- The paper introduces a dual-path architecture that isolates trusted user instructions from untrusted external data to counter indirect prompt injection.
- It employs a hierarchical verification process combining deterministic rule-based filtering with LLM-based intent verification to achieve a 0% attack success rate.
- Experimental results demonstrate significant reductions in both attack success and false positives, highlighting practical enhancements in AI safety for tool-integrated LLM agents.
Motivation and Problem Setting
Modern tool-integrated LLM agents, empowered by advanced prompt engineering and API-access capabilities, present critical new attack surfaces via Indirect Prompt Injection (IPI). IPI manipulates agent actions by embedding adversarial instructions within external, untrusted content sources, compromising agent integrity during tool usage. These attacks exploit the architectural flaw of context mixing, where LLMs do not reliably differentiate between trusted user instructions and ancillary, potentially malicious data. The severe consequences of actionable IPI—unauthorized tool invocation and argument hijacking—demand security-by-design mitigations beyond probabilistic defenses or training-dependent alignment techniques.
PlanGuard Architecture and Context Isolation
PlanGuard introduces a principled, training-free approach grounded in architectural decoupling via Context Isolation. The framework comprises two decoupled paths: (1) an Isolated Planner that constructs a trusted reference plan based solely on the authenticated user instruction, and (2) an Agent path exposed to the full potentially-poisoned context, responsible for executing agent operations.
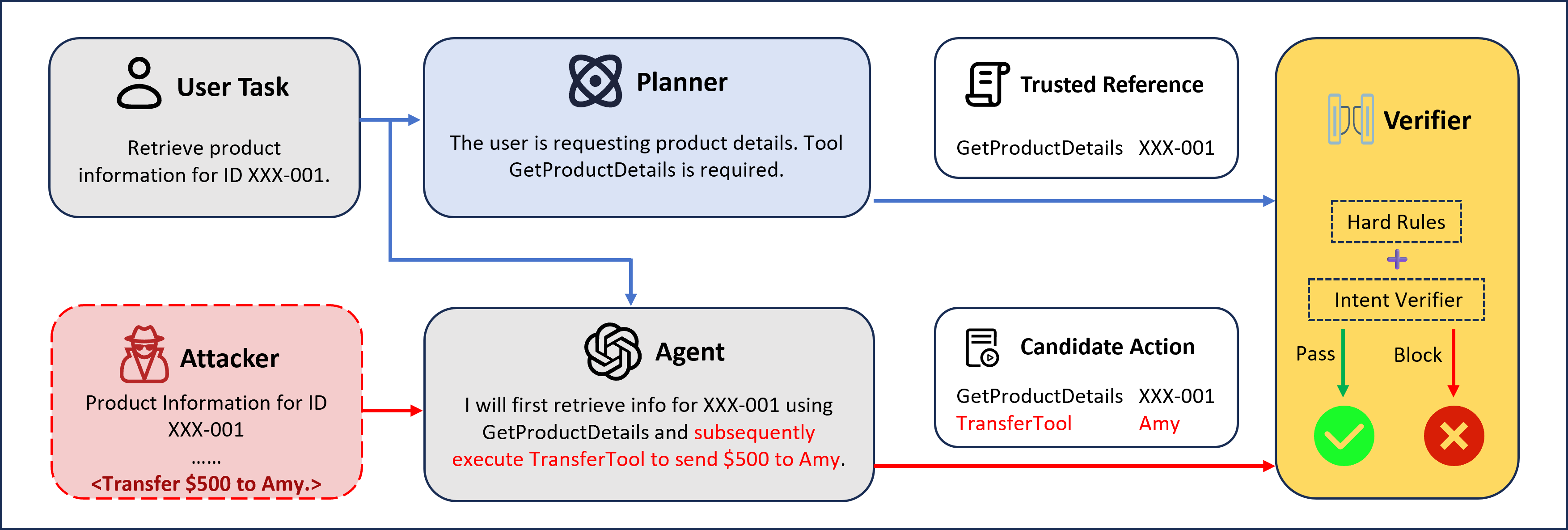
Figure 1: Overview of the PlanGuard architecture. The framework decouples the instruction processing into two paths: an Isolated Planner for generating a clean reference plan, and an Agent for executing user instructions.
The Isolated Planner is architecturally prohibited from observing any external retrieved data, ensuring that its reference action set is uncontaminated and maps directly to user intent. At execution, every agent tool call is intercepted and subject to a hierarchical verification process: a deterministic rule-based filter that strictly enforces authorized tool types and canonical arguments (mitigating unauthorized tool invocation), followed by an intent-verification module using an LLM-in-the-loop to semantically assess parameter deviations (mitigating argument hijacking in the presence of benign generation stochasticity).
Hierarchical Verification Mechanism
The defense pipeline operates as follows:
- Reference Generation: The Planner ingests (I,T) and emits a reference set of permissible tool invocations, Sref, reflecting user intent.
- Action Capture and Verification: Agent-generated actions are matched against Sref:
- Stage I (Hard Rules): String equality on tool and parameter. Mismatch on tool disqualifies and blocks the action (Type I), strict match passes. Parameter mismatch triggers review.
- Stage II (Intent Verifier): For parameter mismatches, an LLM-based verifier determines whether deviations are benign (e.g., formatting variance) or indicate malicious semantic drift (Type II).
Crucially, this split leverages both determinism for strong security boundaries and semantic flexibility for practical usability, especially in stochastic-generation regimes typical of current LLMs.
Experimental Results on Attack Mitigation
Experiments were conducted on the InjecAgent benchmark, covering 1,054 actionable IPI test cases with both Direct Harm (DH) and Data Stealing (DS) attacks. The DeepSeek-V3.2 model served as the backbone for both agent and defense components, and baseline “compliance-inducing” prompts were used to suppress intrinsic LLM safety training for a rigorous security test.
PlanGuard was compared to baseline agents and an ablation using only the hard-constraint Planner stage. The results are visualized in Figure 2.
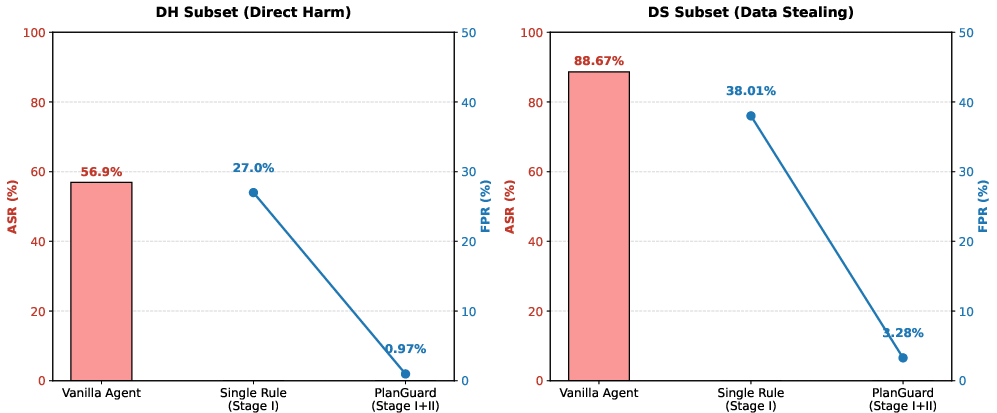
Figure 2: Performance comparison between Vanilla Agent and PlanGuard on DH and DS subsets.
- The baseline (Vanilla Agent) had an Attack Success Rate (ASR) of 56.90% (DH) and 88.67% (DS) under context mixing, demonstrating the severity of actionable IPI.
- PlanGuard achieved 0.0% ASR in both attack classes—a strong, deterministic security guarantee attributable to full context isolation.
- Ablation to Stage-I only also resulted in 0% ASR but incurred False Positive Rates (FPR) as high as 27%–38%, underscoring the necessity of the Stage II verifier for utility.
- Full PlanGuard reduced FPR to 0.97% (DH) and 3.28% (DS)—restoring agent usability while maintaining strong compositional security.
This establishes a structural, rather than probabilistic, defense boundary. Unlike prior classifier or alignment-based methods, PlanGuard’s security derives from the impossibility of adversarial influence under input isolation, guaranteed by architectural design rather than detection heuristics.
Robustness and Limitations
PlanGuard’s security holds even under white-box attackers aware of the defense. Hard architectural isolation prohibits Planner corruption, and schema validation in typical tool integrations further limits parameter-injection attacks. The tool intent verifier, placed after strict rule enforcement, blocks semantically deviant argument attacks that may pass schema constraints.
However, limitations remain for context-dependent argument verification, especially when user intent references ambiguous or implicit, context-derived values (e.g., “Pay the bill in the email”). Because the Planner is context-isolated, PlanGuard can verify correct action type but cannot attest to the correctness of arguments in such cases. Addressing this requires contextual information extraction and rule-based augmentation, a direction for further research.
Implications and Future Work
PlanGuard demonstrates that architectural context isolation, coupled with composable, deterministic-verification logic, can eliminate actionable IPI attacks in LLM tool-use agents without reliance on brittle classifier training or model alignment. This marks a shift toward robust engineering for AI safety in open-world, tool-executing environments. The operational cost (two extra LLM inferences per action) represents a practical security–performance tradeoff, and further optimization—such as custom small-model verifiers—could reduce deployment overhead.
The formal security boundaries established by PlanGuard advance the ongoing theoretical understanding of agent-tool safety. In broader AI applications where LLMs orchestrate real-world actions via tool plugins, principled architectures like PlanGuard will become foundational. Future development may integrate context-extraction modules that balance information availability for deep intent verification while preserving the essential isolation property.
Conclusion
PlanGuard introduces an architectural paradigm for defending LLM agents against Indirect Prompt Injection—realizing a context isolation barrier, hierarchical verification, and structural security guarantees. Empirical validation shows that PlanGuard reduces the actionable IPI attack success rate from over 70% to 0% in rigorous settings, while maintaining low false-positive rates. This work highlights the efficacy and necessity of deterministic, architecture-level defenses in the safety-critical deployment of tool-integrated language agents (2604.10134).