- The paper introduces NVIDIA’s CuTile abstraction to simplify GPU kernel programming for AI workloads on Hopper and Blackwell GPUs.
- It compares CuTile performance against cuBLAS, Triton, WMMA, and SIMT, showing up to 79% GEMM throughput and 2.5× fused attention gains on B200.
- The study highlights cross-architecture optimization challenges, emphasizing the need for improved compiler tuning for workstation-class GPUs.
Evaluating CUDA Tile for AI Workloads on Hopper and Blackwell GPUs
Introduction and Overview
The paper "Evaluating CUDA Tile for AI Workloads on Hopper and Blackwell GPUs" (2604.23466) addresses the challenges associated with high-performance GPU kernel programming, particularly as they relate to modern transformer architectures and dense AI workloads. CuTile, a Python-based, tile-centric abstraction introduced by NVIDIA, is proposed to simplify GPU kernel development without sacrificing Tensor Core and Tensor Memory Accelerator functionality. This study constitutes the first independent, cross-architecture evaluation of CuTile on NVIDIA's Hopper and Blackwell GPUs.
Methodology and Implementation Variants
The study evaluates CuTile's performance against established methods including cuBLAS, Triton, WMMA, and raw SIMT models. It focuses on several representative AI workloads: General Matrix Multiply (GEMM), fused multi-head attention, and end-to-end LLM inference. The GPUs assessed include the H100 NVL (Hopper), B200, and RTX PRO 6000 (Blackwell Server Edition). The study examines not only raw performance but also portability across architectures, an area where Triton has established strength through its ability to sustain high performance across diverse hardware configurations.
GEMM Evaluation
CuTile's GEMM performance demonstrated substantial efficiency, achieving 52-79% of the throughput of the optimized cuBLAS library across Blackwell architectures, despite requiring far fewer lines of code than WMMA kernels. The gains CuTile presents over WMMA underscore its practicality as it notably simplifies the kernel development process for Tensor Cores without matching cuBLAS's upper limit of performance.
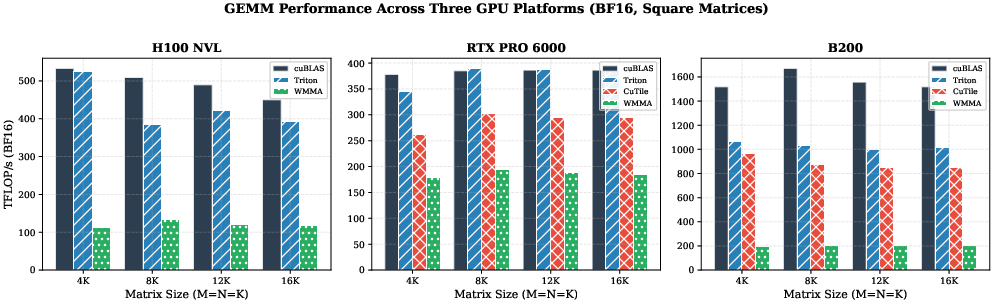
Figure 1: GEMM performance (TFLOP/s, BF16) across four square matrix sizes on three GPUs. cuBLAS dominates on all platforms. CuTile (available only on Blackwell) achieves 52-79% of cuBLAS, significantly outperforming WMMA. Raw SIMT is omitted (6-8 TFLOP/s) for visual clarity.
CuTile shines in its application to fused multi-head attention, especially on the B200 GPU where it achieves up to 1{,}007 TFLOP/s, outperforming FlashAttention-2 by 2.5 times. However, this performance boost is highly architecture-dependent, as evidenced by CuTile's reduced efficacy on the RTX PRO 6000 where throughput reaches only 53% of FlashAttention-2, revealing significant cross-architecture optimization gaps.
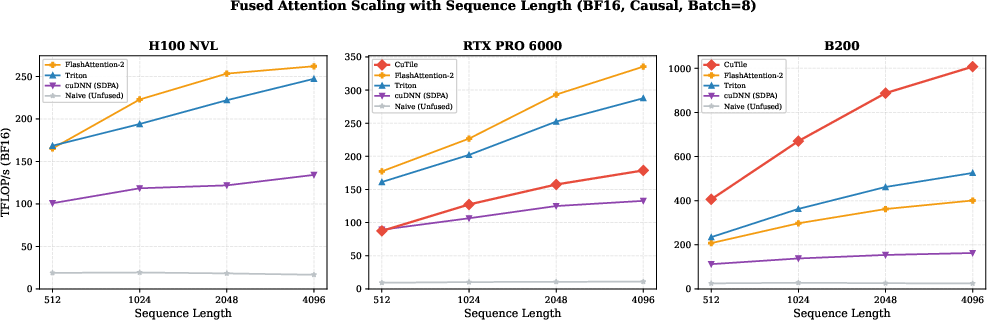
Figure 2: Fused attention throughput (TFLOP/s) vs. sequence length (BF16, causal, batch=8). On the B200 (right), CuTile (red) dramatically outscales all other implementations, reaching up to 1{,}007 TFLOP/s.
CuTile Attention Paradox
The substantial performance variance between the B200 and RTX PRO 6000 platforms, despite identical CuTile kernel code, underscores a critical gap in compiler optimization specifically targeted at different Blackwell variants. This points to the importance of future compiler maturity and enhancements to better cater to workstation-class GPUs.
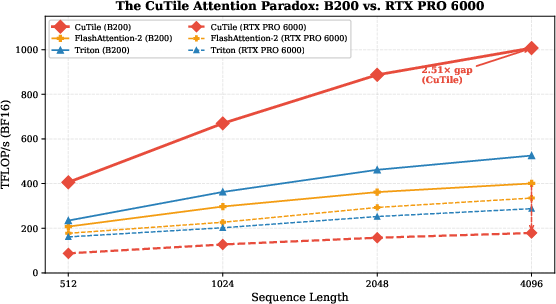
Figure 3: The CuTile attention paradox: identical kernel code produces 2.51 times higher throughput than FlashAttention-2 on B200 (solid lines) but 47% lower on RTX PRO 6000 (dashed lines). This 5.6 times cross-architecture gap is the largest observed for any abstraction.
Implications and Future Directions
CuTile provides a substantial productivity benefit by allowing high-performance kernel expression in tens of lines of Python code. Its applicability is most pronounced on the B200 (datacenter-class Blackwell GPUs) due to impressive performance in fused attention tasks. However, the workstation-class RTX PRO 6000 exposes a need for significant cross-architecture tuning improvements. This suggests caution in deploying CuTile widely without thorough, hardware-specific benchmarking.
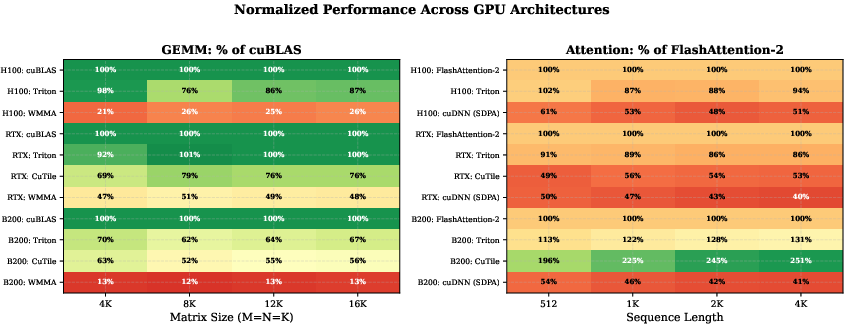
Figure 4: Normalized performance heatmap. Left: GEMM throughput as percentage of cuBLAS. Right: attention throughput as percentage of FlashAttention-2. CuTile on B200 achieves up to 251% of FA2 (dark green), while CuTile on RTX PRO 6000 reaches only 53% (orange-red).
Conclusion
CuTile introduces a promising paradigm shift towards simplified, highly efficient kernel development for AI workloads within NVIDIA's ecosystem. It demonstrates potential as a practical replacement for more complex hand-written approaches on Blackwell architecture, specifically for attention workloads on datacenter-grade GPUs. However, issues of portability and optimization across different architectures remain, emphasizing the importance of targeted compiler advancements. As CUDA Toolkit and tileiras compiler technologies evolve, CuTile's utility and range are expected to expand, potentially offering comprehensive GPU kernel solutions for AI inference.