- The paper presents a novel hierarchical, semi-structured sparse KV attention mechanism that compresses KV caches and accelerates long-context LLM inference.
- It details a flexible pruning strategy with block-level and element-level decisions to balance latency improvements against generation quality.
- Empirical evaluations show up to 2.0× prefill speedup and 1.78× decode speedup, offering significant efficiency gains with minimal accuracy loss.
Hierarchical Semi-Structured Sparse KV Attention in LLMs: An Analysis of "HieraSparse"
Context and Motivation
Extending LLM context windows to hundreds of thousands or millions of tokens introduces severe computational and memory constraints, particularly due to the quadratic scaling of attention and the linear growth of the key-value (KV) cache. As shown in the analysis, attention computation dominates both prefill and decode latency at long sequence lengths, and the KV cache memory footprint rapidly exceeds GPU capacity, with per-request requirements easily surpassing 100 GiB for million-token contexts. Thus, methods that can effectively compress the KV cache and accelerate attention are indispensable for deploying long-context LLMs in practical environments.
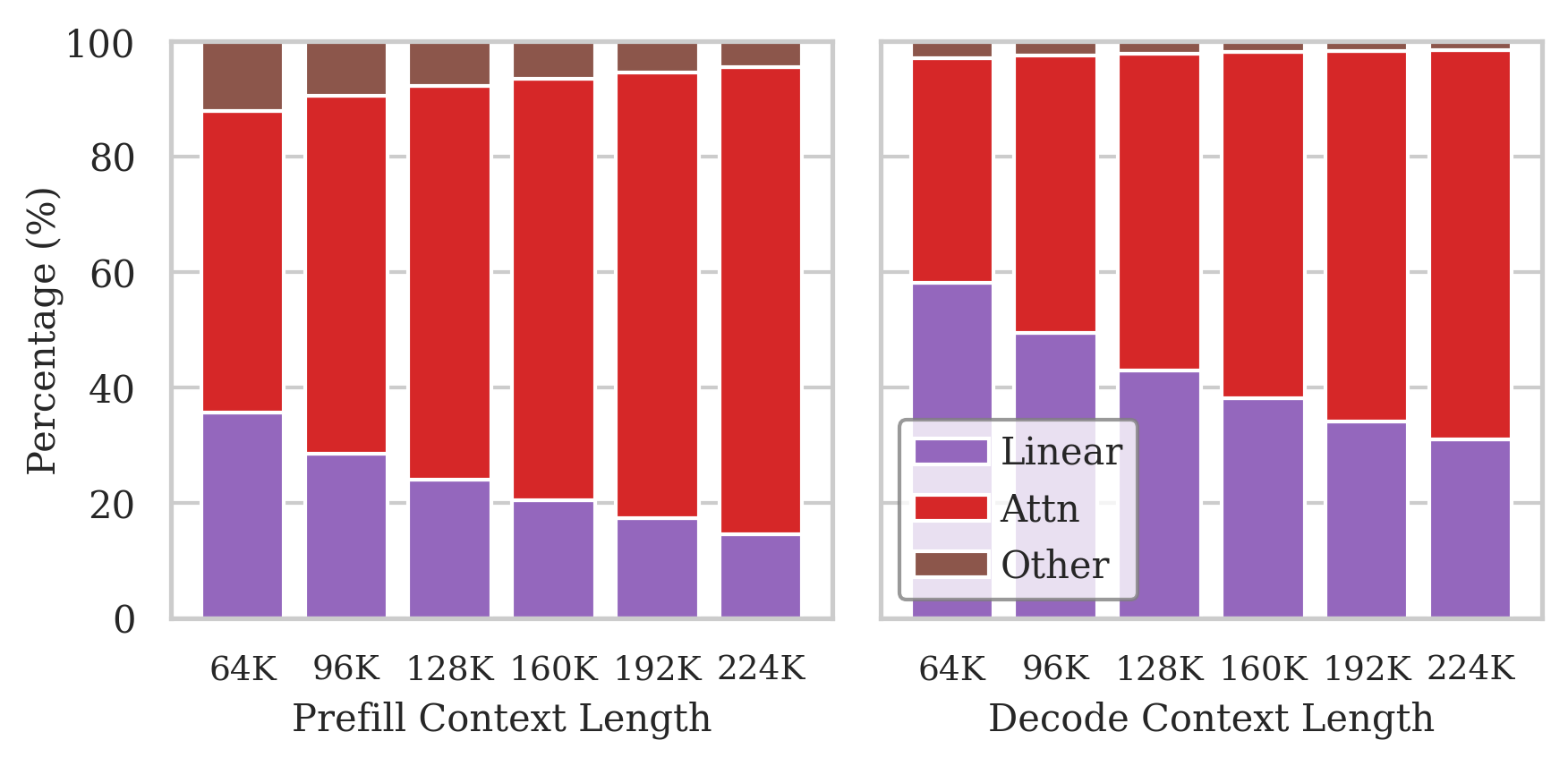
Figure 1: The latency breakdown of the prefill and decode phases under different context lengths. The attention mechanism gradually dominates the computation as the context length increases.
Hierarchical Semi-Structured Sparse KV Attention
HieraSparse addresses the challenge of converting sparsity into tangible efficiency in both compute and memory for long-context LLM inference. Conventional techniques employ either coarse- or fine-grained KV cache pruning, but either forgoes finely tuned quality-control or fails to realize actual system latency reduction due to the overheads of unstructured sparsity handling on modern accelerators. HieraSparse proposes hierarchical, semi-structured N:M sparsity in the KV cache, leveraging hardware support (NVIDIA/AMD sparse tensor cores) to translate pruning directly into acceleration.
Hierarchical Pruning and Block Management
The hierarchical design decomposes KV cache pruning into block-level and element-level decisions. The cache is divided into blocks (default: size 64 along the sequence axis). For each block, block-level pruning masks determine which blocks are retained as dense and which are pruned into sparse format. Within pruned blocks, N:M element-level masks select nonzero elements. Magnitude-based selection is the default—but alternative, more sophisticated query- or task-driven policies are supported in this framework.
Flexible Block and Element Sparsity Patterns
The system architecture supports not only differentiated sparsity ratios between key and value caches but also flexible sparsity assignments across network layers and between the prefill and decode phases. This flexibility enables hardware efficiency to be tuned dynamically against generation quality, tailored to varying application scenarios.
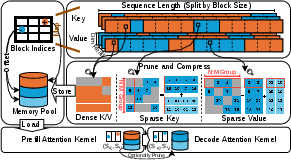
Figure 2: The overall workflow of HieraSparse, which supports flexibility at different levels: i) Different sparsity patterns for the prefill and decode phases. ii) Different sparsity patterns for the key and value caches. iii) Different block-level sparsity pattern. iv) Different element-level sparsity pattern.
Compression and Attention Acceleration Kernels
Cache Compression Strategy
All dense, sparse (nonzero/metadata), and index blocks are maintained in compacted memory pools, and block indexes map logical cache locations to their physical storage. This design supports online compression with minimal overhead, with data packing vectorized to fully exploit hardware bandwidth and register partitioning.
Mixed Sparse-Dense Attention Kernels
To fully utilize sparsity in both prefill (sequence-to-sequence) and decode (token generation) phases, HieraSparse reformulates the attention computation to apply sparse tensor core acceleration to both KV operands. This is achieved through algorithmically efficient transposition and operand re-layout using CUDA instructions (such as movmatrix) to avoid shared memory bottlenecks for register-resident fragments.
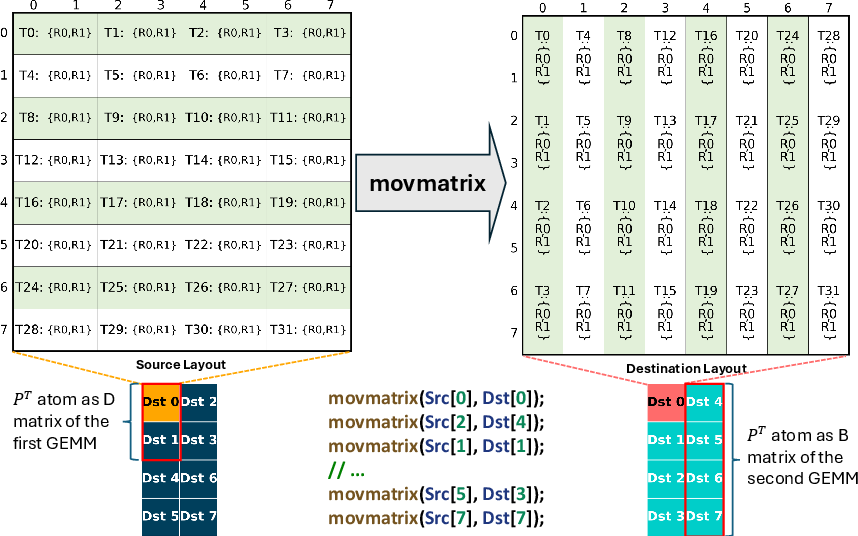
Figure 3: The illustration of PT fragment re-layout. The source layout consists of multiple 16×8 D-matrix atoms, and the destination layout consists of multiple 32×8 B-matrix atoms, both in row-major. They are both partitioned into 8×8 atoms, and multiple movmatrix are issued to perform the re-layout without shared memory access.
Quality-Sparsity Trade-offs
Evaluation on LongBench shows that the value cache can be aggressively pruned with minimal impact on metrics (e.g., $0.06$ drop on Llama-3.1-8B-Instruct for 50% value sparsity; $1.8$ average drop at extreme settings). Key cache pruning induces larger degradation, especially during the prefill phase, due to its influence on softmax sensitivity (exponential scaling in attention weights). The optimal regime retains key cache density during prefill while permitting aggressive value pruning, and applies differentiated policies for decode.
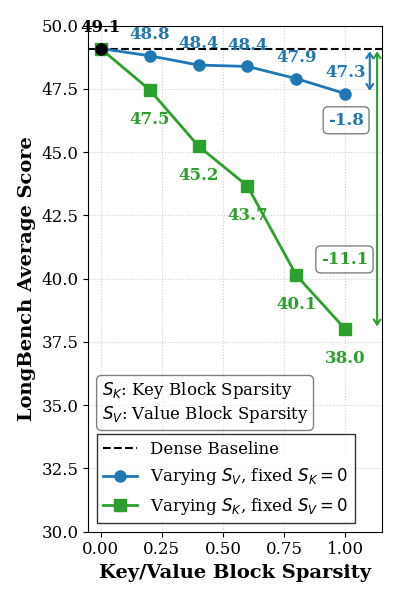
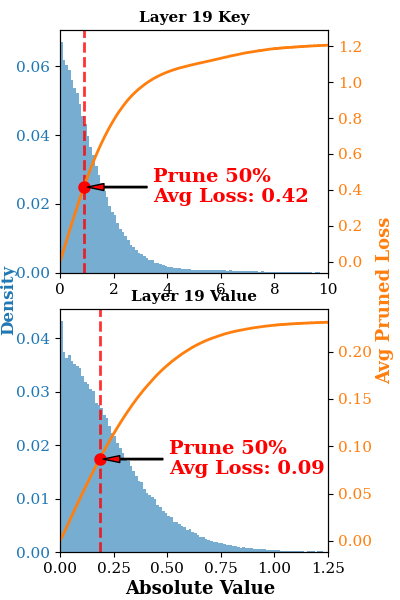
Figure 4: The average LongBench scores with different sparsity settings when extending pruned cache to prefill stage.
Computational Speedup and Memory Savings
With SK=1.0,SV=1.0 (100% block sparsity), HieraSparse delivers up to 2.0× prefill speedup and 16×80 decode speedup. Compared to state-of-the-art unstructured decode methods (e.g., MUSTAFAR), HieraSparse achieves up to 16×81 higher KV compression ratio and 16×82 greater attention speedup at identical sparsity, directly exploiting hardware for actual latency improvements.
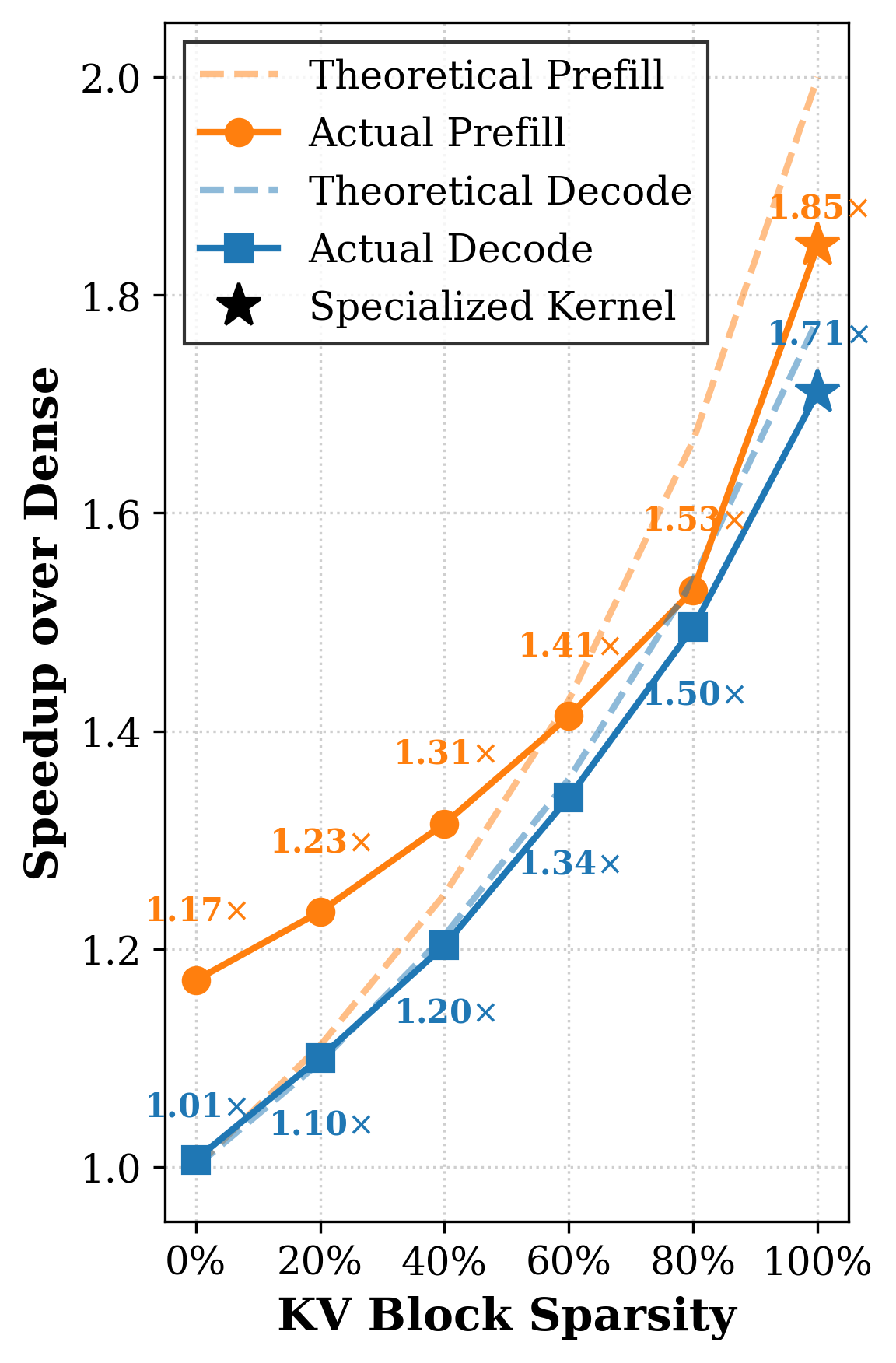
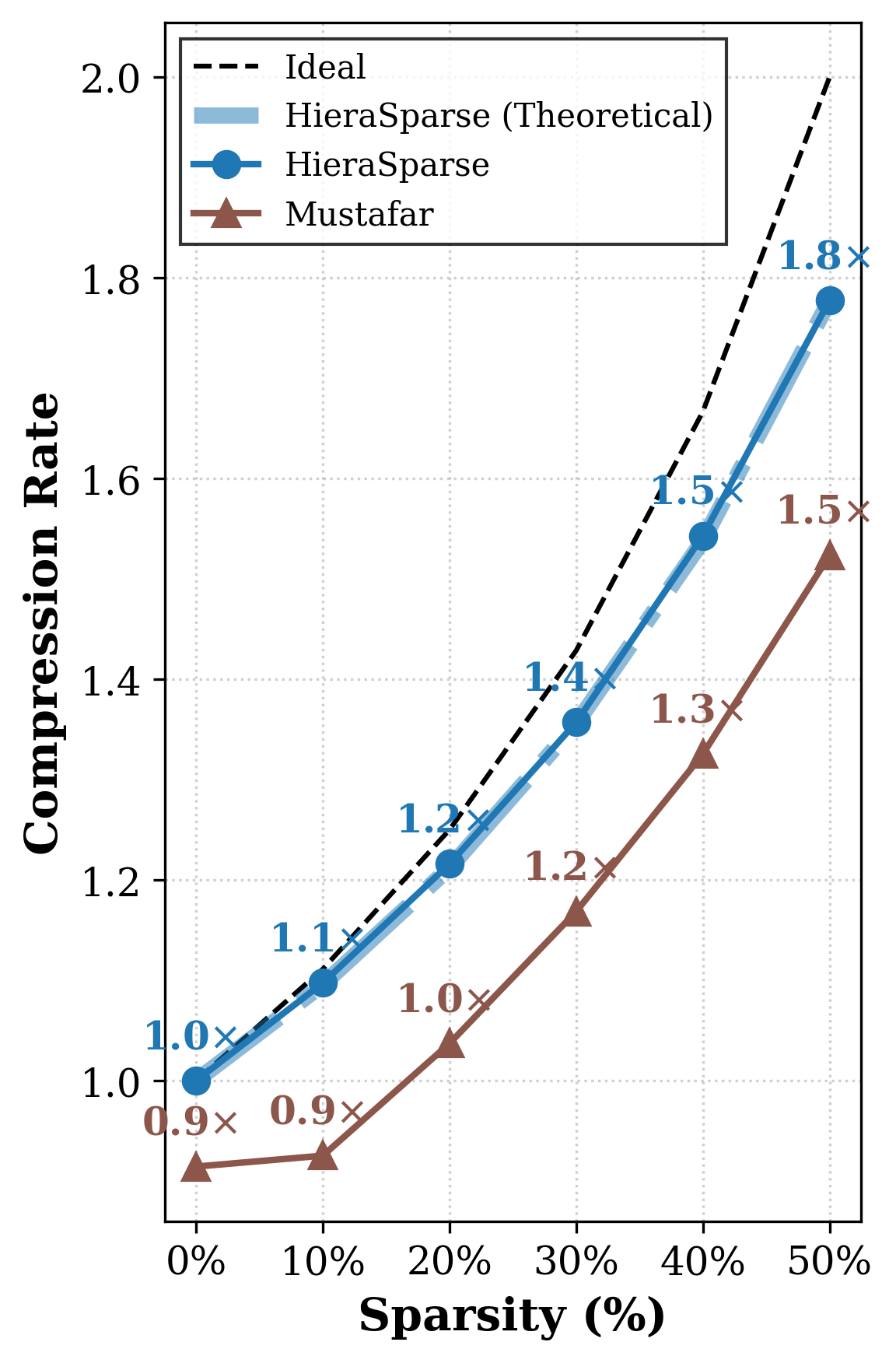
Figure 5: Kernel speedup against dense baseline for different block sparsity.
Memory compression closely matches theoretical predictions, and the index/metadata overheads are negligible at practical block sizes.
Minimal Overheads and Bottleneck Shifts
Compression cost is 16×83 of prefill attention latency (versus 16×84 for MUSTAFAR). Kernel and end-to-end speedups are robust across batch sizes and context lengths, and per-layer analysis shows that as the context window increases, attention (and thus the proposed sparse kernels) dominate the inference path.
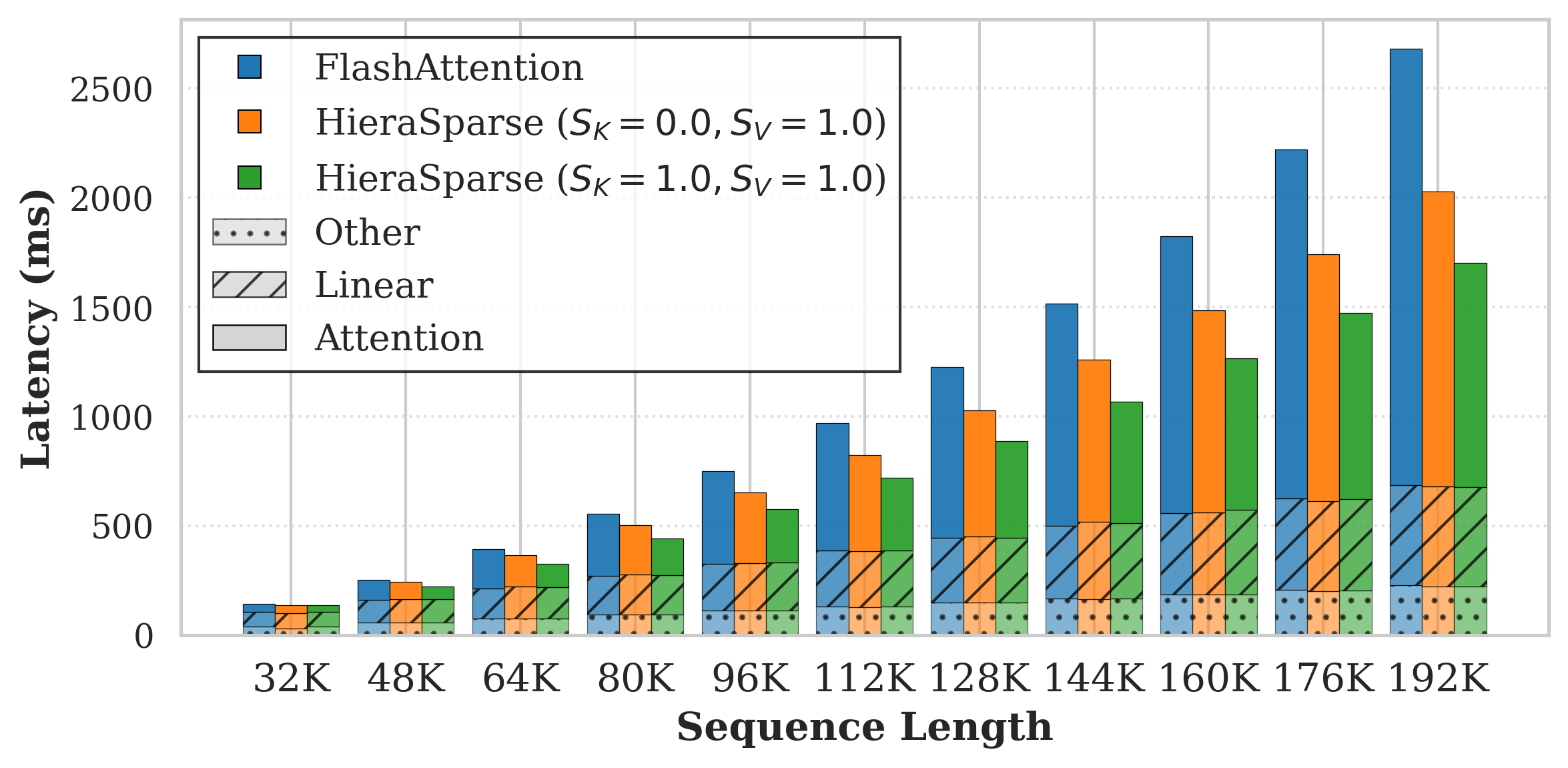
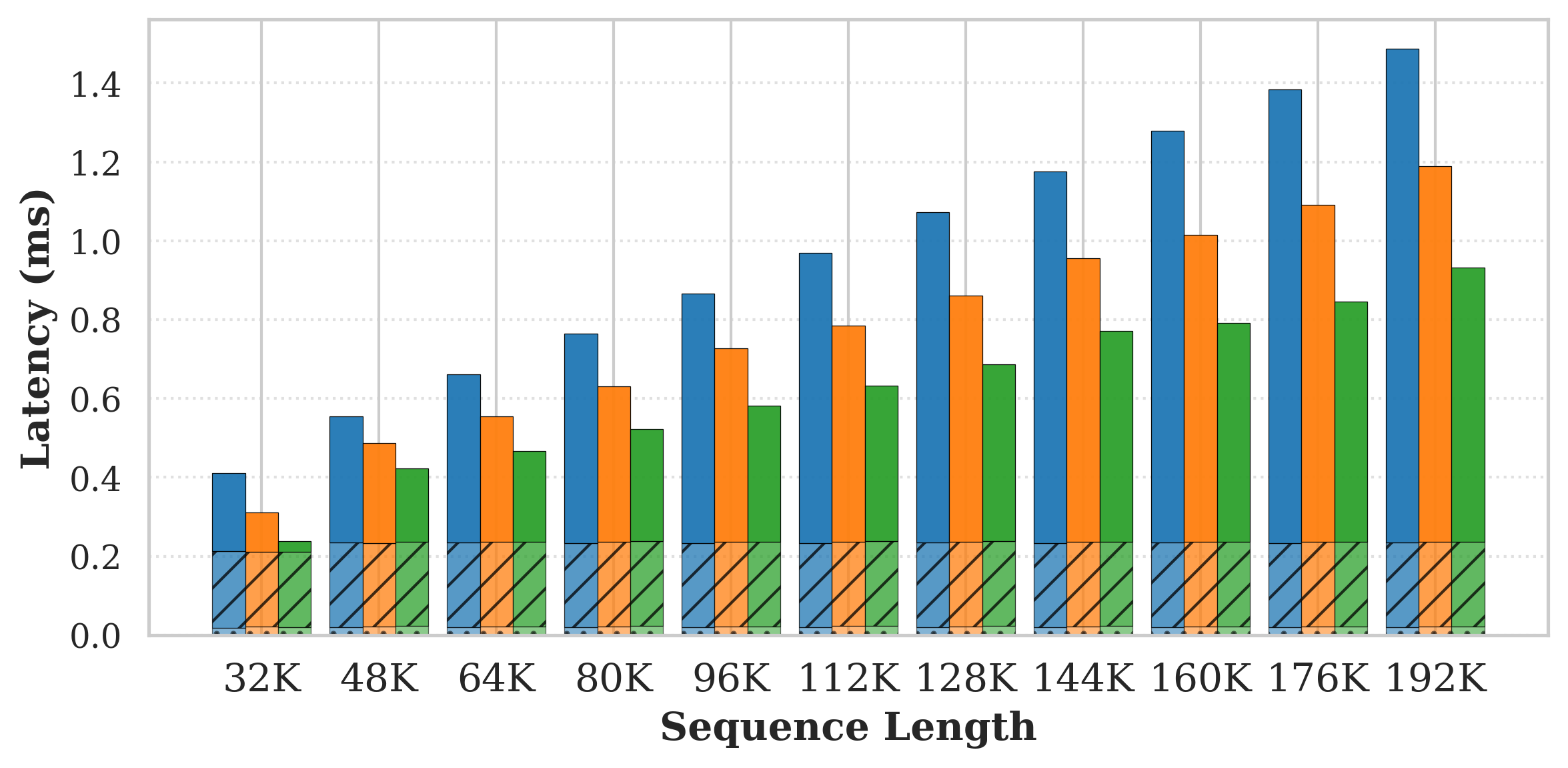
Figure 6: Per-layer prefill latency breakdown against sequence length.
Latency Scaling
For Llama-3.1-8B-Instruct at 16×85K sequence length, HieraSparse reduces TTFT by 16×86 and TPOT by 16×87 at high sparsity, while decreasing peak memory from 16×88 GiB to 16×89 GiB.
Implications and Future Work
HieraSparse demonstrates that hierarchical, semi-structured, hardware-compatible sparsity is the optimal point for balancing efficiency and controllable generation quality in long-context LLM inference. Its approach is orthogonal and potentially synergistic with quantization, block-retrieval, prefix sharing, and further system-level KV offloading mechanisms.
Future research directions highlighted in the paper include:
- Integration with Advanced Pruning: Incorporating fine-grained or learned sparsity patterns using recent advances in learnable or adaptive sparsity (e.g., MaskLLM, SlimLLM) to further close the accuracy gap with unstructured pruning on critical attention regions.
- Hybrid Techniques: Combining HieraSparse with quantization, differentiated memory management (e.g., DiffKV), and block/tile-based KV reuse for maximal system-level benefit.
- Hardware-Software Co-Design: Mapping unstructured or arbitrarily-patterned KV sparsity efficiently onto modern accelerators via techniques exemplified by TASDER or VENOM.
Conclusion
HieraSparse provides a robust, hardware-efficient solution to the most acute bottlenecks of long-context LLM inference, marrying practical cache compression with real attention acceleration. Its hierarchical, semi-structured framework achieves high sparsity-efficiency conversion, supports flexible trade-offs for diverse inference scenarios, and is extensible to further hardware and algorithmic advances. The future of efficient LLM deployment—especially on resource-constrained or cloud-based systems—will likely incorporate hierarchical semi-structured sparsity as a foundational technique.
Reference: "HieraSparse: Hierarchical Semi-Structured Sparse KV Attention" (2604.16864)