HipKittens: Fast and Furious AMD Kernels (2511.08083v1)
Abstract: AMD GPUs offer state-of-the-art compute and memory bandwidth; however, peak performance AMD kernels are written in raw assembly. To address the difficulty of mapping AI algorithms to hardware, recent work proposes C++ embedded and PyTorch-inspired domain-specific languages like ThunderKittens (TK) to simplify high performance AI kernel development on NVIDIA hardware. We explore the extent to which such primitives -- for explicit tile-based programming with optimized memory accesses and fine-grained asynchronous execution across workers -- are NVIDIA-specific or general. We provide the first detailed study of the programming primitives that lead to performant AMD AI kernels, and we encapsulate these insights in the HipKittens (HK) programming framework. We find that tile-based abstractions used in prior DSLs generalize to AMD GPUs, however we need to rethink the algorithms that instantiate these abstractions for AMD. We validate the HK primitives across CDNA3 and CDNA4 AMD platforms. In evaluations, HK kernels compete with AMD's hand-optimized assembly kernels for GEMMs and attention, and consistently outperform compiler baselines. Moreover, assembly is difficult to scale to the breadth of AI workloads; reflecting this, in some settings HK outperforms all available kernel baselines by $1.2-2.4\times$ (e.g., $d=64$ attention, GQA backwards, memory-bound kernels). These findings help pave the way for a single, tile-based software layer for high-performance AI kernels that translates across GPU vendors. HipKittens is released at: https://github.com/HazyResearch/HipKittens.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces HipKittens (HK), a new way to write super-fast programs (called “kernels”) for AMD graphics cards (GPUs) that power AI. Until now, the fastest AMD kernels were written in raw assembly—a very low-level, hard-to-write language used by only a few experts. HipKittens makes high performance much easier to achieve by giving developers simple, reusable building blocks (like LEGO tiles) that map AI algorithms efficiently onto AMD hardware. The big idea: the same “tile-based” programming style that worked well for NVIDIA GPUs can be adapted—and rethought—to run great on AMD too.
What questions does the paper ask?
The paper focuses on three simple questions:
- Can the tile-based programming style (popular on NVIDIA) also work on AMD GPUs?
- If yes, what changes are needed to make AMD kernels fast without using raw assembly?
- Can those changes lead to AMD kernels that match or beat the best hand-tuned code and compilers across common AI tasks (like matrix multiplication and attention)?
How did the researchers approach the problem?
The authors designed HipKittens, a C++ framework with a small set of “opinionated” primitives (simple, well-chosen tools) that help developers write fast kernels for AMD. Think of it like giving chefs a compact set of reliable, high-quality cookware instead of a cluttered kitchen.
They focused on three main areas:
1) Tiles and memory: making data movement fast
- Tiles are like neatly arranged slices of a big spreadsheet. Working on tiles lets the code use the GPU’s memory more efficiently.
- Registers: These are tiny, very fast “pockets” inside the GPU where data is kept while computing. On AMD, the compiler (the “translator” from C++ to machine code) sometimes blocks the best use of these pockets. HipKittens lets developers “pin” registers—meaning they can directly choose which pockets to use and avoid slow extra moves.
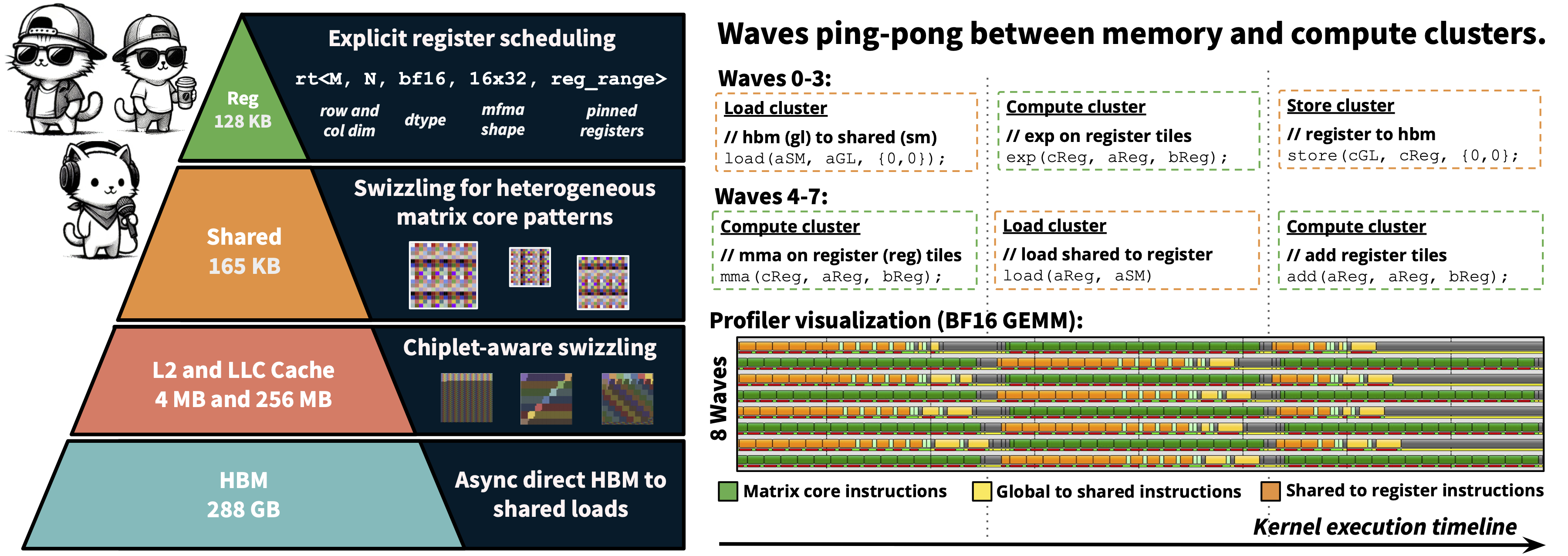
- Shared memory: This is a small, fast “whiteboard” that threads (groups of 64 mini-workers called “waves”) use together. If threads try to write to the same part at the same time, they collide (“bank conflicts”), which slows things down. HipKittens adds “swizzling”—a clever rearranging of how data is laid out—so threads don’t bump into each other.
- Global memory: This is the large, slow storage (HBM). HipKittens uses AMD’s direct async loads from HBM to shared memory to avoid unnecessary detours through registers.
2) Schedules: overlapping compute and memory
GPUs are fast when they can compute and load data at the same time. NVIDIA commonly uses a “producer-consumer” schedule where some waves fetch data (producers) and others do math (consumers). On AMD, this pattern wastes registers (because AMD allocates registers statically to all waves), which hurts performance.
HipKittens introduces two simple, general-purpose schedules:
- 8-wave ping-pong: Two waves per processor unit alternate roles—one does math while the other prefetches the next data, then they swap. Imagine two teammates passing a ball back and forth in perfect rhythm. This works great when compute and memory times are similar, and it keeps code compact.
- 4-wave interleave: One wave per unit does both memory and compute in a carefully staggered sequence. This is more fine-grained and can be faster when workloads are unbalanced (more compute-heavy or memory-heavy), but the code is longer.
These schedules are reusable across many AI kernels (GEMMs and attention) and avoid AMD’s producer-consumer pitfalls.
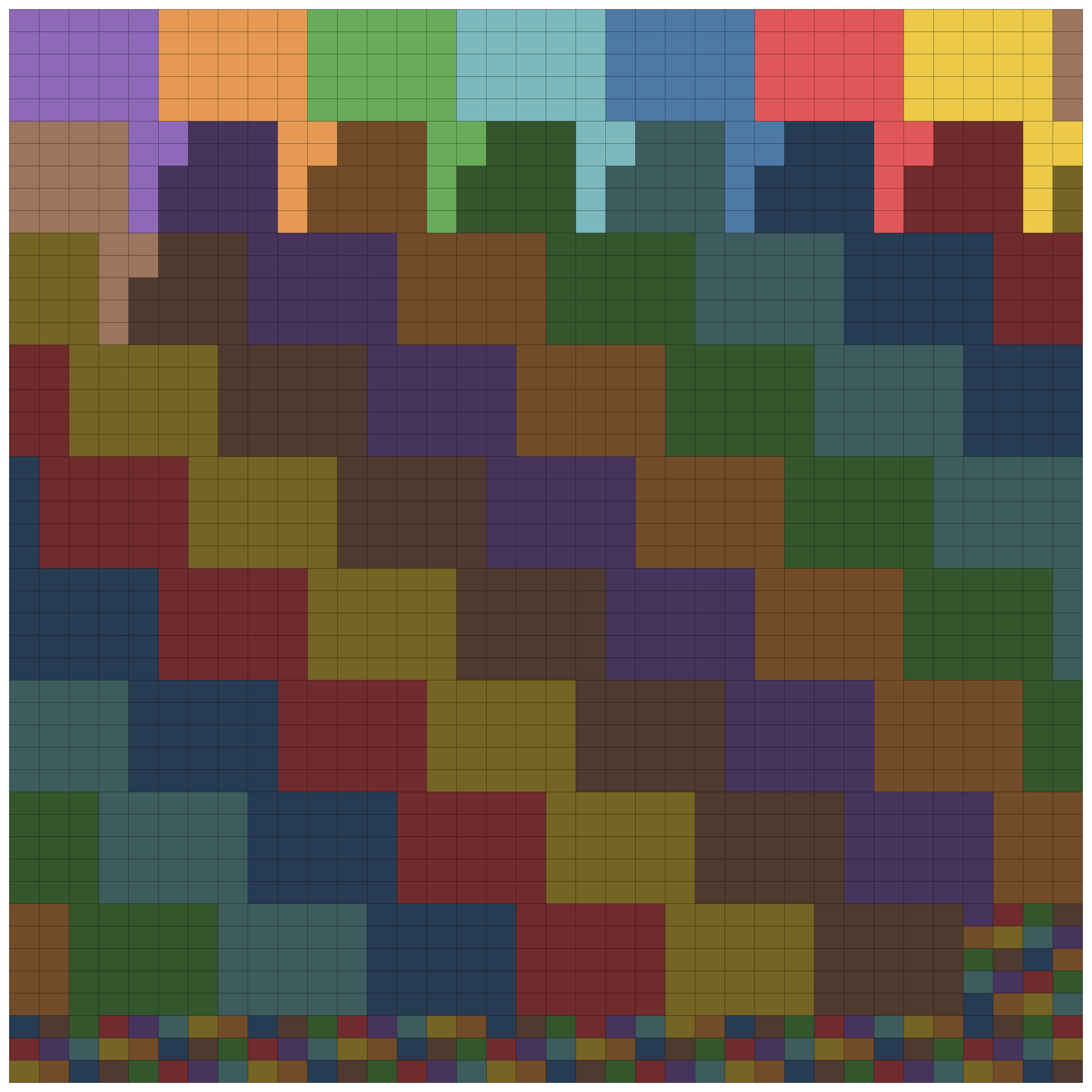
3) Cache-aware work distribution across chiplets
Modern GPUs are built from multiple “chiplets”—like a city made of neighborhoods. Each neighborhood has its own local cache (L2), and the whole city shares a larger cache (LLC). If you schedule work poorly, neighborhoods fetch different parts of the data and miss cache reuse, which wastes bandwidth.
HipKittens adds a “chiplet swizzling” algorithm:
- It groups work so blocks assigned to the same chiplet reuse the same rows/columns of input (boosting L2 cache hits).
- It coordinates across chiplets so they also reuse data in the shared cache (LLC).
- Two tunable knobs control this balance: window height (W) for forming reusable rectangles of work, and chunk size (C) for keeping related work on the same chiplet.
In plain terms: it plans the order of tasks so nearby teams reuse the same tools and don’t constantly run across town to fetch supplies.
What did they find, and why does it matter?
The authors tested HipKittens on AMD’s MI325X (CDNA3) and MI355X (CDNA4) GPUs across common AI workloads:
- GEMMs (matrix multiplications), the backbone of deep learning
- Attention (including multi-head attention, MHA, and group-query attention, GQA), a key part of transformers
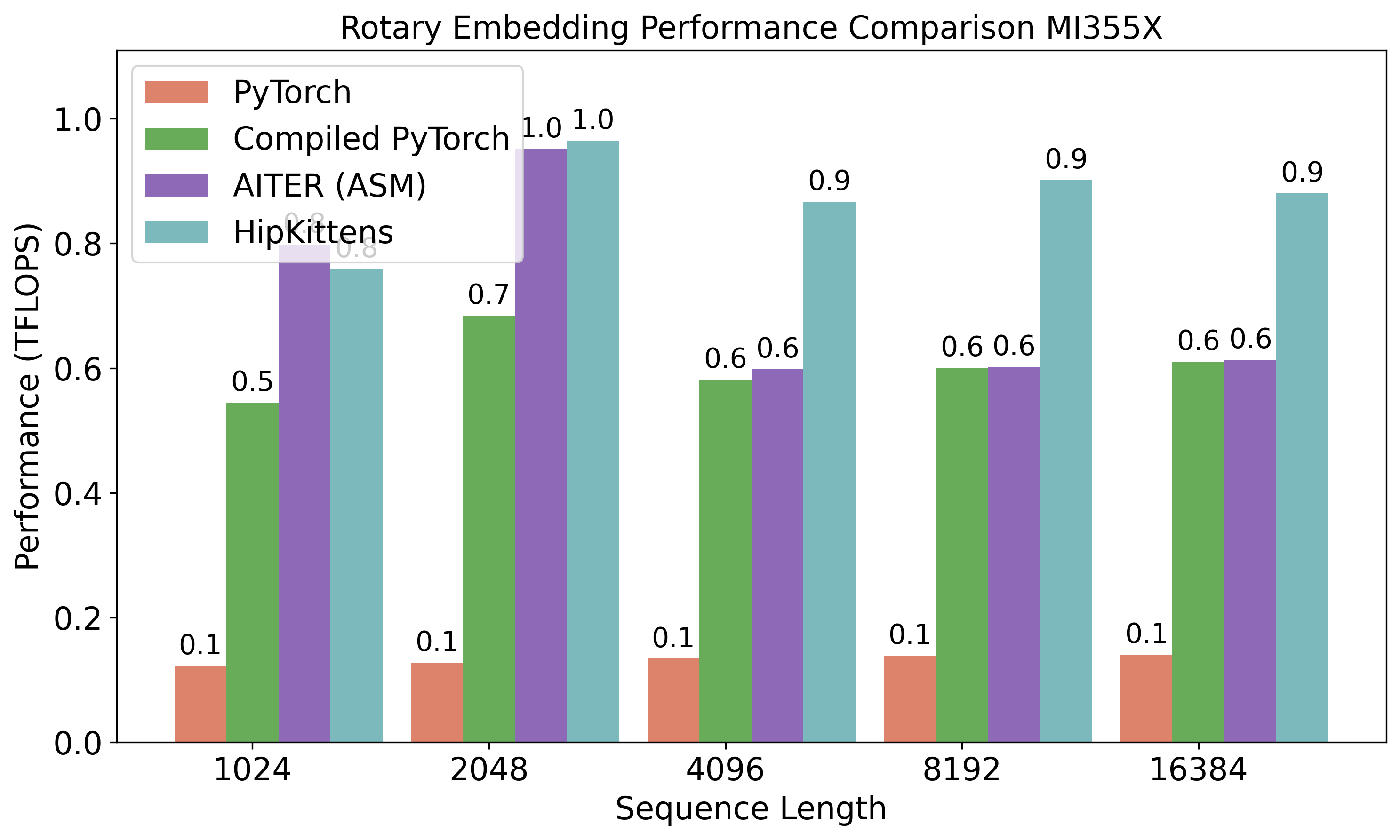
- Memory-bound ops like rotary embeddings (RoPE) and layer normalization
Key results:
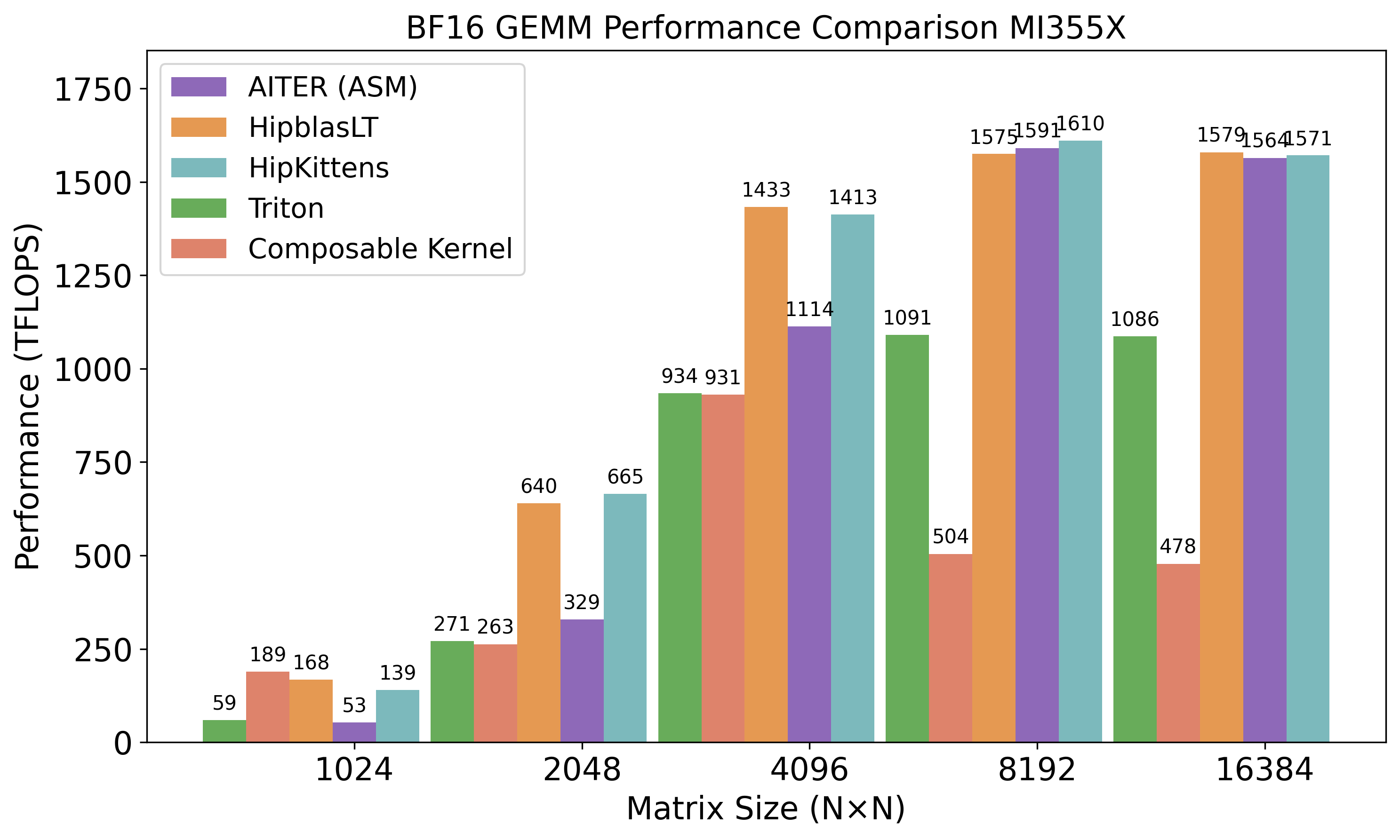
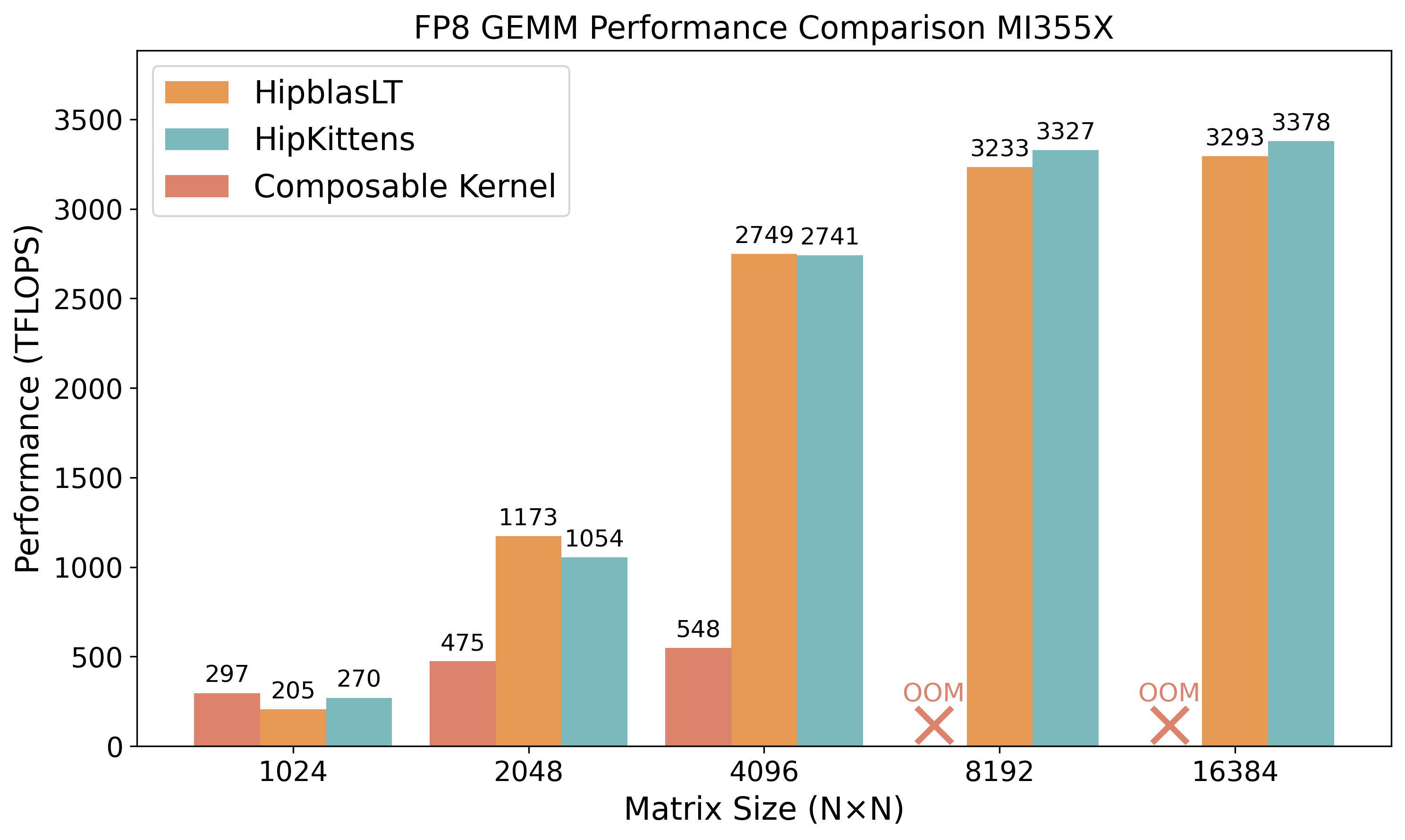
- HipKittens kernels match or beat AMD’s hand-optimized assembly in several cases (BF16 and FP8 GEMMs, attention forward).
- They consistently outperform compiler-generated kernels (e.g., up to 3× faster than Triton for BF16 GEMMs, up to 2× faster than Mojo’s attention forwards).
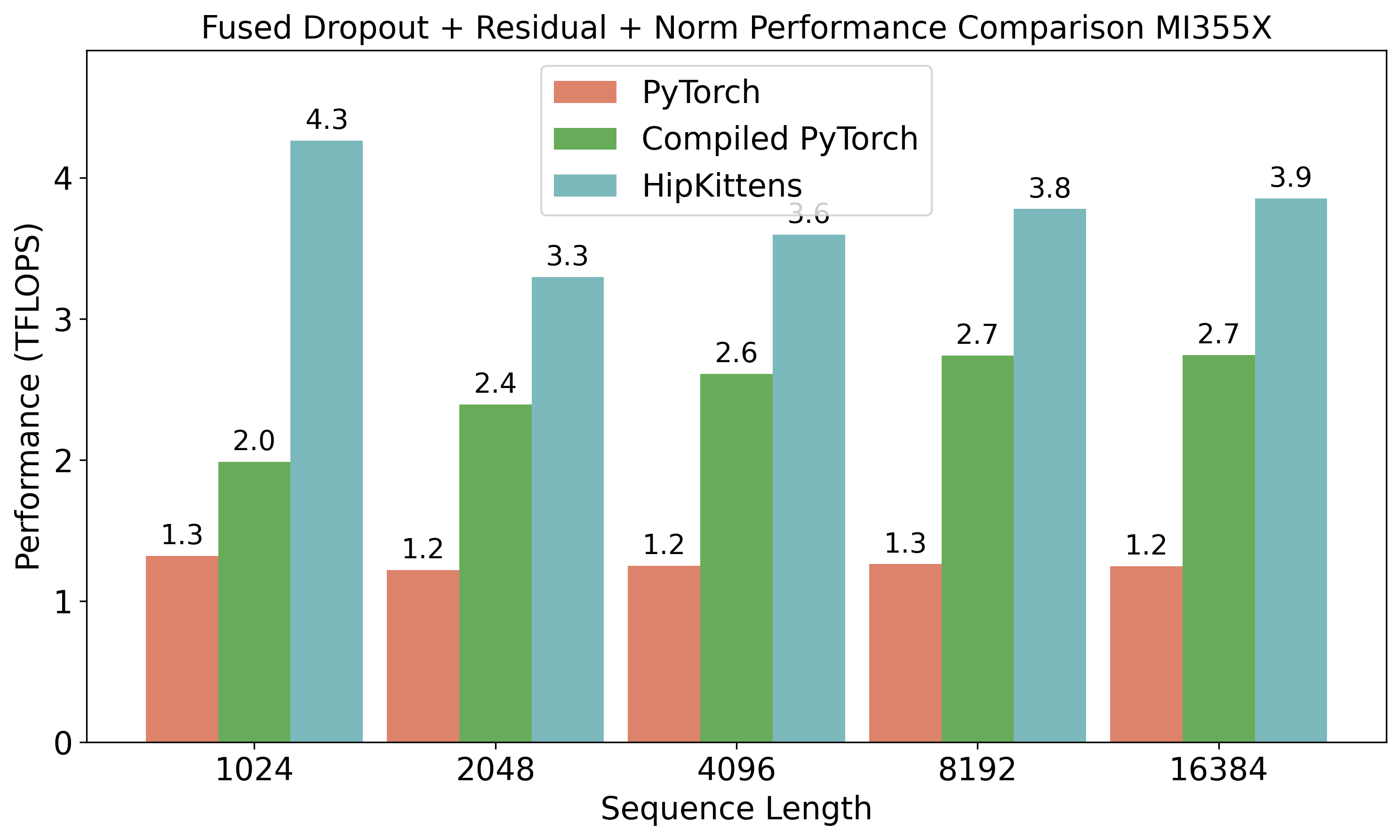
- In areas where assembly libraries don’t cover all shapes or features (like some attention forms or memory-heavy kernels), HipKittens sometimes wins by 1.2–10×.
- The simple 8-wave ping-pong schedule was often enough to reach top performance; the 4-wave interleave schedule pushed even further on tough cases like GQA backward attention.
- Importantly, tile-based programming from ThunderKittens (originally for NVIDIA) transfers to AMD—with new AMD-specific tweaks—suggesting a unified tile-based model can work across different GPU brands.
Why this matters:
- Fast AMD kernels without raw assembly lower the barrier for developers and reduce reliance on a single vendor (the “hardware lottery”).
- It helps use AMD’s strong memory and compute capabilities fully, unlocking more total compute for AI training and inference.
- A common, portable programming style across vendors speeds up innovation and reduces the time-to-performance for new hardware features.
What are the broader implications?
HipKittens shows that a small, well-designed set of primitives—tiles, schedules that overlap compute and memory, and cache-aware grid planning—can give developers the control they need to write high-performance AMD AI kernels without resorting to fragile, hard-to-scale assembly. This:
- Opens the path to a unified, tile-based programming layer that works across GPU vendors.
- Makes high-performance AI more accessible, so more people and teams can optimize new workloads quickly.
- Helps the AI ecosystem tap more hardware capacity, which is crucial to training larger models and serving them efficiently.
The framework is open source (https://github.com/HazyResearch/HipKittens), so others can build on it. If you think of AI as a race car, HipKittens is like a high-quality toolkit that lets more mechanics tune engines for different brands—fast, safely, and in a repeatable way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions suggested by the paper.
- Generality across AMD generations and product lines: HK is validated on CDNA3 (MI325X) and CDNA4 (MI355X) only; it is unclear how the proposed primitives and schedules transfer to future CDNA (e.g., CDNA5) or RDNA compute GPUs with different bank widths, LDS behavior, or matrix core shapes.
- Cross-vendor unification: The paper claims tile primitives can generalize across vendors but HK is AMD-only; there is no demonstration of one unified DSL running unchanged on NVIDIA and AMD, nor an ABI/IR layer that isolates vendor-specific assembly wrapping.
- Compiler evolution sensitivity: Pinned register tiles bypass HIPCC constraints, but the long-term compatibility with evolving ROCm/HIPCC (e.g., if AGPR usage rules change, register allocation policies shift, or ISA constraints tighten) is unexamined; a fall-back path and automated detection are needed.
- Safety and correctness of explicit register pinning: There is no formal verification or tooling to ensure pinned-register schedules avoid hazards (bank conflicts, false dependencies, live range overlap, spills, or deadlocks); methods to statically or dynamically validate correctness would be beneficial.
- Undocumented phase behavior: The LDS phase execution order and bank behavior are stated to be undocumented; the “solver” used to infer phases is not described, validated, or released. A general, provably correct method (and dataset of validations across ISA revisions) is missing.
- Swizzle coverage and automation: HK supports swizzles for “commonly co-occurring” layouts; there is no systematic coverage plan for less common MFMA shapes or mixed layouts, nor an automated swizzle generator that guarantees bank-conflict freedom across all supported instructions.
- Tails and non-multiple tile sizes: Tiles are restricted to multiples of matrix core shapes; handling of boundary tiles (“tails”) and correctness/performance tradeoffs for non-divisible dimensions is not detailed.
- Asynchronous HBM→LDS addressing safety: The paper notes swizzling via HBM addresses for direct async loads but does not discuss bounds checking, alignment constraints, or protection against out-of-range addressing in complex tiling schemes.
- Scheduling selection heuristics: While 8-wave ping-pong and 4-wave interleave are proposed, there is no principled heuristic or auto-tuner to select between them based on workload compute/memory balance, register pressure, or LDS saturation at runtime.
- Pipeline depth vs tile size tradeoffs: The interaction between pipeline depth, MFMA instruction granularity, and register/shared-memory pressure is not fully characterized; a more general model or tuner could automate these choices across problem sizes and dtypes.
- Synchronization overhead characterization: Shared-memory atomics are asserted to have “negligible overhead,” but detailed measurements across workloads (including contention scenarios) and comparison to hardware barriers (if/when available) are missing.
- Grid scheduling generality: The XCD swizzle algorithm targets GEMM; extension to attention, reductions, batched/strided GEMMs, non-rectangular tilings, and kernels with irregular reuse patterns is not explored.
- Automatic tuning for W and C parameters: The choice of window height W and chunk size C is empirical; an analytical model or auto-tuner using hardware counters (e.g., L2/LLC hit rates, latency) could generalize the scheduling across shapes and system states.
- Robustness to runtime variability: Cache-aware scheduling assumes round-robin XCD assignment; sensitivity to driver/runtime changes, multi-tenant interference, and concurrent kernel execution is not analyzed.
- End-to-end model impact: Benchmarks report TFLOPs/s and bandwidth, but there is no end-to-end training/inference evaluation (e.g., tokens/sec, time-to-train, energy efficiency) for full models (LLMs with GQA/MHA), making practical impact uncertain.
- Numerical stability and accuracy: FP8/MXFP formats are benchmarked for speed, but there is no analysis of numerical accuracy, scaling strategies, accumulation precision, or training convergence for mixed precision pipelines on AMD.
- Wider workload coverage: Key AI workloads such as convolution, MoE expert routing/dispatch, sparse/structured kernels, batched GEMM variants, KV cache management, prefix-decoding, and comms overlap (RCCL) are not covered; the generality of HK across these remains open.
- Interoperability with frameworks: Integration details for PyTorch (autograd, graph capture, stream semantics, tensor layout compatibility), RCCL, and ROCm libraries are not specified; friction points and required APIs are unclear.
- Performance counter instrumentation: The cache cost model relies on L2/LLC hit rates; more granular stall analysis (e.g., MFMA issue, LDS contention, memory pipeline occupancy) and fine-grained counters could refine tuning and attribution of bottlenecks.
- Fairness and reproducibility of baselines: Some baselines (e.g., Mojo nightly) and ROCm 7.0 preview docker suggest volatile environments; reproducibility across software versions, tuning parity, and fair parameterization (especially for assembly libraries) need tightening.
- Energy and thermal constraints: No measurements of power, energy per operation, or thermal throttling behavior are provided; optimization might shift if energy efficiency is targeted.
- Multi-GPU/distributed considerations: How chiplet-aware scheduling interacts with multi-GPU training, pipeline/tensor parallelism, and communication-compute overlap is unexplored.
- Portability of LDS and MFMA assumptions: The chosen swizzles and schedules rely on specific LDS bank widths and MFMA instruction sets; future ISA changes (e.g., new MFMA shapes, altered LDS banking) may break assumptions without an abstraction layer.
- Handling dynamic shapes and sequence lengths: Real workloads vary sequence length and head dimensions; adaptive tiling, scheduling, and cache-aware ordering for dynamic shapes are not addressed.
- Tooling for developers: Debugging, profiling, and ergonomics for pinned registers, LDS swizzles, and schedule design are not described; developer-facing tooling (visualizers, static analyzers, correctness tests) would help adoption.
- Interaction with future hardware features: If AMD introduces features analogous to NVIDIA’s mbarriers, WGMMA-like shared-memory operands, or register reallocation, how HK’s schedules would evolve is an open design question.
- Release completeness: Appendices and code listings referenced for kernels are incomplete in the text; ensuring all algorithms (phase solver, swizzles, grid schedulers) are fully documented and open-sourced would aid reproduction and extension.
Practical Applications
Immediate Applications
Based on the paper’s results and released code, the following applications can be deployed now on AMD CDNA3/CDNA4 hardware (e.g., MI325X, MI355X) with ROCm 7.0.
- High-performance GEMM and attention kernels for AMD clusters
- Sector: software/cloud, AI infrastructure, finance (risk analytics), energy (grid simulations), healthcare (imaging, genomics), academia (HPC/ML research)
- What: Drop-in HipKittens kernels for BF16 and FP8 GEMM, MHA/GQA attention forward/backward, RoPE, and LayerNorm that match or beat AMD’s assembly baselines and outperform compiler-generated kernels (e.g., Triton) by up to 3×.
- Tools/products/workflows:
HipKittenslibrary bindings; ROCm/PyTorch custom ops; model training/inference pipelines that swap in HK kernels for matmul and attention blocks. - Dependencies/assumptions: ROCm 7.0, AMD Instinct GPUs (CDNA3/CDNA4), problem shapes aligned with HK tile constraints, Python bindings except where FP8 support is still experimental in PyTorch ROCm.
- Cost and energy efficiency improvements for AI training and inference on AMD
- Sector: cloud providers, MLOps, sustainability/green IT
- What: Use HK’s 8-wave ping-pong schedule and chiplet-aware grid ordering to raise arithmetic intensity, increase L2/LLC hit rates, and reduce HBM traffic—improving throughput (TFLOPS) and energy efficiency at data-center scale.
- Tools/products/workflows: HK scheduling templates integrated into training loops; ROCm profiler-guided tuning using
rocprofv3counters (LDS bank conflicts, L2/LLC hit rates); automated kernel selection per workload shape. - Dependencies/assumptions: Accurate cache behavior modeling on target GPUs; cluster monitoring to verify energy savings; availability of ROCm performance counters.
- Diversified compute procurement and deployment beyond CUDA-centric stacks
- Sector: industry policy, government labs, cloud marketplaces
- What: Immediate ability to deploy competitive AMD GPU SKUs for large-scale AI workloads using HK kernels, reducing CUDA lock-in (“moat”) and enabling multi-vendor capacity scaling.
- Tools/products/workflows: AMD-backed model training services; HIP/ROCm-based AI stacks; internal procurement guidelines highlighting HK availability and performance.
- Dependencies/assumptions: Organizational willingness to diversify; qualification of AMD stacks in existing CI/CD; availability of required model architectures and data loaders on ROCm.
- Compiler and DSL engineering improvements using HK’s primitives
- Sector: software tooling, compilers, MLIR/LLVM ecosystem
- What: Incorporate HK’s pinned-register control, MFMA-sized tiles, bank-conflict-free swizzles, and 8-wave/4-wave schedules into HIPCC/Triton/CuTe/Gluon backends to close performance gaps on AMD.
- Tools/products/workflows: New MLIR passes for register pinning and phase-aware swizzling; Triton/TileLang schedules that mimic HK’s 8-wave ping-pong; ROCm library updates.
- Dependencies/assumptions: Compiler teams’ bandwidth; alignment with AMD ISA constraints (e.g., AGPR usage policies).
- Teaching and curriculum for modern GPU kernel design
- Sector: education, academia (systems/architecture/ML)
- What: Use HK to teach tile-based programming, register scheduling, shared memory banking, and chiplet-aware cache strategies with hands-on labs on AMD GPUs.
- Tools/products/workflows: Course modules and lab notebooks showing MFMA tiles, LDS swizzles, wave scheduling; reproducible performance microbenchmarks with
rocprofv3. - Dependencies/assumptions: Access to AMD GPU nodes; instructor familiarity with HIP/C++ and ROCm.
- Performance profiling and debugging workflows for cache and shared memory
- Sector: software performance engineering
- What: Adopt HK’s diagnostics to detect and fix LDS bank conflicts and poor L2/LLC reuse in production kernels.
- Tools/products/workflows: Profiling harnesses capturing
SQ_LDS_BANK_CONFLICT,SQ_INSTS_LDS, L2/LLC hit rates; automated remediation via HK’s swizzles and grid rescheduling. - Dependencies/assumptions: Stable ROCm perf APIs; developer access to kernel code for remediation; problem shapes that benefit from cache-aware remapping.
- Accelerated domain workloads through matmul/attention substitutions
- Sector: healthcare (foundation models for imaging/text), finance (time-series transformers), energy (forecasting, HPC simulations), scientific computing
- What: Replace bottleneck kernels in domain models (matmul, attention, norms, RoPE) with HK versions to reduce training/inference time.
- Tools/products/workflows: Pytorch-ROCm custom ops/FX graph passes to rewrite critical nodes to HK; validation harnesses to ensure numerics match.
- Dependencies/assumptions: Model graph is compatible with HK kernel interfaces; FP formats (BF16/FP8) acceptable for accuracy targets; numerical equivalence verified.
- Multi-tenant runtime plugins that reduce cross-chiplet cache thrash
- Sector: cloud runtime, job schedulers
- What: Apply HK’s XCD swizzle (window/chunk scheduling) to reorder block launches for better cache locality across tenants, especially in shared clusters.
- Tools/products/workflows: HIP runtime plugin or ROCm scheduler hook that remaps
(b.x,b.y)per Algorithm 1; per-job tuning of windowWand chunkC. - Dependencies/assumptions: Ability to intercept and remap grid launches; minimal interference with framework-level launch policies; cache topology matches MI325X/MI355X assumptions.
Long-Term Applications
These depend on broader adoption, further research, or hardware/compiler evolution.
- A unified, vendor-agnostic tile-based kernel DSL
- Sector: software tooling, cross-vendor compute
- What: Converge ThunderKittens (NVIDIA) and HipKittens (AMD) primitives into a single DSL that targets multiple accelerators (NVIDIA, AMD, future architectures).
- Tools/products/workflows: Common tile APIs; auto-selection of vendor-specific swizzles/schedules; shared test suites; cross-vendor autotuners.
- Dependencies/assumptions: Vendor ISA harmonization or abstraction layers; mature compiler backends for MFMA/WGMMA equivalents; sustained open-source collaboration.
- AI-assisted kernel generation targeting HK primitives
- Sector: AI tooling for systems
- What: RL/agentic systems that learn to assemble HK tiles and schedules (8-wave/4-wave) to produce near-assembly performance, avoiding reward hacking by grounding in perf counters.
- Tools/products/workflows: Training environments with
rocprofv3metrics; reward models for cache reuse and bank conflicts; generative coders constrained by HK API. - Dependencies/assumptions: Stable perf measurements; robust anti-reward-hacking designs; datasets of high-quality AMD kernels.
- Compiler evolution: full register control and AGPR-friendly pipelines
- Sector: compilers/LLVM/MLIR
- What: HIPCC and MLIR passes that support using AGPRs as inputs to matrix instructions and expose programmer hints to steer register lifetimes—so developers don’t need to bypass compilers.
- Tools/products/workflows: New IR intrinsics; register-pinning metadata; matrix-phase-aware memory ops.
- Dependencies/assumptions: ISA/legal constraints; vendor roadmap alignment; backward compatibility.
- Generalizing chiplet-aware scheduling to more workloads and hardware
- Sector: HPC, AI systems
- What: Extend XCD swizzle to convolutions, MoE routing, sparse GEMM, pipeline-parallel training, and cross-node NUMA-aware placement; port to other chiplet designs (e.g., future NVIDIA/Intel/accelerators).
- Tools/products/workflows: Cache-aware launch planners; workload-shape-specific heuristics; cluster schedulers that couple kernel-level cache reuse with node-level NUMA.
- Dependencies/assumptions: Detailed cache topology per vendor; APIs to control launch order; accurate cost models across ops.
- End-to-end ROCm integration and standardized kernel packs
- Sector: ML frameworks, package ecosystems
- What: Curated “HK Kernel Packs” that frameworks (PyTorch, JAX-on-ROCm) can select at runtime based on shape/dtype, with safe fallbacks to compilers.
- Tools/products/workflows: Runtime kernel registries; graph rewrite passes; CI for numerical fidelity and perf regression.
- Dependencies/assumptions: Framework buy-in; robust ABI stability; FP8 support standardized.
- Sector-specific AI platforms on AMD
- Sector: healthcare, finance, energy
- What: Full-stack AMD-optimized platforms (data loaders, training loops, inference servers) for regulated sectors where cost/performance matters (e.g., medical imaging foundation models, risk engines, grid forecasting).
- Tools/products/workflows: Domain libraries pre-wired to HK kernels; compliance-ready deployment blueprints; perf+accuracy validation suites.
- Dependencies/assumptions: Sector validation, accuracy/tolerance for BF16/FP8; long-term ROCm support; security/compliance certifications.
- Real-time and edge robotics on AMD (as AMD’s GPU portfolio broadens)
- Sector: robotics/autonomy
- What: Apply HK-style scheduling and bank-conflict mitigation to time-sensitive kernels (attention, sensor fusion) as AMD releases edge-friendly accelerators.
- Tools/products/workflows: Embedded runtime variants; real-time scheduling heuristics; minimal-latency memory layouts.
- Dependencies/assumptions: Availability of suitable AMD edge GPUs; deterministic kernel timing; robotics framework integration.
- Sustainability and policy: compute diversification and carbon-aware scheduling
- Sector: public policy, sustainability
- What: Use HK-enabled AMD performance to support policies encouraging multi-vendor compute procurement and carbon-aware workload placement (e.g., favoring cache-efficient kernels to reduce power).
- Tools/products/workflows: Procurement guidelines; carbon accounting tied to perf counters; scheduling policies privileging high arithmetic intensity.
- Dependencies/assumptions: Access to energy telemetry; policy coordination across agencies; standardized metrics.
- Curriculum standardization for cross-accelerator GPU programming
- Sector: education
- What: Establish a cross-vendor course track where students learn unified tile abstractions, cache models, and scheduling patterns applicable to AMD/NVIDIA/others.
- Tools/products/workflows: Shared labs, vendor-neutral DSLs, performance challenges.
- Dependencies/assumptions: Ongoing vendor support and academic partnerships.
- Safety and reliability engineering for high-performance kernels
- Sector: software assurance
- What: Formalize testing harnesses and verification for HK-style kernels (numerical stability, overflow handling in FP8, edge-case shapes) used in critical systems.
- Tools/products/workflows: Property-based tests; perf/accuracy Pareto dashboards; fallback/rollback mechanisms.
- Dependencies/assumptions: Sector requirements (medical/financial standards); tooling maturity for low-level kernel verification.
Cross-cutting assumptions and dependencies
- Hardware: AMD CDNA3/CDNA4 availability; future architectures may change register, cache, and shared memory behaviors.
- Software stack: ROCm 7.0 maturity; PyTorch ROCm feature parity (e.g., stable FP8); HIPCC compiler capabilities.
- Workload shapes: HK tile constraints require M/N/K multiples of MFMA shapes; attention head dims and sequence lengths affect schedule choice (8-wave vs 4-wave).
- Portability: While tiles generalize, layouts and phases are vendor-specific; chiplet-aware scheduling must be retuned per hardware generation.
- Expertise: Effective use of HK benefits from developers with HIP/C++ and performance profiling experience; broader adoption may need abstractions in higher-level frameworks.
Glossary
- AGPRs (Accumulator General-Purpose Registers): A class of AMD registers used to hold accumulator values, distinct from vector GPRs. "HIPCC prevents the HIP developer from using certain types of registers (AGPRs) as input operands to matrix instructions."
- arithmetic intensity: The ratio of computation to memory traffic; higher values generally yield better performance. "AMD's static register allocation means that producer waves consume registers without contributing to computation, which limits the output tile size that gets computed per thread block and thus the kernel's arithmetic intensity."
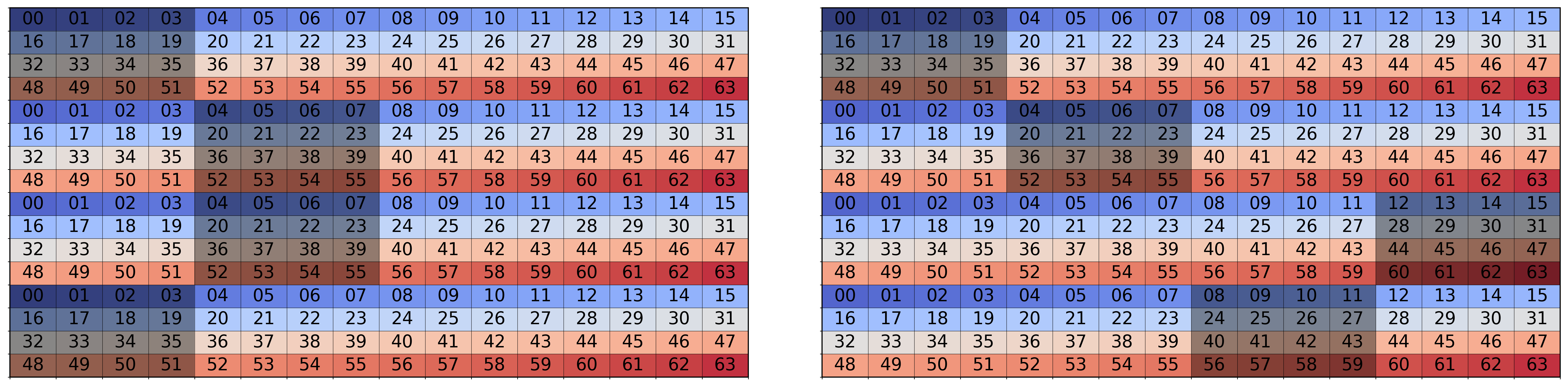
- bank conflicts: Performance-degrading events when multiple threads access the same shared memory bank simultaneously. "On the left is an unswizzled layout suffering from 2-way bank conflicts."
- BF16 (bfloat16): A 16-bit floating-point format with 8-bit exponent and 7-bit mantissa, commonly used in AI workloads. "On the MI355X, wave specialization achieves just 80\% of peak BF16 GEMM performance (Tab.~\ref{tab:producer_consumer_ablations})."
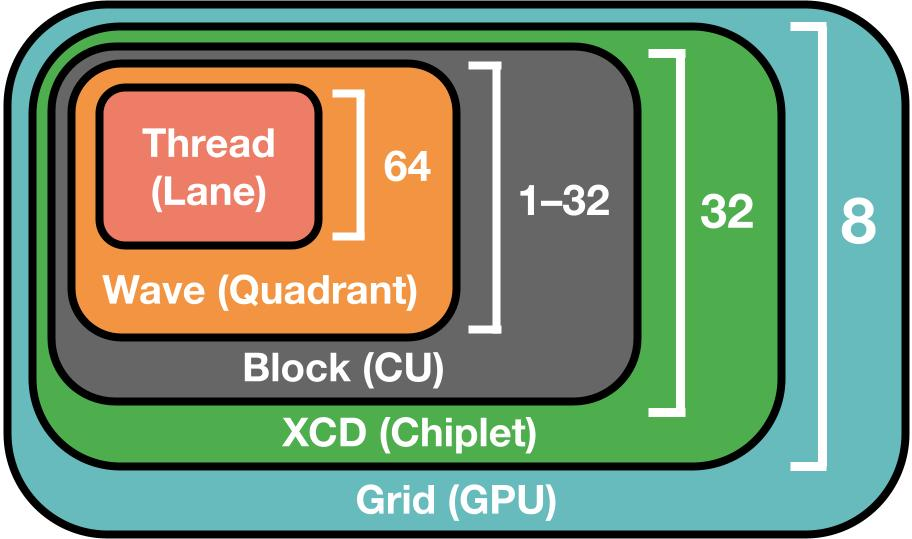
- chiplet architectures: GPU designs composed of multiple smaller dies (chiplets) interconnected, affecting cache hierarchy and scheduling. "Chiplet architectures are becoming the dominant path to GPU scaling---NVIDIA Blackwell uses 2 chips, AMD MI355X uses 8---but existing frameworks ignore their hierarchical cache structures, leaving performance untapped."
- CUTLASS: NVIDIA’s CUDA Templates for Linear Algebra Subroutines and Solvers, a performance-oriented CUDA library for GEMM and related kernels. "using low level CUDA/CUTLASS, it took two years between the H100 GPU's release and the release of peak performance open-source attention kernels~\cite{dao2024flashattention3}."
- ds_read_b128: An AMD shared-memory load instruction that reads 128 bits per access with specific banking behavior. "ds_read_b128 accesses shared memory through 64 banks, each 32-bits wide, and correspond the individual cells and numbers in the figure."
- GEMM (General Matrix Multiply): A core linear algebra operation computing D = A·B + C. "In a GEMM kernel (), each thread block computes a distinct tile of the output matrix ."
- HBM (High Bandwidth Memory): High-speed external memory used by GPUs, sitting below LLC in the hierarchy. "All CUs share a large, slow global memory (HBM) and a last level cache (LLC) sits between L2 and HBM."
- HIP (Heterogeneous-Compute Interface for Portability): AMD’s C++ GPU programming model analogous to CUDA. "CUDA / HIP C++ gets compiled (via NVCC, HIPCC) to assembly, and the compiler may introduce its own instruction reordering and register lifetime tracking."
- HIPCC: The HIP C++ compiler for AMD GPUs. "However, while the hardware does support using AGPRs as input to matrix core instructions, HIPCC does not."
- L2 cache: A per-chiplet (per-XCD) on-GPU cache level offering higher bandwidth and lower latency than LLC/HBM. "Each XCD shares a non-programmable 4MB L2 cache."
- LLC (Last-Level Cache): The cache level shared across chiplets, sitting between L2 and HBM. "All CUs share a large, slow global memory (HBM) and a last level cache (LLC) sits between L2 and HBM."
- LLVM: A compiler infrastructure used by GPU compilers and DSLs; supports hints to guide code generation. "LLVM accepts compiler hints, which let the developer guide the compiler's behavior."
- matrix cores: Specialized GPU execution units for matrix operations (tensor/matrix math). "Threads execute instructions on physical execution units (ALU, FMA, matrix cores), which are specialized for different types of compute."
- matrix fused multiply add (MFMA): AMD’s matrix multiply-accumulate instruction family for high-throughput matrix ops. "A SIMD's compute wave executes matrix fused multiply add (MFMA) instructions while its paired memory wave prefetches the next data, hiding memory effectively."
- mbarriers: NVIDIA hardware synchronization primitives used in advanced GPU kernel pipelines. "NVIDIA kernels implement wave specialization using dedicated memory access hardware (tma), asynchronous matrix multiplies which accept operands directly from shared or tensor memory (wgmma, tcgnen05), deep pipelines enabled by large shared memory per processor (B200 has 40\% larger SRAM than AMD MI355X per processor), register reallocation (where the register-efficiency of TMA lets producers give their registers to consumers), and hardware synchronization primitives (mbarriers)."
- occupancy: The degree to which GPU execution resources are kept busy by active threads/waves. "A few basic kernel patterns help developers achieve high occupancy, or schedule workers (waves on AMD, warps on NVIDIA) onto the different hardware execution units."
- pinned registers: Explicitly assigned physical registers that bypass compiler allocation for precise control. "The developer pins the registers belonging to each tile, rather than letting HIPCC manage the registers."
- producer-consumer (pattern): A scheduling pattern where some waves handle memory (producers) while others compute (consumers). "Modern NVIDIA kernels have consolidated around wave specialization (producer-consumer) scheduling patterns~\cite{dao2024flashattention3, spector2025tk, spector2025look, 25-comet, wang2025tilelang}."
- register reallocation: A feature where register resources are dynamically reassigned across waves to improve efficiency. "register reallocation (where the register-efficiency of TMA lets producers give their registers to consumers)"
- ROCm: AMD’s open software stack for GPU computing. "All kernels are benchmarked in AMD's recently released beta Docker using ROCm 7.0 (\url{rocm/7.0-preview:rocm7.0_preview_pytorch_training_mi35x_beta})."
- shared memory (LDS on AMD): Programmable on-chip memory shared among threads/waves in a block with banked access constraints. "Each CU has an L1 cache and shared memory that can be accessed by multiple waves in the same thread block."
- SIMD (Single Instruction, Multiple Data): Execution units processing multiple data elements with one instruction; AMD schedules waves per SIMD. "CUs organize their hardware resources in 4 'single instruction, multiple data' (SIMD) units."
- swizzling (tile/layout swizzle): A permuted memory layout designed to avoid bank conflicts and optimize access patterns. "{HK} introduces a general 8-wave ping-pong schedule to overlap compute and memory, programmer controlled register allocation, and efficient shared memory and chiplet-aware swizzling algorithms to enable a suite of high performance AMD AI kernels."
- TMA (Tensor Memory Accelerator): NVIDIA hardware for asynchronous memory movement that can bypass registers. "Like TMA, these loads bypass the register file."
- Triton: A high-level GPU compiler for writing custom kernels; easier to use but may lag peak performance/features. "Compilers like Triton~\cite{triton} are simpler to use, but sacrifice performance and struggle to quickly support new hardware features~\cite{spector2025tk, triton2025gluon}."
- VGPRs (Vector General-Purpose Registers): AMD vector registers used for general computation and as MFMA operands. "For kernels with a single SIMD per wave, the hardware splits the registers into 256 vector general-purpose registers (VGPRs) and 256 accumulator registers (AGPRs)."
- v_accvgpr_read: An AMD instruction to move data from accumulator registers to vector registers. "For workloads that involve both matrix and vector operations (e.g., attention backwards), kernels compiled via HIPCC would need to generate redundant \verb|v_accvgpr_read| instructions that move data from AGPRs to VGPRs prior to issuing matrix instructions."
- wave: A group of 64 threads that execute in lockstep on a SIMD on AMD GPUs. "waves, groups of 64 threads, execute in lockstep on individual SIMDs"
- wave specialization: A scheduling strategy assigning distinct roles to waves (memory vs compute) to build deep pipelines. "The wave specialization pattern dominates NVIDIA kernels and DSLs; producer waves handle memory operations while consumers execute bulk compute operations over large tiles."
- XCD (Accelerator Complex Die): A chiplet containing a cluster of compute units that share an L2 cache. "AMD MI355X GPUs contain 256 CUs organized into 8 accelerator complex dies (XCDs) of 32 CUs in a chiplet layout."
Collections
Sign up for free to add this paper to one or more collections.