- The paper presents HiChunk, a framework that enhances RAG performance by employing hierarchical chunking to optimize document segmentation.
- It introduces HiCBench, a benchmark that rigorously evaluates multi-level chunking methods using curated datasets and synthesized evidence-dense Q&A pairs.
- Experimental results demonstrate that HiChunk improves evidence recall and response accuracy across diverse retrieval scenarios using the Auto-Merge algorithm.
HiChunk: Evaluating and Enhancing Retrieval-Augmented Generation with Hierarchical Chunking
This paper discusses the development of HiChunk, a framework designed to enhance Retrieval-Augmented Generation (RAG) systems by focusing on hierarchical chunking. The study identifies existing gaps in RAG evaluation concerning document chunking quality and introduces HiCBench, a benchmark tailored for assessing this aspect. This paper presents a novel multi-level document structuring method and evaluates its efficacy using extensive experiments and comparisons.
Introduction to Retrieval-Augmented Generation
RAG systems augment LLM responses by retrieving relevant content from external knowledge sources, thereby mitigating hallucinations and enhancing response accuracy. Document chunking, which involves segmenting documents into meaningful units, plays a crucial role in defining the quality of retrieved content. Poor chunking may result in fragmented or irrelevant information retrieval, thereby weakening the overall performance of RAG systems. The research highlights the inadequacy of existing benchmarks in effectively evaluating document chunking methods because of evidence sparsity, leading to the introduction of HiCBench.
HiCBench: A Benchmark for Hierarchical Chunking
HiCBench is introduced as a benchmark to evaluate chunking methods, documents, and the entire RAG pipeline more comprehensively. It encompasses:
- Manually curated multi-level chunking points,
- Synthesized evidence-dense question-answer pairs,
- Corresponding evidence sources.
HiCBench leverages documents sourced from OHRBench, integrating documents of suitable lengths and annotated chunking points at various hierarchical levels. This setup ensures that chunking methods can be evaluated accurately in terms of performance enhancement throughout the RAG pipeline.
HiChunk Framework Description
The HiChunk framework extends beyond linear document structures by implementing hierarchical chunking, allowing for adaptive granularity adjustment during retrieval. The framework uses fine-tuned LLMs for document structuring and introduces the Auto-Merge retrieval algorithm, optimizing retrieval quality by dynamically adjusting the granularity of retrieved segments based on the query context.
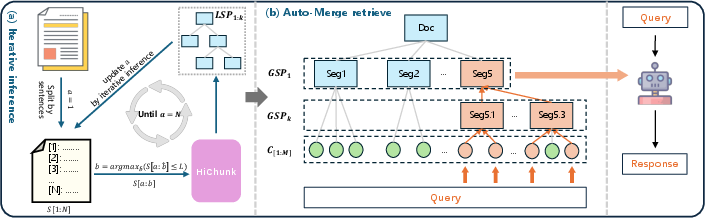
Figure 1: Framework. (a) Iterative inference for HiChunk on long documents. (b) Auto-Merge retrieval algorithm.
Iterative Inference on HiChunk
The inference procedure splits documents into sentence-level tokens, producing hierarchical chunk points iteratively. This strategy optimizes processing of exceedingly long documents, ensuring effective segmentation without compromising semantic integrity.
Auto-Merge Retrieval Algorithm
The Auto-Merge retrieval algorithm enhances chunk retrieval by leveraging hierarchical document structures, merging retrieval nodes adaptively based on specified conditions. This facilitates retrieval of information at appropriate levels of abstraction, optimizing semantic completeness while maintaining hierarchical relationships.
Experimental Evaluation
Chunking Accuracy
Experiments comparing various chunking methods revealed that the HiChunk framework offers superior accuracy. Traditional benchmarks such as Qasper and Gov-report were used, evidencing HiChunk's capacity for improved chunk point prediction, particularly in hierarchical settings.
HiChunk consistently outperformed other methods across multiple datasets, showing significant improvements in evidence recall and response quality. HiCBench, with its focus on evidence-dense QA, demonstrated HiChunk's advantage in optimizing RAG processes more effectively than fixed or single-level chunking methods.
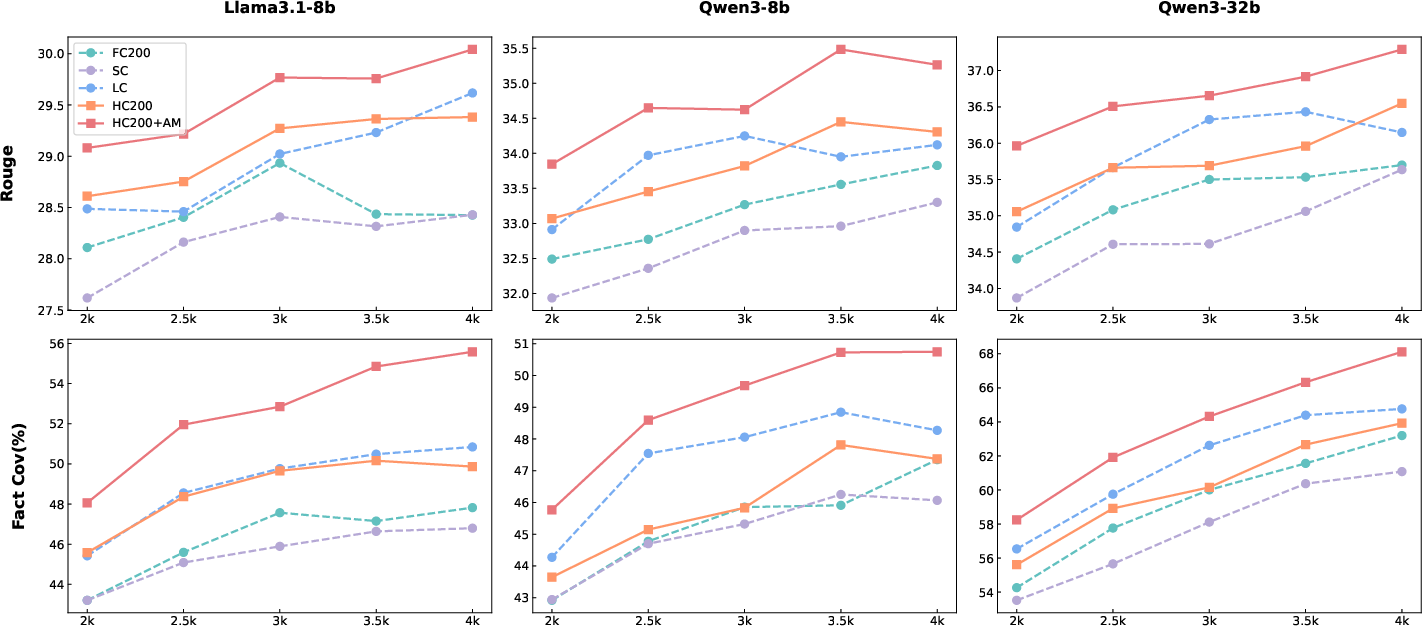
Figure 2: Performance of HiCBench(T_1) under different retrieval token budget from 2k to 4k.
Influence of Maximum Hierarchy Levels
The evaluation of document structures with varying maximum hierarchical levels showed HiChunk's robustness in retaining optimal evidence recall and response quality, reinforcing the importance of multi-level chunk representation.
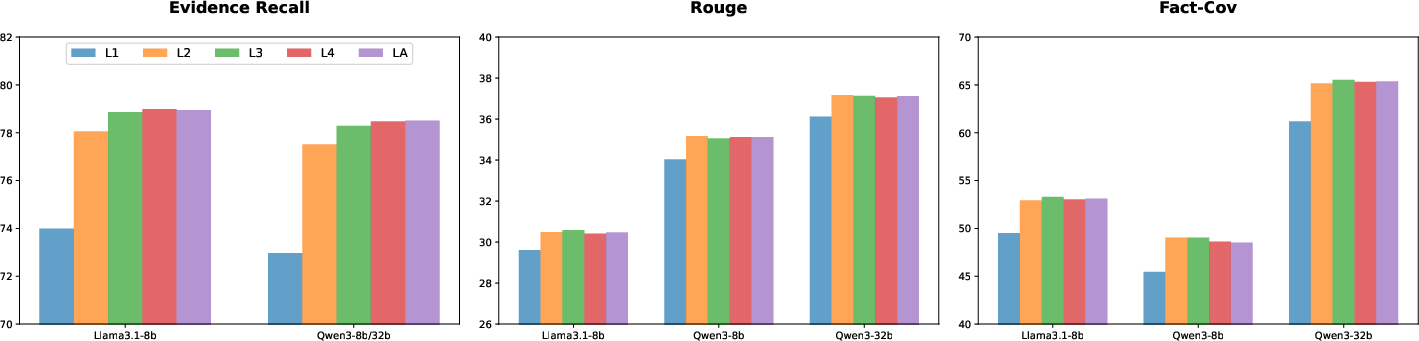
Figure 3: Evidence recall metric across different maximum levels on HiCBench(T_1 and T_2).
Conclusion
The HiChunk framework presents a significant step towards enhancing RAG systems by focusing on hierarchical document structuring and adaptive retrieval techniques. By introducing HiCBench, this work addresses limitations in existing benchmarks, allowing for more rigorous evaluation of chunking methods. The integration of HiChunk into RAG systems represents a promising advancement in improving information retrieval accuracy, paving the way for future research in adaptive document processing techniques.
The paper emphasizes the need for future developments to explore the scalability of the HiChunk framework across varied document types and retrieval scenarios. This trajectory is crucial for adapting to diverse real-world applications of RAG systems.