- The paper introduces AgentVisor, which virtualizes LLM agents by employing a trusted Visor to audit and enforce semantic privilege separation.
- It leverages a structured STI protocol (Suitability, Taint, Integrity) to mitigate both direct and indirect prompt injection while maintaining high utility.
- Experimental results demonstrate near-zero attack success with only a 1.45% average utility decrease and moderate latency overhead across various LLM backbones.
AgentVisor: Semantic Virtualization for Robust Prompt Injection Defense in LLM Agents
Motivation and Security Challenges
The proliferation of LLM agents with tool-usage capabilities has induced a new class of security vulnerabilities, notably prompt injection attacks. The integration of untrusted external data with privileged execution creates direct and indirect prompt injection risks. Direct injection is characterized by adversarial manipulation of user queries to override system instructions; indirect injection exploits hostile content embedded in retrieved context to subvert intended agent behaviors. Existing defenses are brittle—prompt-based hardening is readily bypassed, input/output filtering and guardrails suffer from evasion and utility collapse, and tool-sandboxing is coarse, failing to provide a structured recovery path.
AgentVisor introduces a robust, systematic approach to agent security, inspired by classical OS virtualization paradigms. By enforcing semantic privilege separation, AgentVisor abstracts the target agent as an untrusted Guest and mediates tool calls through a trusted Visor (semantic hypervisor), rigorously auditing privileged actions and providing principled recovery.
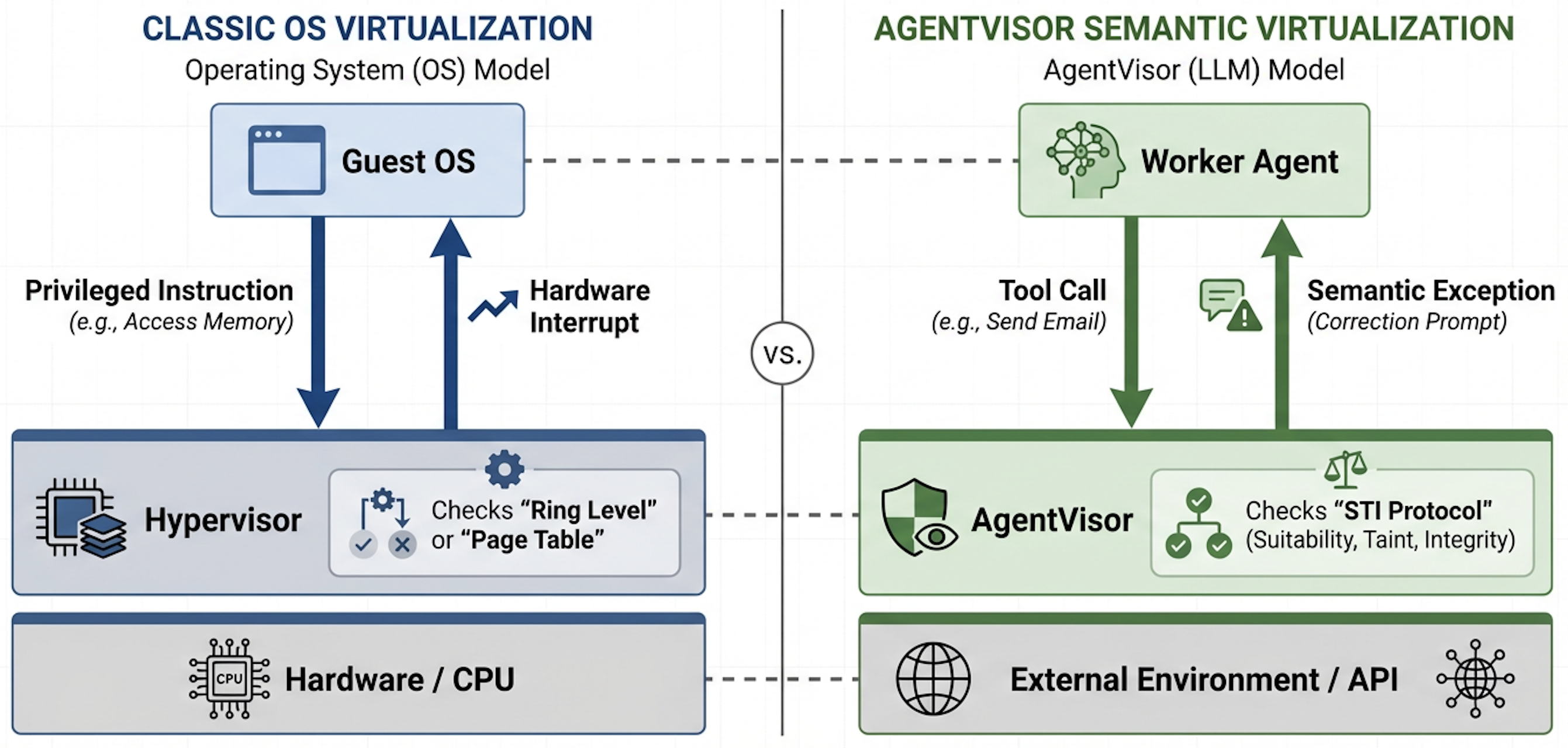
Figure 1: Systematic mapping between OS virtualization concepts and AgentVisor, illustrating translation of classical security primitives into LLM agent semantics.
Architecture and Semantic Isolation
AgentVisor's architecture operationalizes privilege separation: the Visor audits tool-use proposals from the Guest agent, enforcing strict boundaries between trusted (system instruction, user query, sanitized execution history) and untrusted context (external data).
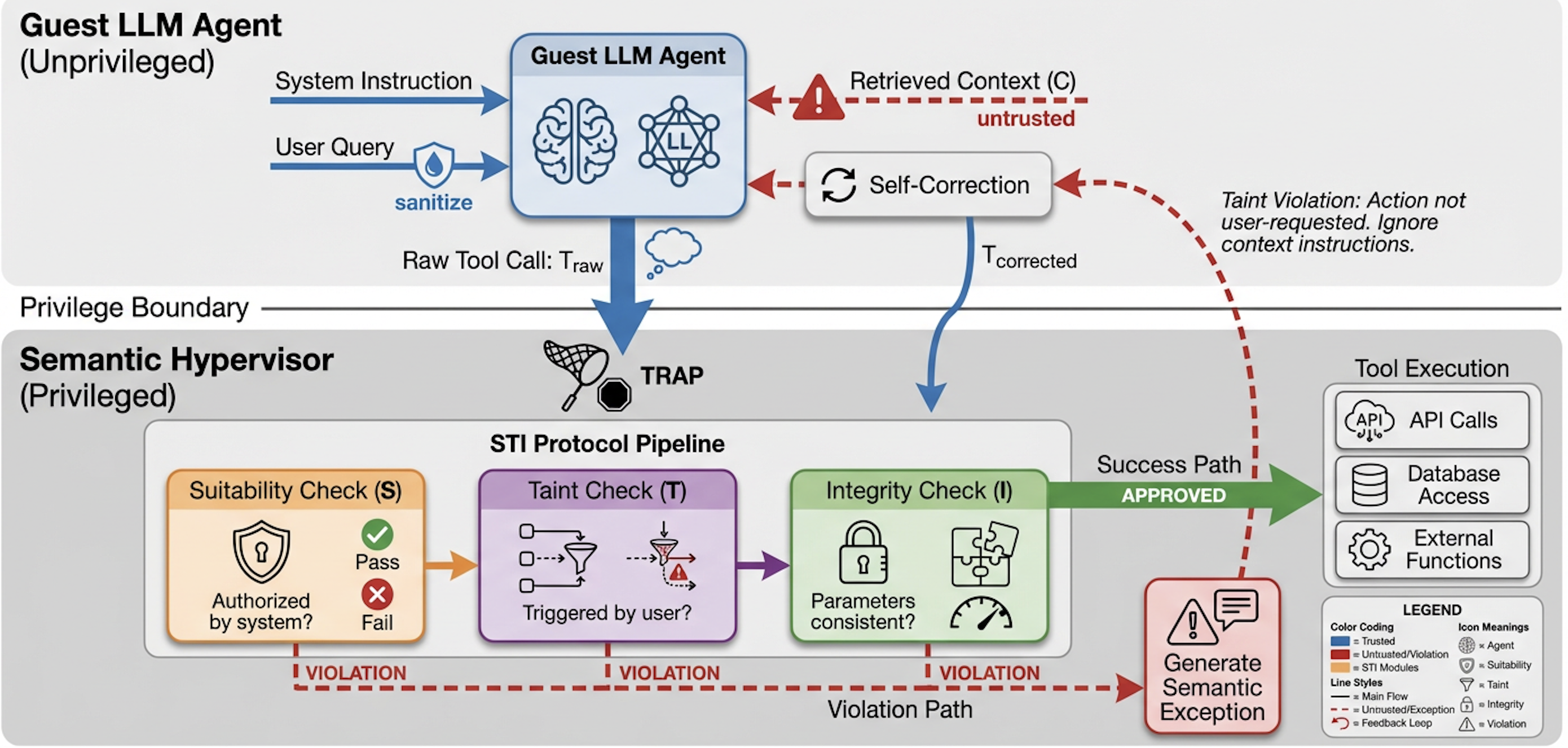
Figure 2: AgentVisor architecture overlays OS virtualization concepts, separating untrusted agent actions (Guest) from trusted audit and control (Visor).
AgentVisor employs a trap–audit–recover loop:
- The Guest proposes a tool call.
- The Visor audits the proposal using the STI protocol (Suitability, Taint, Integrity).
- Unsafe proposals trigger semantic exception injection; the Guest self-corrects once, executing a revised action based on explicit constraints.
Semantic isolation ensures the Visor never directly accesses raw external context, mitigating recursive injection and mixed-intent attacks.
The STI Protocol: Structured Auditing
AgentVisor's audit pipeline comprises three semantically rigorous checks:
- Suitability enforces least privilege, validating tool appropriateness under system policy—critical for direct injection defense.
- Taint verifies alignment between tool invocation and user/task-derived goals, blocking unauthorized objective escalation (effective for indirect injection).
- Integrity enforces consistency of tool arguments with user-specified entities, preventing parameter tampering.
Violation at any stage results in structured exception generation, with machine-readable rationale, violated rule, and corrective constraints. The Guest agent revises its action in response, maximizing utility preservation.
Experimental Findings
AgentVisor achieves significant performance gains over established baselines across direct and indirect injection scenarios, showing a 0.65% attack success rate (ASR) and only 1.45% average utility decrease relative to the No Defense setting. In direct injection, mitigation methods fail to suppress ASR (<50%), and detection approaches induce utility collapse. AgentVisor maintains high utility (UA>83%) while achieving perfect (0.00%) ASR.
In indirect injection, baseline defenses either underperform (UA ∼15%) or react over-defensively. AgentVisor suppresses ASR to negligible levels—even for adaptive and Important attack variants—while preserving high utility.
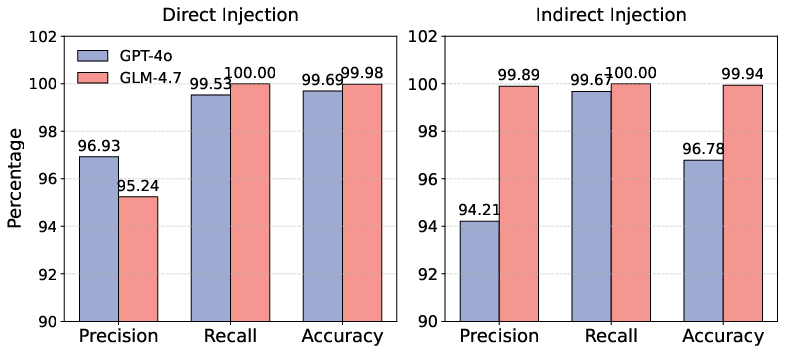
Figure 3: Detection performance of target agents (GPT-4o and GLM-4.7) showcasing awareness–action gap against prompt injection.
Component Analysis and Ablation Studies
Ablation studies quantify the necessity of each STI protocol layer. Removing Suitability sharply increases direct ASR (38.95%), while removing Taint degrades indirect defense (ASR 13.33%). Integrity primarily captures subtle argument tampering. The semantic self-correction mechanism is essential for utility; block-only policies reduce UA to near zero.
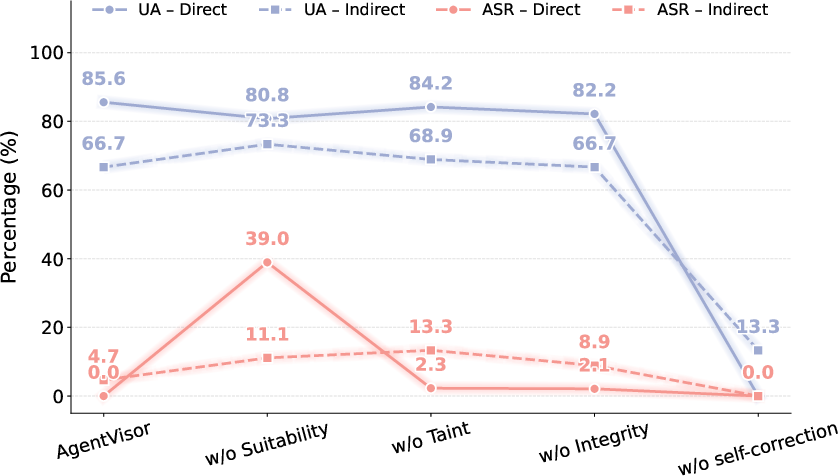
Figure 4: Ablation study demonstrates critical contributions of Suitability, Taint, Integrity, and self-correction for defense efficacy.
Model agnosticism is validated across diverse LLM backbones. AgentVisor consistently achieves near-zero ASR independent of backbone capabilities; stronger models yield higher task completion in self-correction.
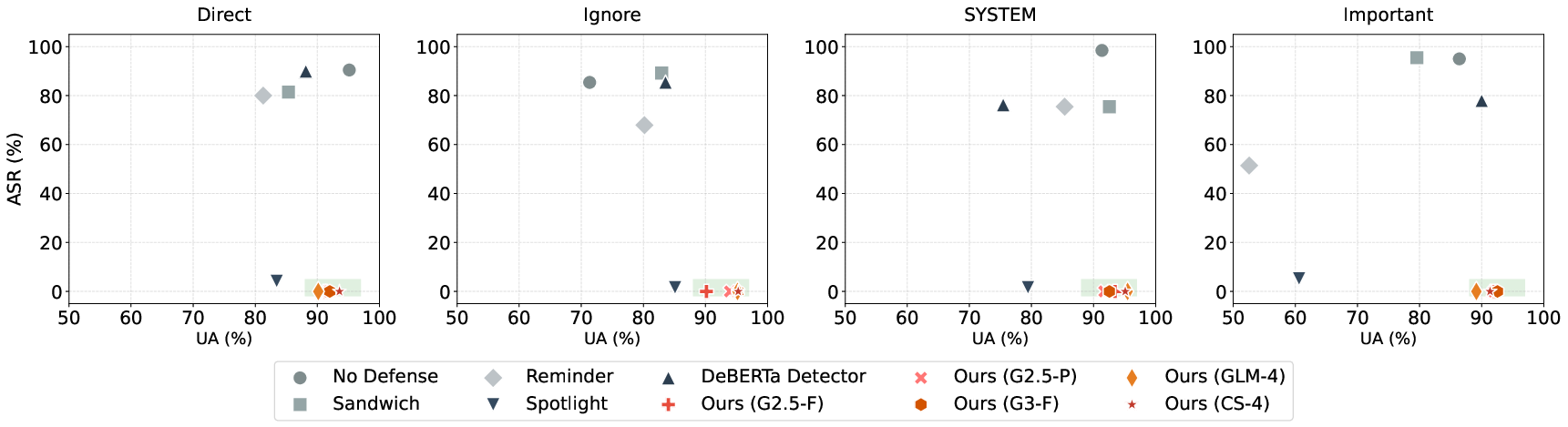
Figure 5: AgentVisor backbone ablation against direct injection confirms robustness across model variants.
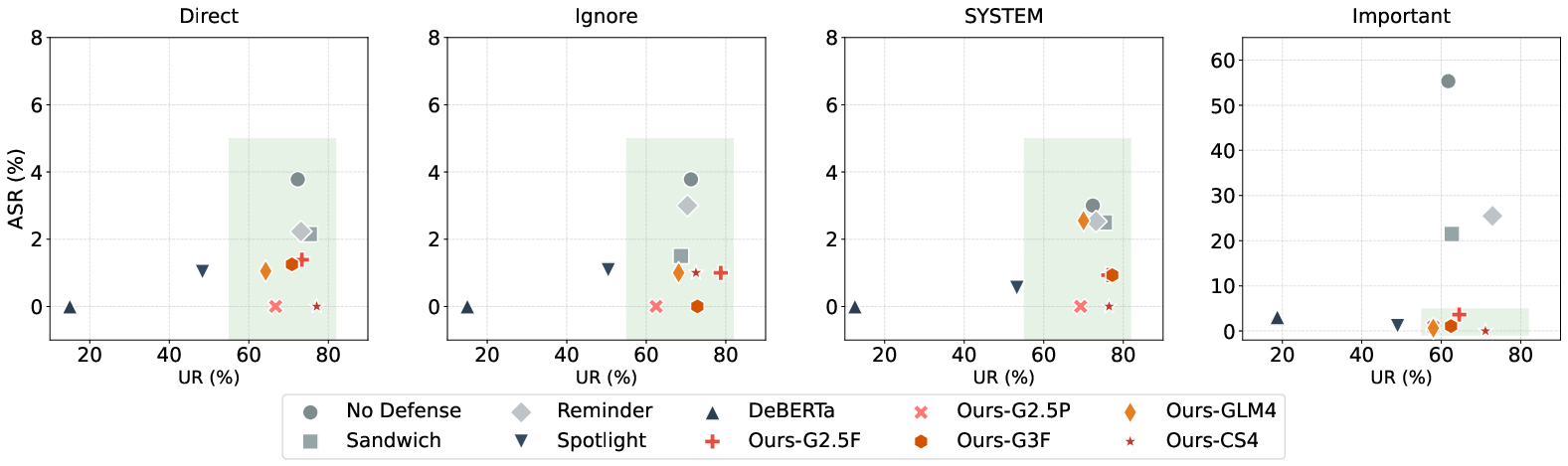
Figure 6: AgentVisor backbone ablation against indirect injection shows systematic defense irrespective of underlying LLM.
AgentVisor is resilient to adaptive attacks (e.g., recursive injections targeting the Visor), maintaining high UA (86.85%) and zero ASR, where naive Visor collapses.
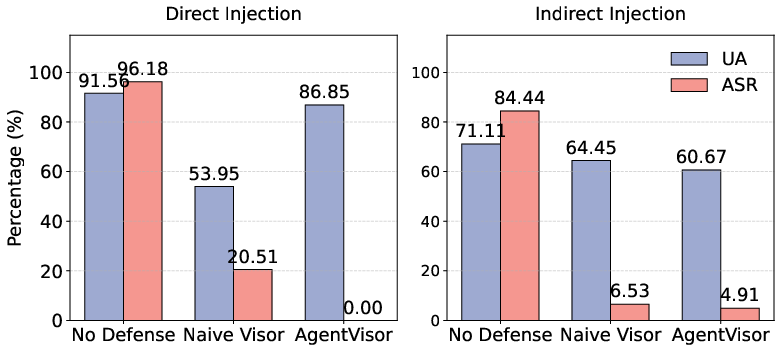
Figure 7: Robustness against adaptive attacks demonstrates complete neutralization with high preserved utility.
Latency and Efficiency Considerations
AgentVisor introduces moderate inference overhead (1.4–2.3x latency), justified by robust safety guarantees and principled one-shot self-correction. Trade-off analysis confirms diminishing utility gains for iterative correction rounds beyond the first.
Theoretical and Practical Implications
Structured semantic virtualization fundamentally advances agent security. By translating OS hypervisor principles to LLM agents, AgentVisor enables systematic policy enforcement, interpretable security audit, and efficient recovery. The STI protocol’s task-agnostic nature provides generalized protection without model-dependent fragility. Practically, AgentVisor is deployable with cost-effective LLMs, supporting robust, scalable agentic workflows in diverse environments.
Theoretically, AgentVisor's methodology paves the way for principled privilege separation and information-flow controls in AI intermediaries. Future developments may involve extending the framework to multimodal agent architectures, improving context scalability, and integrating finer-grained taint tracking as LLMs gain longer context windows and enhanced autonomy.
Conclusion
AgentVisor establishes a robust foundation for defending LLM agents against prompt injection via semantic virtualization, achieving near-zero attack success across benchmark scenarios with minimal utility trade-off. The approach is structurally robust, interpretable, model-agnostic, and efficient, supporting secure deployment of autonomous agents. Future directions include addressing computational overhead, enhancing long-context scalability, and generalizing defenses to multimodal agents.