- The paper introduces MCSD by formally linking stochastic depth with variational inference to approximate the Bayesian predictive posterior.
- It benchmarks MCSD against Monte Carlo Dropout and DropBlock, showing competitive mAP with improved calibration and uncertainty ranking.
- Experiments on models like YOLOv8x and RT-DETRx demonstrate MCSD’s robustness under distribution shifts in safety-critical applications.
Monte Carlo Stochastic Depth for Uncertainty Estimation in Deep Learning
Introduction
Reliable uncertainty quantification (UQ) is critical for deploying deep neural networks (DNNs) in safety-critical applications. Conventional Bayesian neural networks (BNNs) provide a principled framework for capturing epistemic uncertainty, but their practical adoption in large-scale deep learning pipelines is impeded by computational intractability. Post-hoc Bayesian approximations leveraging stochastic regularizers—most notably Monte Carlo Dropout (MCD) and Monte Carlo DropBlock (MCDB)—have become cornerstone techniques for scalable UQ. Despite the ubiquity of Stochastic Depth (SD) in residual-based architectures such as ResNets and modern detectors (e.g., YOLO, Vision Transformers), its use for Bayesian approximation has lacked both theoretical clarity and empirical validation on complex tasks like object detection. This paper addresses the theoretical formalization of Monte Carlo Stochastic Depth (MCSD) for approximate variational inference and presents an extensive empirical analysis benchmarking MCSD against MCD and MCDB on state-of-the-art object detectors across standard and distribution-shifted datasets.
Theoretical Foundations
The primary innovation lies in formally connecting SD to the variational inference framework that underpins contemporary Bayesian approximations in DNNs. In SD, residual blocks are stochastically omitted during training with layer-wise survival probabilities. The paper identifies that MCSD can be interpreted as optimizing the evidence lower bound (ELBO) via stochastic path sampling and that inference via multiple Monte Carlo samples over SD configurations yields an effective approximation to the Bayesian predictive posterior.
Key theoretical claims:
- SD samples network depth at inference time, inducing an implicit posterior over model architectures.
- Training with SD and weight decay approximates optimization of the variational ELBO, analogously to MCD and MCDB but with architectural stochasticity at the block-level.
- At inference, T stochastic forward passes with SD active yield an unbiased estimator of the predictive posterior, providing epistemic uncertainty measures.
Methodological Comparison
MCD applies independent dropout to units at inference to sample weights from the variational family, while MCDB targets spatially contiguous regions for convolutional layers, aligning regularization with spatial hierarchies. MCSD, in contrast, operates on the architectural level, dropping residual blocks, thereby altering effective network depth per sample:
- MCSD requires the existence of skip connections, inherently limiting its applicability to architectures with residual design.
- Sampling is performed at the block level, resulting in a coarser granularity and increased diversity in functional composition compared to MCD/MCDB.
Experimental Protocol and Implementation
Experiments are conducted on prominent object detection architectures: Faster R-CNN (CNN-based, two-stage), YOLOv8x (CNN-based, single-stage), and RT-DETRx (Transformer-based, single-stage). Models are evaluated on the COCO dataset for in-distribution performance and COCO-O for domain shifts. UQ metrics include mean Average Precision (mAP), Brier Score, Expected Calibration Error (ECE), and Area Under the Accuracy-Rejection Curve (AUARC).
The regularizers are injected at varying architectural depths (early vs. late blocks), with a comprehensive ablation over drop rates, number of Monte Carlo samples, and detection confidence thresholds.
The crucial experimental finding is that optimal stochastic regularization placement is both architecture- and method-dependent. Further, MCDB placements are highly fragile, where misplacement leads to severe performance degradation.
Accuracy–Uncertainty Trade-off
A Pareto analysis quantifies the trade-off between mAP and uncertainty ranking (AUARC) for each UQ method. Notably:
Calibration and Uncertainty Ranking
Comparative evaluation of calibration and ranking quality shows:
- For dense detectors (YOLOv8x, RT-DETRx), MCSD achieves the lowest ECE and highest AUARC among methods, with MCD trailing closely in accuracy.
- The two-stage Faster R-CNN exhibits broader entropy ranges and better expressivity of epistemic uncertainty under shift, but at the cost of higher ECE, indicating overconfidence.
- MCDB frequently yields lower calibration quality unless restricted to final layers.
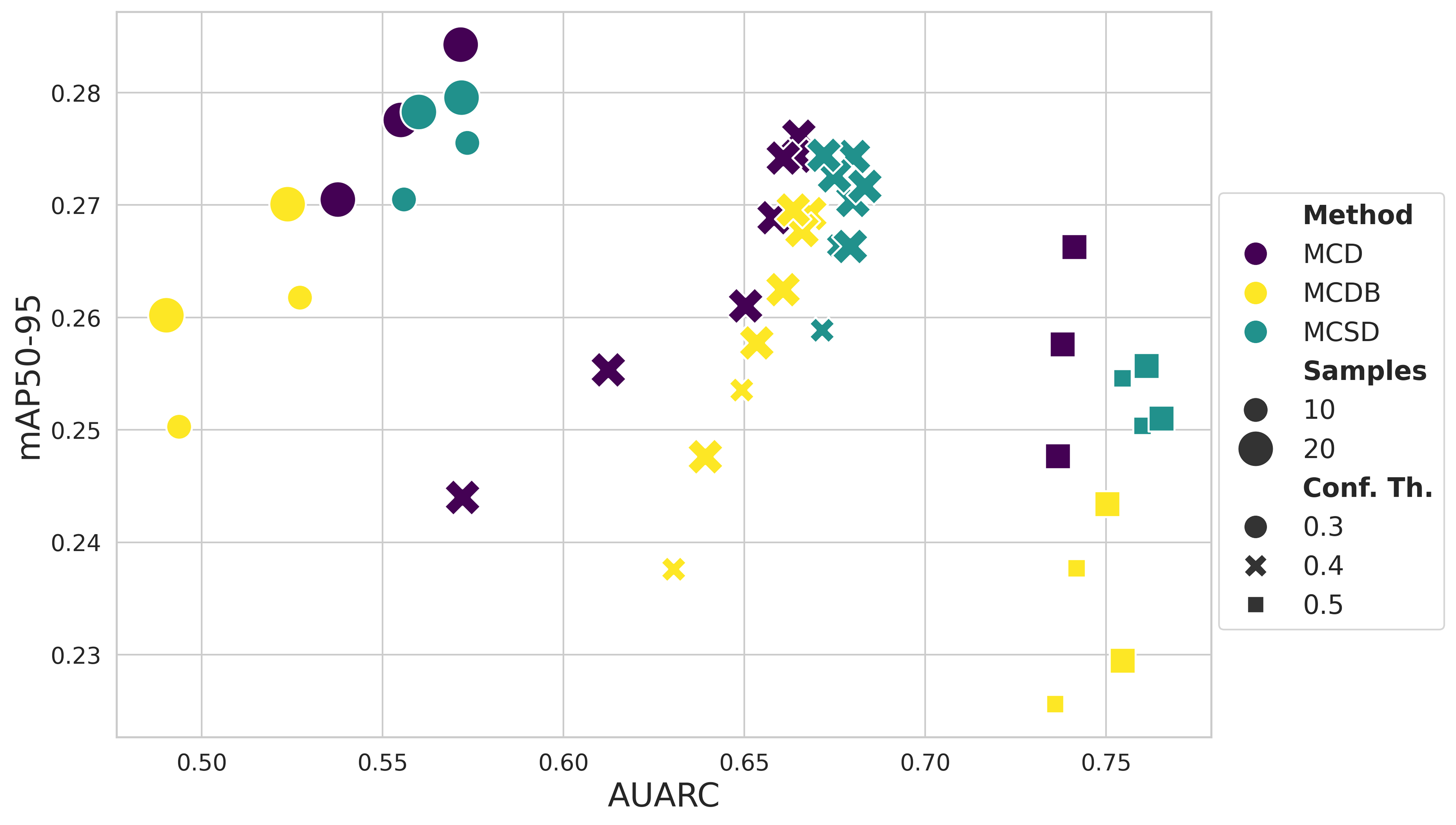
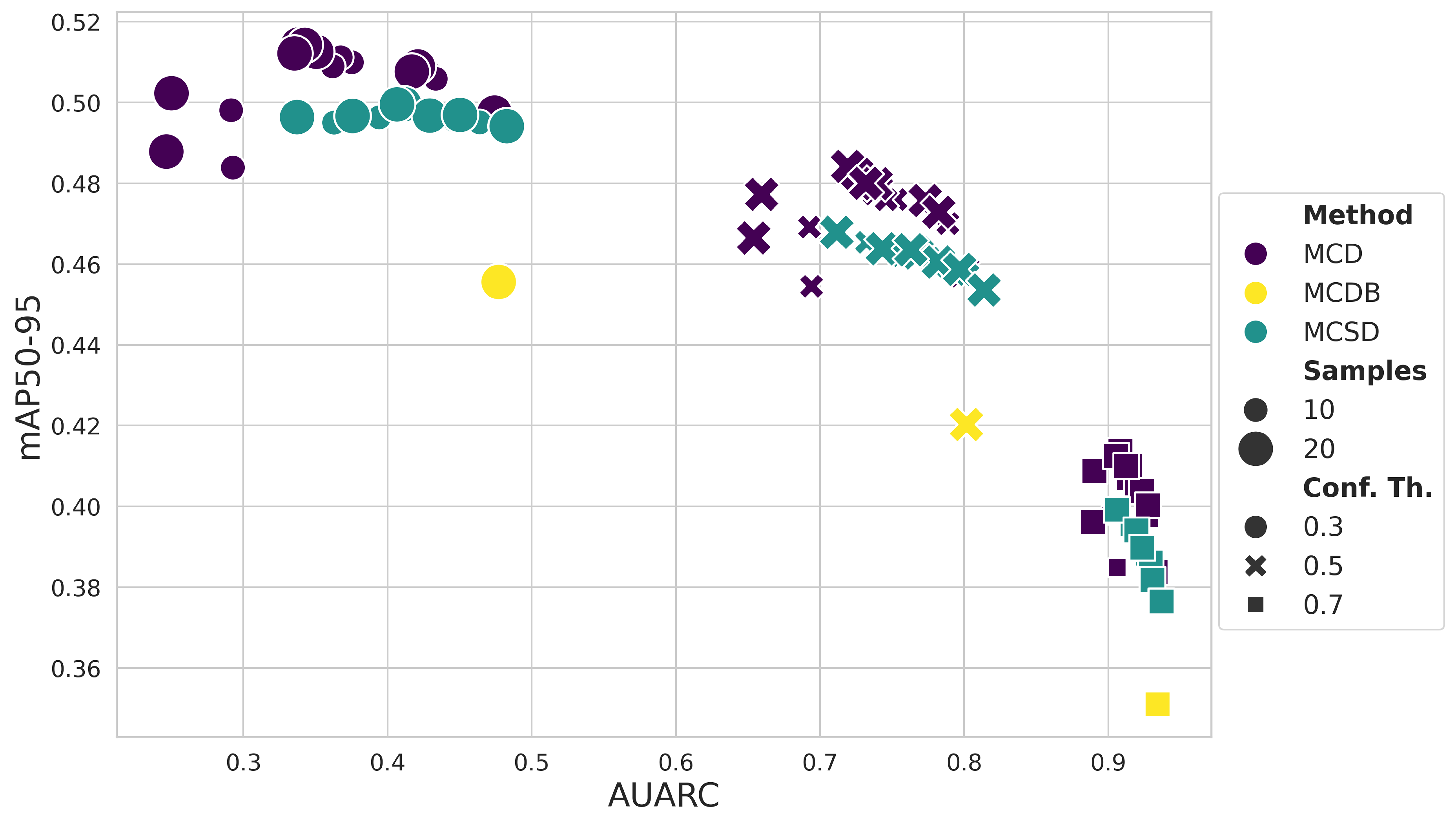
Figure 1: Pareto analysis for Faster R-CNN demonstrates the nuanced mAP–AUARC trade-off across configurations.
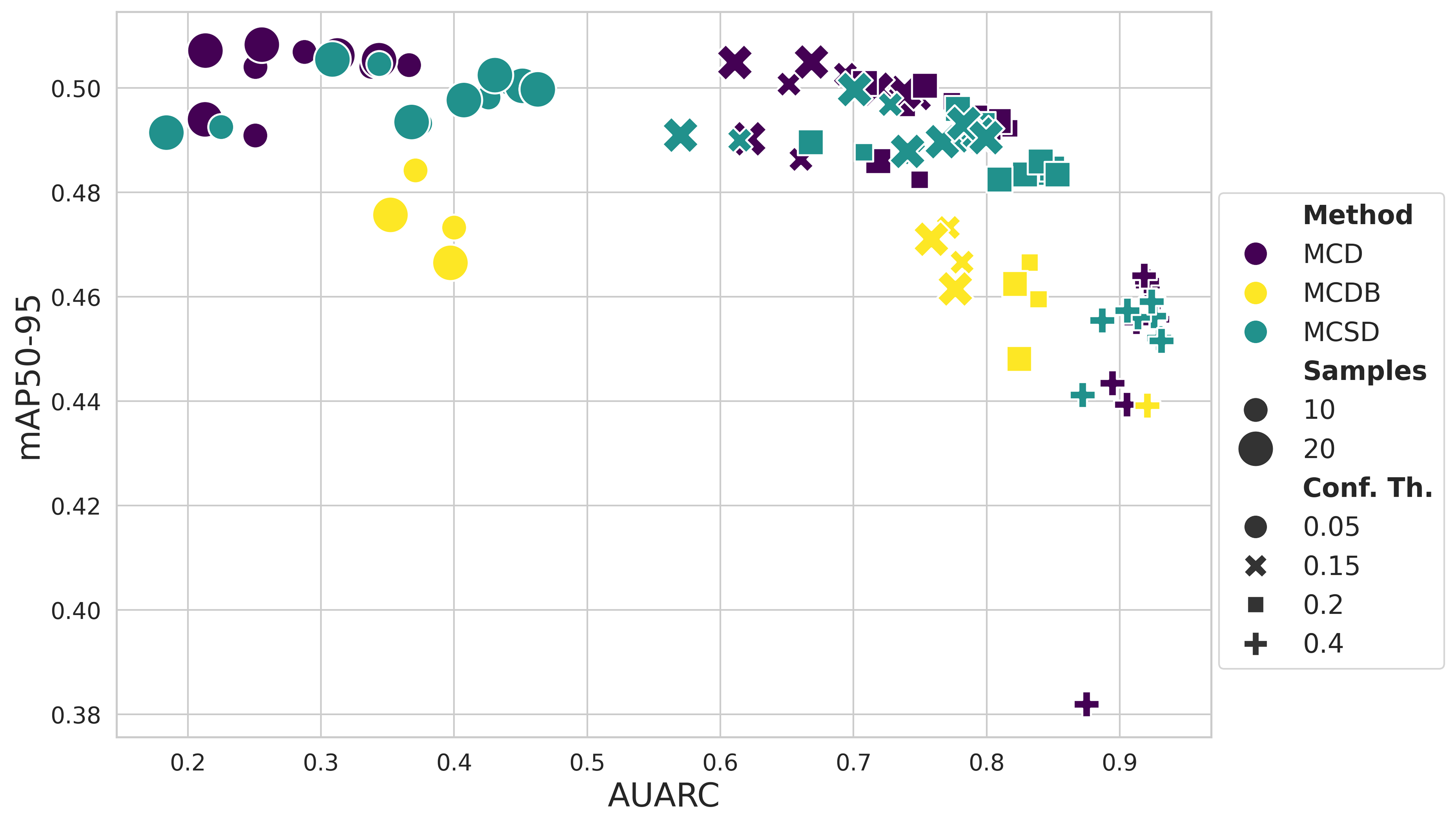
Figure 5: Pareto front for YOLOv8x, illustrating trends consistent with RT-DETRx and showing MCSD's competitive uncertainty ranking.
Robustness under Distribution Shift
Robust UQ under OOD conditions is essential for deployment. Across increasing distribution shifts:
- All methods experience mAP degradation; however, MCSD maintains strict parity with MCD in both accuracy and entropy response, even for severe shifts.
- Dense detectors show compressed entropy scaling, reflecting limited expressivity in uncertainty under distribution shift, in contrast to the wider entropy range of Faster R-CNN.
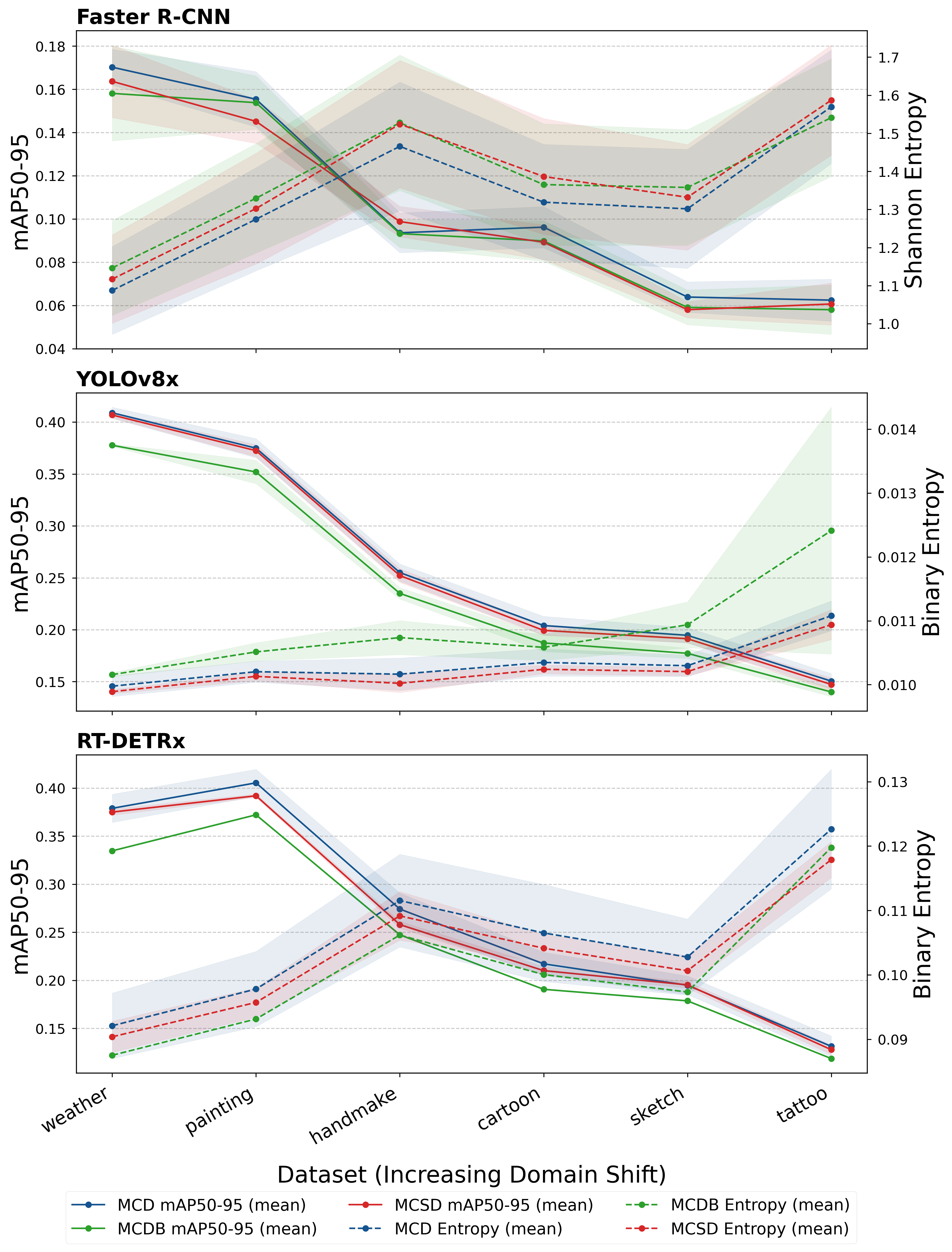
Figure 3: Performance under distribution shift on the COCO-O benchmark; MCSD and MCD remain robust in uncertainty response across all architectures.
Figure 4: Qualitative outputs under domain shift; MCSD maintains recall and detection density similar to MCD, while MCDB can become highly conservative.
Ablation: Stochastic Layer Placement
The efficacy of UQ is impacted by the phase in which stochastic regularization is applied:
- In YOLOv8x, stochasticity earlier in the network enhances calibration while later stages improve uncertainty ranking.
- For RT-DETRx, late-stage stochasticity uniformly optimizes both ECE and AUARC.
- MCSD’s performance is robust to placement but optimal settings are architecture specific.
Limitations
MCSD, while theoretically principled and empirically effective, is limited to architectures with residual paths. Furthermore, like all MC-based methods, it incurs linear compute overhead with the number of Forward passes for UQ at inference. Absolute calibration remains highly architecture sensitive—dense detectors often display compressed uncertainty response and require bespoke calibration strategies for OOD interpretability.
Implications and Future Directions
The establishment of MCSD as a Bayesian approximation expands the toolkit for scalable UQ, particularly for residual- and transformer-based detectors. Its empirical parity with MCD in predictive performance, and superiority in calibration and uncertainty ranking, recommend it for scenarios where overconfidence poses operational risk. Future directions include:
- Exploring MCSD variants in deterministic networks via synthetic residualization
- Developing hierarchical or adaptive SD schedules to enrich posterior expressivity
- Hybridizing MCSD with single-pass uncertainty estimation to reduce inference cost
Conclusion
Monte Carlo Stochastic Depth (MCSD) is theoretically and empirically validated as a scalable, architecturally-compatible, and robust method for uncertainty estimation in modern deep learning, complementing and in several contexts exceeding established methods such as MCD and MCDB in object detection tasks. Its performance under domain shift and strong uncertainty ranking support its adoption for high-assurance AI systems, with future research poised to expand its generalizability and efficiency.