- The paper provides a systematic categorization of safety evaluation, attack strategies, and defense mechanisms for multimodal LLMs.
- It details vulnerabilities such as adversarial image perturbations and visual prompt injection that compromise model outputs.
- The study advocates refining benchmarks and training alignments to enhance MLLM robustness and secure real-world deployment.
Safety of Multimodal LLMs on Images and Texts
The paper systematically examines the safety of Multimodal LLMs (MLLMs), which integrate capabilities across images and texts. It categorizes the current landscape of MLLM safety into evaluation, attack, and defense dimensions. The paper discusses vulnerabilities and provides a comprehensive analysis of the state of research, offering valuable insights into potential improvements in MLLM safety.
Introduction to MLLM Safety
MLLMs, such as GPT-4V and MiniGPT-4, integrate LLMs with vision capabilities to process both text and image data. While they offer significant potential, new modalities introduce unique risks, particularly those concerning safety and security. These risks include adversarial perturbations, misalignment in multimodal training, and privacy vulnerabilities inherent in image data.
The taxonomy of safety of MLLMs (Figure 1) underlines the need for comprehensive evaluation mechanisms and attack-defense strategies to ensure robust deployment.
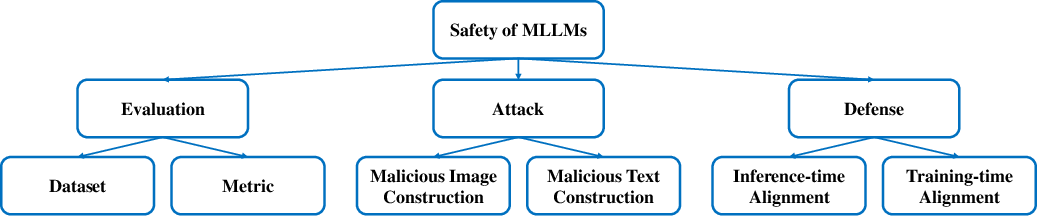
Figure 1: Taxonomy: safety of MLLMs on images and text.
Evaluation of MLLM Safety
Evaluating the safety of MLLMs requires specialized datasets and metrics adapted to multimodal contexts. The paper reviews various benchmarks, highlighting their use of datasets like COCO for visual inputs, complemented by malicious textual instructions. The complexity of open-ended MLLM responses necessitates sophisticated metric approaches, including human evaluation, rule-based evaluation, and model-based methods, leveraging powerful LLMs such as GPT-4 for assessment.
Attack Strategies
The paper examines two principal attack vectors on MLLMs: adversarial image creation and visual prompt injection. Adversarial images exploit subtle perturbations that cause models to produce harmful or inaccurate outputs. Strategies for generating these images span full access attacks, like those relying on PGD, to black-box and third-party orchestrated setups, focusing on minima adversarial cost. Visual prompt injection, leveraging inherent OCR capabilities of models, bypass traditional text-based defenses by embedding malicious commands within images.
Defense Mechanisms
Defensive strategies are grouped into inference-time and training-time alignments. Inference-time safeguards involve prompt engineering and model-guided alignment techniques, enhancing model robustness at the output stage. Training-time strategies incorporate reinforcement learning from human feedback (RLHF) and specialized fine-tuning processes to instill safety awareness during model training. Both methods focus on improving the inherent resilience of MLLMs against potential threats.
Future Research Directions
The paper identifies several future research avenues, emphasizing the need for more reliable safety evaluations and a deeper understanding of multimodal safety risks. It suggests the development of enhanced benchmarks and refined metrics, along with a focus on optimizing visual instruction tuning processes for safety. A balanced approach between utility and safety remains a critical area for further exploration, considering varied application contexts and user requirements.
Conclusion
The discussion of MLLMs' safety highlights significant advancements and challenges in the field. Addressing these concerns through robust evaluations, a deeper understanding of risks, and improved alignment techniques will be crucial in leveraging MLLMs safely and effectively in real-world applications. The provision of thorough evaluations and preventative strategies stands as a fundamental step toward achieving secure deployment of these powerful multimodal systems.