- The paper introduces a unified taxonomy of document chunking strategies, comparing structure-based, semantic, and contextualized methods in dense retrieval.
- It demonstrates that structure-based methods excel in in-corpus retrieval, while LLM-guided approaches, like LumberChunker, yield significant gains for in-document tasks.
- The study highlights that contextualized chunking boosts performance for LLM-based approaches in corpus-level tasks but can reduce discriminability in intra-document retrieval.
Introduction
This paper systematically investigates and unifies the fragmented literature on document chunking—a crucial preprocessing step for dense retrieval systems constrained by fixed-size input windows. Dense retrieval architectures, pervasive in tasks from web search to RAG, require documents to be split into smaller units (“chunks”) for effective encoding and retrieval. Despite the prevalence of chunking in practical systems, prior studies have evaluated disparate chunking strategies in isolation, using different retrieval tasks and evaluation metrics, impeding rigorous comparison and holistic understanding.
The authors address these deficiencies by introducing a unified analytical taxonomy for chunking strategies, encompassing both segmentation methods (structure-based, semantic, LLM-guided) and embedding paradigms (pre-embedding chunking, contextualized chunking). They perform a reproducible comparative evaluation across both in-corpus (standard IR) and in-document (needle-in-a-haystack) retrieval tasks, spanning multiple datasets and SOTA embedding models.
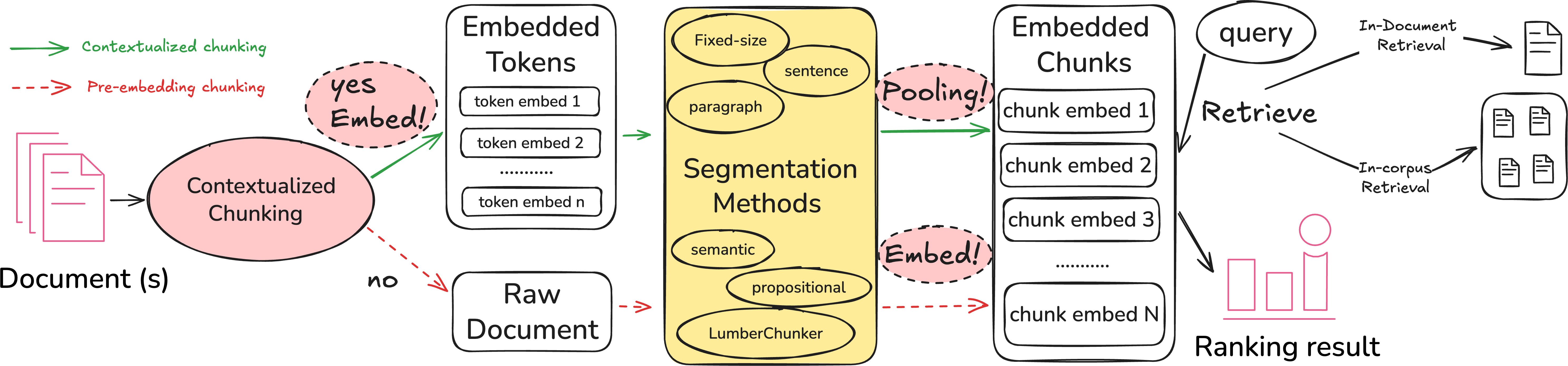
Figure 1: Unified framework for evaluating document chunking strategies across retrieval tasks.
Taxonomy of Chunking Strategies
The paper delineates chunking strategies along two axes:
1. Segmentation Methods:
- Structure-based methods: Include fixed-size, sentence, and paragraph boundaries. These are deterministic, efficient, and widely used in real-world systems due to their simplicity.
- Semantic and LLM-guided methods: Employ neural models or LLMs for segmentation, seeking semantically coherent boundaries. Notable approaches include semantic similarity-based boundaries, proposition-based chunking (LLM decomposes text into atomic facts), and LumberChunker (LLM identifies topic shifts to insert breakpoints).
2. Embedding Paradigms:
- Pre-embedding chunking: Documents are segmented prior to embedding, with each chunk processed in isolation.
- Contextualized chunking (a.k.a. late chunking): The document is first embedded as a whole, producing token-level embeddings with broad context, then segmented post hoc—potentially capturing inter-chunk context in the final pooled chunk representations.
The authors formalize this taxonomy into a unified evaluation framework that enables consistent empirical analysis of chunking strategies across multiple retrieval scenarios.
Experimental Framework
Experiments cover both in-corpus retrieval (six BEIR datasets across various domains) and in-document retrieval (GutenQA), leveraging four embedding models (Jina-v2, Jina-v3, Nomic, E5-large). Effectiveness is measured with nDCG@10 (BEIR) and DCG@10 (GutenQA), using well-defined max-pooling and per-chunk evaluation protocols to ensure comparability.
Key experimental controls include matching embedding models and datasets across strategies, robust statistical analysis, and rigorous reproduction of major prior chunking studies (LumberChunker, Late Chunking) for validation.
Empirical Findings
RQ1: Segmentation Methods for In-Corpus Retrieval
Structure-based methods—specifically paragraph-based and fixed-size segmentation—consistently outperform semantic and LLM-guided alternatives for in-corpus retrieval, regardless of embedding model. The effectiveness gaps are minimal among structure-based variants, whereas LLM-guided and especially proposition-based methods degrade performance, often significantly. Despite the sophistication of LLM-based boundaries, their computational overhead and lack of empirical advantage render them impractical for this use case.
RQ2: Task Generalization of Segmentation Methods
Effectiveness rankings invert for in-document retrieval: LumberChunker significantly outperforms structure-based methods on GutenQA, with notable improvements over paragraph segmentation (10–30% gain). Proposition-based methods remain relatively weak but improve compared to their poor in-corpus results. This task dependency is attributed to the need for distinguishing relevant passages within documents—LLM-guided topic shifts yield more discriminative, contextually aligned chunk boundaries in well-structured documents.
RQ3: Efficacy of Contextualized Chunking
Contextualized chunking yields large relative effectiveness gains for LLM-guided approaches in in-corpus retrieval (notably for proposition-based segmentation, which sees up to +27% relative improvement with certain models), but does not surpass structure-based methods in absolute terms.
However, contextualized chunking degrades in-document retrieval effectiveness across all configurations. The embeddings encode global document themes, reducing the discriminability of relevant and non-relevant chunks within the same document, which is detrimental in tasks requiring fine-grained identification.
Model architecture and context window size modulate these effects: models allowing longer context windows (Jina-v2, Jina-v3, Nomic) benefit more from contextualized chunking in in-corpus tasks, while E5-large shows mixed or even negative results given its shorter context window.
RQ4: The Influence of Chunk Size
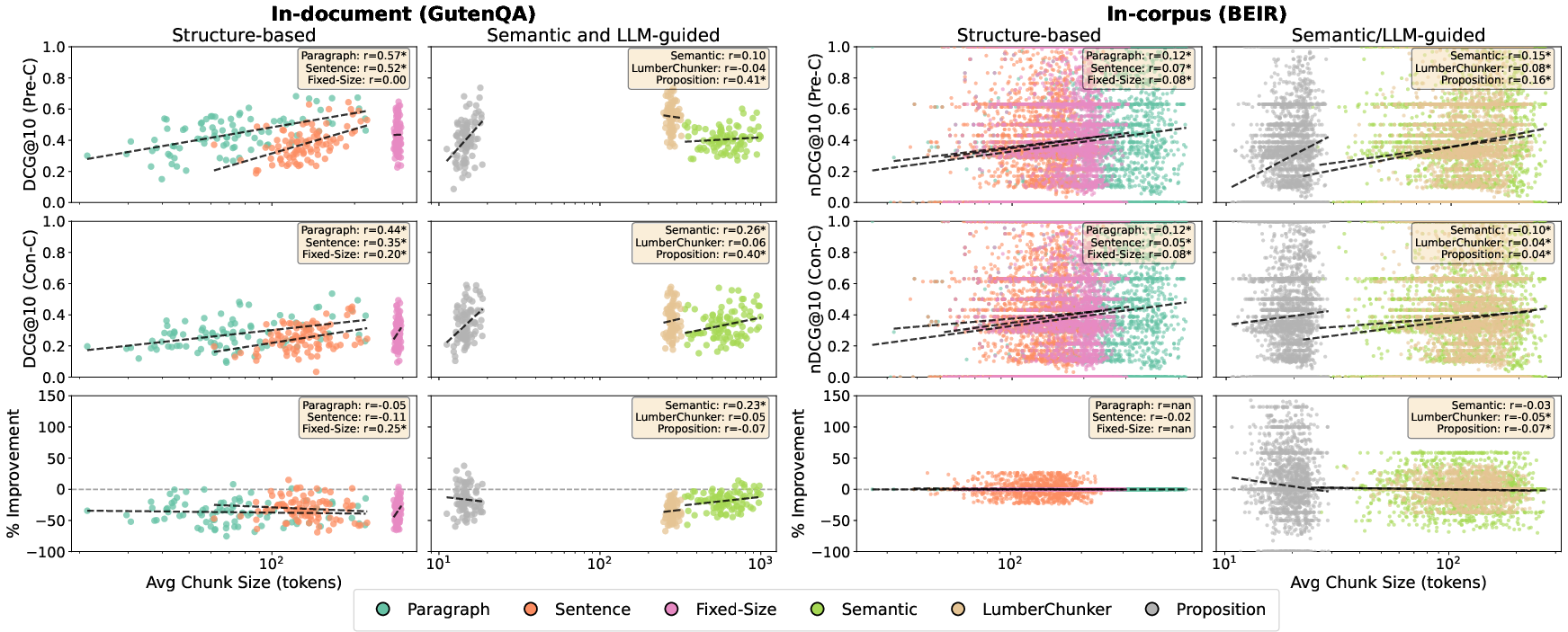
Figure 2: Per-query correlation between chunk size and retrieval effectiveness for Jina-v3 in both in-document and in-corpus retrieval; moderate correlation is observed for in-document retrieval, weak for in-corpus.
Chunk size exhibits a moderate positive correlation with in-document retrieval effectiveness, but only a weak correlation with in-corpus effectiveness. Contextualized chunking attenuates this effect but does not eliminate it. The benefits of contextualized chunking are not strictly dependent on chunk size, indicating that segmentation quality rather than chunk length primarily determines retrieval performance.
Implications and Future Directions
This work unequivocally demonstrates that optimal chunking strategies are task-dependent:
- Practitioners should employ structure-based segmentation (paragraph or fixed-size) for in-corpus retrieval, balancing simplicity, speed, and effectiveness.
- For in-document retrieval on structured documents, LLM-guided (LumberChunker) segmentation is preferable, despite its computational cost.
- Contextualized chunking can enhance LLM-guided chunking in in-corpus tasks but must be avoided in applications demanding intra-document discrimination.
Theoretically, these findings clarify the nuanced interplay between chunk boundary semantics, embedding paradigm, document structure, and retrieval setting. They also underscore the importance of broad, cross-task evaluations in IR preprocessing research.
Potential avenues for future investigation include adaptive discrimination strategies for unstructured documents, efficient approximations of LLM-guided chunking, and end-to-end optimizable chunking methods directly targeting retrieval metrics. Integration of chunking with retrieval-aware pooling objectives or context window adaptation in encoder architectures may yield further improvements.
Conclusion
This study delivers a comprehensive, reproducible benchmark and taxonomy of document chunking methods for dense retrieval. The authors conclusively establish practical recommendations: utilize structure-based chunking for corpus-level search, LLM-guided chunking for document-level passage retrieval, and contextualized chunking selectively for LLM-guided strategies in in-corpus tasks. These contributions provide a solid empirical and conceptual foundation for future advances in retrieval-centric document segmentation (2602.16974).