- The paper introduces a cache-centric planning mechanism that leverages plan locality to reduce inference latency and token costs by asynchronously updating cached plans.
- It demonstrates significant performance gains with up to 7.4× latency reduction and 4.8× token cost reduction while achieving high task success rates across multiple benchmarks.
- The hybrid design combines local cache planning with periodic, context-aware LLM updates, enhancing coordination and efficiency in multi-agent embodied scenarios.
AgenticCache: Cache-Driven Asynchronous Planning for Embodied AI Agents
Introduction
"AgenticCache: Cache-Driven Asynchronous Planning for Embodied AI Agents" (2604.24039) addresses the challenging issue of inference latency and token cost in embodied AI agents that rely on LLMs for planning. Leveraging the concept of plan locality—where plan transitions are highly predictable in structured environments—the paper introduces a cache-centric planning mechanism that enables agents to act asynchronously and efficiently without requiring per-step LLM queries.
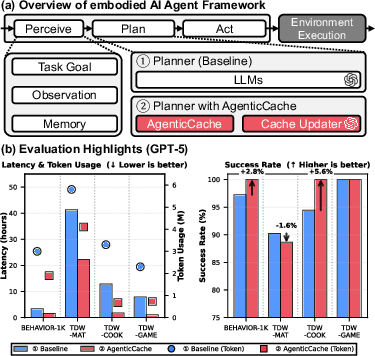
Figure 1: Overview of AgenticCache, illustrating both the embodied AI agent framework and its evaluation highlights with GPT-5.
Background and Motivation
Traditional embodied AI systems typically operate through a perceive-plan-act loop, often relying on handcrafted pipelines attuned to specific domains. Recent advances in LLMs have made them the de facto reasoning cores for embodied agents, replacing rigid pipelines with flexible, high-level decision-making. However, these LLM-driven approaches are hindered by substantial inference latency and cost, often dominating runtime as agents synchronously block on LLM responses at each decision step. Existing parallelization strategies—such as parallelized planning-acting and speculative planning with weaker LLMs—alleviate some latency but still require frequent LLM invocations and suffer from trajectory invalidation in dynamic environments.
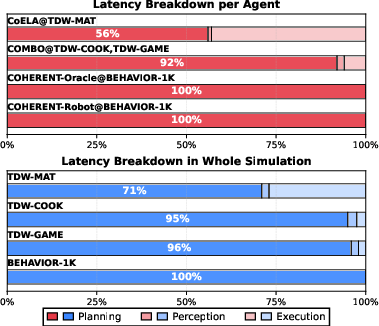
Figure 2: Latency breakdown across agents and benchmarks, confirming LLM query dominance in runtime.
Plan Locality Analysis
The key insight underpinning AgenticCache is plan locality: in multi-agent embodied settings, plan transitions frequently follow predictable short-horizon patterns, exemplified by bigram statistics from episodic execution. Empirical analysis using GPT-5 trajectories demonstrates that successor plans often emanate from a limited set, enabling strategic caching of these transitions.
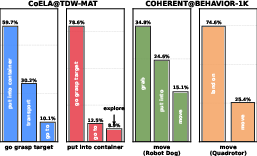
Figure 3: Probability distribution of successor plans under a 2-gram model, showcasing strong locality in GPT-5 execution trajectories.
Nonetheless, pure pattern-based cache exploitation is not robust to environmental changes—cached plans risk becoming invalid if context shifts, such as resource contention or manipulation by other agents. Therefore, hybridization with asynchronous, context-aware LLM-driven updates is necessary.
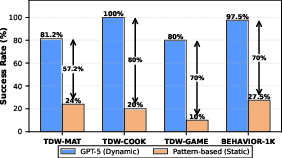
Figure 4: Pattern-based agents exploit plan locality but suffer large performance gaps without context-aware updates.
AgenticCache Framework
AgenticCache operationalizes cache-driven planning via two principal components:
- Local Cache Planner: Each agent maintains a cache of frequent plan-to-plan transitions, keyed by prior plan and task-state metadata. The next plan is selected by maximizing a composite score combining local transition counts and global confirmation frequency from the LLM.
- Asynchronous Cache Updater: A background process periodically queries the LLM to validate cached entries. On confirmation, cache statistics are reinforced; on misprediction, the cache entries are corrected and plan execution is preemptively replaced. Redundant queries are suppressed to minimize token usage, and cache misses prompt direct LLM calls for novel situations.
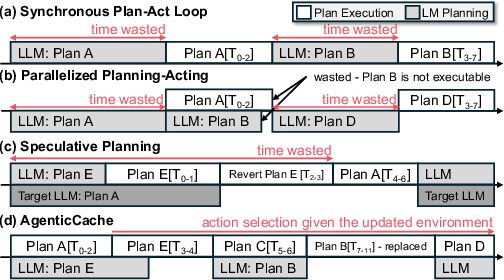
Figure 5: Comparison of synchronous, parallelized, speculative, and cache-driven planning strategies.
A runtime example illustrates continuous agent operations, with plans chosen from the cache, periodically validated, and corrected via asynchronous LLM feedback.
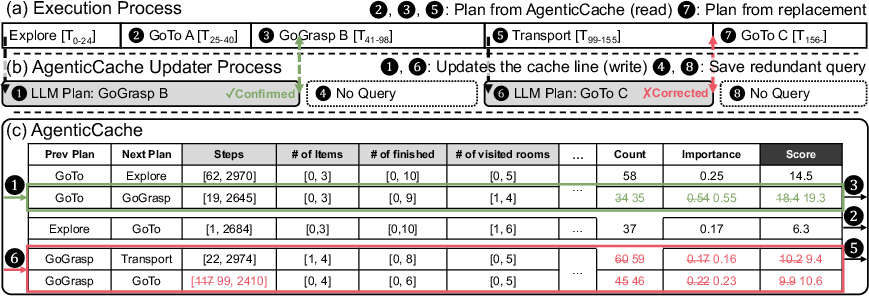
Figure 6: Runtime example of AgenticCache execution, detailing cache-guided plan selection and asynchronous updates.
AgenticCache also supports optional offline cache prefilling with plan transitions from successful prior episodes, further reducing cold-start overhead.
Experimental Evaluation
Extensive evaluation is conducted across four multi-agent embodied benchmarks (TDW-MAT, TDW-COOK, TDW-GAME, BEHAVIOR-1K) and three planner models (GPT-5, GPT-5-mini, GPT-5-nano). The experiments are run on standard hardware with simulated environments for manipulation, cooking, puzzle assembly, and household transport with both centralized and decentralized agent coordination.
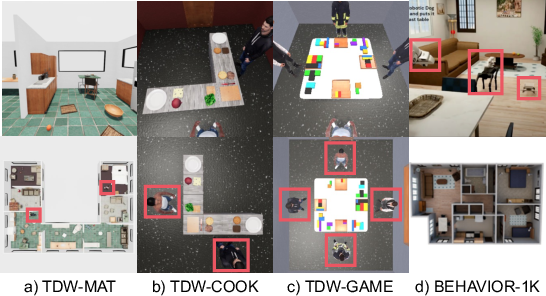
Figure 7: Snapshots from the four benchmark environments with agents highlighted.
Main Results
AgenticCache achieves high task success rates (84–100% with GPT-5 and GPT-5-mini; up to 100% with GPT-5-nano in TDW-GAME), demonstrating robustness in coordination and adaptability. It delivers a 22% average improvement in task success rate, 65% reduction in simulation latency, and 50% reduction in token usage compared to baseline synchronous LLM agents. Latency reductions of up to 7.4× (12.86 hours → 1.75 hours) and cost reductions up to 4.8× are observed.
AgenticCache consistently outperforms parallelized and speculative planners, especially in multi-agent settings where those baselines suffer from environment invalidation and degraded coordination.
Cold-Start and Cache Dynamics
Cache-prefilling is optional; even with cold starts, AgenticCache maintains its efficiency and performance, incurring only transient overhead during cache construction. The cache achieves high hit rates (>66% in structured environments), with minimal memory overhead (typically 0.1–1.0 KB per agent) and controlled growth, as new transitions plateau after early execution.
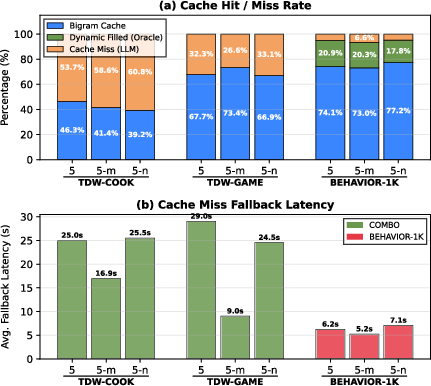
Figure 8: Cache performance across benchmarks and model scales, showing hit/miss rates and fallback latency on cache misses.
Ablation and Validity
Ablation experiments confirm that asynchronous cache updates and plan replacement are synergistic, with each mechanism addressing distinct failure modes. Enabling both yields substantial gains (average success rates of 70.7% vs. 24% for static cache).
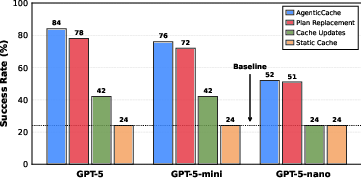
Figure 9: Ablation of AgenticCache components on TDW-MAT; the full system achieves the highest success rate.
Plan execution accuracy is measured by agreement with the reference planner (GPT-5); cache-guided planning steadily improves accuracy with more executions and higher-quality updates with stronger models.
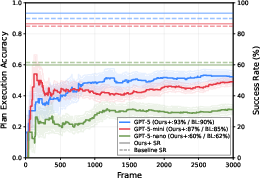
Figure 10: Plan execution accuracy for AgenticCache with GPT-5 variants over time.
Implications, Limitations, and Future Directions
AgenticCache offers a practical architectural analogue to short-term memory in embodied agents, enabling fast recall of behaviorally relevant transitions and reducing LLM dependency through episodic adaptation. The approach is best suited to environments with strong plan locality, as in structured manipulation and coordination tasks. In less structured or open-ended domains, cache hit rates may decline, suggesting opportunities for higher-order caching (e.g., n-gram, hierarchical routines) and learned cache scoring.
Multi-agent coordination poses additional challenges—cache-based plans may conflict at rendezvous points or under resource contention. Extending the cache with coordination protocols and adaptive conflict-resolution will be necessary for broader deployment.
Conclusion
AgenticCache introduces a cache-driven planning paradigm that successfully exploits plan locality in embodied AI agents to reduce inference latency and cost, while maintaining or improving task success rates. Its hybrid architecture, combining fast local cache guidance and asynchronous LLM correction, provides a scalable path toward efficient, responsive, and adaptive agentic systems. The results motivate further exploration of cache-based planning frameworks in diverse agent domains, particularly where short-horizon decisions exhibit regularity and episodic reuse is feasible.