- The paper introduces a multimodal action-conditioned video generation framework that integrates proprioception, kinesthesia, EMG, and haptic signals for precise control.
- It employs dedicated expert encoders with self-supervised reconstruction and channel-wise cross-attention to align diverse sensory modalities in a shared latent space.
- Experimental results demonstrate a 36% improvement in video prediction accuracy and 16% boost in temporal consistency over text-based baselines, underscoring its effectiveness for robotic simulations.
MultiModal Action Conditioned Video Generation: Fine-Grained Control of Generative Video Simulators via Multisensory Action Signals
Introduction and Motivation
The paper addresses the limitations of current video generative models in simulating fine-grained, causally accurate world dynamics, particularly for embodied agents such as household robots. Existing text-conditioned video models lack the temporal and physical specificity required for tasks involving dexterous manipulation or rapid, context-sensitive responses. The authors propose a framework for action-conditioned video generation that leverages a rich set of interoceptive signals—proprioception, kinesthesia, force haptics, and muscle activation—enabling precise, temporally resolved control over simulated visual outcomes.

Figure 1: Overview of the proposed pipeline for multisensory action-conditioned video generation, highlighting the integration of diverse interoceptive signals for fine-grained control.
Multimodal Action Representation and Feature Learning
The core technical contribution is a multimodal feature extraction paradigm that aligns heterogeneous sensory modalities into a shared latent space while preserving modality-specific information. Each modality (e.g., hand pose, body pose, muscle EMG, haptic force) is encoded via a dedicated expert head, with self-supervised reconstruction losses ensuring meaningful representations. To synchronize these features, the authors introduce channel-wise cross-attention between the aggregated context video embedding and each modality-specific feature, promoting implicit alignment without erasing complementary information.
The fusion of modality-specific features is performed using a softmax-weighted aggregation, ensuring permutation invariance and robustness to missing modalities. This design avoids the pitfalls of contrastive alignment (as in ImageBind or LanguageBind), which can suppress critical modality-specific cues necessary for generative control.
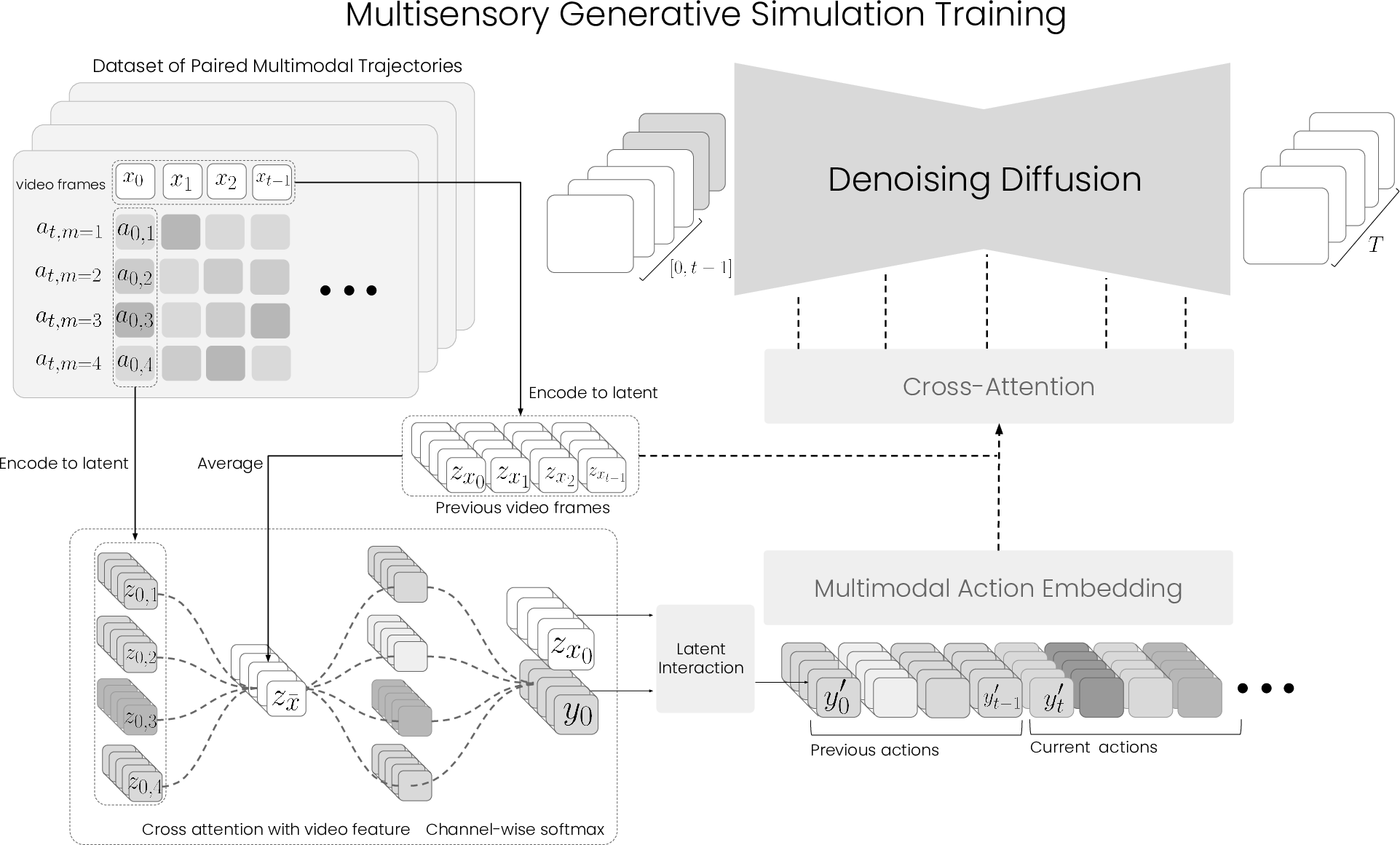
Figure 2: Detailed architecture of the multimodal feature extraction and fusion pipeline, including expert encoders, cross-attention, and softmax aggregation.
Latent Interaction Regularization for Causal Control
To ensure that the learned action representations encode not only the action itself but also its causal effect on the environment, the authors introduce a latent interaction regularization scheme. The action feature is projected to be orthogonal to the context embedding, isolating the component responsible for state change. The norm of this interaction vector is further regularized to match the magnitude of frame-wise visual changes, enforcing a direct correspondence between action intensity and visual outcome.
A relaxed hyperplane interaction is also proposed, allowing for context-dependent deviations from strict orthogonality, which empirically improves generalization and stability.
Conditioning Diffusion-Based Video Generators
The action-conditioned latent is used to modulate a video diffusion model (I2VGen backbone), replacing text prompts with temporally resolved, multimodal action features. The model is trained end-to-end with a composite loss: video denoising diffusion loss, self-supervised reconstruction loss for each modality, and the latent interaction regularization. The conditioning is temporal, enabling frame-specific control, in contrast to static text prompts.
Experimental Evaluation
The framework is evaluated on the ActionSense dataset, which provides synchronized video and multisensory action signals. The model is benchmarked against state-of-the-art text-conditioned video simulators (e.g., UniSim), unimodal action conditioning, and several multimodal feature learning baselines (Mutex, ImageBind, LanguageBind, SignalAgnostic).
Key empirical findings:
- Multisensory action conditioning improves video prediction accuracy by 36% and temporal consistency by 16% over text-based baselines.
- The model outperforms all tested multimodal feature extraction baselines in MSE, PSNR, LPIPS, and FVD metrics.
- Ablation studies show that removing any modality degrades performance, but the model remains robust to missing modalities at test time due to the softmax fusion and implicit feature alignment.
- The approach generalizes to out-of-domain scenarios via fine-tuning and is effective on other datasets (H2O, HoloAssist) with unimodal action signals.

Figure 3: Qualitative comparison of unimodal versus multisensory action conditioning, demonstrating superior temporal coherence and task specificity with the proposed approach.

Figure 4: Comparison with multimodal feature extraction baselines, highlighting the preservation of fine-grained control and avoidance of mode collapse.

Figure 5: Diversity of video trajectories generated from identical context frames, illustrating the model's ability to capture subtle action variations beyond text-based conditioning.
Downstream Applications: Policy Optimization and Planning
The authors demonstrate the utility of the simulator for downstream embodied learning tasks:
- Goal-conditioned policy optimization: Training a policy network with an additional supervision signal from the video simulator improves both action trajectory accuracy and final state matching, despite the high-dimensional action space (2292D).
- Long-term task planning: The simulator can be integrated with high-level planners (e.g., text-to-action diffusion policies) for iterative, vision-based planning and execution, with a vision-LLM used as a subgoal achievement heuristic.
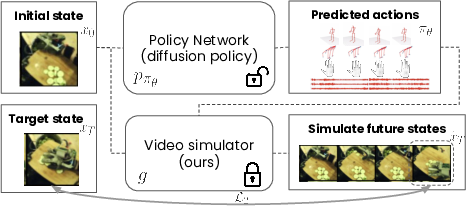
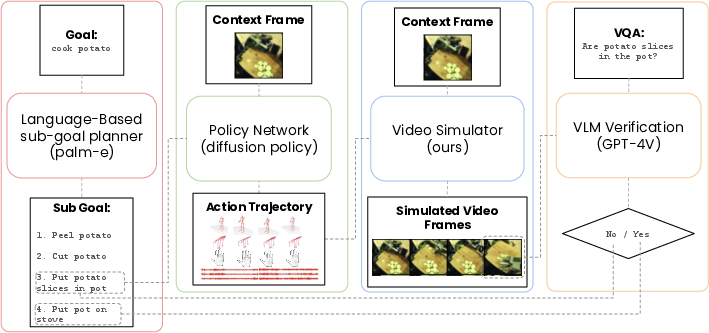
Figure 6: Left: Pipeline for goal-conditioned policy optimization using the action-conditioned simulator. Right: Pipeline for long-term task planning with iterative action rollouts.
Robustness, Generalization, and Limitations
The model exhibits strong robustness to missing modalities at test time, with minimal degradation in prediction quality. Cross-subject and out-of-domain experiments confirm generalizability, and the modular design allows for extension to additional sensory modalities as data becomes available.
Limitations include reliance on high-quality, synchronized multisensory datasets (currently scarce), and the computational cost of high-resolution video diffusion models. The authors note that only the lightweight policy network, not the simulator, needs to be deployed on edge devices in practical robotics applications.
Conclusion
This work establishes a principled framework for fine-grained, causally accurate video simulation conditioned on rich multisensory action signals. By combining modality-specific encoding, implicit alignment, and causal regularization, the approach overcomes the limitations of text-based and unimodal conditioning, enabling new capabilities for embodied AI, policy learning, and planning. The results suggest that future world models for robotics and interactive agents should incorporate temporally resolved, multimodal action signals to achieve robust, precise, and generalizable control. Further research directions include scaling to higher resolutions, integrating additional exteroceptive modalities, and deployment on real robotic platforms.

