- The paper introduces MLA as a multisensory model that integrates 2D, 3D, and tactile inputs via an encoder-free LLM for enhanced robotic manipulation.
- It employs token-level contrastive alignment and future multisensory forecasting to improve physical dynamics modeling and achieve higher success rates in dynamic tasks.
- Empirical results show MLA outperforms 2D and 3D baselines with up to 24% improvement, demonstrating robust generalization to unseen objects and environments.
Multisensory Language-Action Models for Robotic Manipulation: The MLA Framework
Introduction and Motivation
The paper introduces MLA, a Multisensory Language-Action model designed to address the limitations of existing Vision-Language-Action (VLA) models in robotic manipulation. While prior VLA models have demonstrated generalization in mapping visual and linguistic inputs to actions, they predominantly rely on 2D visual observations and language, neglecting the rich spatial and interaction cues available from 3D and tactile modalities. This omission is particularly detrimental in contact-rich, dynamic environments where spatial reasoning and physical feedback are critical for robust manipulation. MLA is proposed to bridge this gap by integrating 2D images, 3D point clouds, and tactile signals into a unified policy, and by forecasting future multisensory states to enhance physical dynamics modeling.
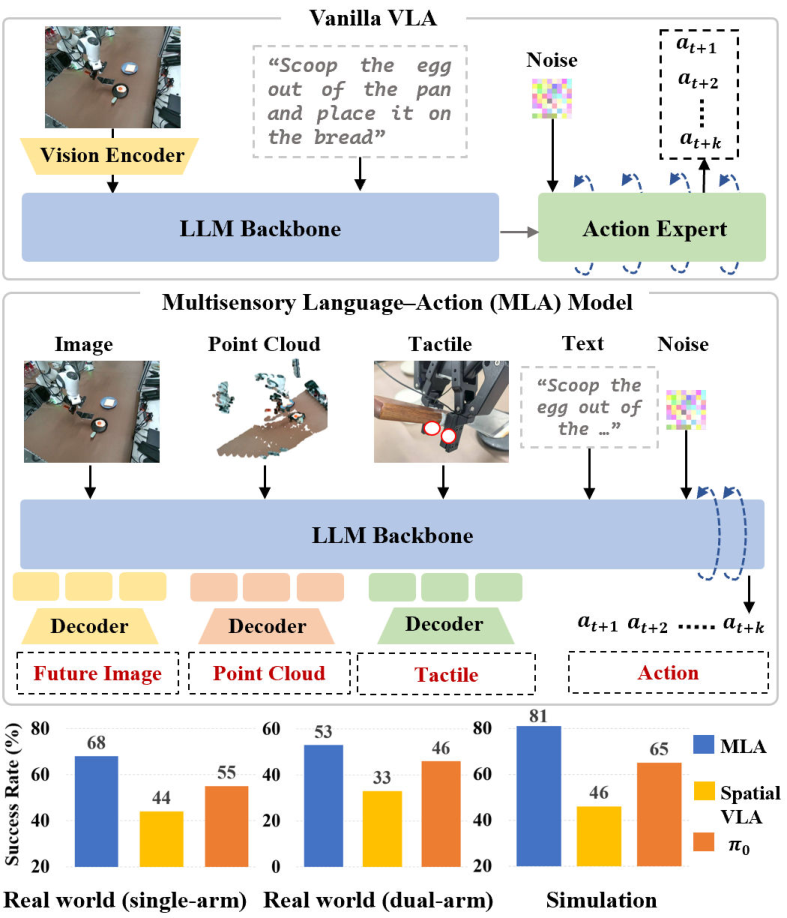
Figure 1: MLA extends beyond vanilla VLA by integrating diverse robotic-specific modalities and predicting their future states, achieving SOTA performance across real and simulated tasks.
Model Architecture and Multimodal Alignment
MLA is architected around a LLM backbone (LLaMA-2 7B), which is repurposed as a unified perception and reasoning module. The model eschews traditional modality-specific encoders in favor of lightweight tokenizers for each sensory input:
- Image Tokenizer: Converts RGB images into patch tokens.
- 3D Point Cloud Tokenizer: Aggregates local geometric features using FPS and KNN, producing point tokens.
- Tactile Tokenizer: Embeds low-dimensional tactile signals via an MLP.
All tokens are projected into a shared embedding space and processed jointly by the LLM. This encoder-free design is enabled by a novel token-level contrastive alignment mechanism, which leverages cross-modal positional correspondences. Specifically, 3D points and tactile sensor positions are projected onto the 2D image plane using camera parameters, and token-level InfoNCE losses are used to align corresponding tokens across modalities. This approach enforces both semantic and spatial consistency, enhancing the LLM's ability to interpret heterogeneous sensory cues without the inefficiency and misalignment of external encoders.
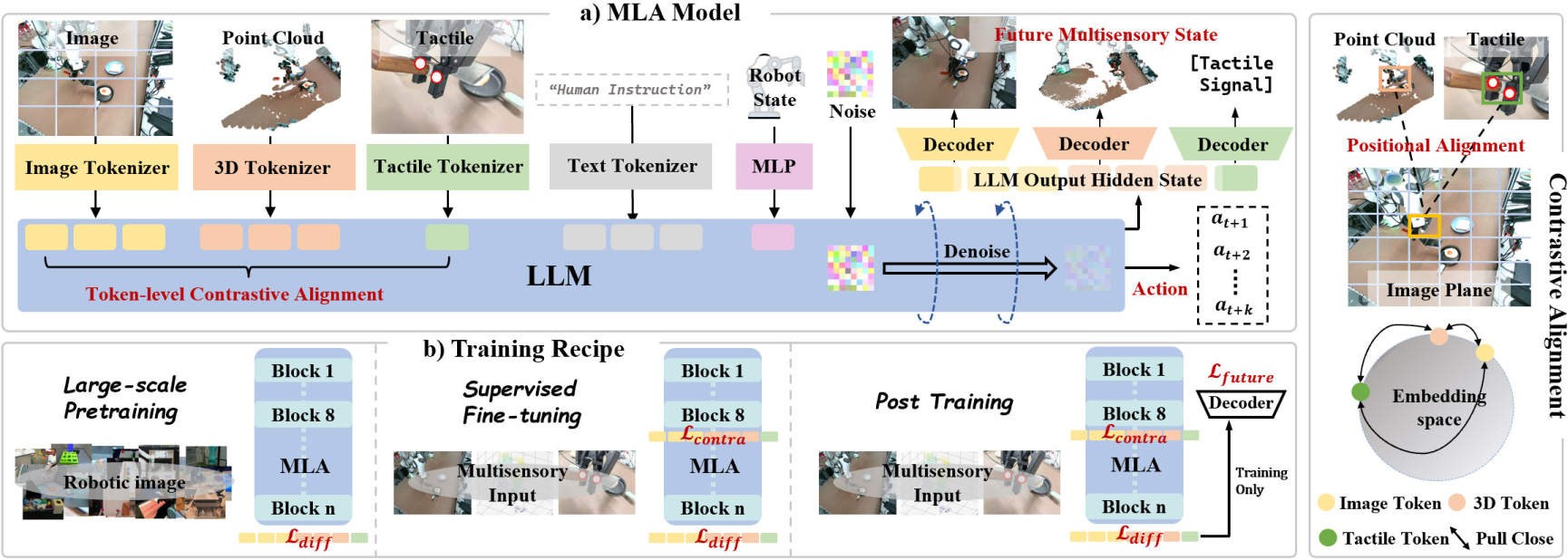
Figure 2: MLA’s framework: encoder-free multimodal alignment via token-level contrastive learning, and future multisensory generation post-training. The three-stage training pipeline is depicted.
Future Multisensory Generation
To further improve physical dynamics modeling, MLA incorporates a future multisensory generation post-training strategy. Transformer-based decoders are attached to the LLM’s final hidden states to predict future keyframes for each modality:
- Image Prediction: Foreground-masked image generation supervised by MSE loss.
- Point Cloud Prediction: Patch-based reconstruction using Chamfer Distance, inspired by masked autoencoders for point clouds.
- Tactile Prediction: Low-dimensional tactile vector prediction via MSE loss.
This predictive process is only active during training and does not impact inference efficiency. By requiring the model to anticipate future sensory states, MLA learns representations that are more robust to dynamic and contact-rich scenarios, providing stronger conditions for action generation.
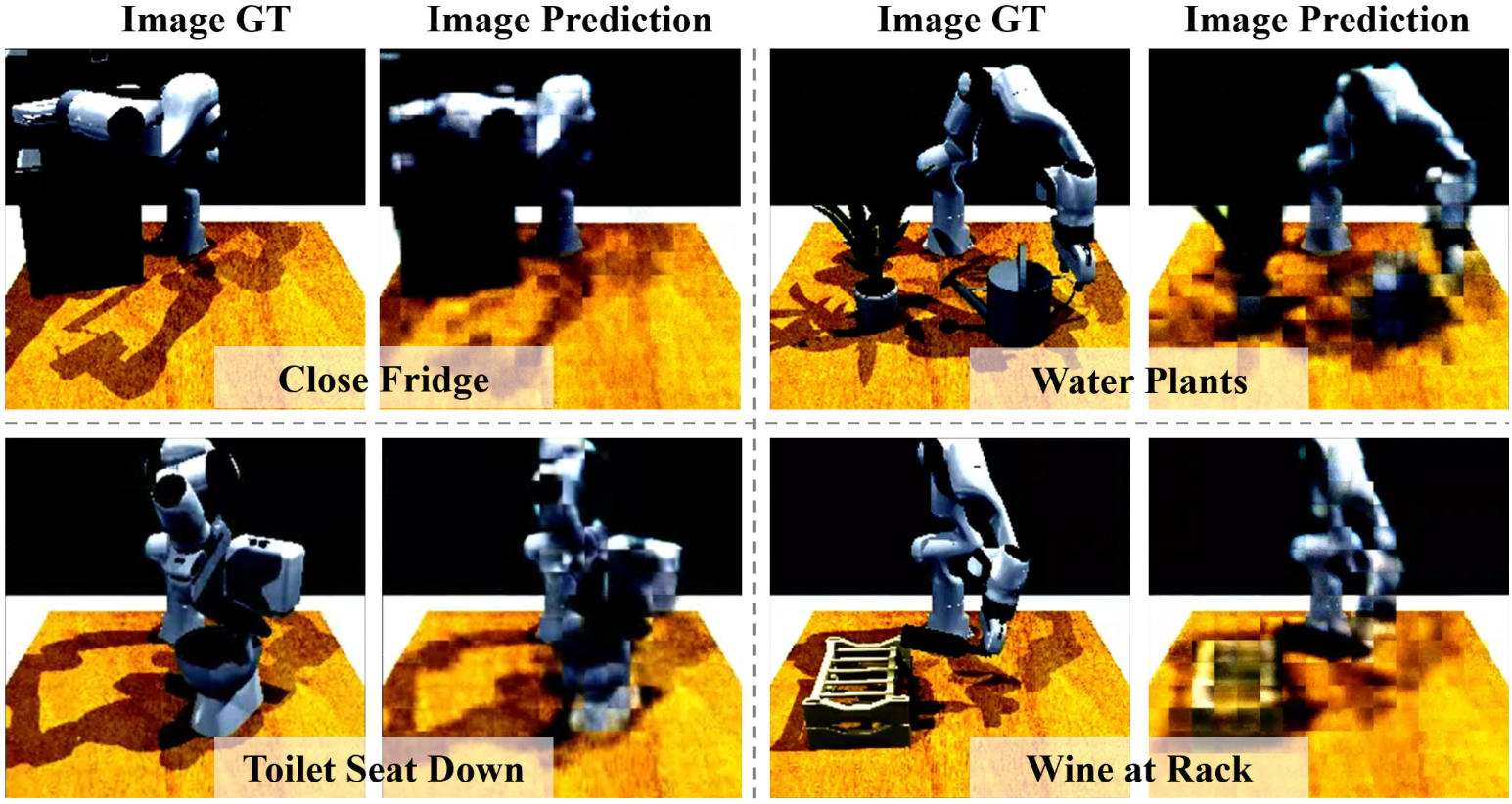
Figure 3: MLA’s image prediction capability: ground truth (left) vs. model prediction (right) for four samples.
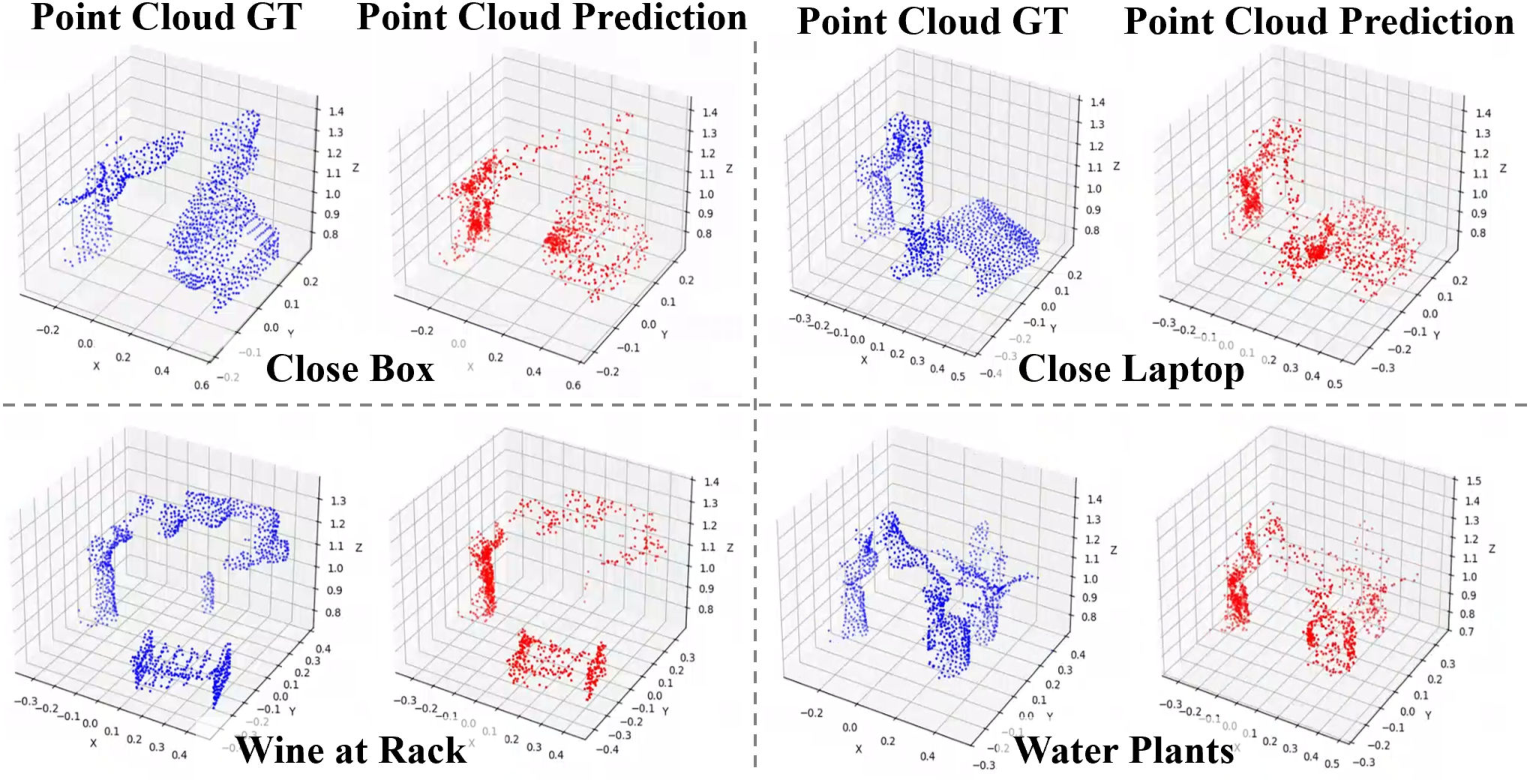
Figure 4: MLA’s point cloud prediction: ground truth (left) vs. model prediction (right) for four samples.
Training Paradigm
MLA is trained in three stages:
- Large-Scale Pretraining: On 570K trajectories from 28 datasets, using only image, language, and robot state modalities. Token positions for 3D and tactile inputs are reserved to ensure sequence consistency.
- Supervised Fine-Tuning (SFT): On task-specific datasets with all modalities, using the encoder-free contrastive alignment loss.
- Post-Training: Incorporates future multisensory generation losses, further refining the model’s ability to reason about physical dynamics.
The action head is implemented as a diffusion model, with noise tokens appended to the token sequence and trained using a DDPM objective.
Empirical Evaluation
Real-World Robotic Manipulation
MLA is evaluated on six real-world tasks (four single-arm, two dual-arm) involving contact-rich manipulation, using Franka Research 3 arms, RealSense D455 cameras, and Tashan TS-E-A tactile sensors.
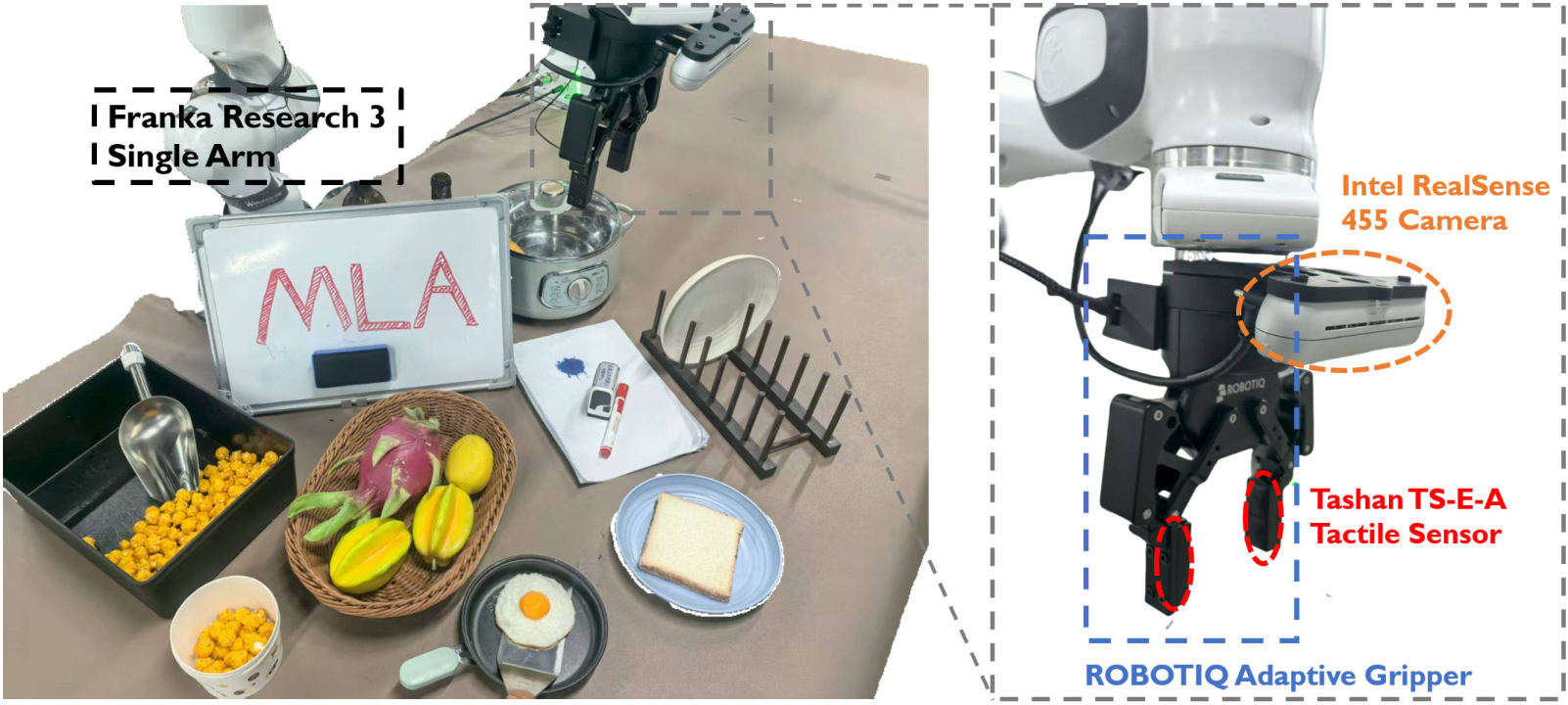
Figure 5: Single-arm experiment setup with camera and tactile sensor placements.
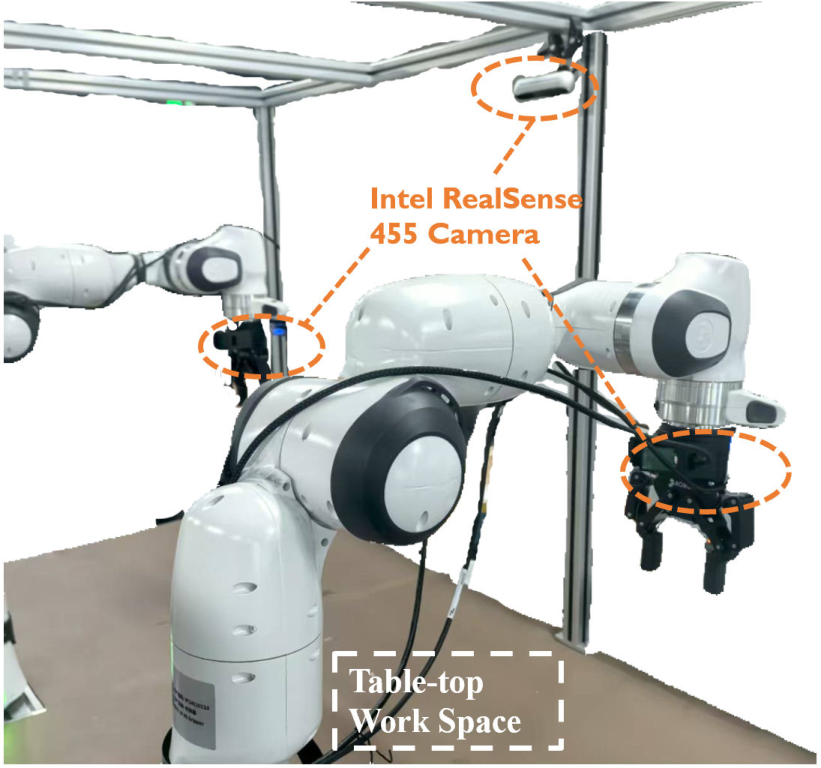
Figure 6: Dual-arm setup for collaborative manipulation.
MLA outperforms strong 2D (π₀) and 3D (SpatialVLA) VLA baselines by 12% and 24% average success rate, respectively, across all tasks. Notably, in tasks such as "Wiping a Whiteboard," tactile feedback is critical for regulating end-effector motion, and MLA’s multisensory integration yields superior performance.
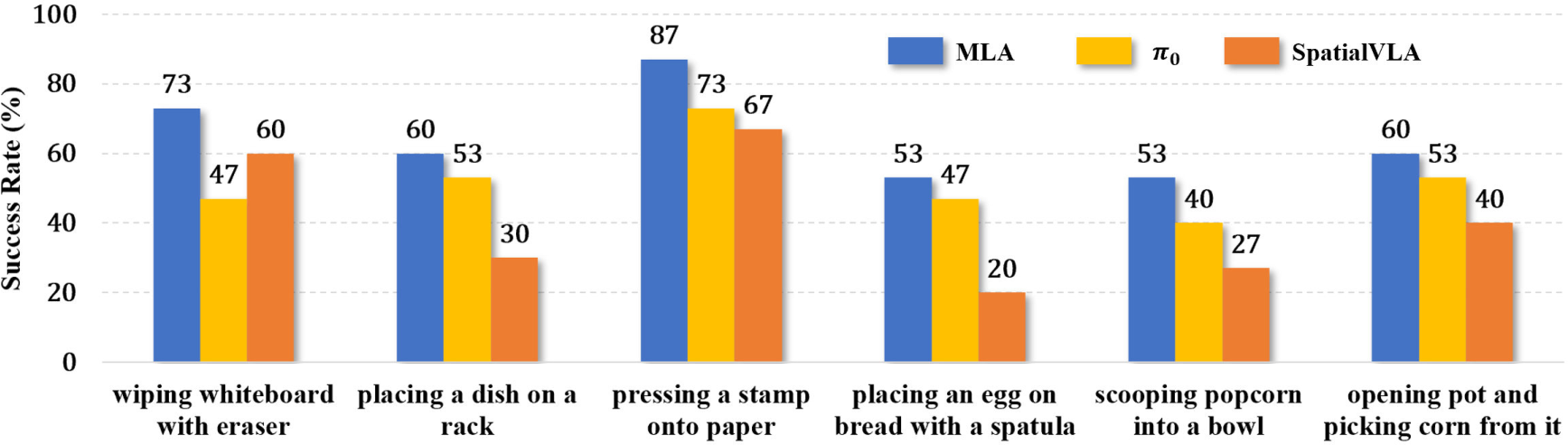
Figure 7: Real-world task success rates for MLA and baselines over 15 rollouts per task.
Generalization and Simulation
MLA demonstrates improved generalization to unseen objects and backgrounds, with only a 15–25% drop in success rate under challenging conditions, compared to 26–47% for π₀. In RLBench simulation benchmarks, MLA achieves an average success rate of 81%, significantly surpassing all baselines, including π₀ (65%) and SpatialVLA (46%).
Ablation Studies
Ablation experiments confirm the importance of each component:
- Token-level contrastive alignment outperforms both simple concatenation and image-level alignment, with a 7% accuracy gain.
- Contrastive loss applied at the 8th transformer block yields optimal performance, balancing early alignment with downstream reasoning capacity.
- Removal of any future generation modality (image, point cloud, tactile) degrades performance, confirming the necessity of comprehensive forecasting.
- Encoder-free design is both more efficient and more effective than adding external 2D/3D encoders.
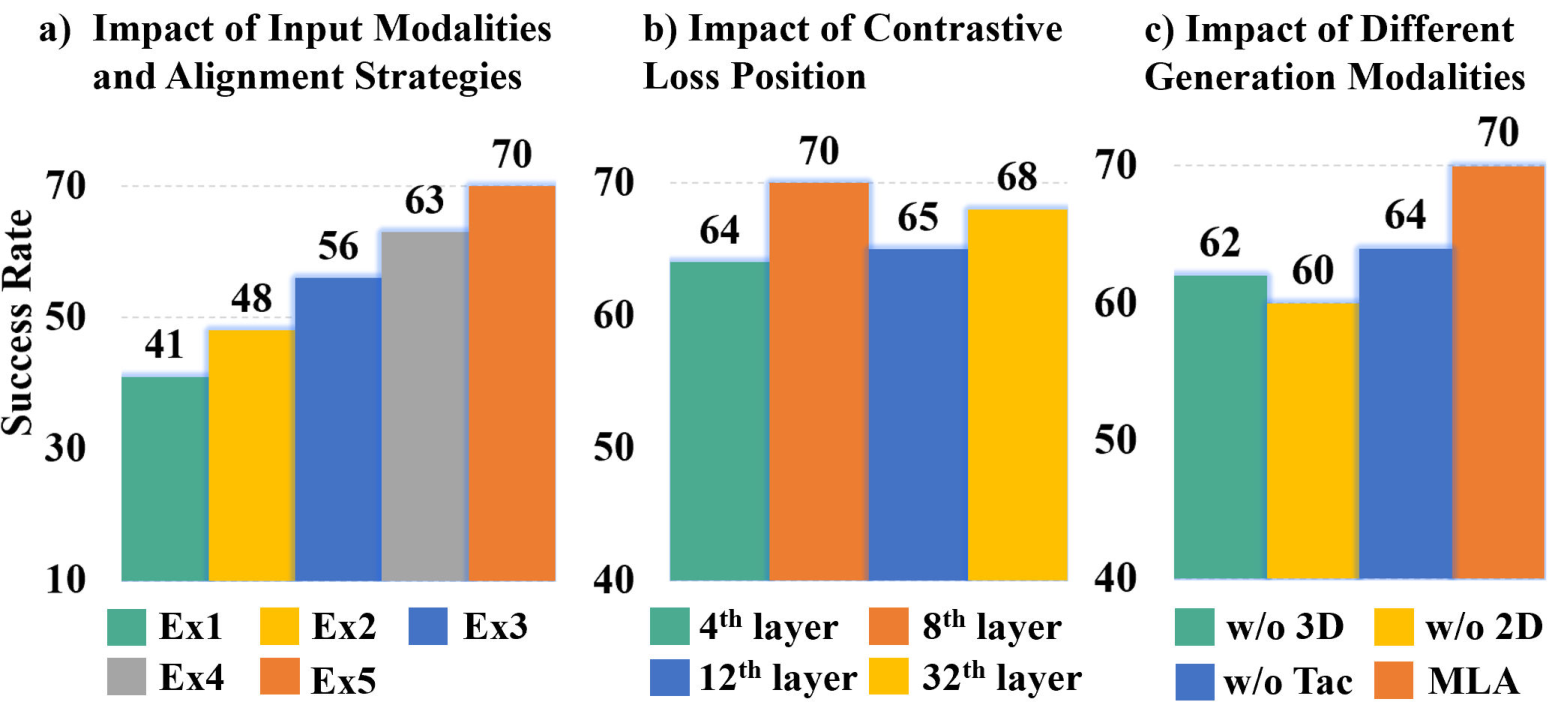
Figure 8: Ablation study results for input modalities, alignment strategies, and future generation components.

Figure 9: Visualization of task progress and attention heatmaps, showing MLA’s focus on relevant objects and robot states.
Implications and Future Directions
MLA establishes a new paradigm for robotic policy learning by demonstrating that a unified LLM can serve as both a perception and reasoning module for multisensory inputs, provided that cross-modal alignment is enforced at the token level. The encoder-free approach not only improves efficiency but also ensures that all modalities are natively aligned in the LLM’s embedding space, avoiding the representational mismatch of external encoders.
The future multisensory generation strategy is shown to be critical for robust action generation in dynamic, contact-rich environments. This approach is extensible to additional modalities (e.g., audio, force-torque) and to more complex multi-agent or multi-robot scenarios. The demonstrated generalization to unseen objects and backgrounds suggests that such models can serve as robust foundation policies for real-world deployment.
Theoretical implications include the viability of LLMs as universal multimodal sequence models for embodied agents, provided that appropriate alignment and forecasting objectives are imposed. Practically, the encoder-free, token-level alignment paradigm reduces system complexity and computational overhead, facilitating deployment in resource-constrained robotic platforms.
Conclusion
MLA advances the state of the art in vision-language-action modeling for robotics by integrating 2D, 3D, and tactile modalities through encoder-free, token-level alignment and by leveraging future multisensory generation for robust physical dynamics modeling. The model achieves strong empirical results in both real-world and simulated environments, with significant improvements in generalization and efficiency. The framework provides a scalable foundation for future research in multisensory, multimodal policy learning and sets a precedent for LLM-centric architectures in embodied AI.