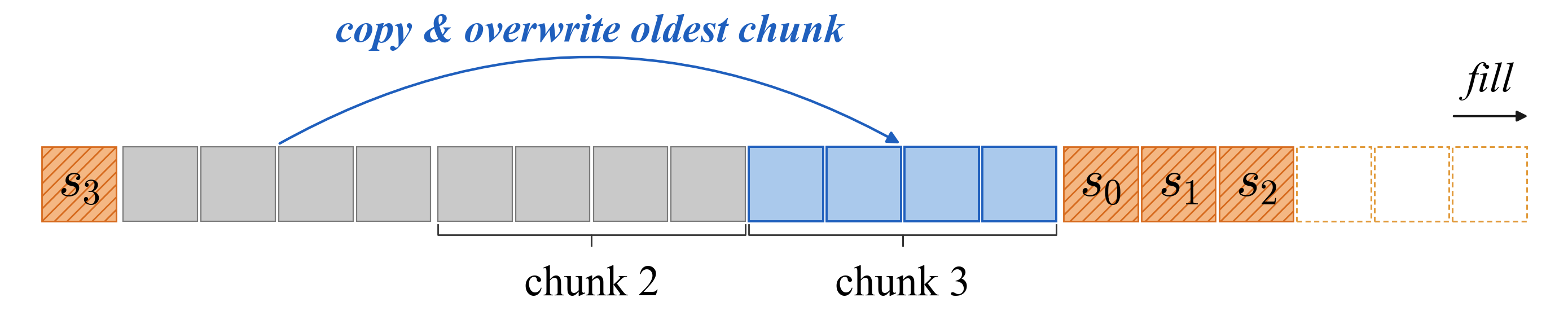
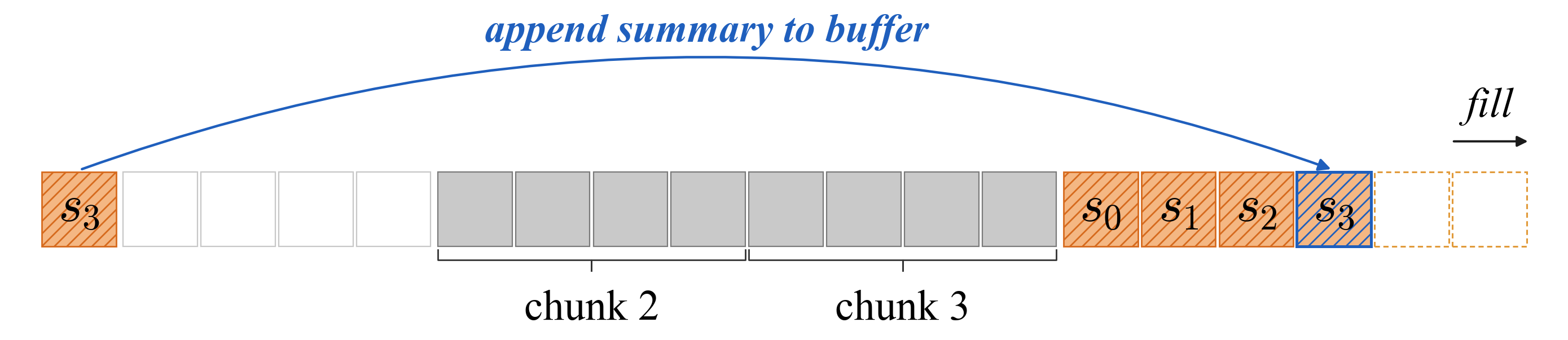
- Ring buffer: A circular buffer where new data overwrites the oldest when full. "The just-finished chunk text is then copied into the ring buffer at the write pointer, overwriting the oldest chunk in a modular fashion"
- RoPE (Rotary Positional Encoding): A positional encoding method applied to keys/queries via rotations in embedding space. "Since RoPE is applied to each key before it enters the cache, every entry inherently carries its own position encoding"
- RoPE Theta: A scaling parameter controlling the frequency base in RoPE for extended context. "Note that we change the RoPE Theta from to after the 8K training finished."
- RULER: A long-context evaluation suite measuring retrieval, aggregation, and QA at large context lengths. "RULER~\cite{hsiehruler} is a comprehensive long-context evaluation suite that assesses models across multiple dimensions"
- Sliding Chunk Attention (SCA): An attention scheme where visibility windows align to chunk boundaries to avoid partial coverage. "we further introduce a sliding chunk attention mechanism (SCA) that allows text tokens to see the latest several chunks' text token."
- Sliding Window Attention (SWA): An attention mechanism limited to a fixed recent window to reduce complexity. "Following the standard full attention mechanism, SWA narrows the visual token window to reduce the KV cache amount."
- Sparse mask: A mask with many zeros, enabling computation only on necessary attention pairs. "The attention mask of KSA is a structured sparse mask defined jointly by the local sliding window of text tokens and the visibility of distant summary tokens."
- SRAM (Static Random-Access Memory): On-chip memory with low latency used for fast compute access. "the kernel only loads non-zero block pairs from HBM to SRAM for computation."
- Sub-linear scaling: Growth that increases slower than linearly with sequence length. "for long sequences, this sub-linear scaling could further reach a considerable compression ratio"
- Sub-quadratic complexity: Computational cost that grows slower than the square of sequence length. "maintains sub-quadratic complexity while preserving the expressivity in modeling long-range dependencies."
- Summary KV cache: A dedicated cache region holding KV states of summary tokens for efficient decoding. "we design a block-sparse attention kernel for training and prefill, and a summary KV cache for decoding"
- Summary token: A learnable token inserted per chunk to compress and carry its semantics over long ranges. "KSA introduces a novel summary mechanism designed to distill historical contexts from lengthy sequences into a lightweight, learnable summary token."
- Tied embeddings: Sharing parameters between input and output embedding matrices. "Tied embeddings & False & True"
- Visibility rule: The policy determining which tokens are visible to others given the cache layout. "the cache layout itself inherently encodes the visibility rule."
- WSD: A learning-rate scheduling strategy referenced for training. "LR Schedule & \multicolumn{2}{c}{WSD~\cite{yu2025minicpmv45cookingefficient}"
Collections
Sign up for free to add this paper to one or more collections.