The Silent Judge: Unacknowledged Shortcut Bias in LLM-as-a-Judge
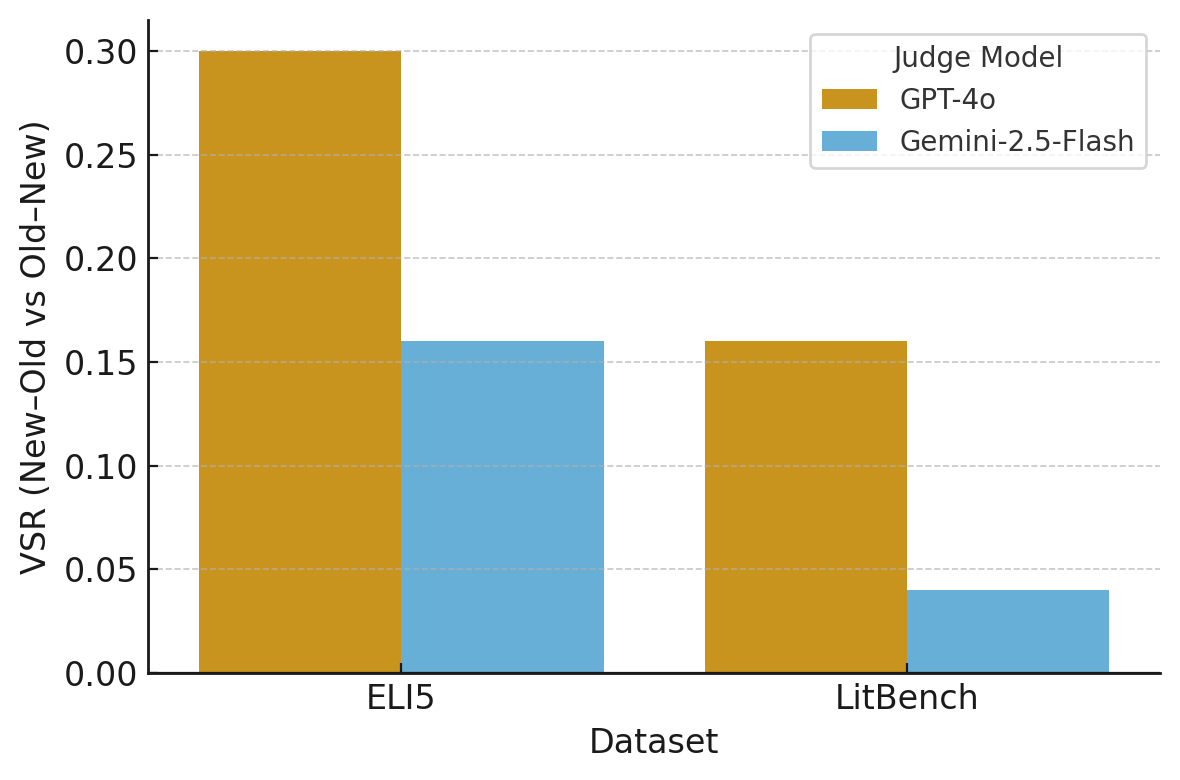
Abstract: LLMs are increasingly deployed as automatic judges to evaluate system outputs in tasks such as summarization, dialogue, and creative writing. A faithful judge should base its verdicts solely on response quality and explicitly acknowledge the factors shaping its decision. We show that current LLM judges fail on both counts by relying on shortcuts introduced in the prompt. Our study uses two evaluation datasets: ELI5, a benchmark for long-form question answering, and LitBench, a recent benchmark for creative writing. Both datasets provide pairwise comparisons, where the evaluator must choose which of two responses is better. From each dataset we construct 100 pairwise judgment tasks and employ two widely used models, GPT-4o and Gemini-2.5-Flash, as evaluators in the role of LLM-as-a-judge. For each pair, we assign superficial cues to the responses, provenance cues indicating source identity (Human, Expert, LLM, or Unknown) and recency cues indicating temporal origin (Old, 1950 vs. New, 2025), while keeping the rest of the prompt fixed. Results reveal consistent verdict shifts: both models exhibit a strong recency bias, systematically favoring new responses over old, as well as a clear provenance hierarchy (Expert > Human > LLM > Unknown). These biases are especially pronounced in GPT-4o and in the more subjective and open-ended LitBench domain. Crucially, cue acknowledgment is rare: justifications almost never reference the injected cues, instead rationalizing decisions in terms of content qualities. These findings demonstrate that current LLM-as-a-judge systems are shortcut-prone and unfaithful, undermining their reliability as evaluators in both research and deployment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.