- The paper presents MoSS, a framework that decouples sensory streams to integrate tactile and torque feedback without causing modality interference.
- The methodology employs parallel Transformer-based streams and cross-modal self-attention layers, achieving an average success rate gain of up to 28.2% over vision-only baselines.
- The framework’s two-stage training and future feedback prediction enable robust performance in contact-rich tasks, demonstrating scalability and practical deployment.
Modular Sensory Stream Integration for Physical Feedback in Vision-Language-Action Models
Motivation and Problem Statement
Vision-Language-Action models (VLAs) have achieved substantial progress in generalist robot policy learning by leveraging large-scale pretrained Vision-LLMs (VLMs); however, these approaches traditionally rely exclusively on visual and linguistic inputs. This intrinsic limitation hinders their capacity to perform contact-rich, precision manipulation tasks that demand real-time incorporation of physical feedback—such as tactile and torque signals—crucial for dexterous behaviors. Prior approaches typically focus on a single modality, and naively extending VLA architectures to handle multiple heterogeneous physical signals fails to yield synergistic effects and often degrades performance due to modality interference and alignment issues.
Empirical analysis demonstrates marked degradation in performance by existing VLA augmentation approaches when increasing the diversity of physical sensory signals, underscoring the need for a scalable framework capable of integrating heterogeneous modalities without corrupting action priors.
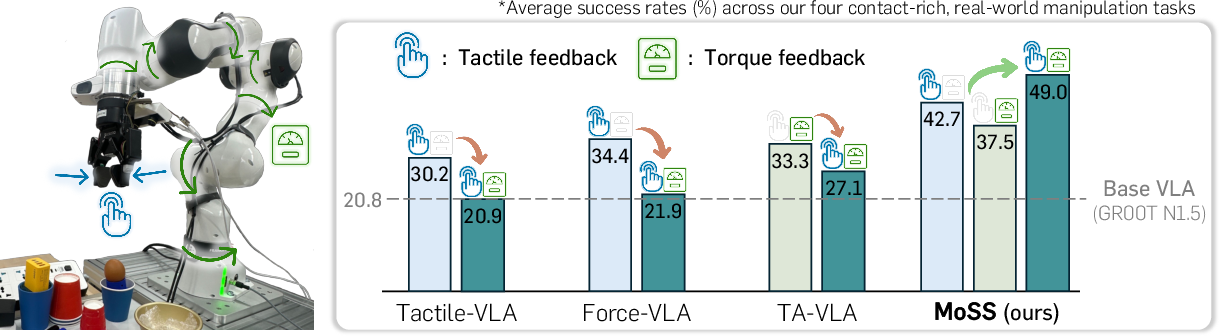
Figure 1: Comparative analysis of success rates as VLAs are augmented with increasingly diverse physical sensory modalities; existing approaches suffer degraded performance under multiple signals, in contrast to MoSS's scalable improvement.
Modular Sensory Stream Architecture (MoSS)
The Modular Sensory Stream (MoSS) framework is introduced to robustly augment pretrained VLA action experts with physical feedback. MoSS extends the Transformer-based action module with decoupled modality streams, each dedicated to a physical signal (e.g., tactile, torque), operating in parallel with the original action stream. Cross-modal information exchange is realized through joint cross-modal self-attention layers. This design enables mutual modulation of actions and sensory feedback (e.g., dynamically adjusting grasp force based on tactile contact or recognizing insertion misalignment via torque cues), while preventing destructive gradient interference by keeping stream parameters independent except for attention.
A two-stage training protocol is employed: Stage 1 freezes pretrained parameters and trains only the new sensory streams for task-aligned representation learning; Stage 2 jointly fine-tunes all streams. An auxiliary future feedback prediction objective further encourages anticipation of physical interaction dynamics, improving signal utilization during action generation.
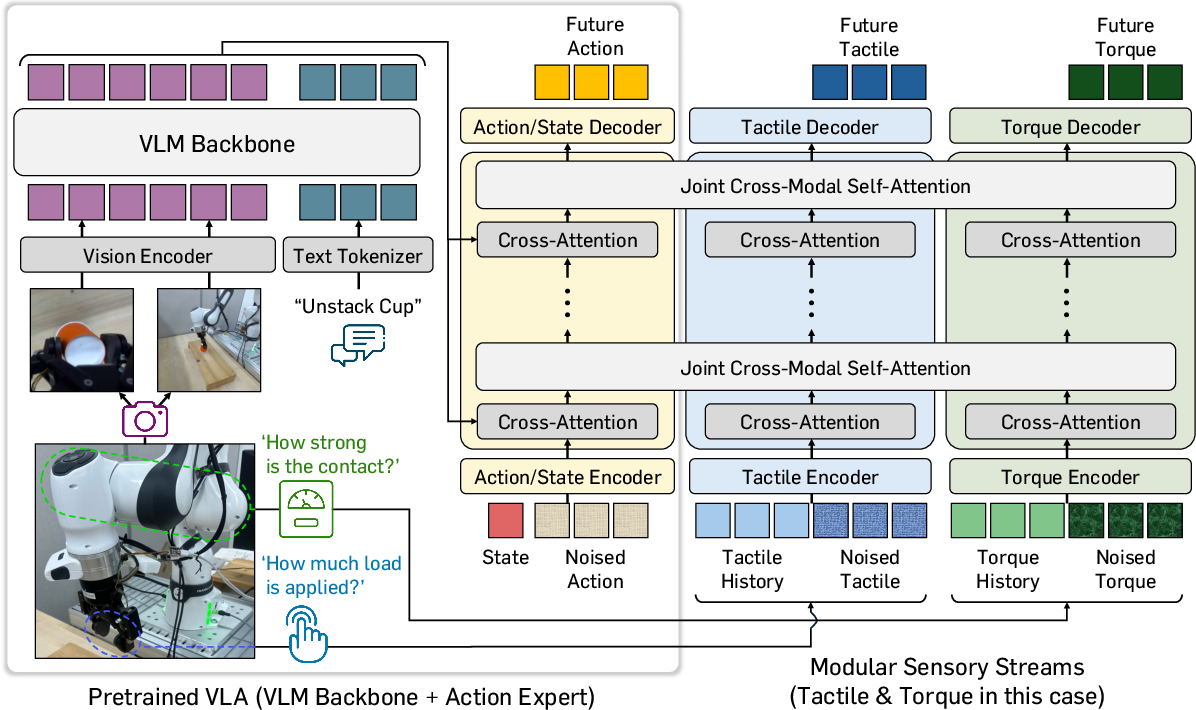
Figure 2: Schematic of MoSS architecture, showing parallel processing of tactile and torque streams with joint self-attention, two-stage training, and future feedback prediction.
A suite of contact-rich manipulation tasks was constructed to systematically assess the necessity and effectiveness of physical feedback, including:
- Unstack Cup: Requires force regulation to lift only the top cup from a stack.
- PnP Egg: Demands delicate handling to avoid breaking a fragile egg.
- Board Erase: Necessitates consistent contact maintenance for effective erasing.
- Plug Insertion: Involves alignment and insertion under occlusion, relying on torque for contact awareness.
These tasks induce ambiguity under vision alone, enforcing the need for multimodal feedback.
The hardware platform consists of a Franka Research 3 robot arm with Robotiq 2F-85 gripper and dual AnySkin tactile sensors on the fingers, alongside a wrist-mounted stereo camera, providing synchronized visual, tactile, and proprioceptive signals.
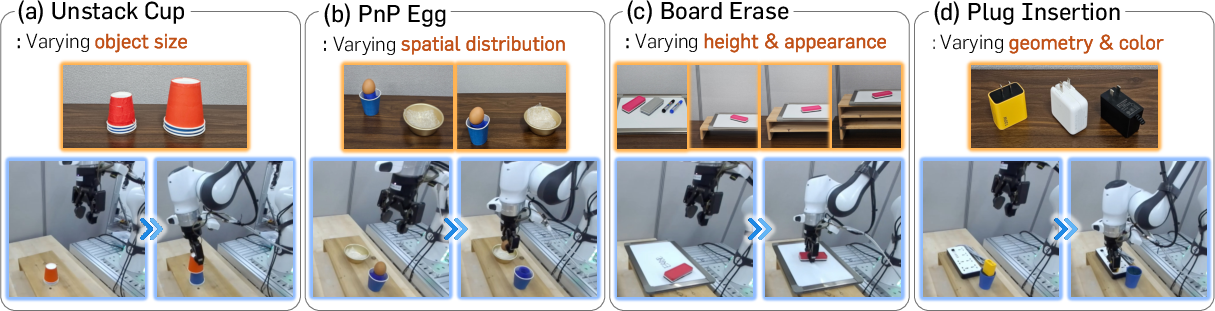
Figure 3: Overview of evaluation tasks with variations in object parameters, requiring policies to leverage physical signals outside vision.
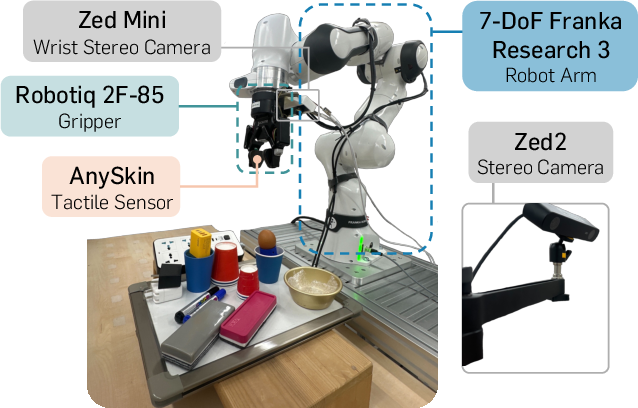
Figure 4: Hardware platform supporting synchronized visual, tactile, and torque sensing for manipulation.
Results and Analysis
Quantitative Gains
MoSS demonstrates consistent and cumulative performance improvements across all base VLA models and tasks. For GR00T N1.5 and π0, MoSS achieves average success rate gains of 28.2% and 19.8%, respectively, over vision-only baselines. Critically, MoSS outperforms modality-augmented baselines even when integrating multiple physical signals, achieving 49.0% and 45.9% averaged success rates under combined tactile + torque input conditions, with additive gains as more modalities are provided.
Qualitative Task Completion
MoSS-enabled VLAs successfully regulate grasping and contact forces, maintain pressure during erasing, and resolve occluded plug insertion scenarios, while vision-only models or single-modality augmentations frequently fail on these metrics.
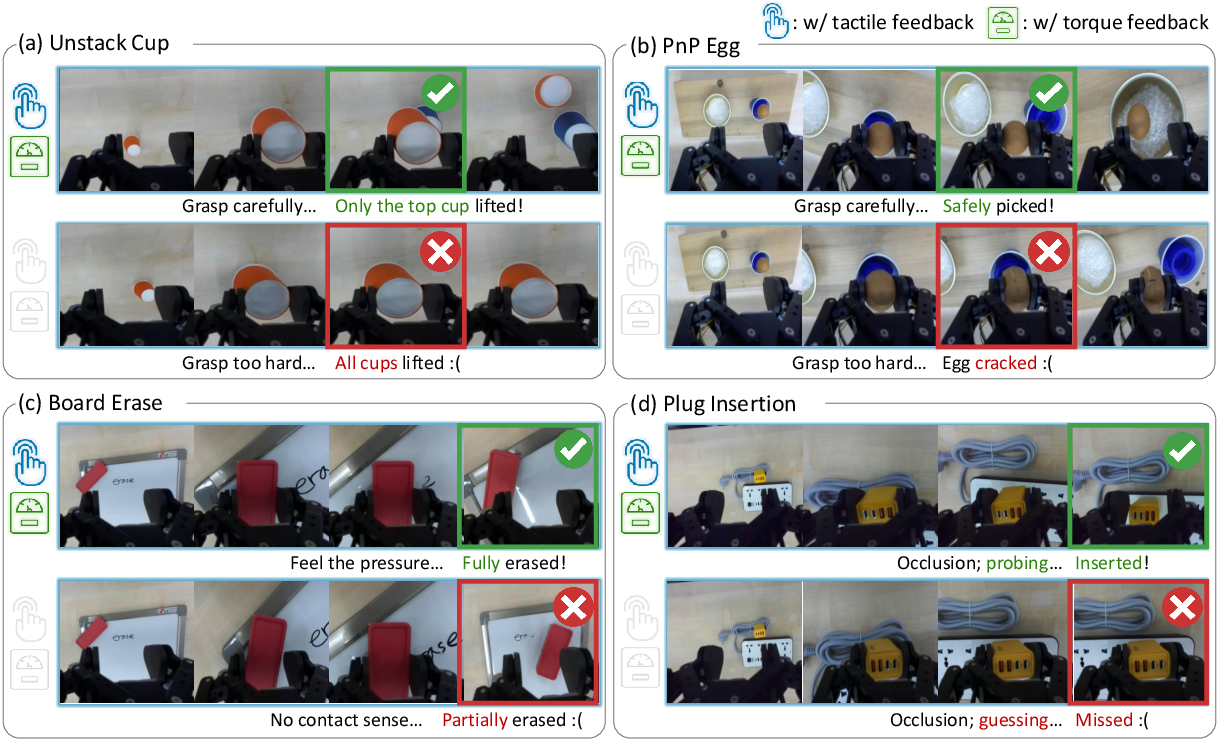
Figure 5: Rollout examples on real tasks, illustrating MoSS's capacity to modulate force, maintain contact, and probe occluded geometry versus performance limitations of GR00T N1.5 w/o physical feedback.
Cross-Modal Attention and Signal Prediction
Attention visualization shows that action tokens attend strongly to tactile and torque modalities at moments requiring contact-intensive control, confirming cross-modal dynamic utilization.
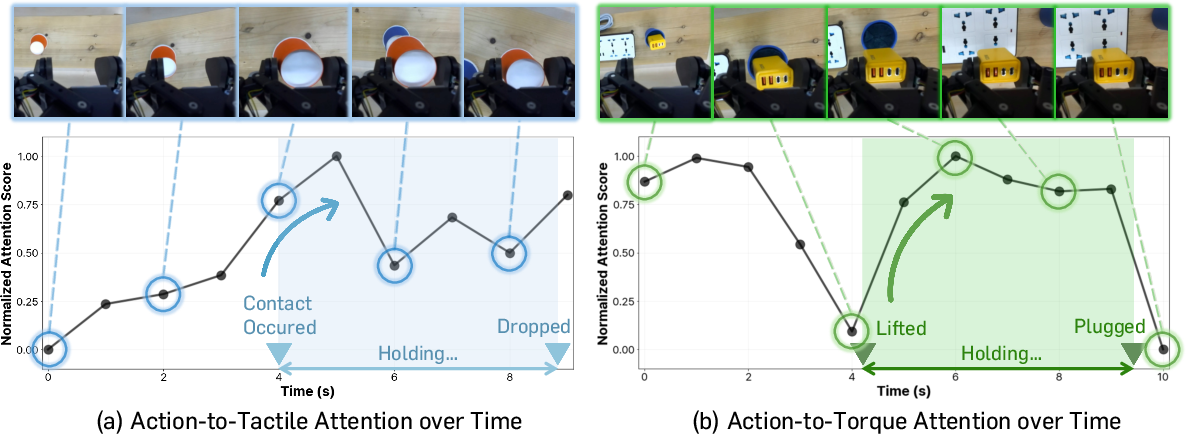
Figure 6: Standardized attention scores between action and physical streams, highlighting moments of high cross-modal correlation during contact and insertion phases.
MoSS accurately predicts changes in physical signals, as evidenced by strong temporal alignment between predicted and actual tactile/torque values during manipulation.
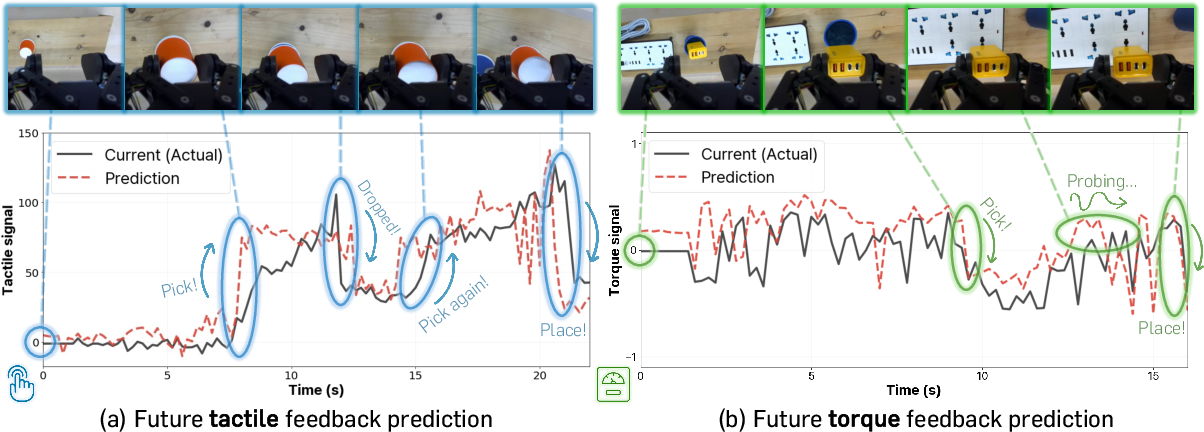
Figure 7: Predicted tactile and torque signals by MoSS during task execution, aligning closely with actual measurement spikes at critical moments.
Ablation and Efficiency
Ablation experiments reveal that decoupling streams, two-stage training, and future prediction objectives are each critical, with separate modality streams yielding +20.9% improvement, two-stage training +16.7%, and prediction objective +8.4% on representative tasks.
Inference latency is only modestly affected, with a 1.11× overhead when integrating both tactile and torque signals, demonstrating practical scalability.
Implications and Prospects
The theoretical implication is the demonstration that modular cross-modal stream architectures with joint self-attention can scalably integrate heterogeneous physical signals, overcoming modality interference and alignment challenges endemic to multimodal policy learning. Practically, MoSS enables generalist robot policies capable of leveraging the full spectrum of available sensing modalities, facilitating robust execution of diverse, contact-rich tasks.
MoSS's flexible architecture can be extended to any combination of physical signals, offering adaptability for new sensors, embodiments, or tasks. Anticipated developments include automated modality stream configuration, hierarchical feedback fusion, and hardware-agnostic learning protocols. This approach will likely catalyze robust, generalizable manipulation models capable of real-world deployment in variable, unstructured environments.
Conclusion
MoSS defines a scalable modular framework for adapting Vision-Language-Action models to leverage multiple physical feedback modalities via decoupled sensory streams and cross-modal self-attention. Empirical results conclusively illustrate its superior performance and cumulative gains as more signals are incorporated, with only marginal inference overhead. These insights establish modular sensory stream architectures as an essential paradigm for physically-grounded AI agents.

