- The paper introduces a stateful runtime protection architecture for LLM agents, addressing prompt injection and memory poisoning in multi-step workflows.
- It employs a dual-module design with a Runtime Controller for session management and a Core module for risk arbitration and policy control.
- Empirical results demonstrate over a 50% reduction in attack success rates while preserving benign task utility compared to traditional guardrail methods.
SafeAgent: A Runtime Protection Architecture for Agentic Systems
Problem Statement and Context
The emergence of LLM agents with tool-use capability has expanded their operational envelope, integrating complex action selection, memory management, and external environment interaction into dynamic, multi-step workflows. This evolution introduces intricate attack surfaces, especially in the context of prompt injection—where adversarial instructions propagate through heterogeneous inputs, tool outputs, persistent states, and agent memory. Conventional defenses, predominately input/output detection or model retraining, are inadequate for workflow-level attacks that exploit the agent’s persistent context and evolving execution state. The paper "SafeAgent: A Runtime Protection Architecture for Agentic Systems" (2604.17562) directly addresses this defense gap by introducing a stateful, agent-level protection architecture.
Threat Model and Attack Surfaces
Unlike classical LLM prompt injection, agentic prompt injection operates across the entire action-observation loop—malicious instructions may appear in user queries, tool outputs, retrieved evidence, or memory, gradually contaminating the agentic context and causing operational failures rather than isolated output deviations. Composite attacks are further facilitated in multi-step workflows, where injected states persist across agent planning, tool invocation, and memory updates. Notably, direct input-based injection, indirect injection through tool/retriever channels, and multi-stage “memory poisoning” are all considered within the evaluated threat model.
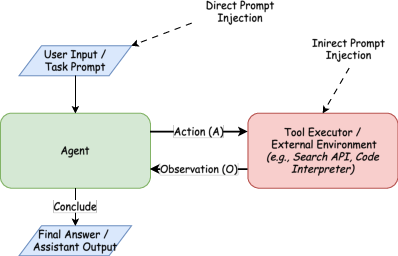
Figure 1: Operation of a ReAct agent and representative attack surfaces in the action-observation loop.
SafeAgent Architecture
The proposed SafeAgent system comprises two architecturally distinct but tightly integrated modules: the Runtime Controller and the SafeAgent Core. This separation abstracts execution mediation from risk-sensitive, context-aware decision making—a design choice that enables resilience and extensibility against evolving threat vectors.
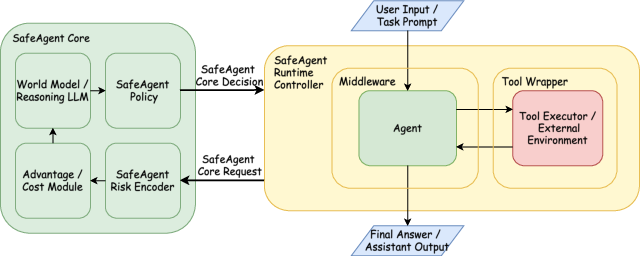
Figure 2: Overview of the SafeAgent architecture.
Runtime Controller
The Runtime Controller serves as a governed interface, insulating privileged operations (tool use, memory update, side-effectful actions) from untrusted agent outputs and observations. It manages a session context across agent lifecycles, curating traceable, auditable records and maintaining a runtime snapshot for rapid intervention. At strategic execution boundaries (input intake, plan emission, observation, and final response), normalized events are dispatched to the Core for risk arbitration. The Controller centrally orchestrates mediation, including recovery-oriented routines—context repair, agent replanning, trajectory checkpoint rollback, session termination, argument sanitization, and escalation for human approval or shadow execution.

Figure 3: Flow control sequence in the agent lifecycle.
SafeAgent Core (Context-Aware Decision Module)
The SafeAgent Core functions as a persistent, stateful, advanced machine intelligence (AMI) layer, operating over partially observable, dynamically evolving session states. The Core receives structured observations and session context, maintains latent world states, and executes a modular decision pipeline:
Evaluation Methodology
SafeAgent is benchmarked on Agent Security Bench (ASB) and InjecAgent, two widely adopted agent security testbeds. ASB comprises 2040 instances involving prompt injection, tool abuse, and persistent context attacks across 51 tasks and 40 attacker tools. InjecAgent evaluates agents across direct-harm and multi-stage (data extraction+exfiltration) attacks, reflecting indirect/latent prompt injection and memory persistence.
SafeAgent’s performance is compared with baseline (no defense), Llama Guard (LLM-based classifier (Inan et al., 2023)), and LLM Guard (RoBERTa-based classifier), using standard metrics: benign performance (PNA), attack success rate (ASR), normalized reward preservation (NRP), and stage-wise data-stealing rates.
Empirical Results and Robustness Analysis
SafeAgent demonstrates pronounced reductions in attack success rates relative to all baseline and guardrail-only defenses under every measured attack vector. It suppresses ASB’s IPI and memory poisoning attack success rates to 0.2936 and 0.1858, respectively—representing more than a 50% relative reduction over the strongest competitor. Notably, NRP is maximized, indicating that SafeAgent enforces safety with minimal compromise of benign task completion (matching LLM Guard’s utility but with fundamentally lower ASR).
On InjecAgent, SafeAgent’s context-governing and stateful tracking completely suppress multi-stage data-stealing attacks (S1 and S2 reduced to zero attack success)—a clear failure case for reactive, text-level guardrails. Llama Guard and LLM Guard, by contrast, allow propagation of (and ultimately action upon) latent adversarial intent, confirming their inadequacy for agentic workflow-level threats.
Detailed Ablation: Policy and Recovery Controls
SafeAgent exposes tunable parameters for override/recovery “confidence” and policy weighting. Conservative recovery settings (lower confidence) favor rejection over repair, limiting recurrent contamination at cost of task utility, particularly effective against persistent “memory poisoning.” Conversely, higher override confidence, which leans toward repair, enhances robustness for direct and isolated context attacks. The operational position in the safety–utility trade-off is primarily determined by the policy objective weighting (safety-first suppresses attacks at a greater utility cost than task-first).
Theoretical Implications and Future Directions
The SafeAgent design formalizes LLM agent security as a stateful, context-dependent decision problem over interaction trajectories, moving beyond static input–output paradigms. Explicit separation of execution governance (Controller) from semantic/inferential risk arbitration (Core) yields resilience, compositionality, and transparency, enabling both fine-grained audit and adaptive deployment. This modularity provides a pathway for compositional augmentation—e.g., integration of hierarchical memory isolation (Wen et al., 7 Feb 2026), tool dependency graphs (An et al., 21 Aug 2025), or taint-tracking propagation (Greshake et al., 2023).
Improvements remain in computational efficiency—particularly the Core’s latency in high-throughput settings and deployment scenarios with tens or hundreds of agents. Richer tool capability constraints, policy programmability, and potential reinforcement-optimized trace selection are promising extensions. Notably, SafeAgent does not claim universal mitigation; “skill injection” and sophisticated workflow subversion remain outstanding challenges. However, it establishes a practical and principled foundation for state-persistent, dynamic agent security intervention.
Conclusion
SafeAgent introduces a rigorous, runtime system for protecting LLM agents in real-world, tool-using settings, characterized by explicit trajectory tracking, governed privileges, and context-aware risk reasoning (2604.17562). Unlike guardrail-based or model-centric approaches, SafeAgent’s stateful architecture offers robust mitigation for evolving prompt-injection and workflow-level threats while maintaining controlled utility degradation. The framework’s modular design anticipates integration with future agentic advances and provides a demonstrably stronger defense baseline for secure agentic AI deployment.
