- The paper demonstrates that semantic chunking's performance gains are inconsistent and often do not justify its computational cost.
- It evaluates fixed-size, breakpoint-based, and clustering-based chunkers using proxy tasks like document retrieval, evidence retrieval, and answer generation.
- The findings suggest that fixed-size chunking can offer competitive performance with greater efficiency, challenging the practical benefits of semantic segmentation.
Is Semantic Chunking Worth the Computational Cost?
The paper "Is Semantic Chunking Worth the Computational Cost?" explores the effectiveness of semantic chunking within Retrieval-Augmented Generation (RAG) systems, scrutinizing its computational demands versus its contribution to performance gains in retrieval tasks. The study evaluates chunking techniques to ascertain whether the benefits of semantic segmentation substantiate its computational overhead compared to fixed-size chunking.
Introduction to Semantic Chunking
Semantic chunking aims to improve retrieval by dividing documents into semantically coherent segments, contrasting with fixed-size chunking which splits documents into uniform segments without regard to content. Despite the intrigue surrounding semantic chunking, systematic evidence proving its superiority in enhancing performance remains elusive. This paper addresses this gap by evaluating semantic versus fixed-size chunking using proxy tasks: document retrieval, evidence retrieval, and answer generation. The results challenge the assumed supremacy of semantic chunking, highlighting that its advantages are inconsistent and often fail to justify the computational burden.
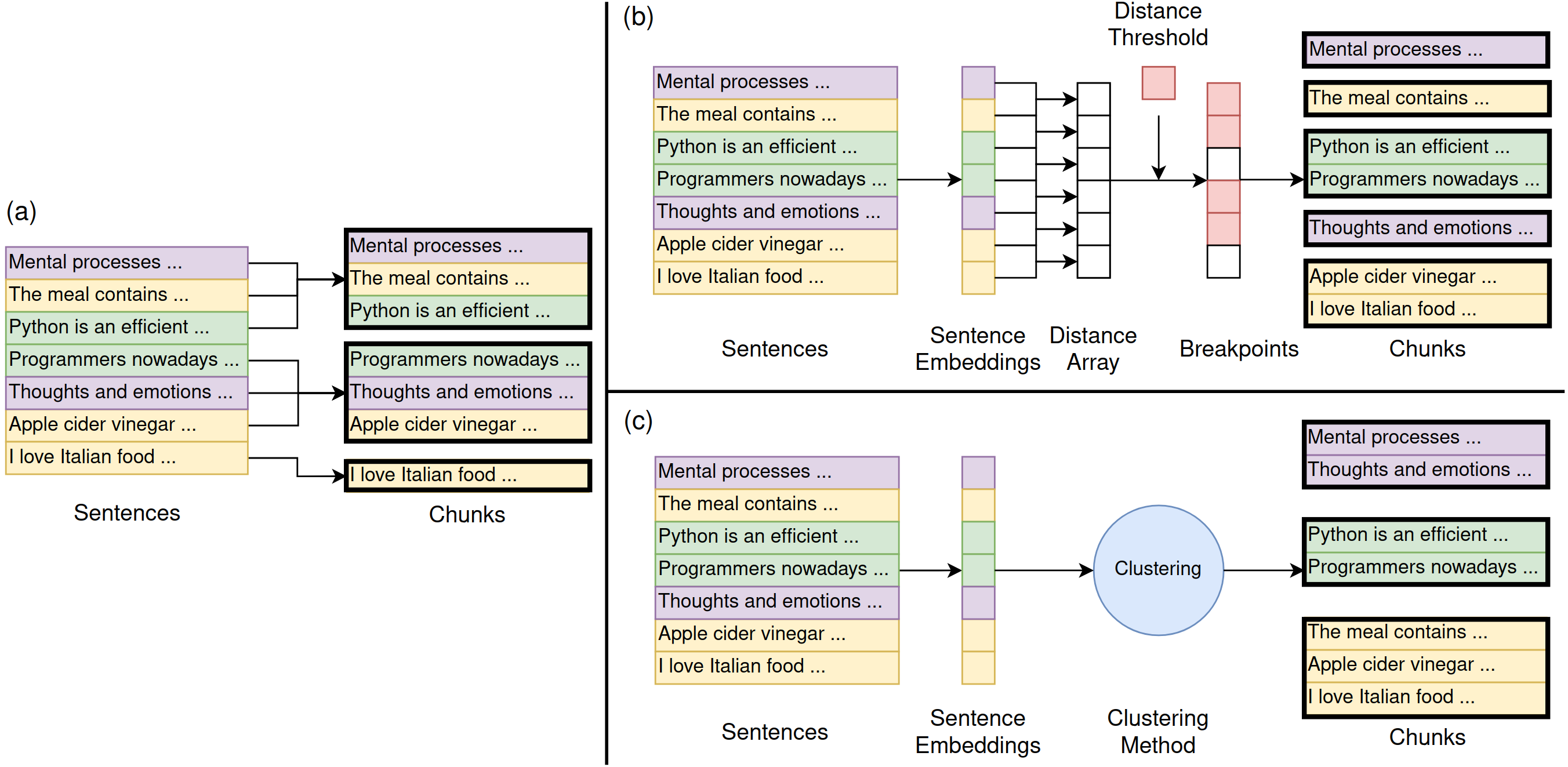
Figure 1: Illustration of the chunking methodologies utilized in the study, contrasting fixed-size with semantic segmentations.
Chunking Strategies
The researchers implemented three chunking techniques:
- Fixed-size Chunker: Divides documents sequentially into chunks of predetermined, uniform sizes, occasionally employing sentence overlap for context continuity.
- Breakpoint-based Semantic Chunker: Segments documents upon detecting semantic distance thresholds surpassing predefined limits, signaling significant topic shifts.
- Clustering-based Semantic Chunker: Utilizes clustering algorithms to group semantically akin sentences, allowing non-sequential grouping with consideration for positional and semantic distance.
The chunkers were assessed on their ability to retain contextual integrity across varied document styles, revealing potential shortcomings in semantic chunking applications.
Experimental Framework
The lack of ground-truth chunk data necessitated the indirect evaluation using proxy tasks:
- Document Retrieval: Evaluates the chunkers' capability in identifying relevant documents.
- Evidence Retrieval: Assesses chunkers' precision in locating ground-truth sentences.
- Answer Generation: Tests the quality of generative model-outputted answers using retrieved chunks.
The absence of real-world chunking data led to synthesized experiments utilizing stitched documents to simulate typical content diversity, challenging the assumptions of semantic chunking efficacy.

Figure 2: Example of chunking a stitched document displaying different chunkers' sentence assignments.
Experimental Results
Document Retrieval
Semantic chunkers demonstrated marginal advantages in environments with high topic diversity, outperforming fixed-size chunkers primarily in synthesized datasets. However, on standard datasets, Fixed-size Chunkers frequently exhibited superior performance. The findings propose that semantic chunking's perceived benefits are, perhaps, artifacts of synthesized evaluations, suggesting a minimal edge over fixed-size techniques in practical scenarios.
Evidence Retrieval
Although Fixed-size Chunkers surpassed semantic chunkers on specific datasets, differences remained negligible across various conditions, inferring that embedding models might exert a larger influence than chunking strategy itself.

Figure 3: Example showcasing chunking a normal document revealing sentence-to-chunk assignment accuracy.
Answer Generation
Semantic chunkers demonstrated slight performance improvement in answer quality, evaluated using semantic similarity metrics like BERTScore, though differences were generally inconclusive.
Conclusion
The study concludes that while semantic chunking occasionally yields benefits, it remains context-dependent and does not consistently outweigh the computational costs. The efficacy of semantic chunkers is highly contingent on document context and length, suggesting that fixed-size chunking continues to be a viable option in RAG systems. Future research should focus on developing chunking strategies that better leverage the trade-offs between computational efficiency and performance, emphasizing embedding quality and contextual richness alongside segmentation methodologies.