- The paper introduces a cross-modal latent filtering approach that integrates vision and tactile data for unsupervised, robust object property inference.
- It employs dynamic Bayesian filtering and structured latent spaces to improve inference speed and accuracy compared to static fusion methods.
- Experimental results with dual-arm robots and synthetic objects demonstrate resilience to noise and effective adaptive cross-modal integration.
Cross-Modal Latent Filtering for Robust Visuo-Tactile Object Perception
Motivation and Biological Foundations
Robust perception in robotics, especially during contact-rich manipulation with non-rigid objects, necessitates the estimation of latent intrinsic (e.g., mass, stiffness, friction) and extrinsic (e.g., shape, size, visual texture) physical properties. Human sensorimotor systems integrate vision and touch through dynamic Bayesian inference, exploiting statistical regularities and context-sensitive cross-modal priors. Existing robotic frameworks predominantly favor static fusion or unidirectional transfer, lacking dynamic uncertainty modeling and causal latent state-space structure. The paper proposes a Cross-Modal Latent Filter (CMLF) inspired by human multi-sensory processing, designed for unsupervised learning of structured latent spaces from raw visuo-tactile streams.
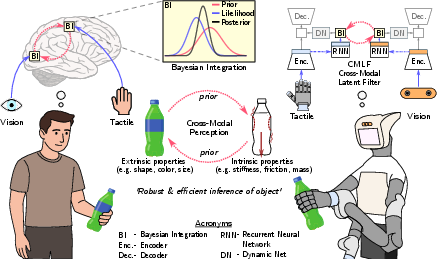
Figure 1: The CMLF framework leverages cross-modal Bayesian integration, enabling bidirectional priors across vision and touch for unsupervised object property estimation.
Framework Architecture: CMLF Design
The CMLF employs a deep state-space model partitioning latent variables into directly and indirectly observable factors, grounded in control theory observability. Separate structured latent spaces for vision and touch, coupled via shared dynamics models, facilitate bidirectional cross-modal priors. Visual representations encode extrinsic properties; tactile representations capture complex intrinsic attributes inaccessible by vision.
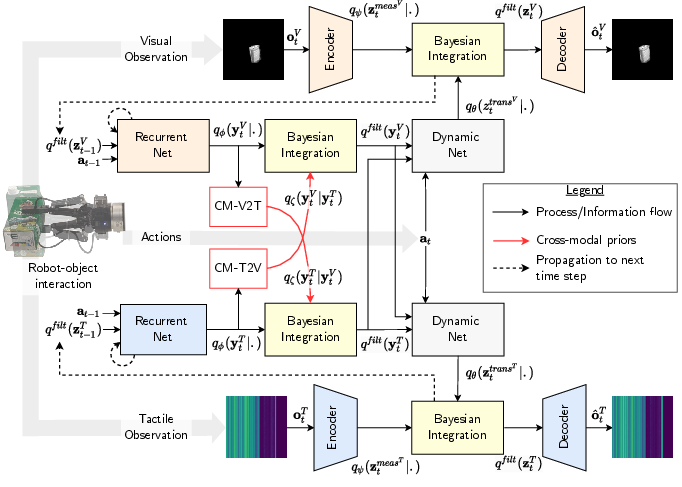
Figure 2: CMLF architecture with bidirectional cross-modal connectivity; cross-modal priors are selectively exchanged for robust causal inference.
Sequential Bayesian filtering, enhanced by hierarchical object-centric priors, supports continuous update of beliefs as new sensor data arrives. Modalities remain autonomous, but prior information from one can dynamically constrain inference in the other via uncertainty-weighted coupling. Cross-modal connections are only activated post stabilization of unimodal latent structures, mirroring developmental neurobiological principles.
Experimental Setup and Dataset
A dual-arm robotic platform, instrumented with stereo vision and tactile sensors, interacts with systematically designed synthetic non-rigid objects. Intrinsic and extrinsic properties are controllable and associated through explicit causal correlations. Data includes rich visuo-tactile interaction streams across 75 objects and multiple interaction primitives (palpation, grasp, lift, rotate), capturing geometric and contact dynamics.
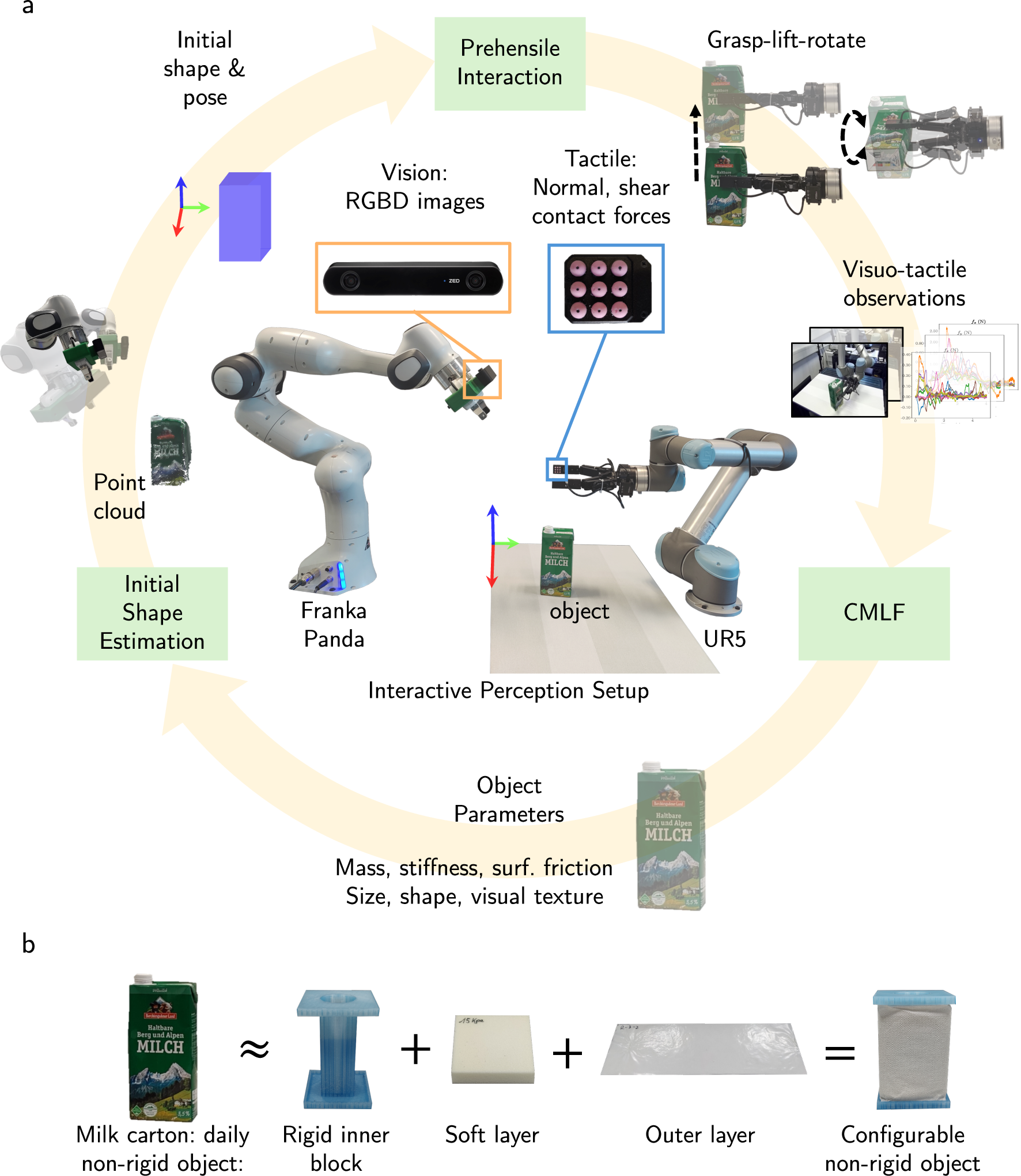
Figure 3: Experimental pipeline for dataset generation and visuo-tactile exploration of configurable objects.
Inference Efficiency and Latent Space Analysis
CMLF was benchmarked against sequential variational autoencoder baselines and ablations. Latent discriminative structure was assessed via logistic regression and KRR alignment to ground-truth properties.
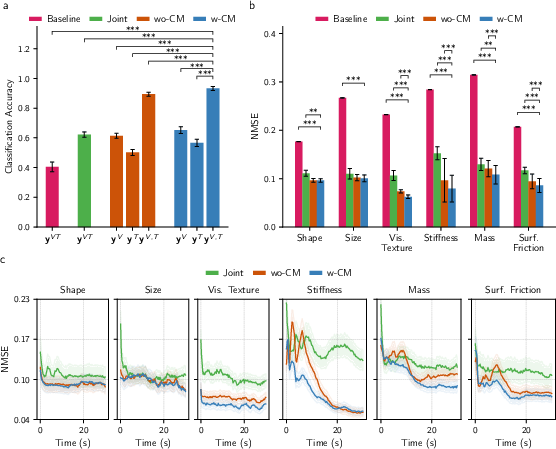
Figure 4: Classification and regression metrics reveal CMLF's superior inference efficiency for intrinsic and extrinsic properties; cross-modal priors accelerate convergence and reduce error.
Results demonstrate significant improvement in inference speed and accuracy for intrinsic properties when cross-modal priors from vision are available. Extrinsic inference is dominated by vision early, but tactile priors enhance robustness under ambiguity. The hierarchical latent space structure affords interpretable alignment of latent variables with physical object parameters.
Robustness to Noise and Corruption
Perturbation studies with additive Gaussian noise and random observation dropout show that CMLF is resilient to sensory degradation, in line with inverse effectiveness in multisensory biology. Cross-modal pathways act as latent backups: tactile priors improve extrinsic inference under visual corruption, and vice versa.
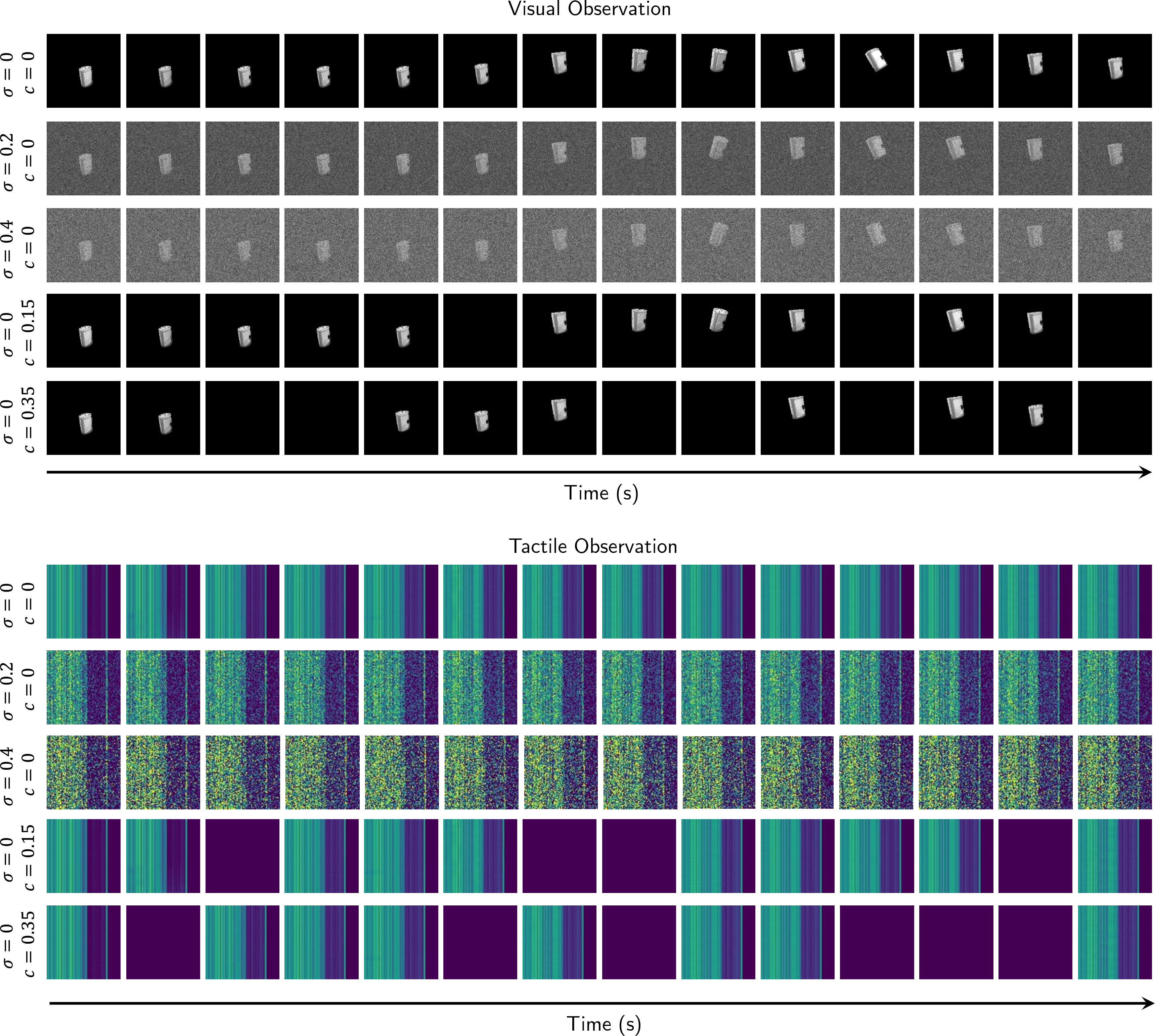
Figure 5: Visualization of different noise and corruption levels applied to visuo-tactile streams for robustness evaluation.
Quantitative metrics confirm that cross-modal coupling yields consistently lower prediction error across all property dimensions under noisy and incomplete input conditions compared to unimodal or joint-space baselines.
Biologically Plausible Cross-Modal Coupling and Surprise Objects
By delaying activation of cross-modal priors until unimodal latent stabilization, the model achieves improved generalization and faster convergence, mirroring developmental alignment processes in associative cortex. When exposed to "surprise" objects with inverted extrinsic-intrinsic correlations, CMLF exhibits Bayesian-like perceptual bias analogous to human multi-sensory illusions (e.g., size-weight).
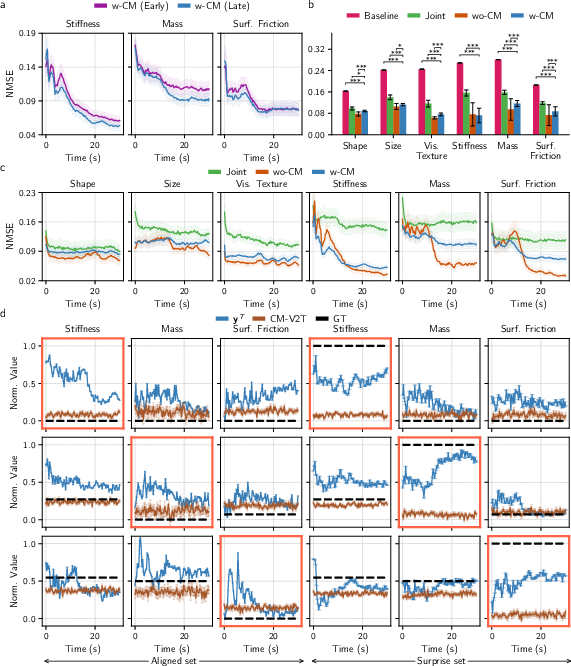
Figure 6: CMLF's perceptual behavior under surprise objects demonstrates biological-like Bayesian bias and gradual correction; delayed cross-modal activation improves learning.
The model's sequential Bayesian process gradually updates biased priors toward ground truth as more evidence accrues. Unlike humans, CMLF is less capable of rapid online adaptation when cross-modal illusions occur, highlighting a key limitation and a direction for neuro-inspired algorithmic advances.
Practical and Theoretical Implications
CMLF offers a principled pathway for uncertainty-aware, context-sensitive perceptual inference in contact-rich robotics. The structured latent partitioning and probabilistic cross-modal coupling improve both efficiency and robustness, providing actionable priors for anticipatory control, haptic exploration, and manipulation policy learning. The parallels to cortical associative motifs suggest that computational principles from neuroscience can significantly inform robotic perceptual architecture. Notably, the framework highlights the need for adaptive gating mechanisms to prevent maladaptive transfer when cross-modal correlations break down, and for causal reasoning to enable selective integration only when a common cause exists.
Conclusion
The cross-modal latent filtering approach advances unsupervised inference of object properties by formalizing causal, object-centric latent spaces and Bayesian cross-modal integration. Empirical results validate improved efficiency, robustness, and biological plausibility compared to static fusion baselines. The developmental and perceptual parallels invite further exploration of online adaptive priors and causal gating, potentially bridging the gap between machine perception and human sensorimotor intelligence.

