- The paper introduces the Judge Sensitivity Score (JSS) to assess decision stability when LLM judges are subjected to paraphrased prompts.
- It reveals that prompt artifacts, particularly polarity inversion, drive significant inconsistency, impacting factuality evaluations and other tasks.
- Empirical evaluations across nine judge models indicate that task structure and prompt design, not model scale, determine decision robustness.
JudgeSense: A Benchmark for Prompt Sensitivity in LLM-as-a-Judge Systems
Introduction and Motivation
JudgeSense addresses a critical blind spot in the reliability of LLM-as-a-judge systems: decision stability under semantically equivalent prompt paraphrasing. While previous work has shown that LLMs can achieve high agreement with human raters when acting as automated judges on tasks such as factuality or coherence (Zheng et al., 2023) [lin2022truthfulqa], these systems have not been rigorously evaluated for stability when the evaluation prompt is reworded. In large-scale benchmarking and model evaluation pipelines, seemingly trivial differences in prompt phrasing can have outsized effects on decisions, potentially undermining the reproducibility and comparability of results.
To quantify this phenomenon, the authors introduce the Judge Sensitivity Score (JSS), which measures the fraction of semantically equivalent paraphrase pairs on which a judge returns the same decision. The paper systematically evaluates nine widely used judge models across 494 validated paraphrase pairs spanning coherence, factuality, relevance, and preference tasks, providing standardized empirical evidence for prompt sensitivity and releasing a new public benchmark for future research.
Judge Sensitivity Score and Benchmark Construction
The Judge Sensitivity Score (JSS) is formally defined as the mean agreement rate on a set of (prompt-paraphrase, evaluation item) pairs:
JSS(j,t)=∣P∣1i=1∑∣P∣δ(j(pi),j(pi′)),
where j is the judge model, t the task, P the set of paraphrase pairs, and δ() the indicator of label equality.
JSS is bounded in [0,1], with lower values indicating higher prompt-induced instability. The authors argue for a practical reliability threshold at JSS~<0.8, i.e., more than one in five decisions flip under rephrasing.
Dataset Construction: The benchmark is built from established evaluation datasets: TruthfulQA (factuality), SummEval (coherence), BEIR (relevance), and MT-Bench (preference). Each task is associated with five minimalist, instruction-only prompt variants. The paraphrase equivalence of each pair is verified by an independent strong classifier. After exclusion of six non-equivalent factuality pairs, 494 pairs remain, covering both binary and Likert-scale labeling tasks.
Evaluation Protocol: Nine judges (five commercial—GPT-4o, GPT-4o-mini, Claude Sonnet/Haiku 4.5, Gemini 2.5-Flash; four open-source—Llama-3.1-70B, Mistral-7B, Qwen-2.5-72B, DeepSeek-R1) are evaluated using strictly greedy decoding. Outputs are normalized for structured answer parsing; error and exclusion rates are logged and reported.
Empirical Results and Analysis
Core JSS Results Across Judges and Tasks
The results surface several critical findings:
- Coherence is the only task where judges meaningfully differ: JSS ranges from 0.389 (Gemini-2.5-Flash) to 0.992 (Claude-Sonnet-4-5). No other task shows similar spread.
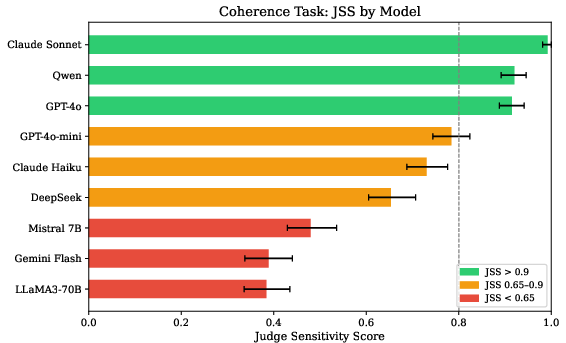
Figure 1: Coherence JSS by judge model. Error bars show 95% bootstrap confidence intervals.
- On factuality, all judges, regardless of architecture or scale, cluster near JSS ≈ 0.63 (i.e., a ∼37% flip rate). This apparent inconsistency is traced to a polarity-inverted prompt template, not model defects.
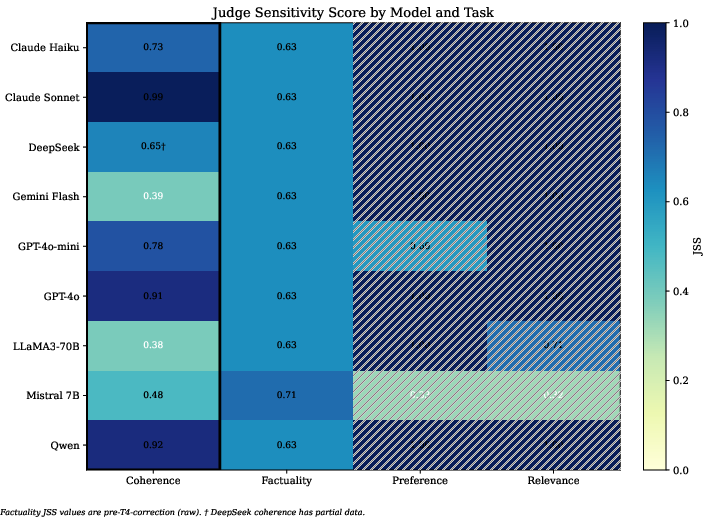
Figure 2: JSS across evaluation dimensions. Factuality values shown are raw (uncorrected). Hatched cells indicate degenerate always-A behavior.
- After correcting for polarity inversion, factuality JSS rises to ≈0.9+ for all models, highlighting that the observed instability is a prompt design artifact.
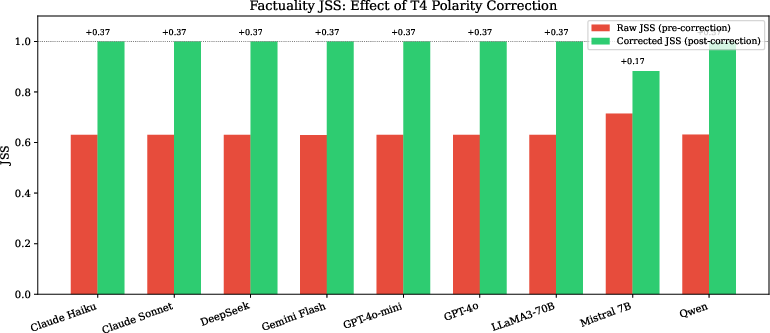
Figure 3: Effect of polarity-inverted template on factuality JSS. Raw values underestimate judge consistency due to polarity mismatch; corrected values reflect underlying agreement.
- Pairwise preference and relevance tasks are dominated by "always-A" degenerate behavior in 8 out of 9 judges: the models output "A" for all pairs, making JSS uninformative in the absence of option-order randomization. Only Mistral-7B departs from this pattern, yielding a chance-level flip rate.
Detailed Empirical Claims
- Model scale does not predict consistency. The largest models are not always the most stable; for instance, Gemini-2.5-Flash demonstrates the worst coherence JSS while mid-scale models (Claude-Sonnet-4-5, Qwen-2.5-72B) excel.
- Task structure affects the detectability of instability. Likert-scale tasks (coherence) surface more prompt-induced flips than binary decision tasks because the answer space is richer.
- Polarity inversion in prompts drives artifactual disagreement. The polarity-inverted template in factuality evaluation is responsible for nearly all observed inconsistency; correcting for this effect yields high JSS across all models.
- Negative Cohen's κ scores for some models on coherence tasks suggest systematic anti-correlation, i.e., models responding with opposite labels under different paraphrases.
Practical Implications and Recommendations
The findings have urgent implications for the use and reporting of LLM-as-a-judge systems:
- For researchers and practitioners: JSS should be reported alongside traditional human agreement scores in any evaluation pipeline; high human agreement is insufficient if judge decisions are unstable under paraphrase.
- Judge selection: Model size or vendor is an unreliable proxy for prompt sensitivity. Coherence JSS is a practical discriminator. Claude-Sonnet-4-5, Qwen-2.5-72B, and GPT-4o (all JSS >0.9) are recommended for robust judging; models with JSS j0 are unsuitable for settings in which prompt variation is unavoidable.
- Prompt design: Avoid polarity-inverting templates unless normalization is performed post hoc. Practitioners designing factuality prompts should ensure polarity consistency.
- Pairwise tasks: Option-order randomization is necessary before JSS is informative for relevance and preference tasks due to strong position biases.
Theoretical and Methodological Implications
JudgeSense reframes LLM-as-a-judge reliability: self-agreement under prompt paraphrasing is independent of human agreement, and is essential for reproducibility. The study establishes that much apparent variation in factuality tasks is primarily attributable to prompt artifacts, not model architecture or training. This rebuts any presumption that more advanced or larger models are inherently more stable as judges (Grattafiori et al., 2024, OpenAI et al., 2023, Qwen et al., 2024, Team et al., 2023, DeepSeek-AI et al., 22 Jan 2025).
The benchmark also makes a case for reporting distributional and multi-paraphrase metrics rather than single-prompt outcomes (Zhuo et al., 2024, Sclar et al., 2023, Thakur et al., 2024), and motivates the use of scaled or multiclass verdict spaces (like Likert) to better surface instability.
Future extensions to JudgeSense might include: randomized option-order to disentangle position bias from true insensitivity in pairwise labeling (Shi et al., 2024); multilingual paraphrase sets to examine language effects; and fine-tuning for paraphrase invariance during instruction tuning.
Conclusion
JudgeSense provides the first formal, standardized metric—Judge Sensitivity Score—for measuring the stability of LLM-as-a-judge decisions under semantically equivalent prompt paraphrasing. The results demonstrate that prompt formulation, not model scale or architecture, is often the dominant cause of observed instability. The released benchmark dataset and codebase should serve as a foundation for reporting and improving judge reliability in automated evaluation pipelines.
Researchers are encouraged to adopt JSS as a standard reporting metric and to prioritize prompt-invariant judging in both academic and production settings. Systematic mitigation of prompt-based artifacts—by both engineering (prompt normalization, template curation) and methodological (randomization, multi-template evaluation) means—is now essential for credible LLM-as-a-judge practice.
References:
(2604.23478, Zheng et al., 2023, Sclar et al., 2023, Zhuo et al., 2024, Thakur et al., 2024, Qwen et al., 2024, Team et al., 2023, DeepSeek-AI et al., 22 Jan 2025, Grattafiori et al., 2024, Shi et al., 2024, OpenAI et al., 2023).
Conclusion
JudgeSense establishes the necessity of prompt-paraphrase sensitivity benchmarking for LLM-as-a-judge systems and proposes JSS as a transparent, actionable metric with immediate applicability. The supporting empirical analysis shows prompt artifacts, not model differences, are the major source of unreliability in factuality judgments, while coherence evaluation best exposes model-dependent instability. System design and reporting practices must now incorporate these findings to ensure robust and reproducible benchmark results in the era of LLM-automated evaluation.