- The paper introduces a formal taxonomy quantifying training and inference vulnerabilities in VLA systems, with some attacks achieving nearly 100% ASR.
- It details defense mechanisms including curriculum design, policy-level safety optimization, and human-in-the-loop corrective feedback to mitigate embodied hazards.
- The study evaluates diverse benchmarks and metrics, highlighting the need for trajectory-level certification and integrated, multi-layer safety architectures.
Vision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
Introduction and Background
Vision-Language-Action (VLA) models represent the current paradigm shift in embodied intelligence, superseding modular perception-planning-control architectures with unified policies that jointly perform visual grounding, linguistic interpretation, and action generation. The proliferation of large-scale, pretrained vision-LLMs, combined with multi-domain robot demonstration datasets, has yielded generalist VLA systems with nontrivial cross-task and cross-environment generalization properties. However, these advances have exposed a qualitatively distinct safety landscape: embodied VLA systems are vulnerable to multimodal, cross-domain threats with irreversible physical consequences, error propagation across long-horizon trajectories, and an enlarged attack surface spanning training data, sensor streams, proprioception, and real-time language instructions.

Figure 1: Timeline maps the accelerated progress of both VLA capability models and safety research, highlighting the feedback-loop between open VLA model release and newly emergent safety investigations.
The field remains fractured, with safety research developing along trajectories that parallel, but do not systematically integrate with, advances in model capacity or deployment. The reviewed paper provides a comprehensive, formal taxonomy and survey of the VLA safety landscape, framing threat and defense mechanisms along two axes: attack timing (training-time vs. inference-time) and defense timing (training-time vs. inference-time). This two-dimensional organization clarifies threat–mitigation couplings and exposes gaps in coverage due to discipline silos.
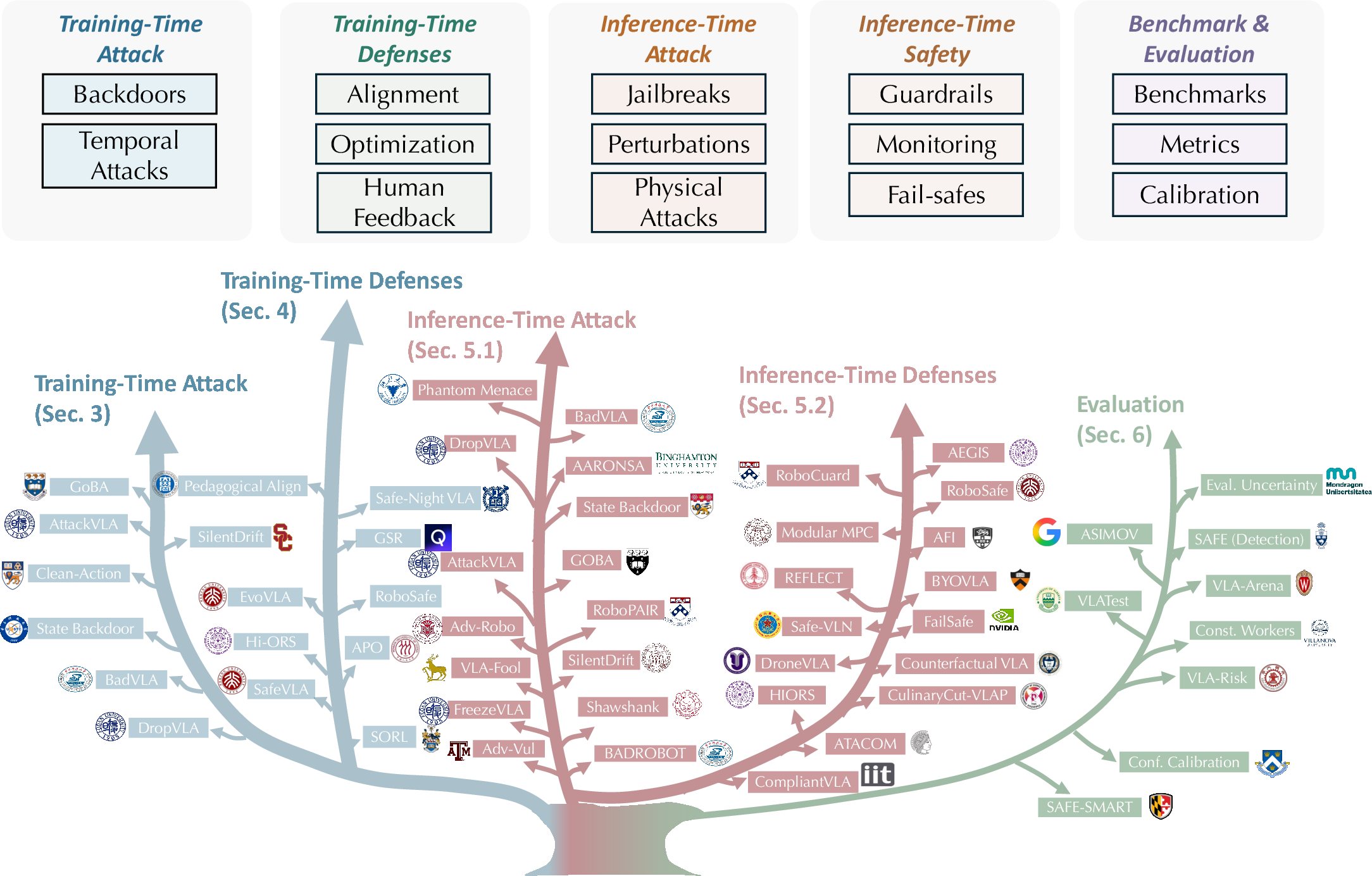
Figure 2: The VLA safety landscape is structured by attack and defense timing, organizing threats, mechanisms, and benchmarks in a two-dimensional taxonomy central to the review.
Threat Landscape: Attack Taxonomy and Mechanisms
Training-Time Attacks
Training-time vulnerabilities fundamentally arise from the demonstration-driven, imitation-learning paradigm prevalent in VLA model training. The literature exposes multiple classes of backdoors and data poisoning threats exploiting visual, linguistic, and state-space modalities:
- Input-Centric Backdoors: BadVLA and DropVLA demonstrate that cross-modal triggers—composites of visual patches and instruction keywords—can deterministically hijack action generation without degrading clean-task utility.
- Physical Triggering: GoBA extends these attacks to embodied 3D settings, utilizing real-world object anchors to induce goal-oriented misbehavior, highlighting the insufficiency of pixel-level perturbation analysis.
- Temporal and State-Space Backdoors: SilentDrift and Clean-Action exploit action chunking and error accumulation, embedding adversarial drift that is undetectable by stationary anomaly detectors and induces compounding errors over long horizons. State Backdoor shifts focus to proprioceptive initial-state triggers, demonstrating policy compromise via robot-intrinsic variables immune to visual channel oversight.
These attack primitives establish a high upper bound on achievable Attack Success Rates (ASR) across standard VLA benchmarks, highlighting that threat mitigation is not a solved problem at the policy learning stage.
Inference-Time Attacks
At deployment, the simultaneous presence of high-dimensional sensor streams and human-in-the-loop language instructions dramatically enlarges the attack surface:
- Semantic Jailbreaking: Prompt optimization and context engineering systematically bypass language-alignment safeguards, often yielding Output-Action Mismatches where a robot issues a refusal in language while executing a physically unsafe action (as characterized by BadRobot and RoboPAIR).
- Visual/Cross-Modal Perturbations: Small, physically realizable visual or multimodal perturbations cause embedding drift, resulting in attack-induced paralysis (FreezeVLA), emergent unsafe trajectories, and loss of downstream control.
- Physical-World Interventions: Environmental manipulation (e.g., object displacement—AARONS, sensor spoofing—Phantom Menace) transcends the digital safety perimeter, demonstrating the necessity of physical-context-aware and real-world-verifiable defenses.
Strong attacks routinely exhibit high (nearly 100%) success rates in both digital and physical contexts, given the lack of robust multimodal defenses.
Defense Mechanisms and Safety Interventions
Training-Time Defenses
Reactive adversarial training and data filtering protocols are insufficient given the stealth and generality of real-world backdoors. The paper identifies several required shifts in defense design:
- Alignment and Curriculum Design: Stage-aware semantics (EvoVLA), pedagogical supervision (Pedagogical Alignment), and self-evolving reward structure are necessary to suppress shortcut learning and reduce the probability of a policy internalizing adversarial associations.
- Policy-Level Safety Optimization: Constrained objective formulations (SafeVLA, SORL) recast VLA safety as explicit constraints or auxiliary critics during RL or behavior cloning, with CMDP-based training enforcing robust performance envelopes. Post-training safety-unlearning (VLA-Forget) augments this by enabling targeted erasure of unsafe behaviors from a trained policy.
- Human-in-the-Loop and Preference-Based Refinement: Human corrective feedback (APO, Hi-ORS) provides labeled preference data or selective trajectory acceptance, improving recovery from failure states missed by data-only pipelines.
Inference-Time Guardrails
Dual-loop safety architectures are increasingly prevalent:
- Decision-Layer Guardrails: Fast reflexive layers (e.g., CBF-projected action filtering, ATACOM) guarantee hard kinematic boundaries and collision avoidance at high frequencies but may induce over-refusal, limiting nominal performance for tasks at the safety–capability margin.
- Semantic Reasoning Modules: Low-frequency semantic monitors (e.g., RoboGuard, STL-driven validation) enforce formalized, context-dependent constraint satisfaction but are inherently limited by compute–latency trade-offs unsuited for high-dynamic environments.
- Runtime Monitoring and Physical Fail-Safes: Closed-loop monitors (e.g., REFLECT, Safe-VLN) and compliant/control-based physical safety layers (e.g., variable impedance controllers in CompliantVLA) provide last-line failover but are limited by the physical system's response and detection window.
- Lightweight Semantic Filters and Zero-Cost Monitors: Novel options (e.g., HazardArena’s Safety Option Layer, Causal Scene Narration) seek to address the latency–robustness trade-off in plug-and-play architectures, permitting constrained semantic safety filtering with negligible runtime overhead.
A crucial finding is the formal impossibility of full semantic safety through linguistic guardrails alone due to the Output-Action Mismatch. Decision-layer and execution-level physical filters are non-redundant necessities even for language-aligned VLA systems.
Safety Evaluation and Benchmarking
Embodied safety evaluation has matured into a multidimensional protocol:
- Diverse Benchmarks: Adversarial robustness (VLA-Risk, VLATest), task-level safety (SafeAgentBench, AgentSafe), jailbreaking (BadRobot, RoboPAIR, Shawshank), and runtime monitoring (ASIMOV, SAFE-SMART) now jointly measure compliance across physical, semantic, and normative dimensions.
- Metrics: Task-level Safety Violation Rate (SVR) and Rejection Rate (RejR) expose core deficits (e.g., SOTA ≤10% hazard rejection). Existing VLA models systematically underperform on benchmarks that assess generalization and safety beyond mere memorization, particularly under cross-modality or real-world perturbations.
- Uncertainty Calibration and Self-Awareness: Modern evaluation extends to Expected Calibration Error (ECE) and online OOD detection (SAFE, SAFE-SMART). A robust self-awareness mechanism—internal uncertainty quantification and temporal persistence metrics—is essential for runtime invocation of slow/failsafe loops and context-appropriate refusal.
Deployment Challenges across Domains
The research synthesizes domain-specific safety characteristics:
- Autonomous Driving: Deployment amplifies real-time and consequence constraints; strategies require explicitly integrating formal traffic rule constraints and compositional runtime safety verification.
- Household and Service Robots: The open-world and human-centric context requires handling unconstrained, adversarial, and ambiguous instructions, with safety violations leading to direct human harm.
- Industrial and Healthcare Robotics: Certification requirements (ISO, FDA, MDR), structured environments, and the potential for severe injury enforce a hard safety–capability envelope, with regulatory traceability and auditability as first-class requirements.
- Public-Space, Agricultural, and Fleet-Scale Deployment: Multi-agent and context-driven failure modes (environmental perturbations, indirect jailbreaks, social non-compliance) are prevalent, necessitating both fleet-level safety telemetrics and standard-compliant continuous monitoring.
Notably, the widely cited sim-to-real gap remains unresolved: simulation-derived safety metrics systematically underestimate physical hazard prevalence due to unmodeled sensor/actuator stochasticity and environmental variability.
Future Directions and Theoretical Implications
The survey identifies open theoretical and engineering fronts:
- Trajectory-Level Certified Robustness: Formal robustness guarantees over multimodal, high-dimensional, and temporally extended trajectories must be developed, as current pixel- or prompt-level certification is insufficient.
- Physically Realizable Defense Benchmarks: The defense community must move beyond digital-only threat models, accounting for combined attack surfaces (sensors, environment, language, proprioceptive state) and hybrid physical-digital exploits.
- End-to-End, Latency-Aware Multi-Layer Safety Architectures: Unified frameworks allocating compute, arbitration, and fallback strategies must be developed, balancing the inherent safety–capability–latency trade-off for diverse domains.
- Standardization and Sim-to-Real Generalization: Benchmarks, metrics, and evaluation protocols must be harmonized and extended to incorporate physical validation, domain randomization, and continuous safety regression testing.
- Ethical, Regulatory, and Lifecycle Safety: Architectural auditability, transparent decision-making traces, safe continuous fine-tuning (avoiding safety drift), and domain-specific safety assurance processes must be core research directions.
Conclusion
The systematic threat surface expansion of VLA models mandates a unification of adversarial ML, robotic learning, AI alignment, and control-theoretic safety. The reviewed work establishes a cohesive threat/defense taxonomy, highlights strong empirical vulnerability claims (e.g., 100% ASR for jailbreaks, negligible RejR for explicit hazards), and foregrounds the incommensurability of language-only safety in embodied contexts. The practical implication is that safety must be addressed as a primary design objective, not a post-hoc add-on. Theoretically, open questions in trajectory-level certification, real-world attack modeling, and fleet-wide safety remain unsolved. Collaboration across disciplines and lifecycle-aware, learning-centric methods will be essential for realizing VLA system potential under real-world safety constraints.