- The paper introduces AgentReuse, an intent-and-parameter-aware framework that achieves a 93% plan reuse rate and reduces latency by over 93%.
- It employs BERT-based intent classification and cosine similarity on deparameterized queries, improving F1 scores by up to 6.8 points compared to baselines.
- The approach streamlines plan generation in LLM-driven agents, offering robust key parameter extraction and structured plan representation for AIoT and mobile applications.
Plan Reuse for LLM-Driven Agents: The AgentReuse Mechanism
Introduction and Motivation
The integration of LLMs into autonomous agents for personal assistance and AIoT tasks has dramatically expanded the expressive and reasoning capacity of such systems. However, the computational and latency costs associated with LLM-based plan generation remain a significant bottleneck. Data-driven analysis demonstrates that approximately 30% of requests to LLM-driven agents are semantically identical or similar, rendering them amenable to plan reuse. However, naive semantic caching approaches, such as vector-based LLM response caching, are insufficient for agent plan reuse due to entanglement of key parameters and unstructured plan representation.
Workflow of LLM-Driven Agents
The canonical workflow employed by LLM-driven agents comprises four phases: (1) the agent receives a user request in natural language, (2) the LLM generates a decomposed plan, (3) the agent dispatches sub-tasks to external tools and aggregates results, and (4) the agent produces a user-facing response. This structure exposes the plan generation latency tp as a dominant factor in the end-to-end response time due to auto-regressive plan synthesis and typically lengthy output sequences.
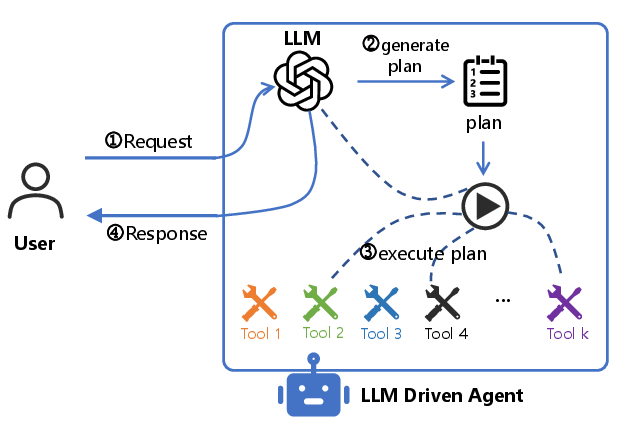
Figure 1: High-level workflow in the LLM-driven agent pipeline, isolating the plan generation and execution stages.
Eliminating redundant tp for similar or identical requests can thus directly improve responsiveness and overall user experience.
Challenges in Plan Reuse
Three core challenges must be resolved to operationalize plan reuse in LLM-driven agent architectures:
- Similarity Definition: Classical embedding-based similarity on raw request strings often fails to recognize structurally equivalent requests with different parameterizations; e.g., "Book a ticket from Hefei to Beijing for the day after tomorrow" vs. "Book a ticket from Changsha to Shanghai for tomorrow."
- Parameter Identification and Replacement: Extracting and slot-filling key parameters (e.g., location, date) is essential, as naive string matching is confounded by natural language variability.
- Structured Plan Representation: Unstructured textual plans generated by the LLM lack the explicit structure for reliable parameter injection and component-level reuse.
The AgentReuse Mechanism
AgentReuse addresses these challenges through an intent-and-parameter-aware framework, incorporating intent classification, robust parameter identification, and structured plan representation.
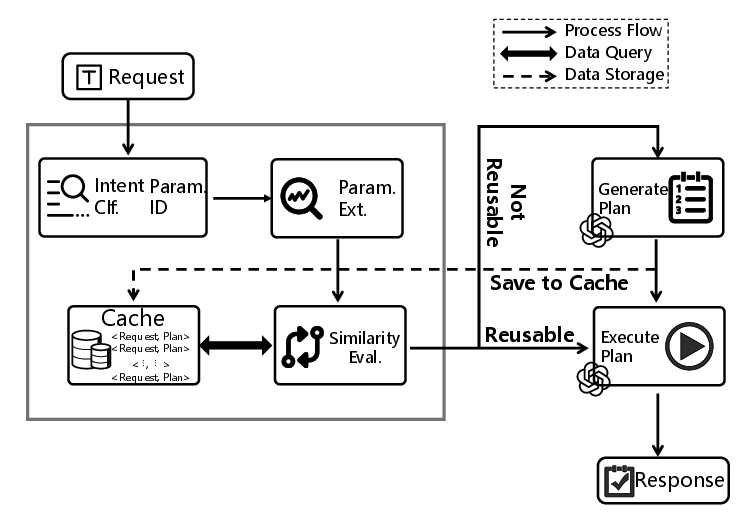
Figure 2: Overview of AgentReuse’s operational flow, including intent classification, key parameter identification, and structured plan entry and retrieval.
Key components include:
Experimental Results
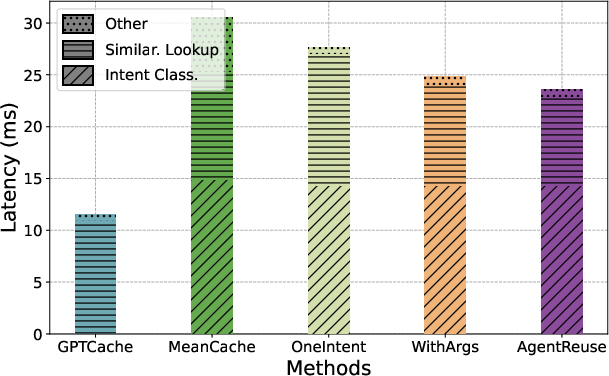
Ablation studies and empirical evaluations on the SMP dialog dataset (2,664 requests, 23 intents) demonstrate strong performance advantages of AgentReuse over prior semantic response caching approaches (GPTCache, MeanCache) and relevant ablations (OneIntent, WithArgs).
- Plan Reuse Accuracy: AgentReuse achieves an effective plan reuse rate of 93%.
- Semantic Similarity Definition: F1 score of 0.9718 and accuracy of 0.9459 at γ=0.75, respectively 6.8 and 13.06 points higher than the strongest competing baseline.
- Latency Reduction: End-to-end system latency is reduced by 93.12% compared to agents without reuse, and by 60.61% compared to GPTCache-based solutions.
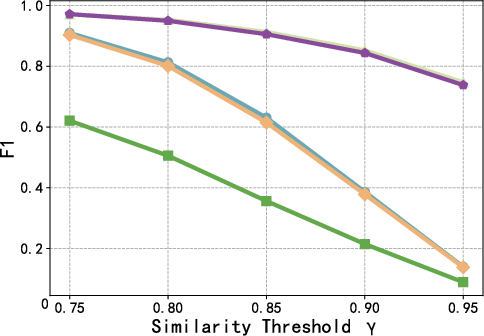
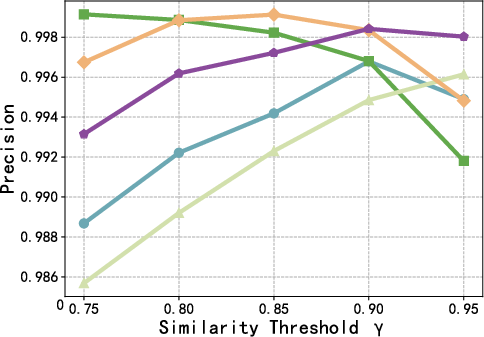
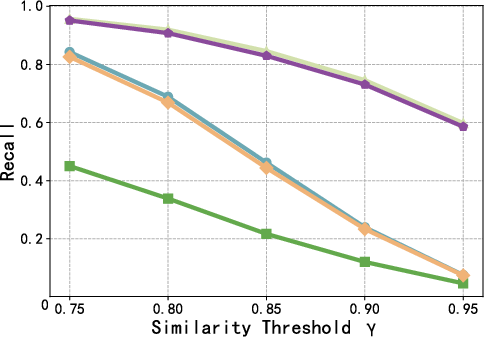
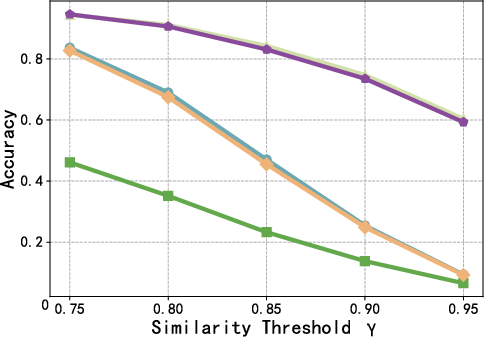
Figure 4: F1 score as a function of the reuse threshold γ, highlighting consistent superiority of AgentReuse across the precision-recall trade-off.
Further, performance is robust to threshold selection. Extraction of key parameters prior to similarity calculation is pivotal; the WithArgs variant, which omits this, exhibits substantially reduced recall and F1.
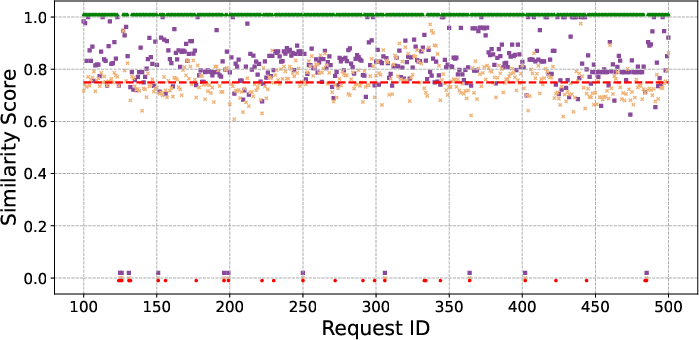
Figure 5: Comparative analysis of similarity scores between AgentReuse (with argument removal) and WithArgs (no argument removal), confirming the importance of parameter delexicalization.
Systemic and Resource Considerations
AgentReuse is designed for tractable system overhead in the deployment context of AIoT and mobile agents:
Theoretical and Practical Implications
The approach demonstrates that the key to effective plan reuse in LLM-driven agents is fine-grained control over intent and argument structure, rather than naive text similarity. Caching at the plan granularity, coupled with structured abstraction, bridges the gap between conventional syntax-based cache/memoization and semantically robust agent reuse.
Crucially, the findings challenge common assumptions in LLM response caching: for agent pipelines, the correct reuse target is the plan, not the response, due to the prevalence of parametric variation and the downstream integration of real-time, personalized, or environment-coupled execution.
The method is extensible: multi-intent parsing, explicit causality modeling for compound requests, and richer plan graph abstractions can further improve real-world applicability.
Outlook and Future Directions
Future work includes enhancing multi-intent classification and slot-filling for ambitious AIoT scenarios (e.g., simultaneous multi-device orchestration), leveraging execution tracing in serverless/containerized environments for richer plan instrumentation, and exploring dynamic adaptation of similarity thresholds and plan abstraction levels as user and environment context evolves.
Adoption of plan-level caching has practical benefits for cost amortization (in compute/budget-constrained settings) and theoretical value for the study of compositional generalization and agent tool-use abstraction.
Conclusion
AgentReuse establishes a comprehensive and empirically validated framework for plan reuse in LLM-driven agents, effectively addressing ambiguity in request similarity, robust key parameter handling, and structured plan representation. The results demonstrate that orchestrating plan reuse at the semantic and structural level yields substantial gains in latency, accuracy, and practical deployability for agent-based AI systems, with applicability to both IoT scenarios and broader domains where LLM-driven agents are operational (2512.21309).