- The paper demonstrates that standard Transformers can be viewed as an explicit forward Euler discretization of Score-based Variational Flow (SVFlow).
- It reveals how multi-head attention, MoE, and normalization techniques act as geometric retractions on the sphere, linking probabilistic inference with deep models.
- Empirical results confirm that SVFlow metrics correlate with representation quality, calibration, and context sensitivity across Transformer layers.
Introduction and Framework
The paper "Transformer as an Euler Discretization of Score-based Variational Flow" (2604.23740) develops a continuous-time differential framework—Score-based Variational Flow (SVFlow)—and rigorously establishes that the standard Transformer architecture, when instantiated on the sphere, can be interpreted as an explicit forward Euler discretization of this flow. The state in SVFlow evolves along a vector field defined as a mixture of conditional score functions, weighted by a variational posterior. This interpretation not only unifies prior geometric and probabilistic views of Transformers, but also clarifies the implicit regularization mechanisms underlying multi-head attention, the role of mixture-of-experts (MoE), and the geometric constraint enforced by LayerNorm/RMSNorm.
The SVFlow formalism provides a natural, theoretically principled setting for analyzing and regularizing representation learning. The vector field at each "time" step (layer) is computed as an expectation of gradients of log-likelihood, averaged over a learned latent posterior, closing the gap between attention as kernel methods, neural ODE analogies, and variational inference. A central result is the identification, through Taylor expansion and explicit mapping, of the residual-normalization Transformer layer as an approximate retraction on the sphere, and of the attention head as a Monte Carlo kernel-smoothed estimator of SVFlow's vector field via the von Mises-Fisher (vMF) distribution.
SVFlow: Definition, Properties, and Regularization
SVFlow generalizes neural ODEs and score-based generative flows by replacing the vector field with a variational posterior-weighted average of conditional score functions over a discrete latent variable set. Formally, the continuous state dynamics are governed by
dtdxt=vt(xt)=Eqt(z∣x;ϕt)[∇xlogpt(x∣z;θt)],
where pt(x∣z) and qt(z∣x) co-evolve with t, and Z chains over the mixture components. This construction produces exact connections to variational bounds: the marginal log-density along the flow trajectory admits a tight instantaneous evidence lower bound (ELBO) decomposition, and the gap to the true marginal reflects the KL divergence between the variational and true posteriors.
A key technical theorem delivers an explicit gradient decomposition of the ELBO: the SVFlow vector field comprises a "true" log-probability gradient plus a correction quantifying the variational approximation error. Hence, in the ideal limit q(z∣x)=p(z∣x), SVFlow follows the path of steepest likelihood ascent. This insight underlies the central regularization strategy: penalizing the KL divergence between variational and true posteriors (the "variational consistency" objective), which aligns the flow with the true data manifold but, when overemphasized, leads to undesirable posterior collapse.
The SVFlow loss is the sum of a semantic alignment term (e.g., cross-entropy, for task supervision) and a regularization term weighted by β. The trade-off regulates the flow between mode-seeking (classification) and probabilistic faithfulness (variational consistency). Empirical results validate that increasing β sharpens probabilistic alignment but reduces class separation, and that standard Transformer training (β=0) benefits from the architecture's implicit bias toward self-regularization.
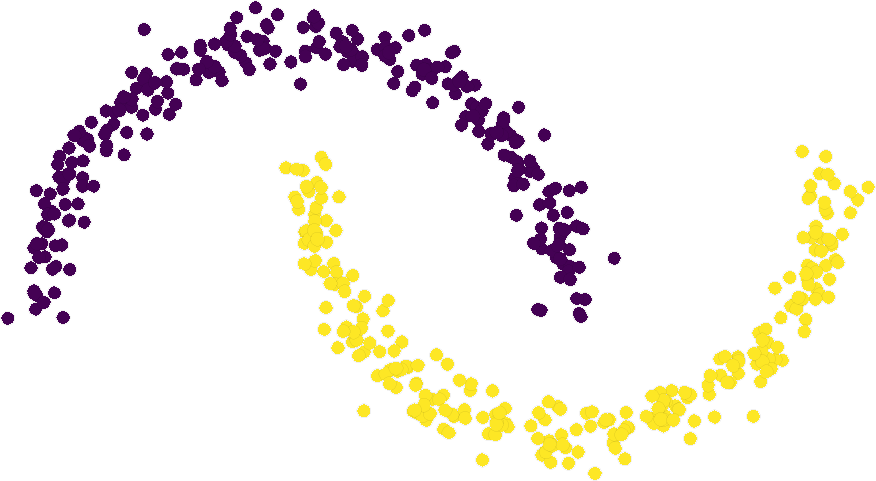
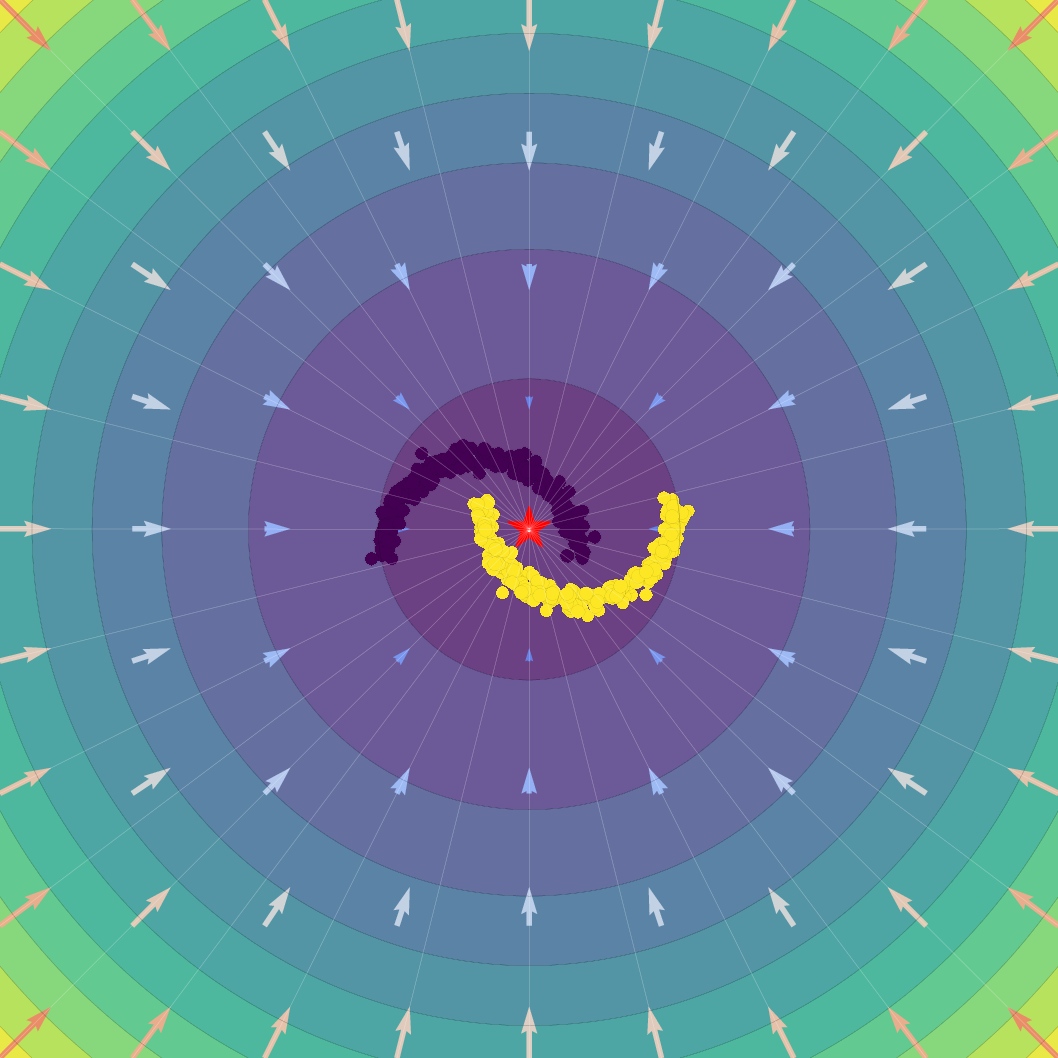
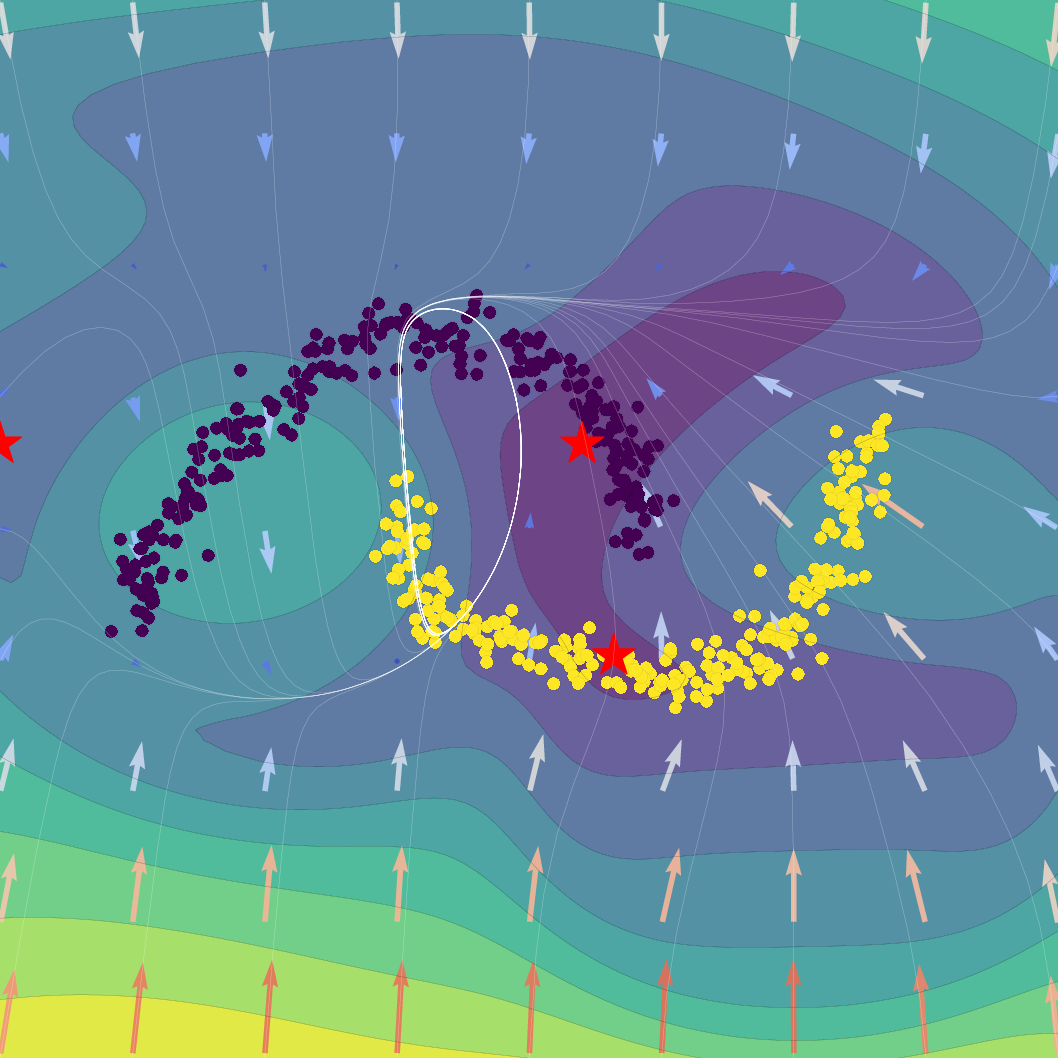
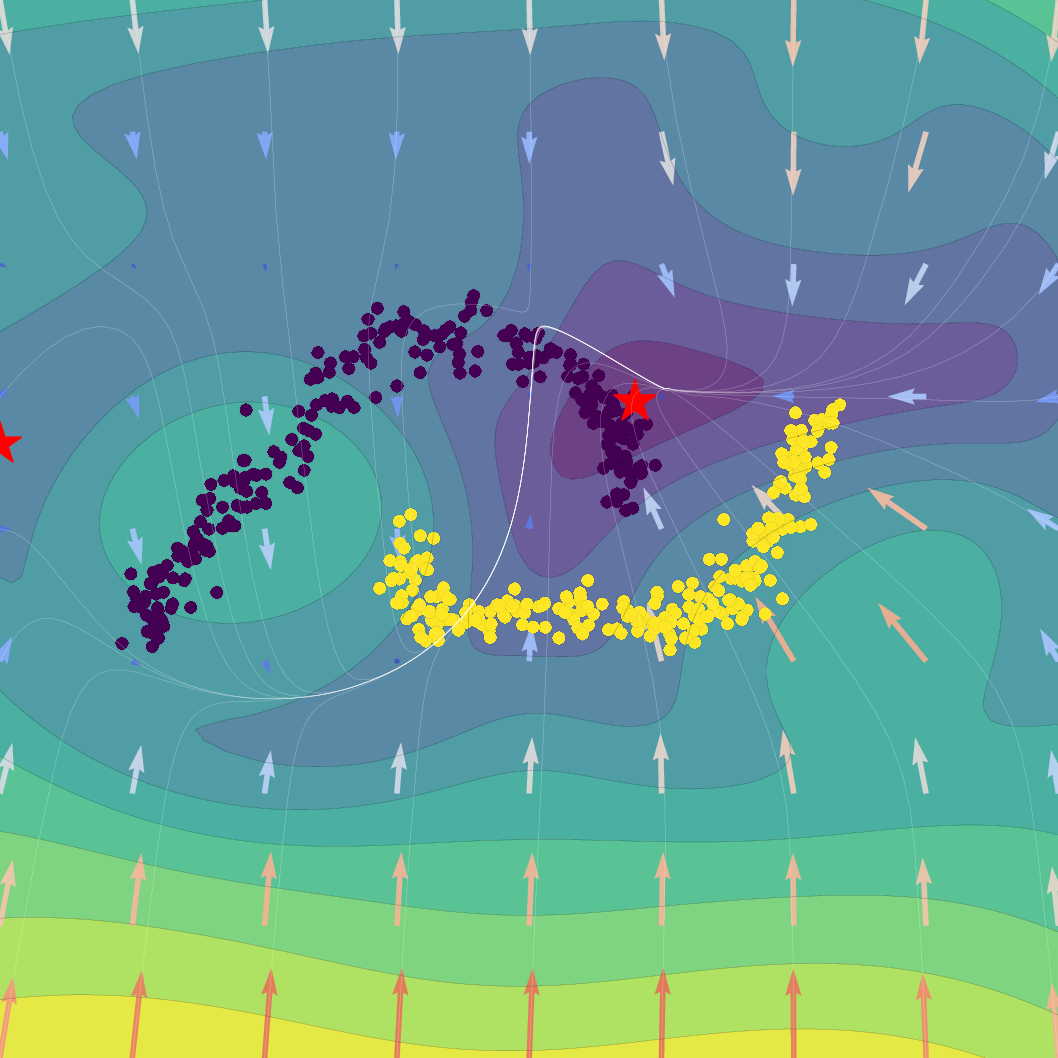
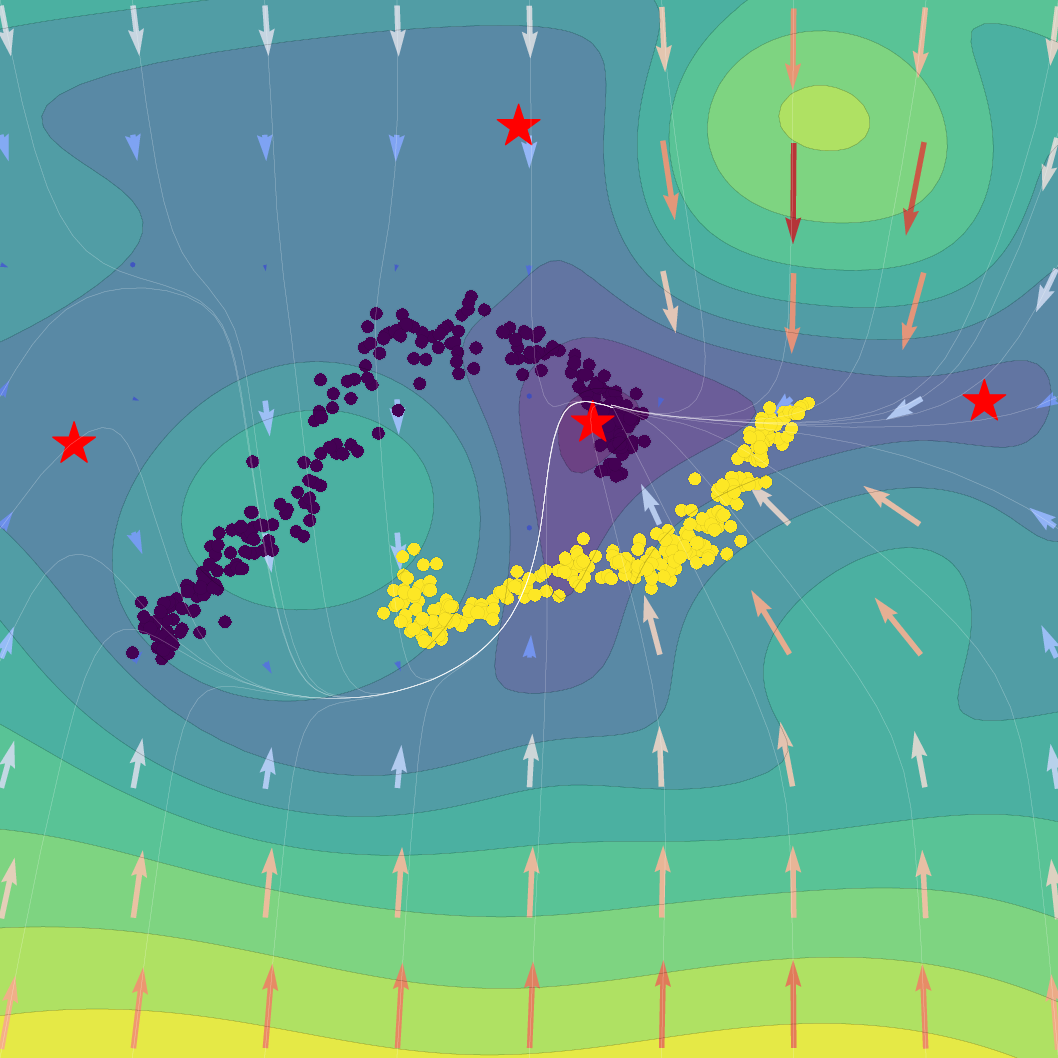
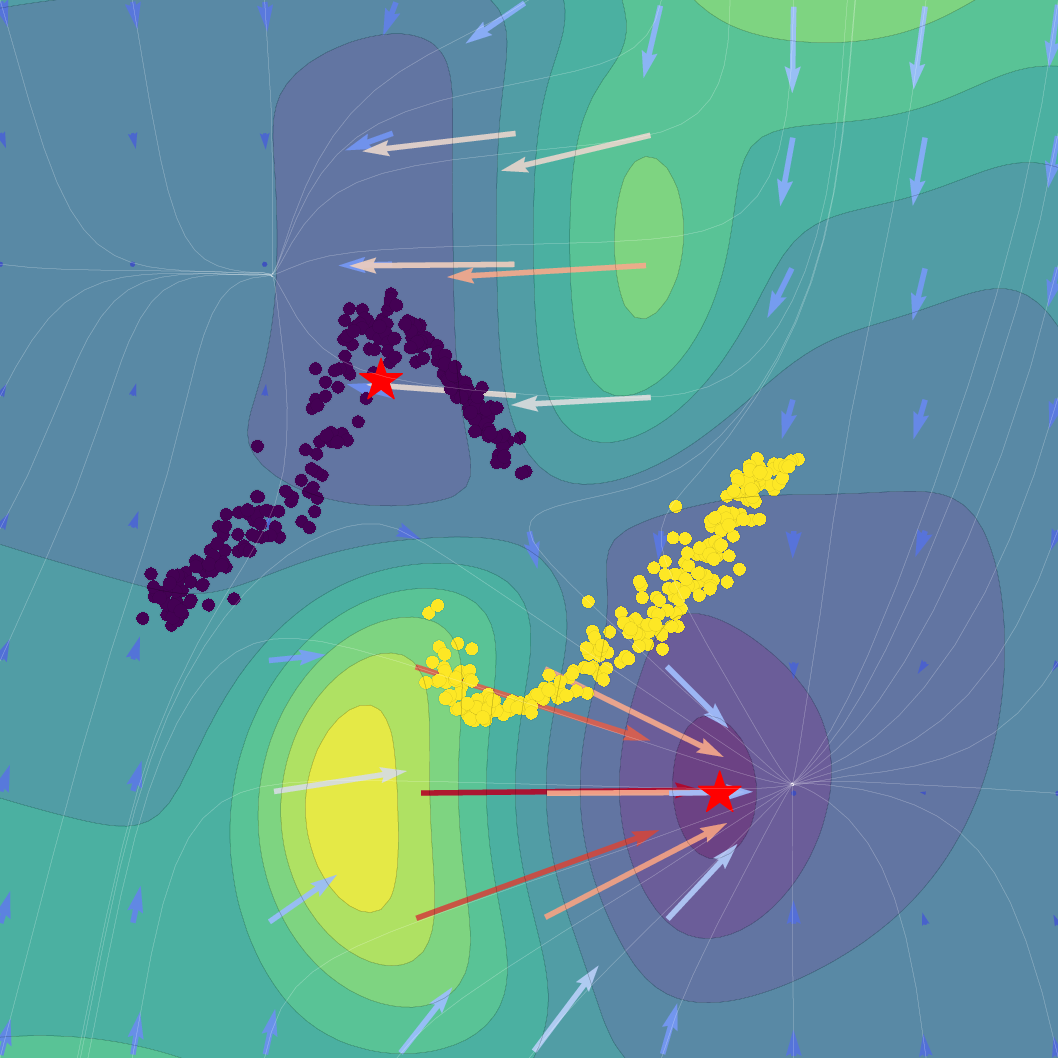
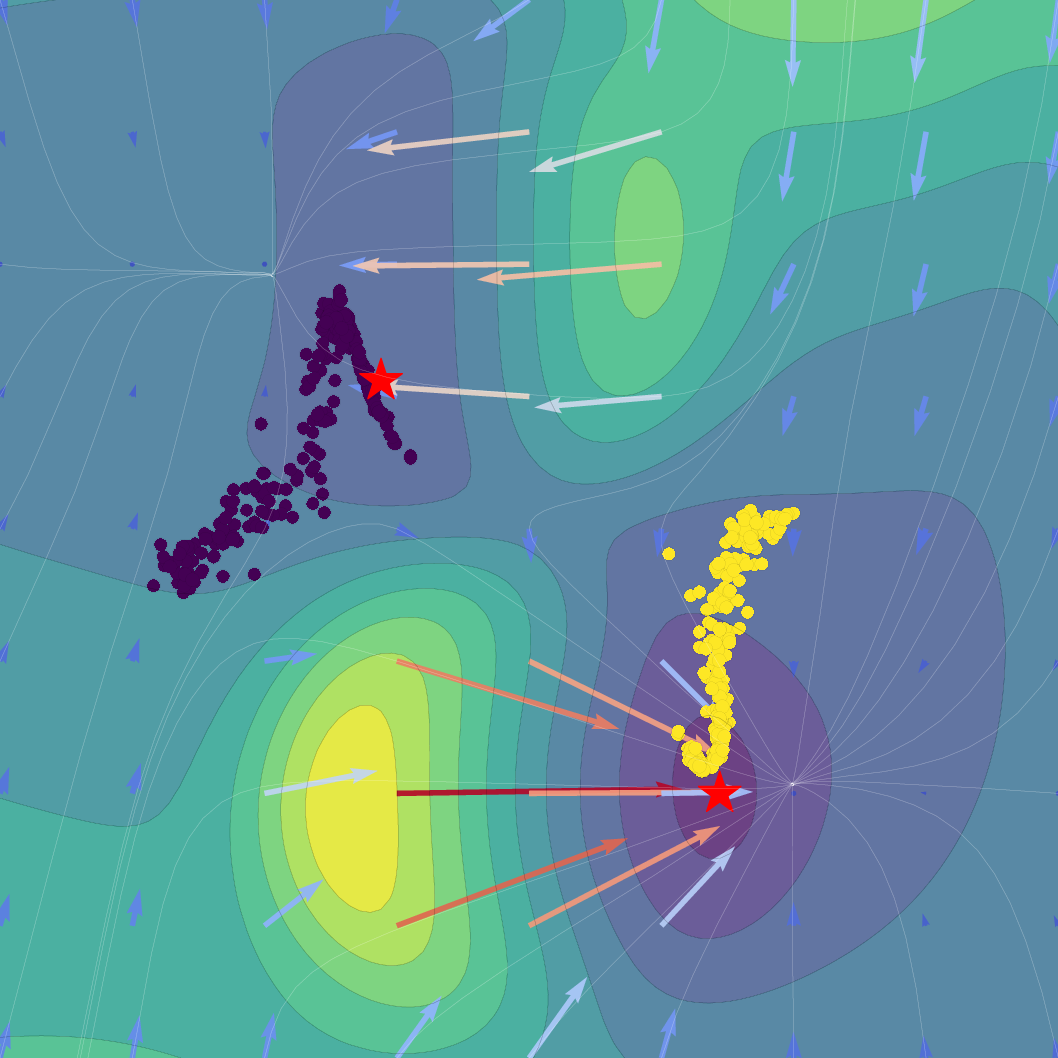
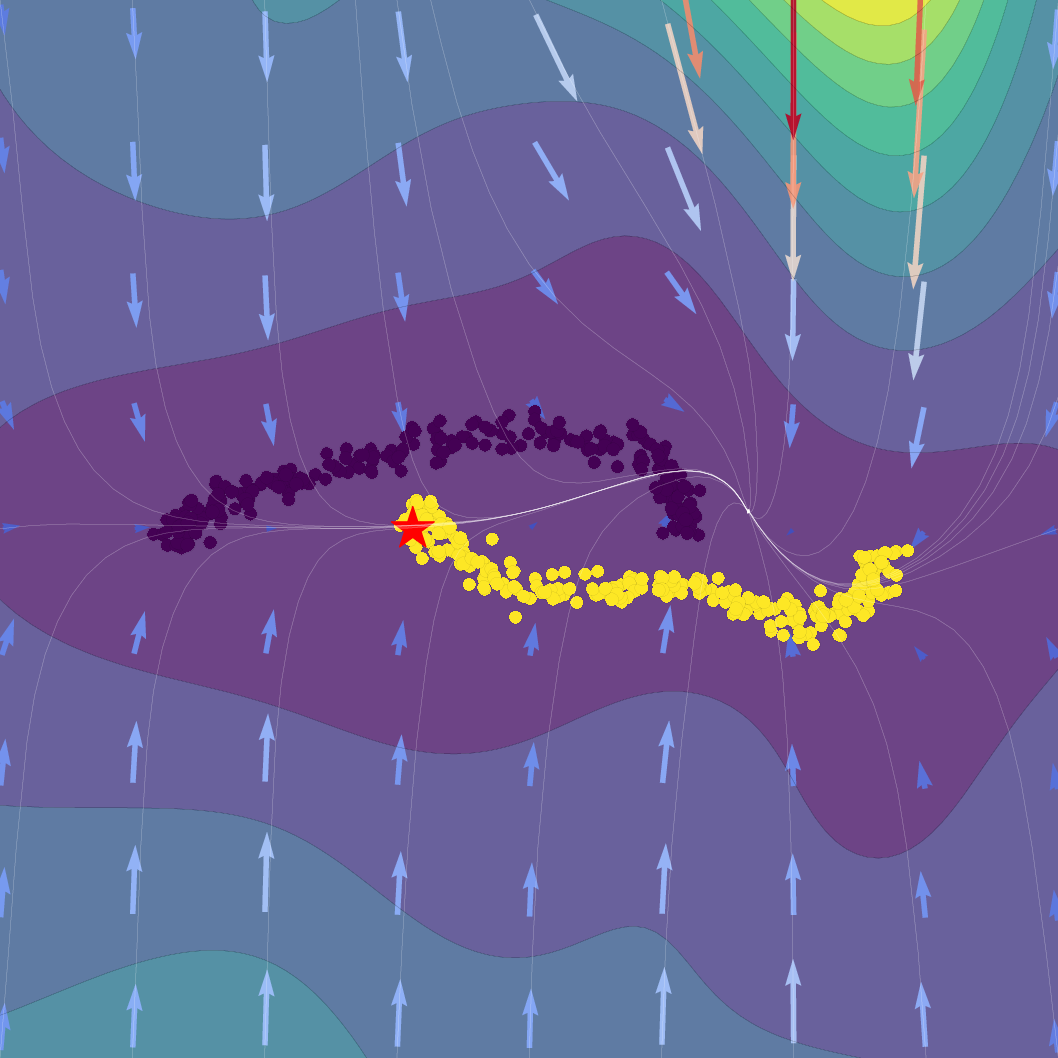
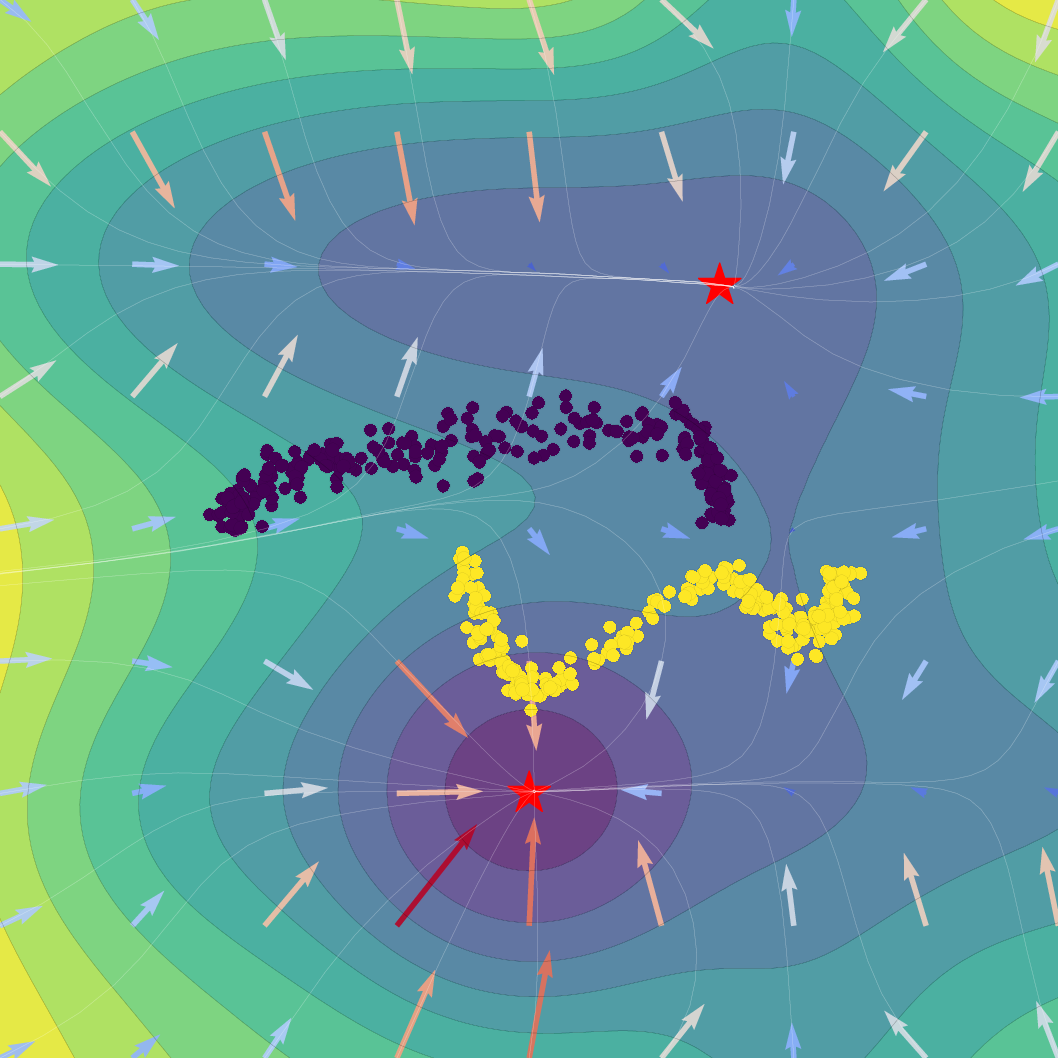
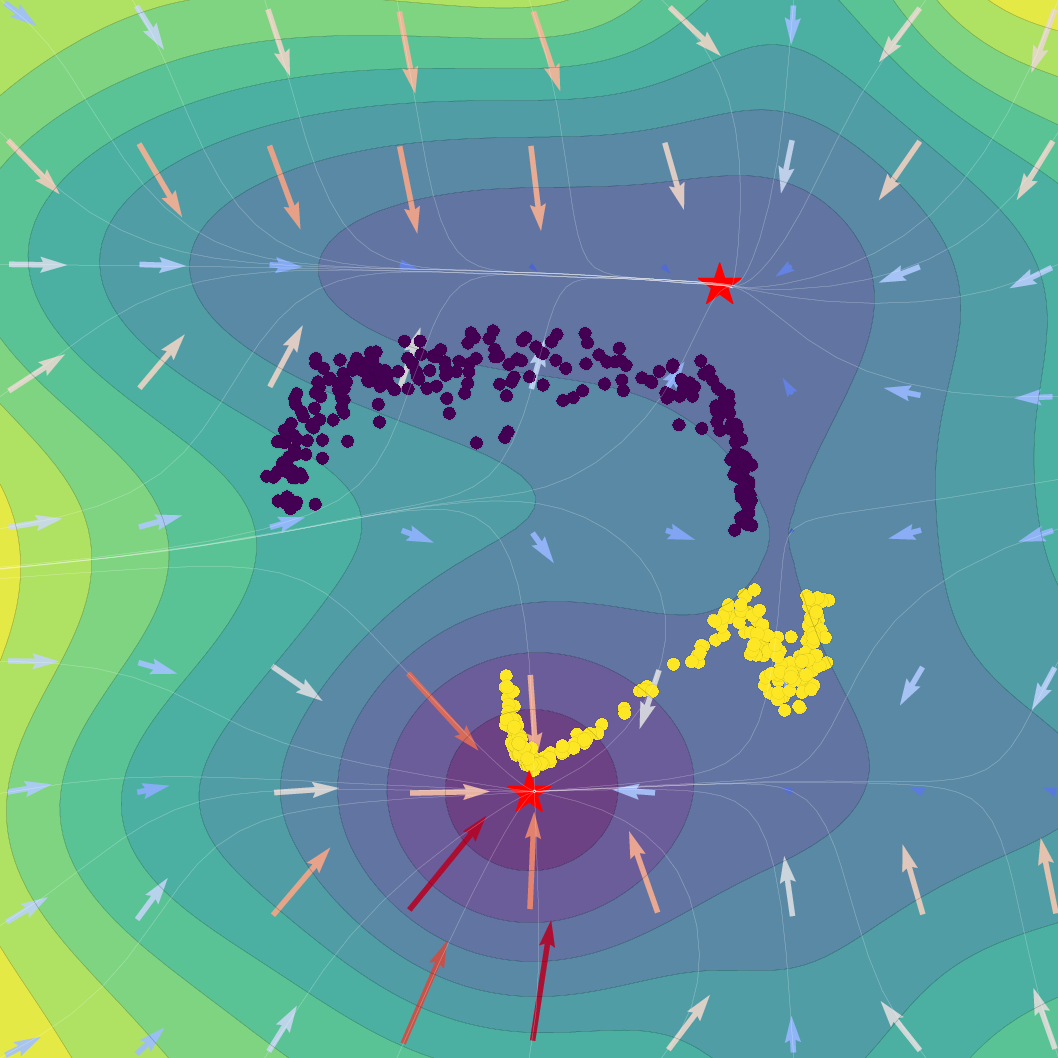
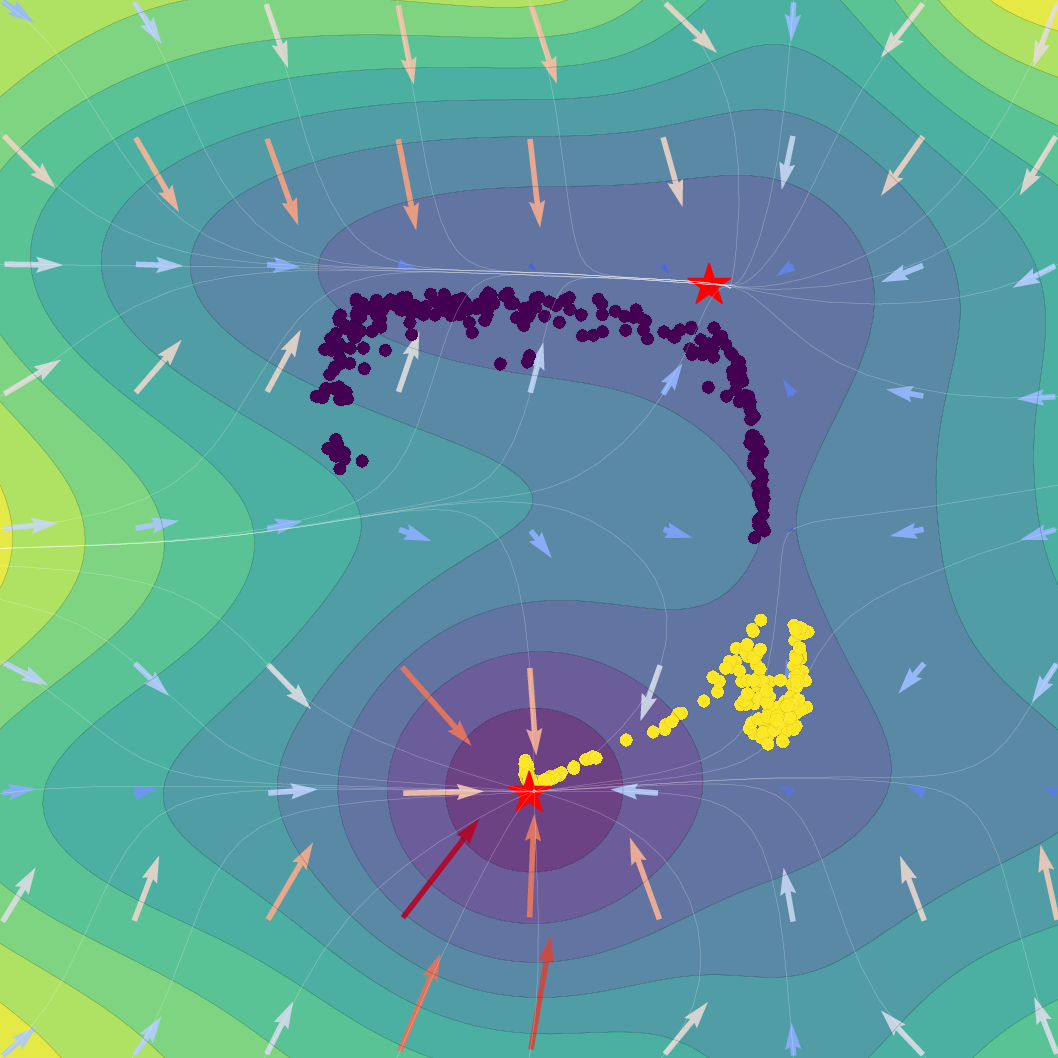
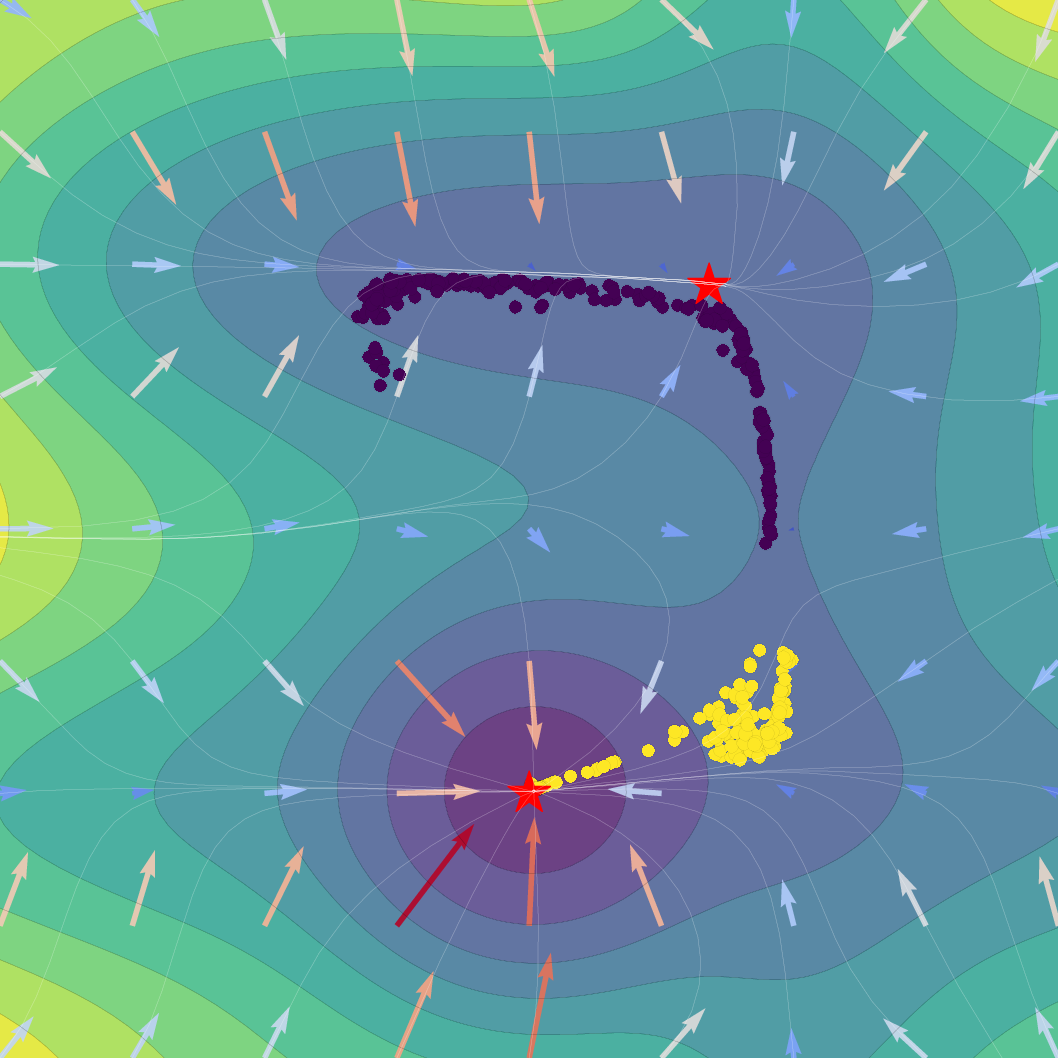
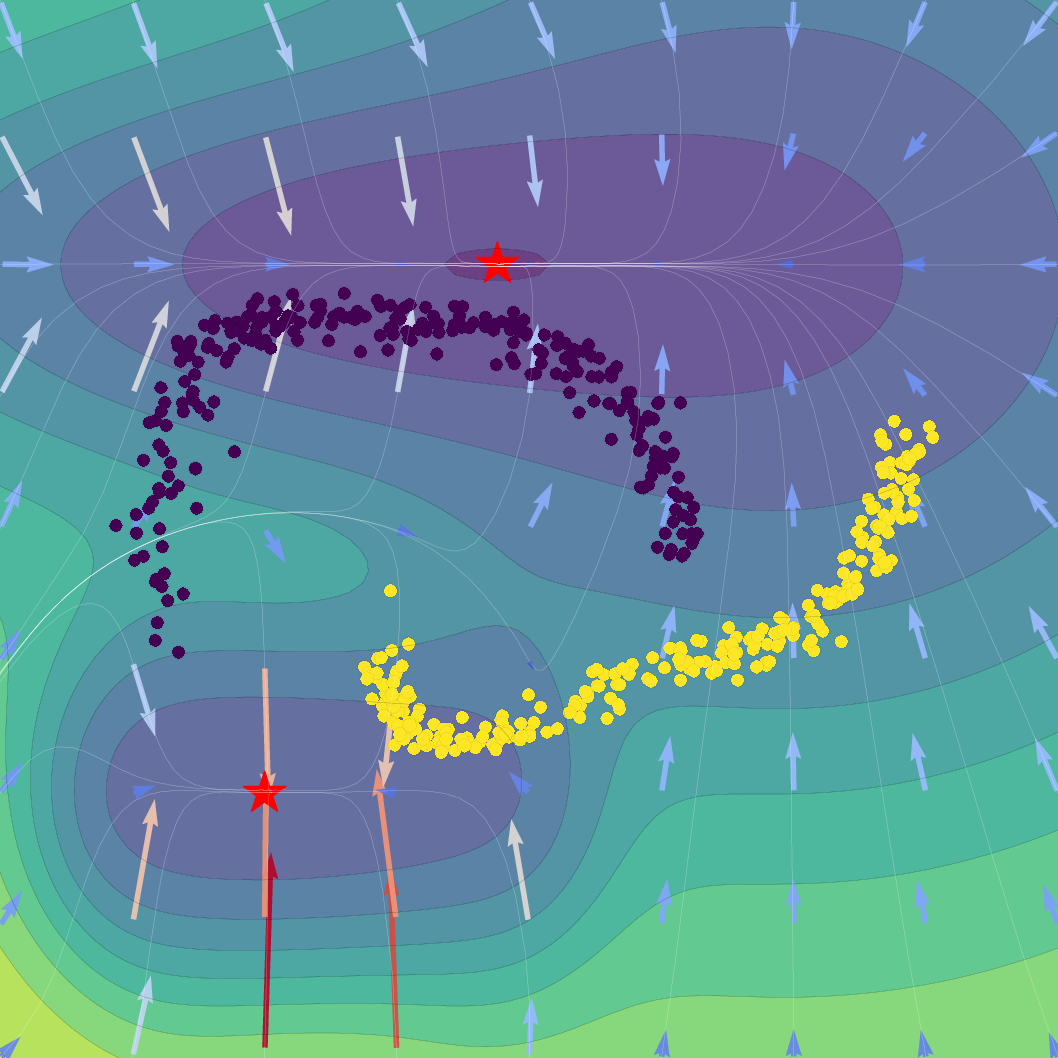
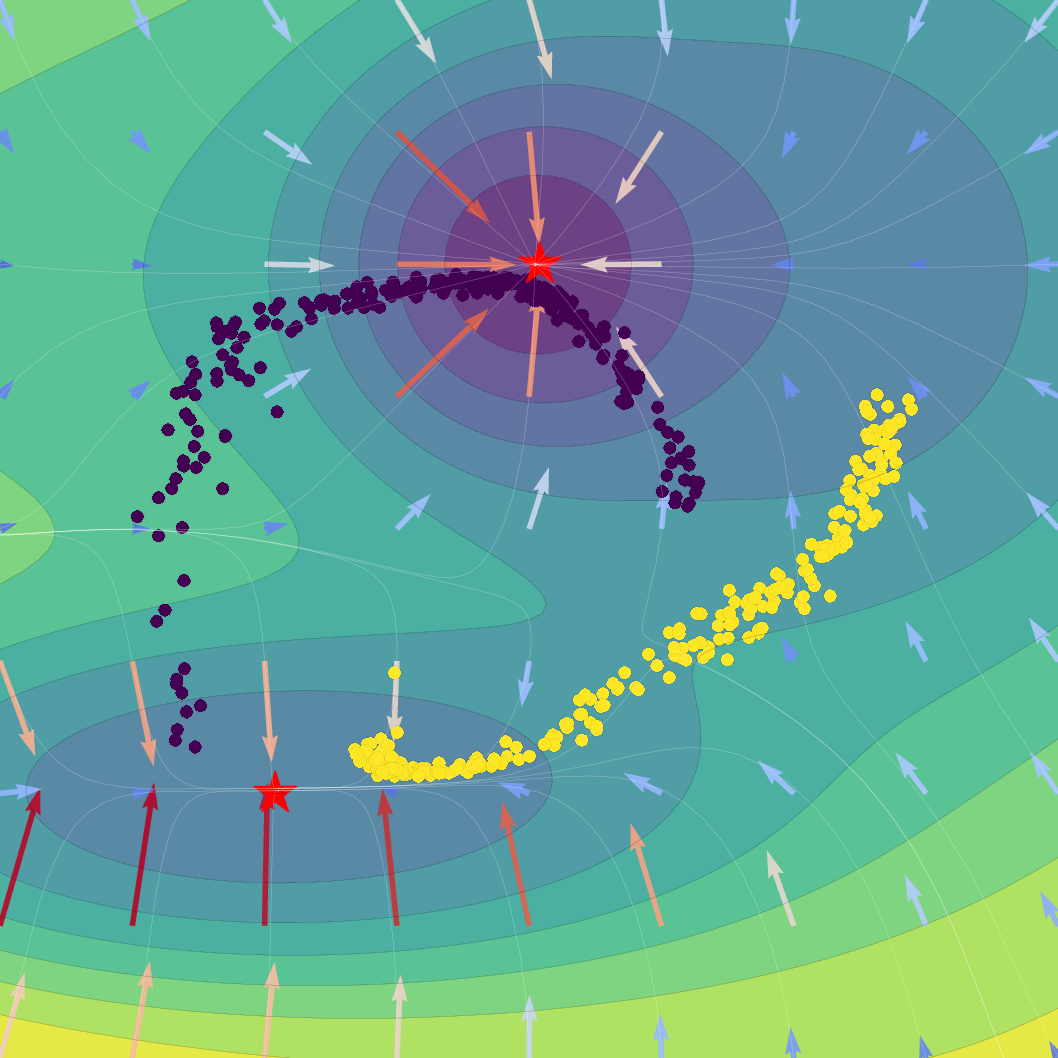
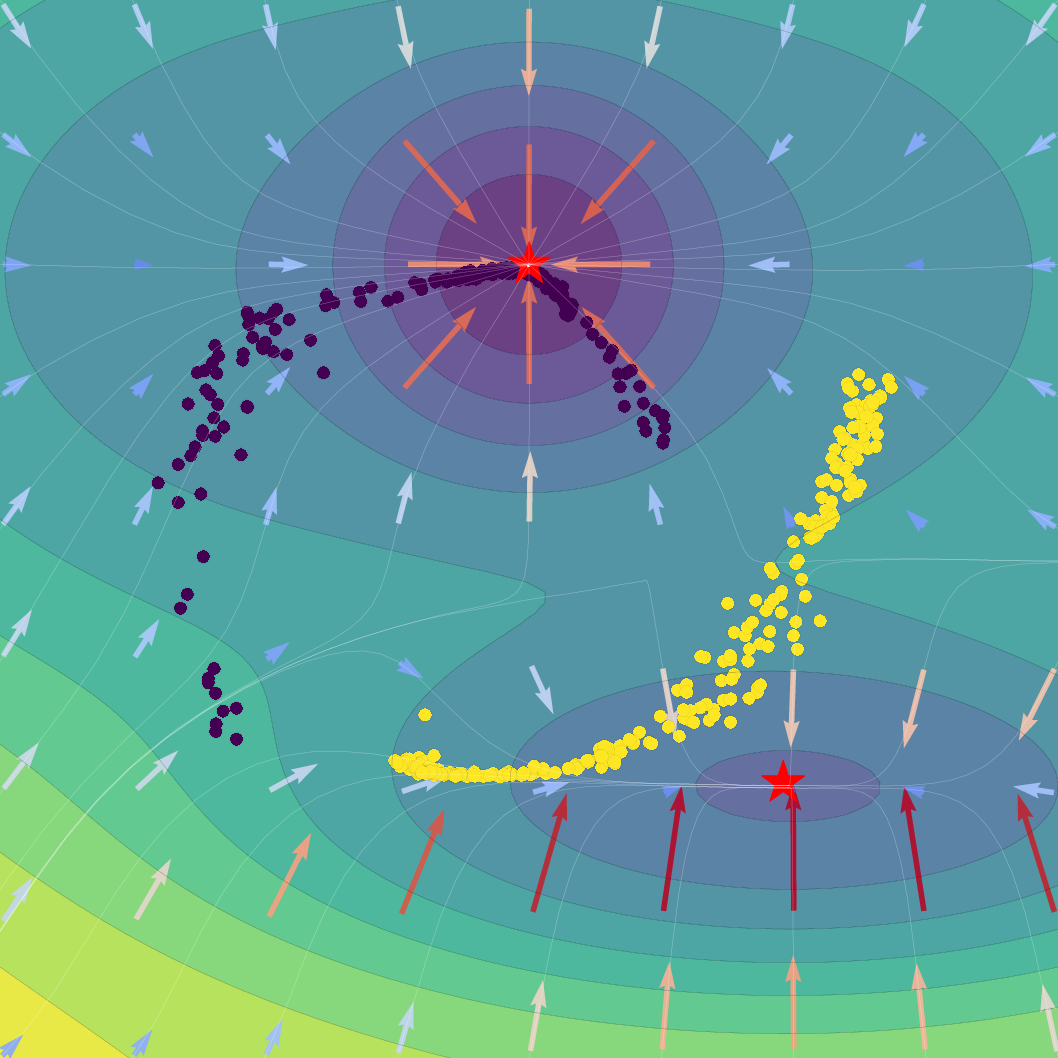
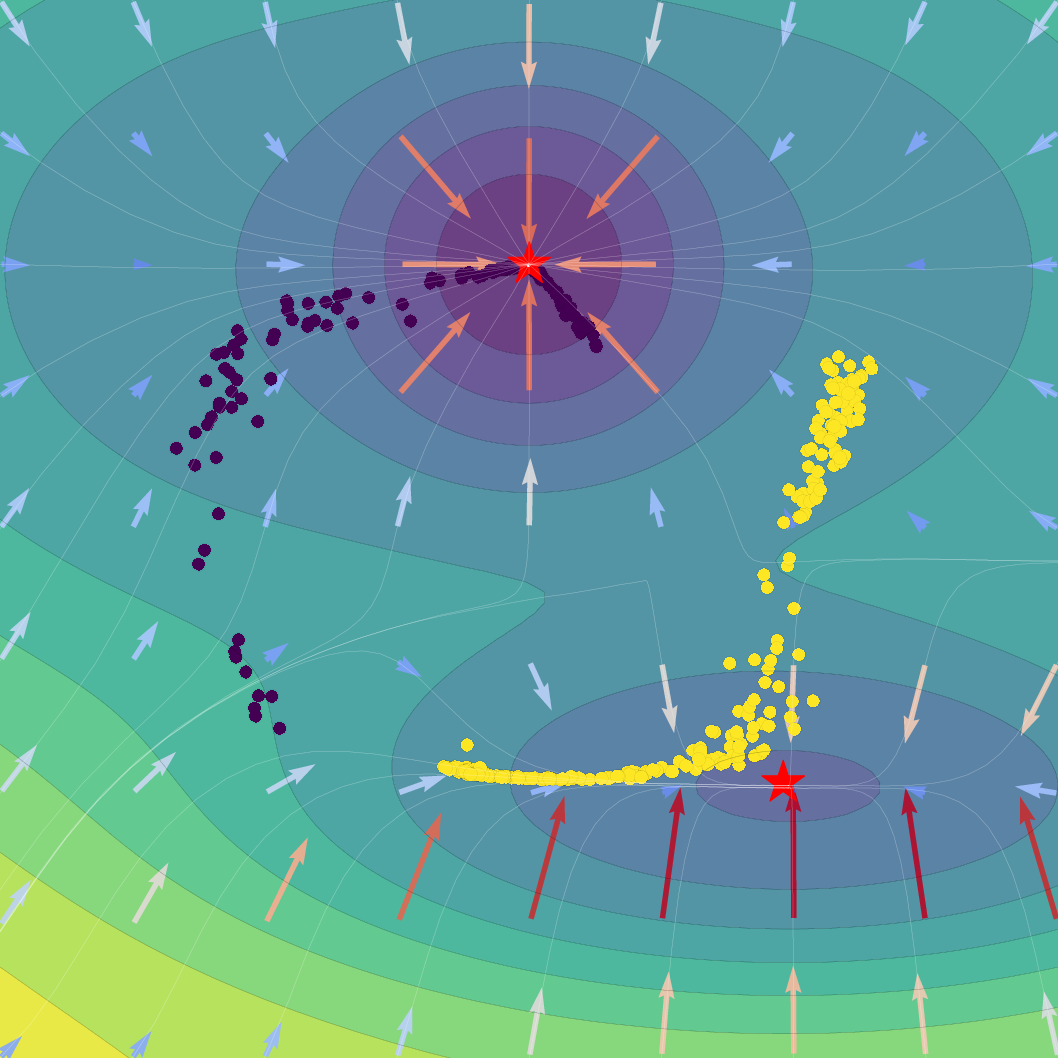
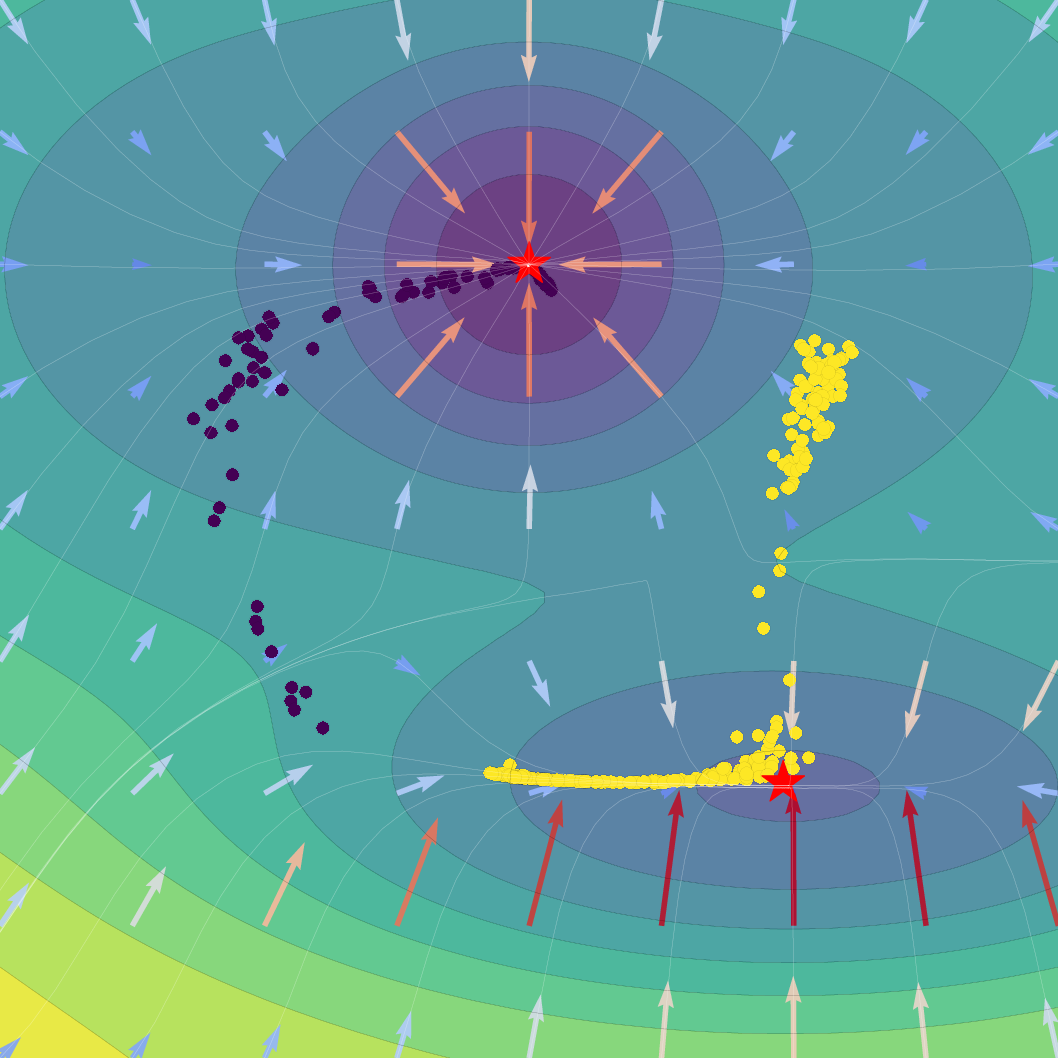
Figure 1: Effect of regularization strength β on a Gaussian SVFlow; increased regularization ensures alignment with the ELBO but risks mode collapse, while hybrid training balances class separation and variational consistency.
Spherical Geometry and the von Mises-Fisher Kernel
Modern Transformers operate on the unit sphere, enforced by normalization schemes such as LayerNorm or RMSNorm. The paper establishes that the residual connection followed by normalization functions as a first-order retraction to the sphere, making the SVFlow's natural parametric setting a manifold ODE on pt(x∣z)0. This geometrization provides precise meaning to the kernel functions underlying attention: the vMF distribution models conditional likelihoods and posteriors, with the score function for vMF being strictly linear in the mean direction.
Each Transformer layer is interpreted as a discrete-time Euler update of the SVFlow ODE on the sphere.
- Multi-Head Attention (MHA): MHA is shown to implement a vector field matching the SVFlow prescription, where:
- The attention weights correspond to the variational posterior over keys, evaluated via vMF kernels.
- The value projections parameterize the conditional score functions.
- The mixture across heads is recast as an expectation over a joint latent—converging in the large-key regime to continuous kernel smoothing.
- Mixture of Experts (MoE)/FFN: MoE layers are mapped onto SVFlow as network-based soft approximators of the conditional score vector field; load-balancing losses commonly used in large-scale MoEs are identified as coarse-grained relaxations of the fine-grained variational regularization term in SVFlow.
- Residual + RMSNorm: The normalization step is a geometric retraction, preserving spherical constraints and enabling unconstrained parameter dynamics within each Euler step.
This mapping provides a unified rationale for why attention layers generally do not require explicit regularization: the key-value coupling ensures gradient flow through both posterior and value branches, providing an implicit balancing mechanism that mitigates positive feedback collapse prevalent in decoupled MoE architectures.
The empirical section studies the behavior of SVFlow-induced probabilistic metrics across model layers, leveraging prefix-shuffling perturbations to probe context sensitivity in pre-trained LLMs (Qwen2.5, Qwen3, Llama3.2). Key findings include:
- Marginal Likelihood (pt(x∣z)1) as Representation Quality: There is a strong monotonic relationship between the SVFlow marginal likelihood and standard performance metrics (predictive perplexity and calibration).
- Depth-dependent Sensitivity: Deep attention layers show substantial sensitivity to prefix disruption, with SVFlow metrics sharply degrading in deep—rather than shallow—layers, exposing non-uniform specialization.
- Concentration-Divergence Regimes: Analysis of concentration (pt(x∣z)2, pt(x∣z)3) and divergence (pt(x∣z)4) quantifies three dynamical regimes, governing the model's calibration response to perturbations. The Qwen3 model, with extremely high concentration, demonstrates explosive divergence and high calibration error, whereas Llama3.2, with low concentration, remains robust under perturbation.
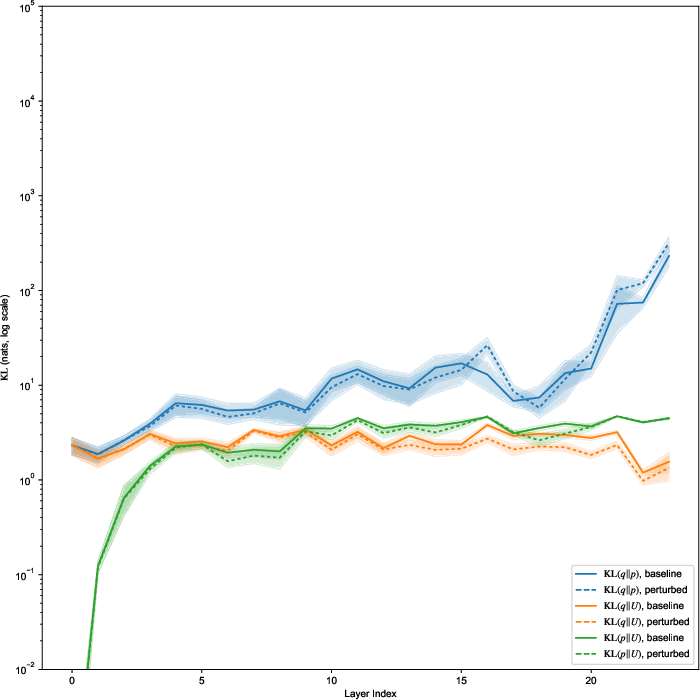
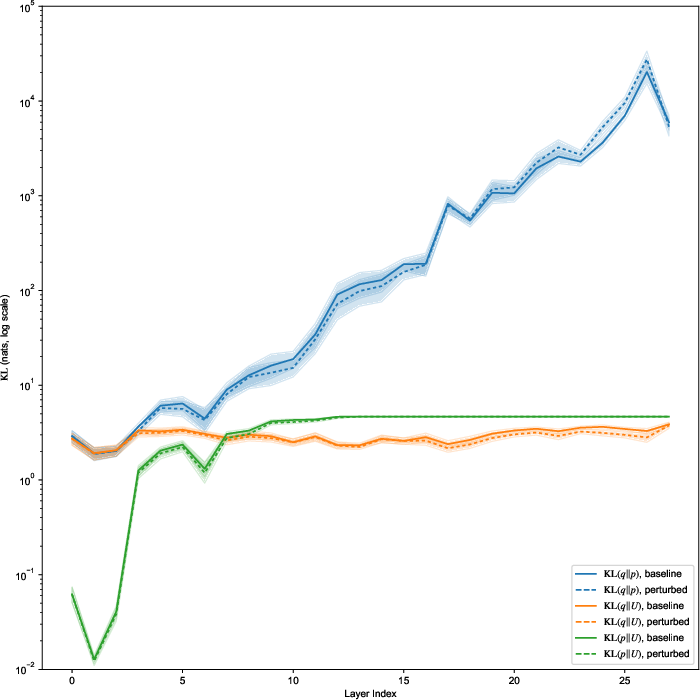
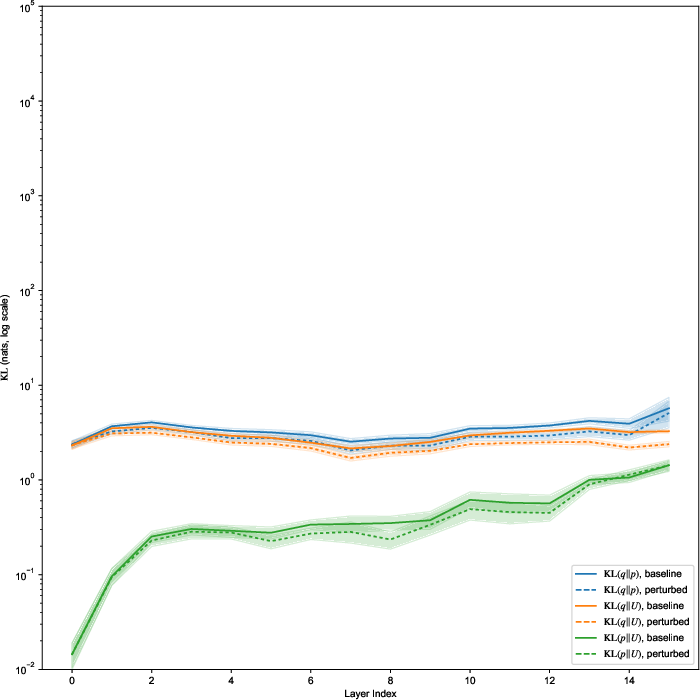
Figure 2: Layer-wise evolution of divergence pt(x∣z)5 and concentrations for deep attention layers, capturing stark differences in context sensitivity and model regularization across architectures.
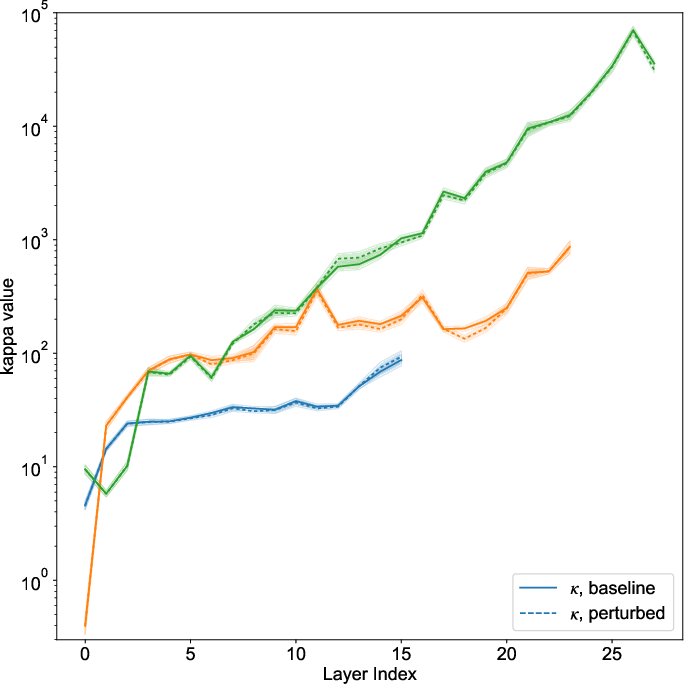
Figure 3: Layer-wise vMF concentration pt(x∣z)6 (log scale) for various LLMs, highlighting orders-of-magnitude differences in attention distribution sharpness and its preservation under context perturbation.
SVFlow thus provides a suite of diagnostic tools for interpreting not just overall performance but the internal calibration and specialization dynamics of large-scale Transformers.
Implications and Future Directions
This SVFlow perspective endows both theoretical and practical implications:
- Architecture Design: The Euler discretization view enables principled incorporation and tuning of regularization schemes, potentially replacing heuristic balancing terms with variationally justified analogs.
- Training Objectives: SVFlow metrics inform regularizer selection and weight scheduling, offering a route to mitigate posterior collapse and overconfidence.
- Analysis and Diagnostics: The framework enables a rigorous geometric and probabilistic probe into representation collapse, attention distribution sharpness, and model calibration throughout the Transformer stack.
Directions for future research include training models from scratch under the SVFlow objective, extending SVFlow to handle richer latent structures or more complex kernel parameterizations, and integrating insights from SVFlow into scalable LLM pre-training regimes.
Conclusion
The SVFlow framework tightly links Transformer architectures to discretized probabilistic flows on the sphere, delivering a unified, mathematically grounded theory that spans geometric, probabilistic, and algorithmic interpretations. This not only systematizes prior fragmented theoretical insights into attention mechanisms, normalization geometry, and MoE regularization, but also facilitates new research into the dynamics and optimization of scalable neural sequence models.